Why migrate from Oracle to Postgres? The reasons for an Oracle to Postgres migration are many, but it starts with what the Oracle and PostgreSQL databases are all about, their features and pros and cons. In this blog we learn about the reasons why you should migrate from Oracle to Postgres, the Postgres benefits you could enjoy, and some phases, approaches, and methods of Oracle to Postgres migration. Also learn how BryteFlow as an automated Oracle to Postgres migration tool can shorten and smoothen your journey of moving data from Oracle to Postgres.
Quick Links
- What is the Oracle Database?
- What is the PostgreSQL Database?
- Oracle to Postgres Migration: Postgres Benefits that provide compelling reasons to migrate
- About Database Migration
- Oracle to Postgres Migration Phases
- Oracle to Postgres Migration: What to keep in mind
- Oracle to Postgres Migration Approaches
- Common CDC types to migrate from Oracle to Postgres
- Oracle to Postgres Migration Methods
- How to ingest data from Oracle to Postgres Step by Step with BryteFlow
What is the Oracle Database?
Oracle Database (Oracle DB) is a relational database management system used by some of the world’s largest enterprises and is it a commercial database licensed by the Oracle Corporation. It is also referred to as Oracle DBMS, Oracle Autonomous Database, or simply Oracle. It is a multi-model database management system that is mostly used for storing, organizing, and retrieving data, online transaction processing (OLTP), Data Warehousing (DW) and running mixed database workloads (combination of OLTP and DW). Oracle DB is one of the most reliable and widely used relational database engines in the world. Oracle Database can be run on-prem, on Cloud or even as a hybrid cloud installation. It offers the capability to be run on third-party servers, and on Oracle hardware (Exadata, Oracle Cloud, Oracle Cloud at Customer). BryteFlow for Oracle CDC
The Oracle DB architecture centers around a relational database framework that enables users and application front ends to access data objects directly through Structured Query Language (SQL). The Oracle DB system is highly scalable and used by large enterprises to access, process, manage and consolidate their data across wide and local area networks. Oracle is equipped with its proprietary network components that enable easy communication over the network. Oracle CDC and 13 things you should know
What is the PostgreSQL Database?
PostgreSQL or Postgres as it is popularly known, is the most advanced open-source object-relational database system in the world and has been under active development for over 35 years. As an enterprise-grade database, Postgres has a well-deserved reputation for reliability, versatility, robustness, and performance. Postgres is used by many web, mobile, analytical, and geo-spatial applications as a data repository and data warehouse. Most startups and enterprises today use PostgreSQL to power their dynamic websites and applications. Postgres supports SQL and JSON queries and supports advanced data types and multiple programming languages such as Python, Java, C#, Ruby etc. BryteFlow for Postgres CDC
Why is Postgres becoming so popular?
Firstly, Postgres is an open-source RDBMS (no expensive licensing fees), secondly it is highly extensible and fault-tolerant. Efforts are always on by companies as well as the Postgres community to increase the extensibility for different use cases and to extend the functionality of the database. Postgres provides users an ever-expanding number of functions that assist tech teams in building applications, maintaining data integrity, and building secure data environments. Postgres can have customized extensions to cater to very specific needs (e.g., extensions to handle time-series, geo-spatial data, extended logging etc.). PostgreSQL is being updated continually and adapted for various platforms. Postgres to Oracle with BryteFlow
Postgres has powerful SQL querying capabilities and can function as a cost-effective data warehouse. It is compatible with many BI tools and can be used for data analytics, data mining and business intelligence objectives. Being highly scalable, Postgres enables users to process and manage their data efficiently no matter what the size of the database. PostgreSQL Data Integration
Postgres is highly flexible and being open source, it is easy to upgrade or extend. Users can define their own data types, create custom functions, and write code in a different programming language without needing to recompile the database. It can be run on Windows, Mac OS X, and almost all Linux and Unix distributions. Postgres is highly compliant with SQL standards leading to increased interoperability with other applications. Postgres CDC (6 Easy Methods to Capture Data Changes)
Oracle to Postgres Migration: Postgres Benefits that provide compelling reasons to migrate
Oracle to Postgres migrations can confer many advantages to organizations. Here are some Postgres benefits listed for you:
Oracle to Postgres Migration: Postgres can save on data costs
Additional features such as data partitioning and high availability may need to be paid for when using Oracle DB. These expenses can add up quickly in addition to Oracle’s licensing costs. In contrast open-source Postgres is free to install and use, and new features and functionalities are being added all the time, which again, are free to use. Postgres acquisition, installation and support is completely free of charge. Oracle to Postgres with BryteFlow
Oracle to Postgres Migration: Because Postgres means no vendor lock in
Postgres has open-source licensing and is widely available online and from public cloud providers. PostgreSQL is widely supported as a DBaaS. These services are provided by Amazon RDS, Microsoft’s Azure Database for PostgreSQL, and Google’s Cloud SQL for PostgreSQL. With Postgres (unlike Oracle) you do not risk being locked into a vendor. Oracle vs Teradata (Migrate in 5 Easy Steps)
Oracle to Postgres Migration: Avoid expensive Oracle licensing and Paid Support
Oracle being a commercial database comes with heavy licensing costs. For e.g. additional tools like Oracle GoldenGate for real-time replication may need additional licensing and may require installation of the Oracle Enterprise Edition to unlock advanced features. Oracle support too, is not free and must be paid for. In contrast Postgres has an active developer community so tweaks, patches and updates are easy to source and free. Answers to queries about installation, upgrades and usage can be found quickly with no charge. Postgres extensions are ever growing and there are thousands of plugins available, supported by an enthusiastic community. Commercial support for Postgres is available and is largely cheaper than Oracle support. Oracle to Azure Cloud Migration (Know 2 Easy Methods)
Oracle to Postgres Migration: Because Postgres has thousands of free extensions
Since Postgres is an open-source DB, there are thousands of free extensions and add-ons that can greatly enhance database performance. At Oracle, the cost of similar functionality adds up fast. Though Oracle does offer provide many tools, they are add-on solutions that attract additional processor licensing costs, software update licensing costs and support fees. Aurora Postgres and How to Setup Up Logical Replication
Oracle to Postgres Migration: Benefit from Easy Application Programming with Postgres
Both Oracle and Postgres provide application APIs for communicating with databases. However, a big Postgres benefit is that it is open source. A developer can simply include the header files in the project to directly access any of the Postgres components. Debezium CDC Explained
Oracle to Postgres Migration: Benefit from flexible Host-based Postgres Authentication
While Oracle has an integrated authentication system, Postgres is based on host-based authentication, which means it can support a variety of authentication methods (Trust authentication, Peer authentication, Password authentication etc.) This provides more authentication flexibility and enables delegation of the process. SQL Server vs Postgres – A Step-by-Step Migration Journey
Oracle to Postgres Migration: Because Postgres supports many procedural languages
PL/SQL language is built into Oracle, but PostgreSQL allows you to write directly to the database using language handlers for multiple languages (PL/pgSQL, PL/Tcl, PL/Perl, and PL/Python). It also supports several external languages. In fact, users can even define a new procedural language as per requirement in the form of plugins and create bindings for additional programming languages. Postgres supports the JSON data type, which is lightweight and flexible, due to which PostgreSQL provides support for many programming languages and protocols such as Python, Perl, Ruby, Java, .Net, C/C++, ODBC, and Go. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
Oracle to Postgres Migration: Because Postgres is highly compatible
PostgreSQL is compatible with most RDBMS including Oracle which makes it easy to migrate to Postgres from Oracle. It also has excellent operating system compatibility with platforms like HP-UX, Linux, NetBSD, OpenBSD, FreeBSD, OS X, Unix, Solaris, and Windows which is a great benefit. Oracle vs Teradata (Migrate in 5 Easy Steps)
Oracle to Postgres Migration: Because Postgres provides automatic character encoding
Oracle has the Globalization Development Kit and Unicode character support to function as globalization support tools, while Postgres has integrated localization system services to provide automatic character encoding and collation support. Oracle to Snowflake: Everything You Need to Know
Oracle to Postgres Migration: Because Postgres provides high performance at low cost
Postgres can create an unlimited number of nodes in a read cluster, it can reduce the cost of any given read to near zero. This enables the provision of different settings for each workload. This can also be done in Oracle, but at an additional cost per node. Oracle to SQL Server: Reasons, Challenges and Tools
Oracle to Postgres Migration: Because Postgres has unlimited scalability
Though Oracle has strong vertical read scalability, Postgres can scale almost infinitely and can create a virtually unlimited number of nodes in a read cluster, depending on resources available. Oracle can also be used for heavy workloads but scaling an Oracle database always comes at a cost. PostgreSQL can scale and process millions of transactions per second and handle very high data volumes. Postgres to Snowflake : 2 Easy Methods of Migration
Oracle to Postgres Migration: Because Postgres releases major updates and bug fixes frequently
Unlike Oracle where major releases happen every 2 to 4 years, PostgreSQL releases major updates and bug fixes often – approximately every three months. Aurora Postgres and How to Setup Up Logical Replication
Oracle to Postgres Migration: Because Postgres has data security
Oracle does offer advanced data security tools, but these are costly add-ons. PostgreSQL has role-based access control and free security authentications such as Host, LDAP, and PAM. Data encryption is also available through advanced security extensions.
Some database migration challenges when migrating from Oracle to Postgres
Now that we have examined the benefits of migrating from Oracle to Postgres, you should be aware of the challenges you could come up against in the Oracle to Postgres migration process. Schema conversion, continuous, low latency data replication, and conducting migration validation could be some big stumbling blocks. Debezium CDC Explained and a Great Alternative CDC Tool
About Database Migration
What exactly is database migration and why do organizations migrate data? Database migration is the process by which an organization moves its data from one location or platform to another. It could also include moving data from an on-premise database to the Cloud. The process includes moving data, stored procedures, definitions and making changes in the application. Stages in data migration include data selection, data preparation, extraction, ingestion, transformation etc. Database migration helps to integrate data from different sources, so it is accessible for different purposes and techniques, it helps in cost reduction, adds scalability for faster processing and improves data reliability.
Oracle to Azure Cloud Migration (Know 2 Easy Methods)
Some reasons why organizations need to migrate their data:
- Database migration saves on data costs, for e.g., moving from Oracle, a commercial licensed database to Postgres which is open source and completely free. Postgres to Snowflake : 2 Easy Methods of Migration
- Increase in data volumes which cannot be handled efficiently by an existing data implementation, for e.g., moving from a resource-stretched on-premise database implementation to the unlimited scalability of the Cloud. Moving to the Cloud also reduces infrastructure and staffing costs.
- Database migration may be called for when organizational requirements change, and the existing database cannot handle a new operational use case. Connect Oracle to Databricks and Load Data the Easy Way
- Migrating data from an outdated legacy system to a more modern platform and software. Postgres to Oracle with BryteFlow
- Data migration can help to consolidate multi-source data, so it is available to different teams for analytics and data science purposes.
- Over a period, a company may eventually move away from a current database to save expenses, improve dependability, attain scalability, or accomplish any other goal.
Oracle to Postgres Migration Phases
Migrating Oracle to Postgres involves several phases including the assessment of the existing database and potential needs, right schema selection, doing compatibility checks, conversion of incompatible objects, performance and functional testing, data migration and post-migration checks.
Steps in migrating from an Oracle to Postgres database
Database migration is driven by the goals you need to achieve. Here are some common steps you need to take when moving from Oracle to Postgres. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
Briefing and Preparation
Brief and educate the team about the transition, provide technical knowledge so they can collaborate seamlessly, maintain business continuity and good data governance practices.
Advance check: Find out exactly what you need to migrate. Find and exclude data that does not need to be replicated, such as old backups, old temporary tables etc.
Evaluate your migration: Analyze objects in your apps and databases, find differences between databases, and export sample test data to migration reports to understand the estimated time and resource consumption of the migration process.
Assess Requirements: You should assess your requirements before migrating from Oracle to Postgres. Compatibility of application servers, clients, data access, data type conversion, code conversion, and database functionality should also be assessed.
Schema conversion and migration: In Oracle, there is a one-to-one relationship between schemas and users, and there is no real difference between users and schemas. In PostgreSQL all user-created objects are created in a specific schema or namespace. Oracle requires each schema to be defined but in PostgreSQL the schema defaults to the public schema even if the schema has not been defined. When a role, schema and their association are specified, a schema conversion report should be generated that will provide details on conversion of objects – ones that can be seamlessly converted and others that will require manual coding. Manual conversions must be performed after analyzing the report, so they can work with the application.
Functional testing: It’s important to test the migrated schema with a sample dataset. Load some sample data from your target database or test environment into PostgreSQL and connect to the application with the appropriate driver or data access. After connecting your application to the database, you can use DML to test the functionality of the transformed objects. Load an identical sample dataset into both PostgreSQL and Oracle and verify that the SQL results are the same.
Performance testing: Performance testing is of paramount importance since transactions built into Oracle are different in PostgreSQL. Proper tuning at the app, driver, and database level can help you find and fix differences.
Data Migration: The actual Oracle to Postgres migration may take time on account of them being heterogenous databases. Broadly three data migration approaches can be followed, either in solo fashion or in conjunction with each other. Oracle to Snowflake: Everything You Need to Know
- Snapshot Approach: Data is moved across in a single go. Connect Oracle to Databricks and Load Data the Easy Way
- Snapshot in Parallel Approach: Data is moved in chunks (schema or table)
- Change Data Capture Approach (Continuous Replication): Data is loaded continuously syncing changes at source with the target. Change Data Capture and making CDC Automation easy
The first two approaches may need application downtime and may impact source systems while the CDC approach means very little downtime and almost no impact on source systems.
Data Validation: Since Oracle to PostgreSQL is a heterogeneous migration, it is advisable to validate data after migration. This can verify that all data has been migrated without error and that the target database can be used safely. It can also validate the correct conversion of downstream objects (Views, PL/SQL, etc.).
Oracle to Postgres Migration: What to keep in mind
Prerequisites for Oracle to Postgres Migration
Take care that the machine or system where the migration will take place has both Postgres and an Oracle client installed. Server resources like memory and network ports must be opened between source and target. The compatibility of the operating system must be verified in both source and destination along with the installed and configured data migration software and related drivers. Please note that the PostgreSQL target server should be large enough to scale up for the data migrating from Oracle. Postgres to Snowflake : 2 Easy Methods of Migration
Transactions differ in Oracle and Postgres
Keep in mind that implementations of transactions in Oracle and PostgreSQL are a little different. Each executed statement starts a transaction in Oracle, and a COMMIT statement ends a transaction. PostgreSQL requires a BEGIN statement before activating a transaction and ends with the COMMIT statement. The default isolation level for both databases is Read Committed. Postgres to Oracle with BryteFlow
Language conversion between Oracle and Postgres
Although PL/pgSQL and the PL/SQL language are very similar, there are some important differences to be aware of. These two languages implement data types differently, so some work is required to convert properly. Since PostgreSQL doesn’t have packages, schemas are used to group functions as needed. This also means that you cannot use package level variables. Also, cursor variables are represented differently in these two languages and PostgreSQL function bodies must be written as string literals, so you must use dollar signs or escape single quotes in the function body. Source to Target Mapping Guide (What, Why, How)
Mapping data types between Oracle and Postgres
What is remarkable is that PostgreSQL has many more data types than Oracle. Here are some data mappings
| Oracle | PostgreSQL | |||
| 1 | BINARY_FLOAT | 32-bit floating-point number | REAL | |
| 2 | BINARY_DOUBLE | 64-bit floating-point number | DOUBLE PRECISION | |
| 3 | BLOB | Binary large object, ⇐ 4G | BYTEA | |
| 4 | CHAR(n), CHARACTER(n) | Fixed-length string, 1 ⇐ n ⇐ 2000 | CHAR(n), CHARACTER(n) | |
| 5 | CLOB | Character large object, ⇐ 4G | TEXT | |
| 6 | DATE | Date and time | TIMESTAMP(0) | |
| 7 | DECIMAL(p,s), DEC(p,s) | Fixed-point number | DECIMAL(p,s), DEC(p,s) | |
| 8 | DOUBLE PRECISION | Floating-point number | DOUBLE PRECISION | |
| 9 | FLOAT(p) | Floating-point number | DOUBLE PRECISION | |
| 10 | INTEGER, INT | 38 digits integer | DECIMAL(38) | |
| 11 | INTERVAL YEAR(p) TO MONTH | Date interval | INTERVAL YEAR TO MONTH | |
| 12 | INTERVAL DAY(p) TO SECOND(s) | Day and time interval | INTERVAL DAY TO SECOND(s) | |
| 13 | LONG | Character data, ⇐ 2G | TEXT | |
| 14 | LONG RAW | Binary data, ⇐ 2G | BYTEA | |
| 15 | NCHAR(n) | Fixed-length UTF-8 string, 1 ⇐ n ⇐ 2000 | CHAR(n) | |
| 16 | NCHAR VARYING(n) | Varying-length UTF-8 string, 1 ⇐ n ⇐ 4000 | VARCHAR(n) | |
| 17 | NCLOB | Variable-length Unicode string, ⇐ 4G | TEXT | |
| 18 | NUMBER(p,0), NUMBER(p) | 8-bit integer, 1 <= p < 3 | SMALLINT | |
| 16-bit integer, 3 <= p < 5 | SMALLINT | |||
| 32-bit integer, 5 <= p < 9 | INT | |||
| 64-bit integer, 9 <= p < 19 | BIGINT | |||
| Fixed-point number, 19 <= p <= 38 | DECIMAL(p) | |||
| 19 | NUMBER(p,s) | Fixed-point number, s > 0 | DECIMAL(p,s) | |
| 20 | NUMBER, NUMBER(*) | Floating-point number | DOUBLE PRECISION | |
| 21 | NUMERIC(p,s) | Fixed-point number | NUMERIC(p,s) | |
| 22 | NVARCHAR2(n) | Varying-length UTF-8 string, 1 ⇐ n ⇐ 4000 | VARCHAR(n) | |
| 23 | RAW(n) | Variable-length binary string, 1 ⇐ n ⇐ 2000 | BYTEA | |
| 24 | REAL | Floating-point number | DOUBLE PRECISION | |
| 25 | SMALLINT | 38 digits integer | DECIMAL(38) | |
| 26 | TIMESTAMP(p) | Date and time with fraction | TIMESTAMP(p) | |
| 27 | TIMESTAMP(p) WITH TIME ZONE | Date and time with fraction and time zone | TIMESTAMP(p) WITH TIME ZONE | |
| 28 | UROWID(n) | Logical row addresses, 1 ⇐ n ⇐ 4000 | VARCHAR(n) | |
| 29 | VARCHAR(n) | Variable-length string, 1 ⇐ n ⇐ 4000 | VARCHAR(n) | |
| 30 | VARCHAR2(n) | Variable-length string, 1 ⇐ n ⇐ 4000 | VARCHAR(n) | |
Other data types:
| Oracle | PostgreSQL | ||
| 1 | BFILE | Pointer to binary file, ⇐ 4G | VARCHAR(255) |
| 2 | ROWID | Physical row address | CHAR(10) |
| 3 | SYS_REFCURSOR | Cursor reference | REFCURSOR |
| 4 | XMLTYPE | XML data | XML |
Some technical differences and points to keep in mind during the Oracle to Postgres migration process
- Empty strings and NULLs – In PostgreSQL, the IS NULL operator returns FALSE when applied to an empty string, but in Oracle it returns TRUE in such cases. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
- Dual tables – Oracle databases require a FROM clause for every SELECT statement, so DUAL tables are used for such statements. PostgreSQL, on the other hand, does not require a FROM clause (and thus DUAL tables).
- DELETE statement – Unlike Oracle, PostgreSQL’s DELETE statement works only in the FROM clause.
- SUBSTR – This function returns different results in Oracle and PostgreSQL and can cause problems.
- SYSDATE – PostgreSQL has no equivalent to Oracle’s SYSDATE function that provides execution date and time.
Oracle to Postgres Data Migration Approaches
Three data migration approaches can be followed to migrate data from Oracle to Postgres, we had touched on these earlier, now we will examine them in greater detail.
- Snapshot Approach: Data is moved across quickly in a single go.
- Snapshot in Parallel Approach: Data is moved in blocks (schema or table)
- Change Data Capture Approach (Continuous Replication): Data is loaded continuously syncing changes at source with the target. Change Data Capture and CDC Automation
The first two approaches may need application downtime and may impact source systems while the CDC approach means very little downtime and almost no impact on source systems. Select these as per your downtime window.
Snapshot Replication
The Snapshot replication approach creates a copy of all the data and objects present at the time (full snapshot) and applies it to the target database. Write operations are not allowed on the source during the snapshot replication. This is useful when the volume of data is small, when the latest copy of the data at source is not required, and data changes very infrequently. This is an easy and clean way to migrate your data. This process often provides the initial full refresh of data for transactional and merge processes. Aurora Postgres and How to Setup Up Logical Replication
Advantages of Snapshot Replication
- Data movement happens in one go.
- No Data Type challenge (LoB).
- After the snapshot, the application can start accessing the target database immediately.
- Easy to manage, no special settings are required.
- READ ONLY users can access the source database (in some cases).
Disadvantages of Snapshot Replication
- The application needs to be shut down during the snapshot.
- Reinitialization is required if the snapshot is interrupted.
Snapshot – Parallel in ChunksReplication
Parallel in Chunks snapshot approach divides the data object into chunks and creates the snapshots in parallel. Most tools support snapshots and processes are run concurrently. There are two ways to create block-by-block snapshots- either per table or as one large table partitioned into smaller sets using primary keys or unique row IDs. The parallel in chunks approach can significantly reduce snapshot duration and downtime windows. Using a data migration tool for migrating tables or large tables requires good scripting skills. In contrast, a completely no-code replication tool like BryteFlow can help to migrate the data without any downtime, using automated multi-threaded parallel loading and partitioning. How BryteFlow Works
Advantages of Snapshot – Parallel in ChunksReplication
- Move data simultaneously with less downtime.
- Data is loaded in parallel – per table or one large table in a small set.
Advantages of Snapshot – Parallel in ChunksReplication
- Application downtime is required though less in comparison to the first approach.
- A primary key or unique row identifier is mandatory for large tables that are split into smaller rows.
- Writing scripts will be needed to adopt the parallel approach.
- Reinitialization is required if the snapshot is interrupted.
Change Data Capture (CDC) Replication
Change Data Capture or CDC is a replication process that captures every change happening in the source database and loads them to the target database in real-time to keep data in sync. Since CDC replicates only the rows that have changed, it is efficient and very sparing of system resources. CDC is ideal for modern Cloud architectures and enables real-time analytics and data science use cases.
There are several traditional Change Data Capture (CDC) approaches that have been around for years. In the CDC approach for data migration, the CDC software is designed to determine, track, and capture the data that has changed on the source database and load the same on the target database in real-time. CDC tools distribute high volume data between heterogeneous databases with low latency, reliability, scalability, and zero-downtime. Automating your ETL Pipeline
Common CDC types to migrate from Oracle to Postgres
Trigger-based CDC
A remote trigger is created to capture DMLs (insert/update/delete) before or after the sequence of transaction events is captured in changelog (shadow tables), then they are processed by the software to replay on the target database.
Transaction Log-based CDC
Every database has transaction logs (Redo logs in Oracle) that store all database transactions and events as they occur sequentially. These can be used for recovery in case of a database crash. The native database transaction log plugin allows you to capture transactions (DML) and modify the log with several filters, transformations, and aggregations. The sequence of captured DML is then replicated to the target database.
Both CDC approaches can be used to replicate data from Oracle to Postgres. However, each has its own benefits and limitations, and depending on your needs, you can choose one of the available approaches. There are very good CDC tools that can support both CDC approaches like our very own BryteFlow. Oracle vs Teradata ( Migrate in 5 Easy Steps)
Advantages of CDC Replication
- After the first snapshot, data is continuously loaded into the target database.
- Users can access the source database while data is being loaded into the target database.
- Data synchronization control can be continued even if interrupted.
- Partial duplication (table set duplication possible)
Disadvantages of CDC Replication
- Requires replication software
- Trigger-based CDC may have slightly slower performance
- Large objects are not supported
- Partial or short application downtime (switchover time)
- Only commercial or free tools available, no open source.
Oracle to Postgres Migration Methods
Manual method: Let us first examine the manual methods of moving data from Oracle to Postgres.
Foreign Data Wrappers are extensions to access data from external databases
Foreign Data Wrappers (FDW) are libraries for PostgreSQL databases that allow you to communicate, access and extract data and schema from one database to another, while keeping the connection details hidden. Foreign Data Wrappers enable Postgres to connect with data sources and extract data. When a query like SELECT is executed on the external table, the resulting output from the external data source is extracted by the FDW and loaded to the external table. FDW was based on a SQL specification called SQL/MED (SQL Management of External Data) which was created to provide remote access to SQL databases. PostgreSQL uses parts of the SQL/MED specification, enabling users to access data that exists external to PostgreSQL with ordinary SQL queries. Some foreign data wrappers are available as contrib modules. Other types of foreign data wrappers may exist as third-party products. You can even code a customized foreign data wrapper for your requirements.
- Oracle_fdw supports data migration from Oracle to Postgres
Oracle_fdw is a PostgreSQL extension that provides a foreign data wrapper for easy and efficient access to Oracle databases. Oracle_fdw is supported since PostgreSQL 12.7. It includes WHERE clause and desired column pushdown, and extensive EXPLAIN support. Oracle_fdw is used to perform DML operations (SELECT, INSERT, UPDATE, DELETE) on Oracle servers in PostgreSQL, which is covered under the SQL Management of External Data (SQL/MED) standard.
Learn more
- Orafce enables Oracle functions and packages in Postgres
The Orafce extension enables use of some common Oracle functions and packages within PostgreSQL. It provides functions and operators that emulate some of the functions and packages from the Oracle database. The Orafce extension makes it easy to port Oracle applications to PostgreSQL. It also supports Oracle date formats and additional Oracle data types. RDS for PostgreSQL version 9.6.6 and above supports this extension. As an extension, Orafce’s job is to implement some Oracle functions and data types in PostgreSQL to support data migration. It delivers some Oracle packages as PL/pgSQL functions, and an implementation of the DUAL table.
Learn more
Oracle to Postgres DB Link to enable selection of data from a remote database
You can move data from Oracle to Postgres by creating a DB Link. A DB Link or Database Link is a schema object whose function is to interact with remote database objects such as tables. Database Links can be used to select data from tables that are part of a remote database. DB Links are heterogeneous connections and allow you to select data from the Oracle DB using Oracle’s SELECT statement from within Postgres. You can then use Materialized Views to plan and store the results of those selections.
Learn more
Automated method: Using BryteFlow to migrate data from Oracle to Postgres.
BryteFlow, a real-time CDC tool migrates data from Oracle to Postgres with zero coding
BryteFlow is a Cloud-native tool that specializes in the movement of enterprise-scale data from transactional databases (on-prem and Cloud) like SAP, Oracle, PostgreSQL, MySQL and SQL Server to popular destinations and cloud warehouses like Amazon S3, Amazon Redshift, Snowflake, SingleStore, Teradata, Azure Synapse, Azure Data Lake 2, PostgreSQL, Google BigQuery, SQL Server, Kafka and Databricks. BryteFlow replicates data in real-time using Change Data Capture (CDC) and creates schema and tables automatically on the destination.
Oracle to Postgres Migration Tool Highlights
- BryteFlow’s Oracle to Postgres CDC has minimal impact on source systems.
- Fast Oracle to Postgres initial full refresh with multi-threaded, parallel loading and partitioning.
- Incremental data (deltas) replicated with continual log-based CDC.
- Postgres replication best practices built into the software.
- BryteFlow extraction is at least 6x faster than GoldenGate (1,000,000 rows in 30 secs).
- Oracle to Postgres replication has zero coding for extraction, merging, mapping, masking, or type 2 history.
- Data Reconciliation with BryteFlow TruData is automated with row counts and columns checksum.
- Supports high volume enterprise-scale data ingestion from Oracle to Postgres, both initial and incremental.
- Highly Available and Automatic Network Catchup.
- BryteFlow Ingest supports replication to Amazon Aurora Postgres on AWS.
- Replication support for all Oracle versions, including Oracle 12c, 19c, 21c and future releases for the long term.
How to ingest data from Oracle to Postgres Step by Step with BryteFlow
Prerequisites: Please ensure that all prerequisites have been met and all security and firewalls have been opened between all the components.
Use the BryteFlow Ingest software and follow these steps
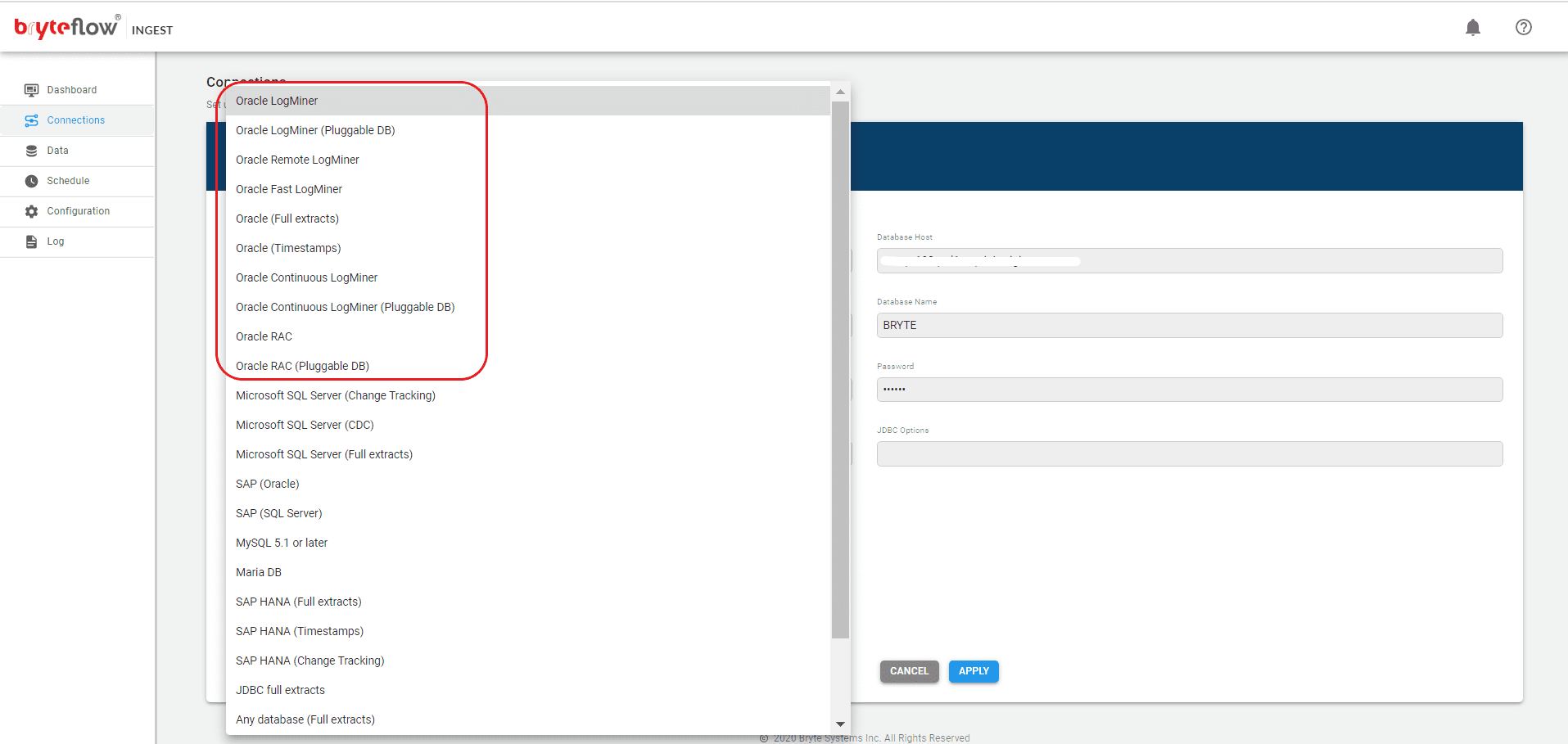
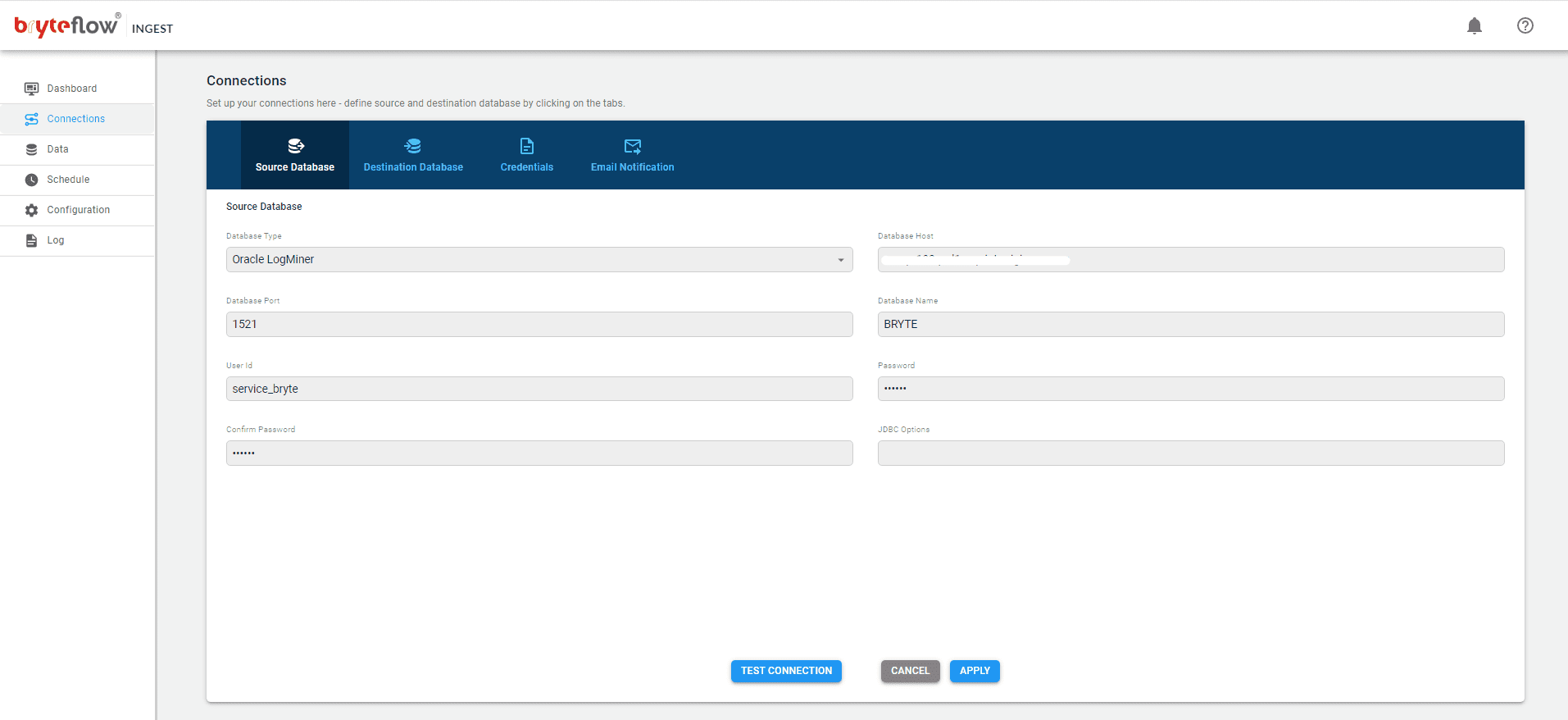
Set up the source connection details, assuming the source is Oracle.
Set up the source connection details. The source can be on the Cloud or on-premise.
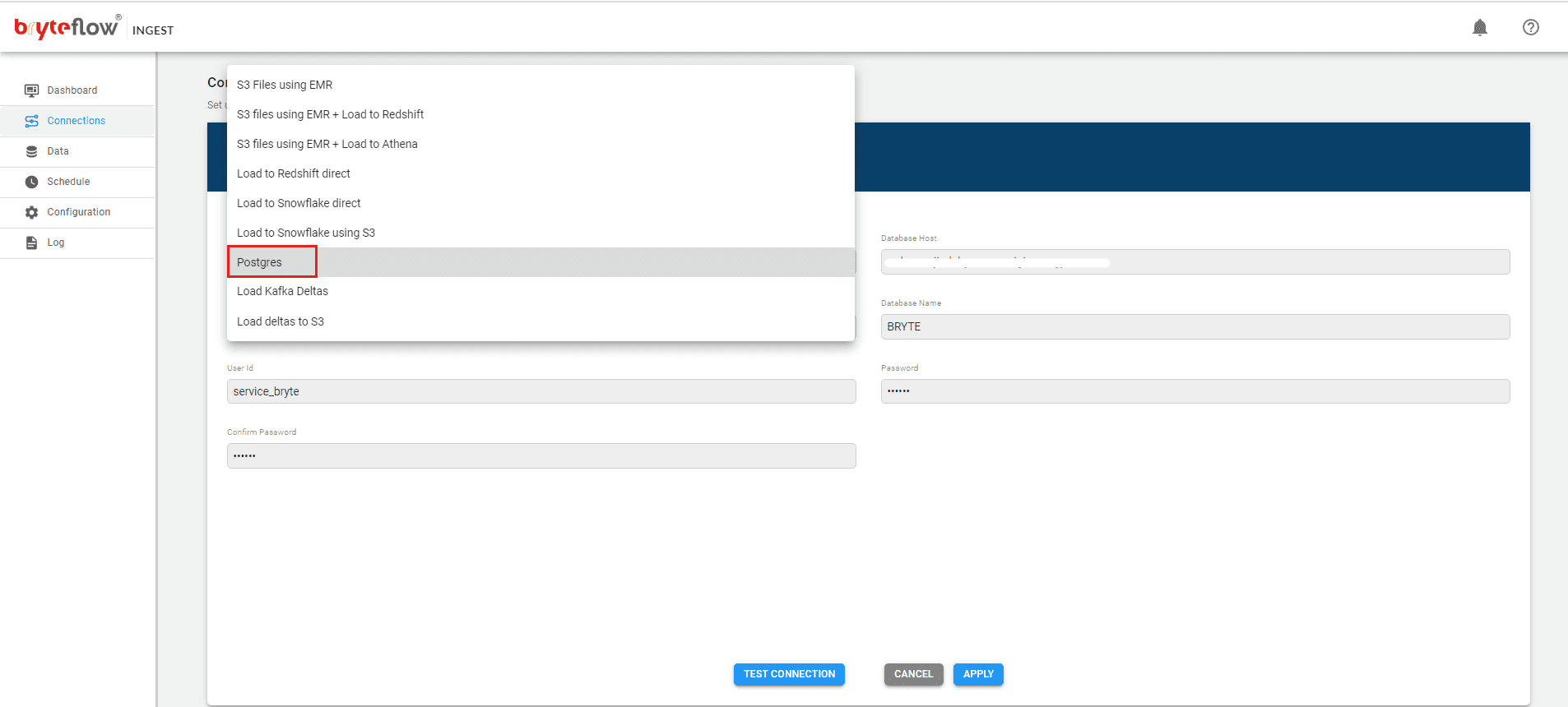
Set up destination as Postgres:
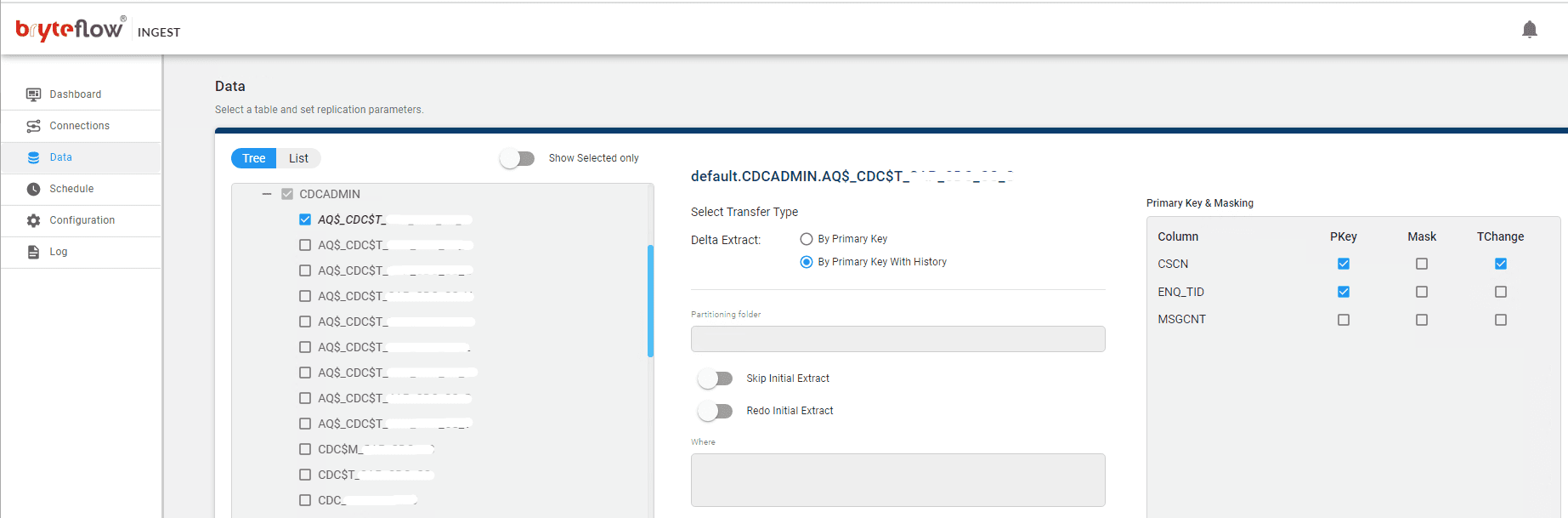
Set up the table(s) to be replicated, select the primary key and the transfer type. ‘By Primary key with History’ automatically keeps SCD Type2 history on Postgres. ‘By Primary Key’ transfer type keeps a mirror of the source, without history.
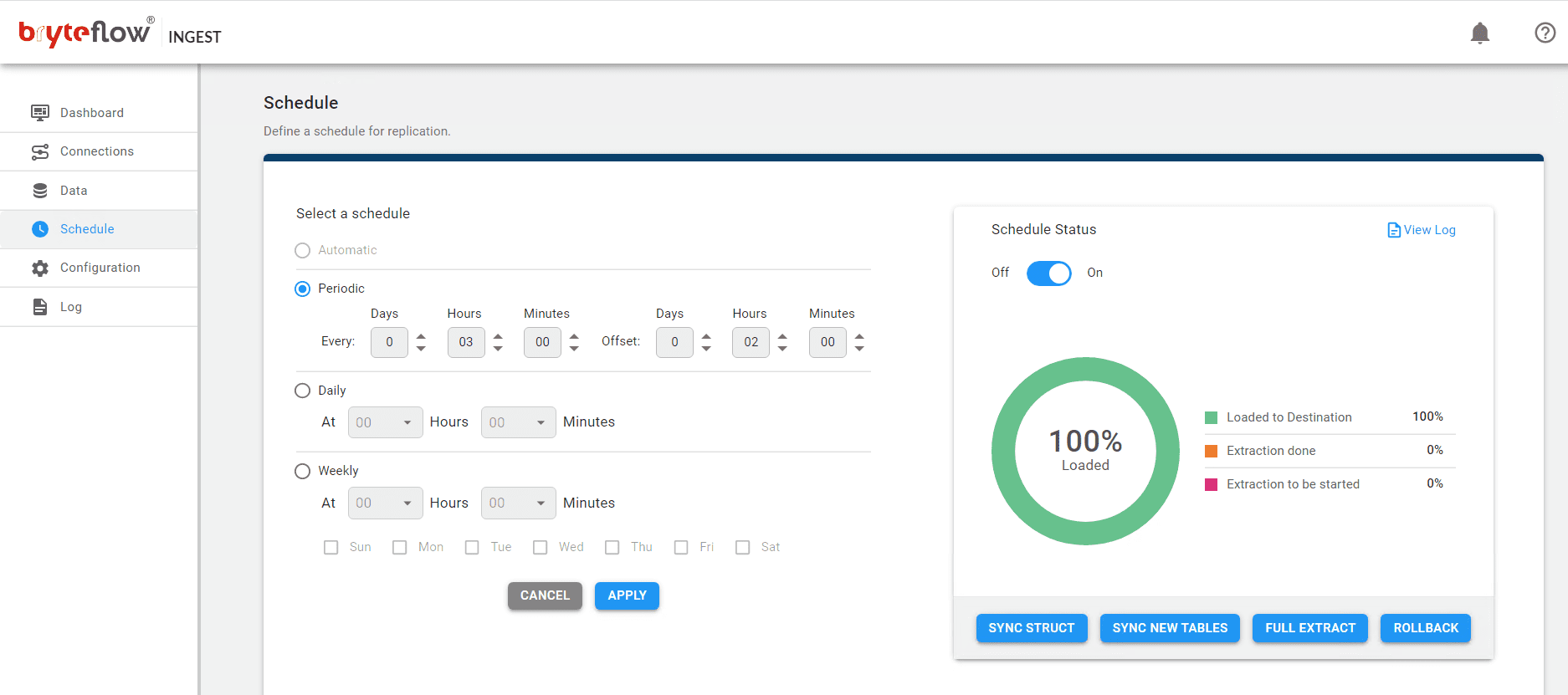
Schedule your data replication time and get your data flowing to Postgres in near real-time.
BryteFlow XL Ingest for Initial sync for really large tables
Use the BryteFlow XL Ingest software and follow these steps:
The tables can be any size, as terabytes of data can be brought across efficiently.
Configure the large table to be brought across. Then slice them
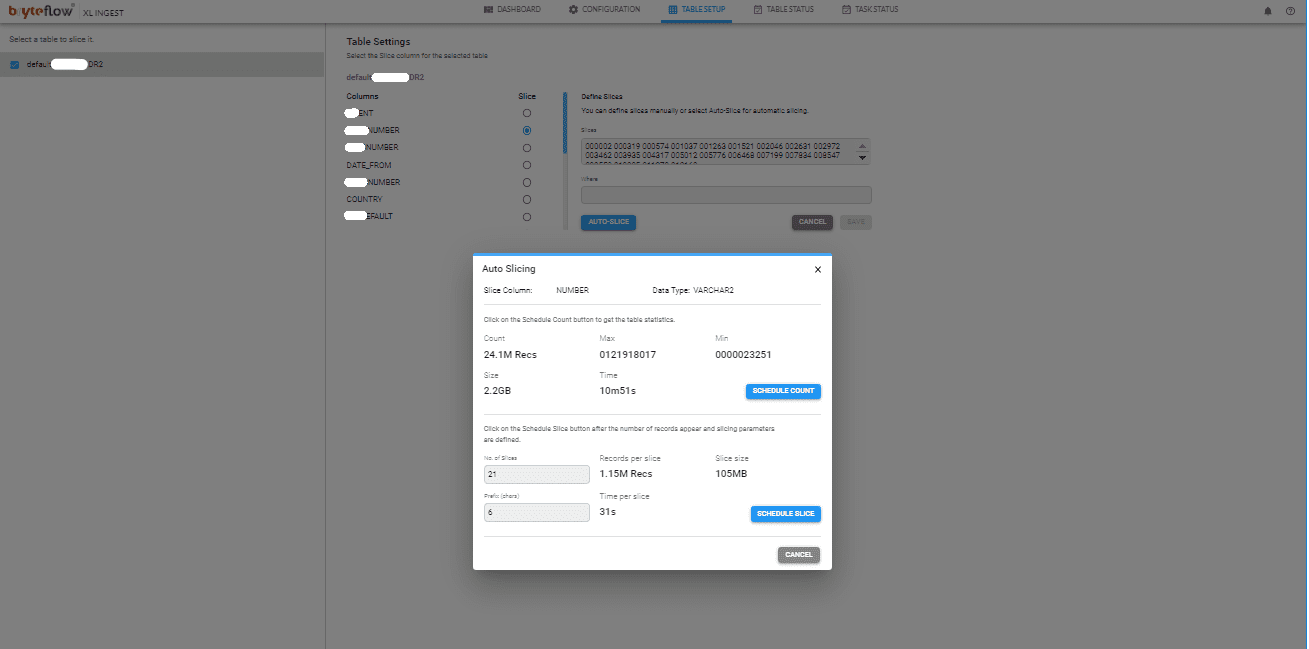
Load the slices in parallel
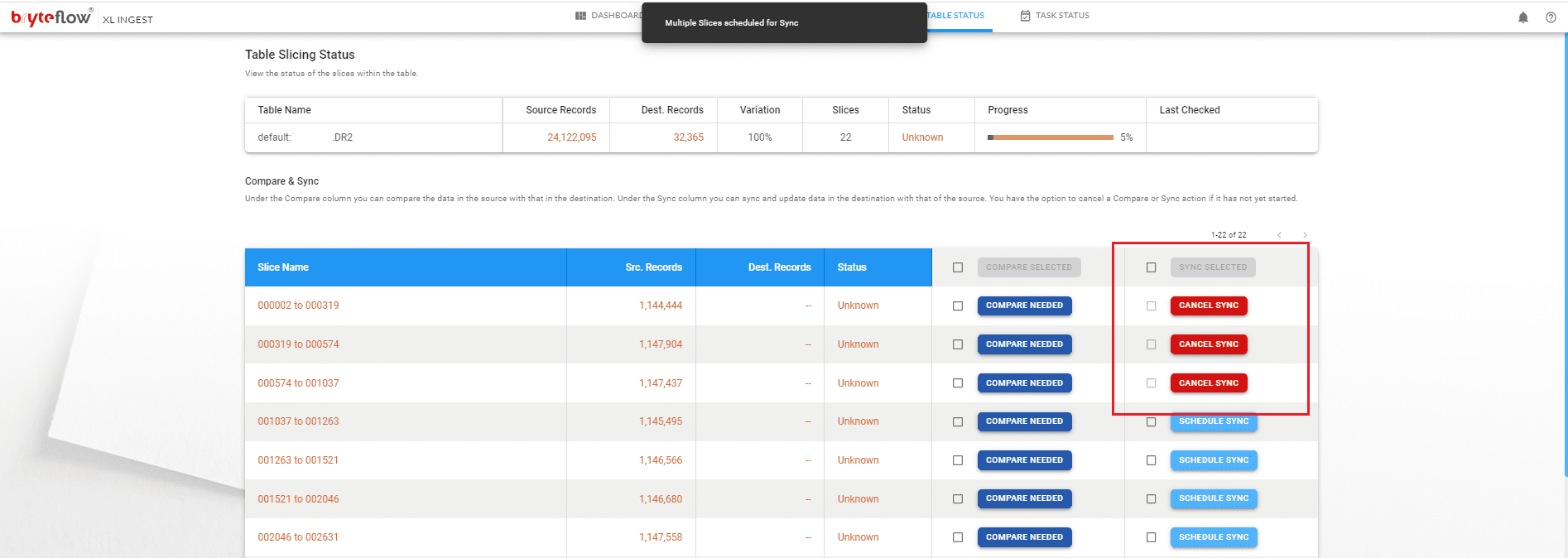
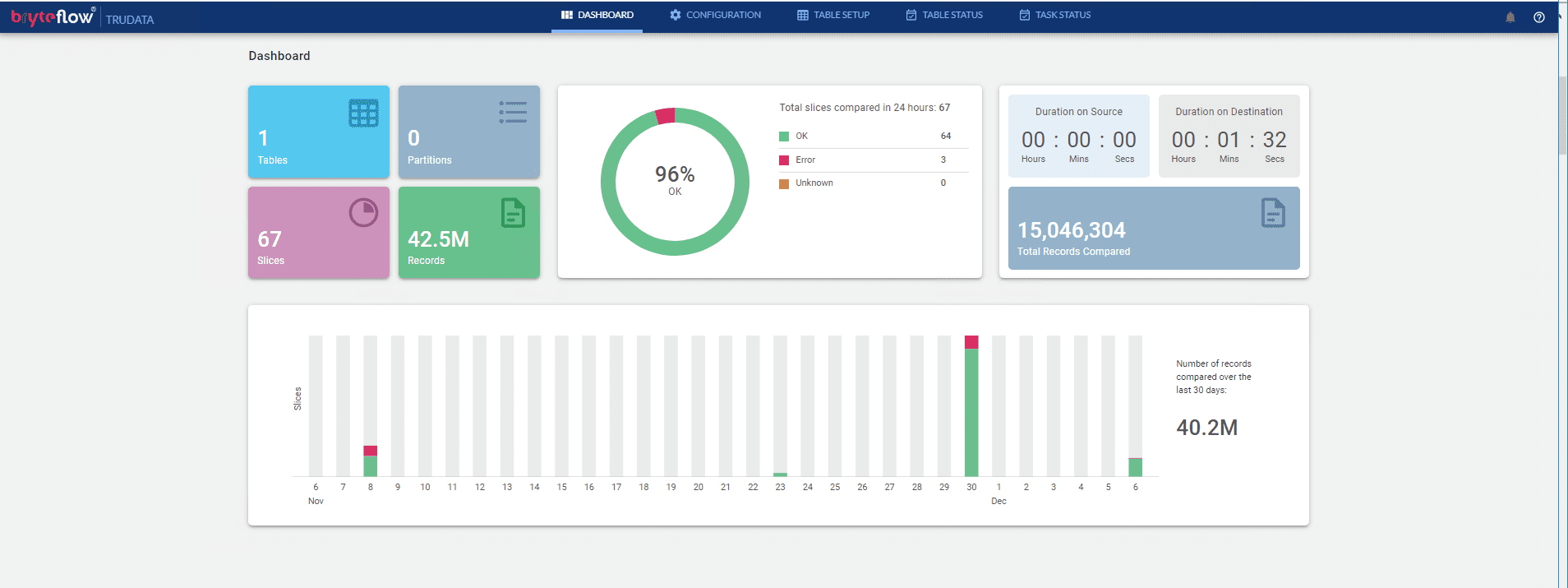
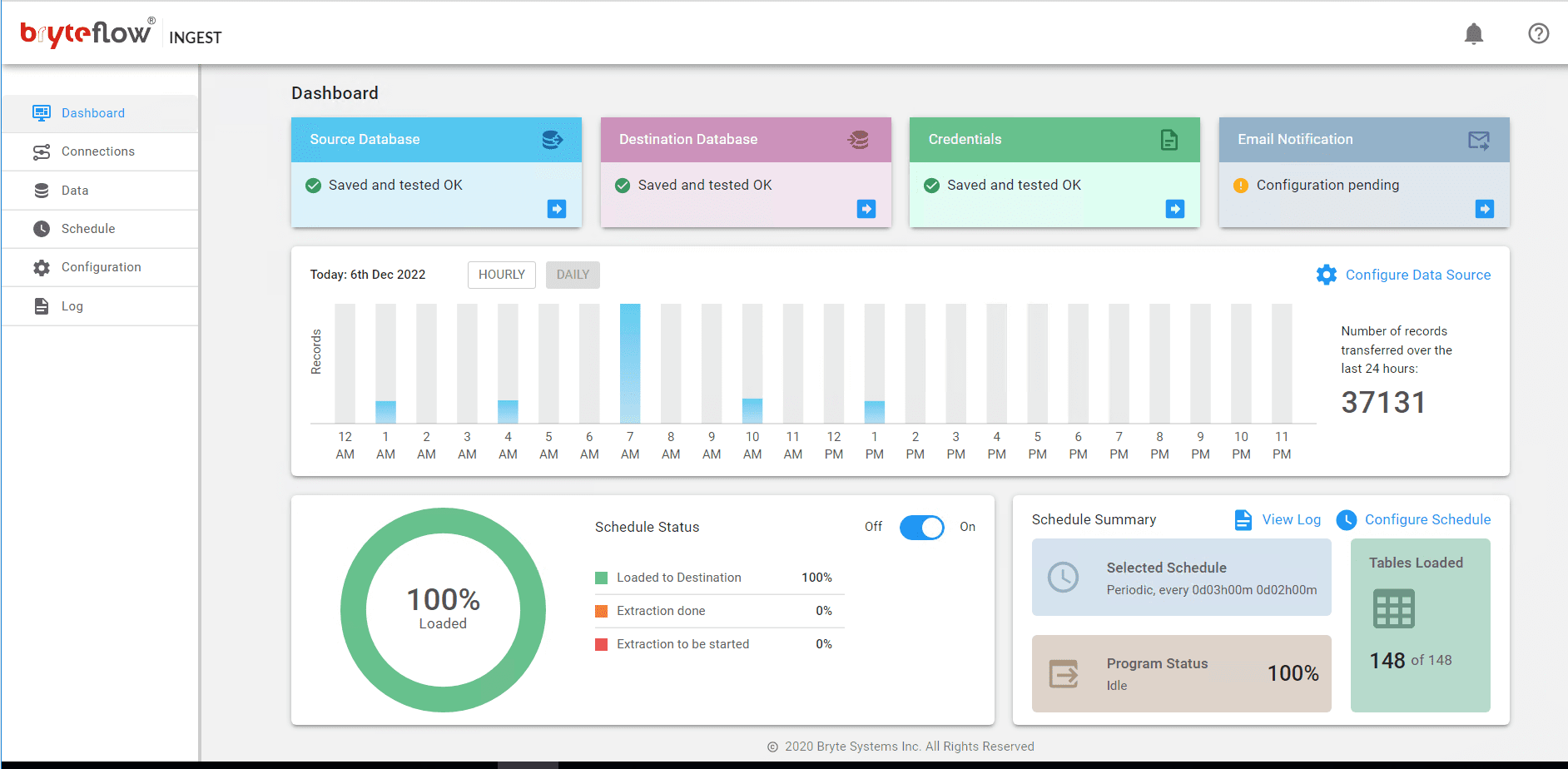
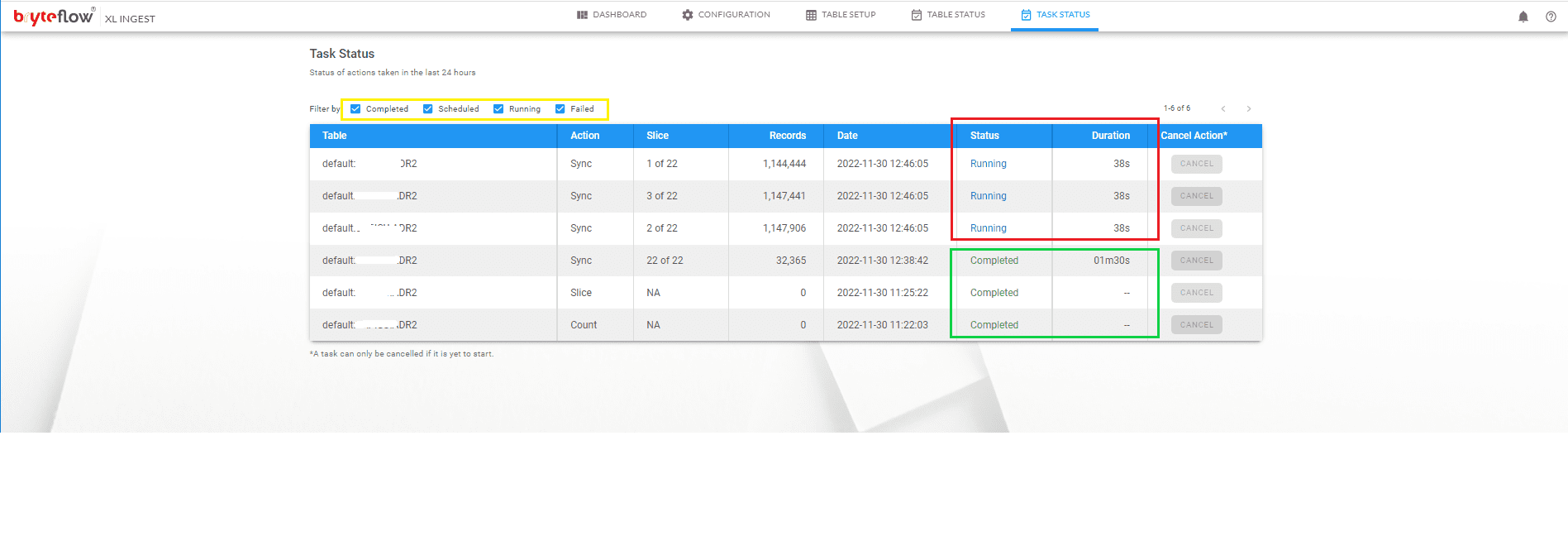
Monitor the process, as the table is brought across. The table is replicated on Postgres and is ready to use with SCD Type2 history, if configured. Overall status is displayed on the Dashboard.
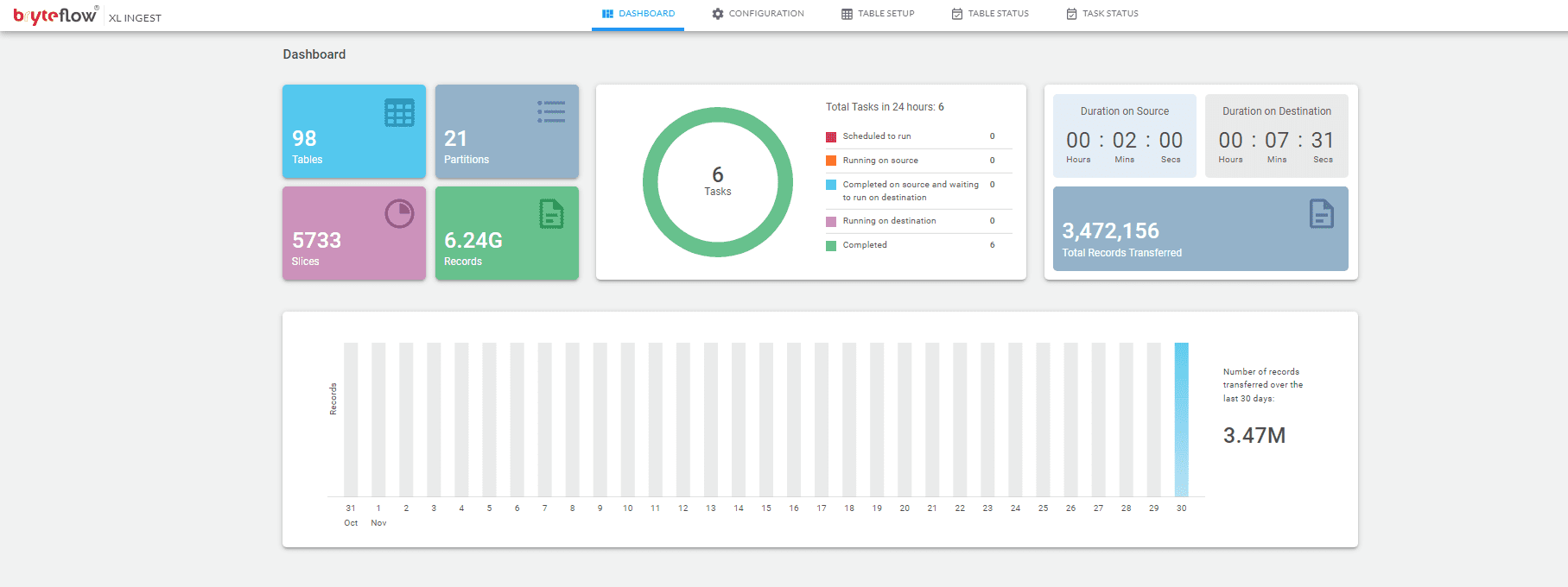
Monitor everything through Dashboard
Validating the Data using TruData
BryteFlow TruData is an automated data reconciliation and validation software that checks for completeness and accuracy of your data with row counts and columns checksum.
Use the BryteFlow TruData software and follow these steps:
Configure the tables to be brought across and then slice them
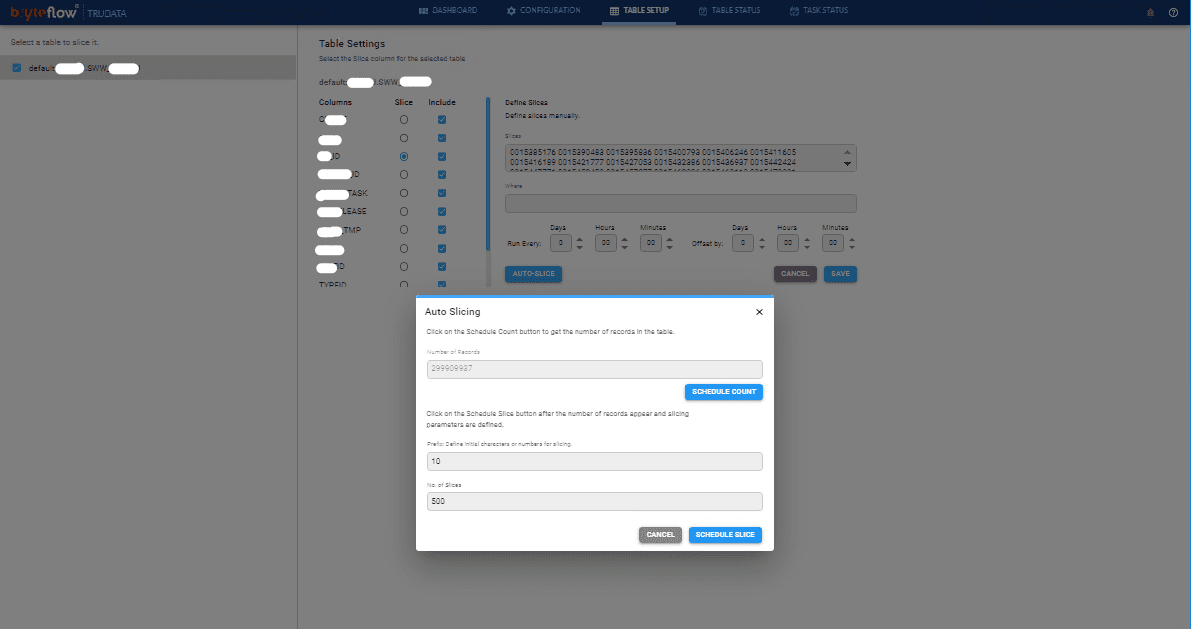
Then validate the tables which will tell you whether the data is loaded correctly or not
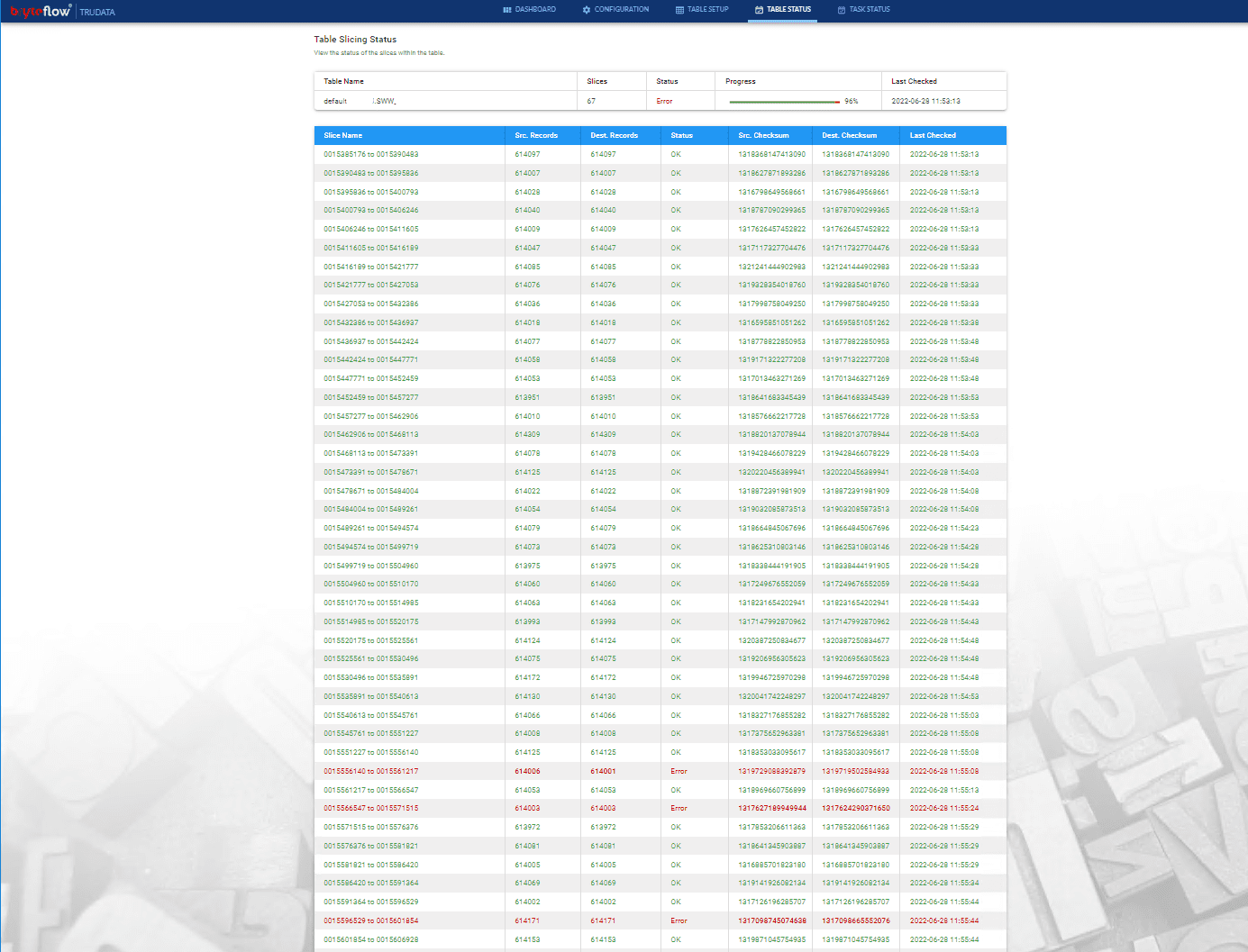
Monitor the overall performance through the Dashboard.