Kafka Connections
Kafka CDC for Kafka Data Streaming with BryteFlow
About Kafka Data Streaming
When you have petabyte-scale data volumes that need to be processed in real-time, Kafka is what you need. Apache Kafka is an open-source software built to process real-time data streams. Kafka collects, stores, processes, and analyzes huge volumes of streaming data. It can handle thousands of messages and events per second. Kafka use cases include creation of data pipelines, connecting and using real-time data streams, multi-source data integration and enabling operational metrics. Apache Kafka has a well-deserved reputation for low latency, high throughput, fault tolerance and superb performance. Kafka users can analyze and visualize data as it flows through Kafka for timely insights. What is Apache Kafka and how to install it
Ingesting Data into Kafka from real-time data streams
Organizations that collect and use enterprise data are turning to Apache Kafka to derive value from real-time streaming data. For Kafka to provide value, you need to ingest data into Kafka from multiple sources, prepare it for different end-users and distribute that data to various applications and platforms in the Cloud and on-premise. However, using Kafka by itself involves a lot of coding and developers’ time. Enterprises need fully managed Kafka replication solutions like BryteFlow to avoid costly coding hassles. BryteFlow is cloud-native replication software that can ingest data to Kafka from multiple sources including transactional databses like SAP, Oracle, SQL Server, Postgres, MySQL and IOT devices and Web applications to provide data that is ready to use. Extract data from SAP applications directly
Kafka Streaming is essential for Enterprise Big Data
Apache Kafka is an open-source, highly scalable event and stream processing platform rather than a destination. Kafka provides the functionality of a messaging system but with a novel design. Kafka is a distributed, partitioned, replicated commit log service. It connects to external systems via Kafka Connect for importing and exporting data and provides Kafka Streams, a library for processing Java streams. CDC to Kafka and Oracle to Kafka CDC methods
Real-time Apache Kafka CDC and Integration with BryteFlow
- Kafka CDC with low latency, log based Change Data Capture replication with minimal impact on source. Debezium CDC Explained
- BryteFlow Ingest is optimized for real-time Apache Kafka integration and data streaming. SQL Server CDC To Kafka
- No coding needed for Kafka integration, BryteFlow has a user-friendly graphical interface. ELT in Data Warehouse
- 6x faster data replication than GoldenGate – a million rows in 30 seconds. CDC Oracle to Kafka
Successful Data Ingestion (What You Need to Know)
How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
SQL Server CDC To Kafka (Unbelievably Easy New Connector)
Kafka CDC and Integration Architecture
Real-time Apache Kafka Data Integration with BryteFlow
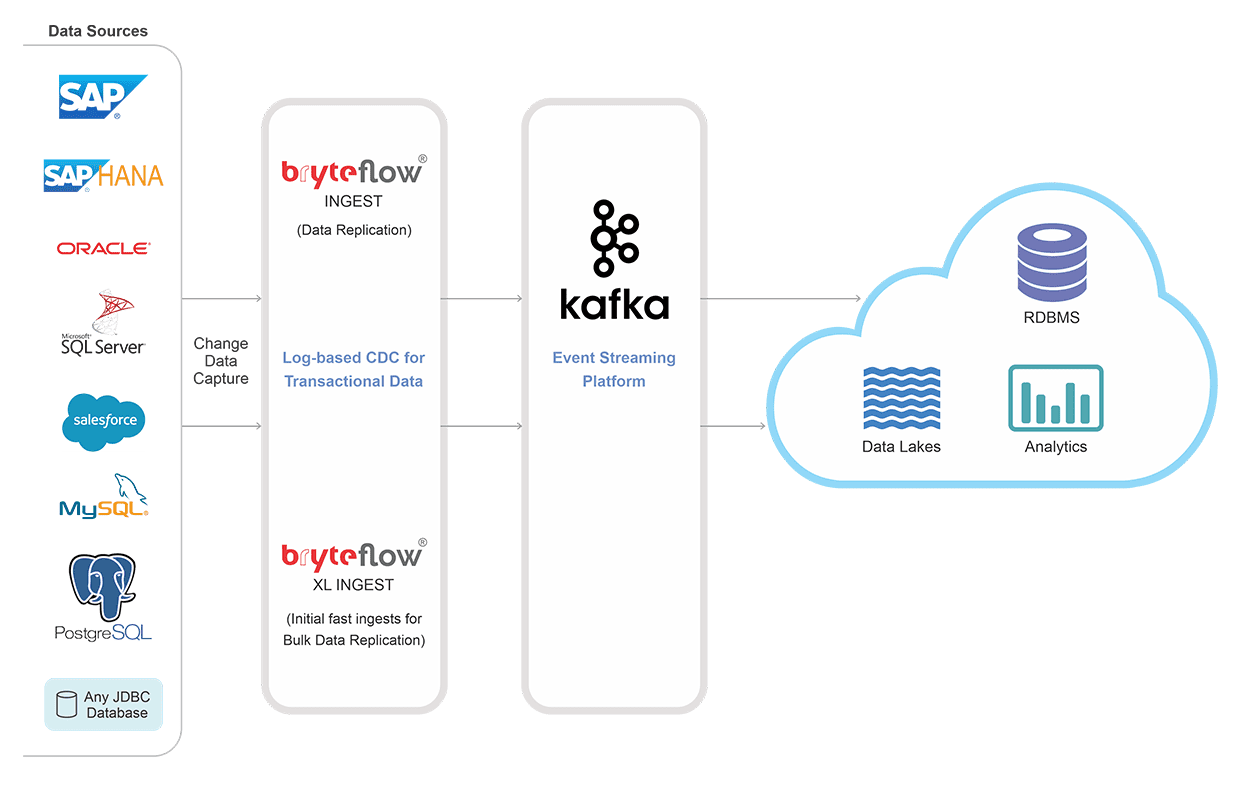
Kafka Stream Processing is Fast, Simple and No-Code with BryteFlow
BryteFlow provides log-based CDC (Change Data Capture) for Kafka stream processing. The Kafka integration process is completely automated, and provides ready-to-use data in real-time. Get a Free Trial of BryteFlow
Real-time Kafka Streaming with BryteFlow
BryteFlow functions as a Kafka replication software. It delivers large volumes of streaming data to Kafka environments in real-time through an easy-to-use UI and without any coding. Your teams can start using your real-time streaming data immediately for AI, ML and analytics. How BryteFlow Works
No Code Kafka Stream Processing
With Bryteflow you can avoid any manual coding that may be involved in building, maintaining, or deploying a Kafka streaming or analytics solution. Getting to your Kafka data is simple with BryteFlow’s graphical point-and-click interface which is essential when you need to access petabytes of big data for location tracking, from social media feeds, from sensors on IOT devices, from web and mobile applications and online transactions. All about Apache Kafka
Scalabale, Fast Data Ingestion to Kafka
BryteFlow’s data ingestion into Kafka is highly scalable and super-fast (100,000 rows in 30 seconds). This is 6x faster than GoldenGate. Debezium CDC Explained and a Great Alternative CDC Tool
Kafka CDC with BryteFlow using Log-Based Change Data Capture
BryteFlow enables real-time Kafka stream processing using low impact Kafka CDC from enterprise databases and other sources with no impact on source, and delivers every update, insert, and delete into Kafka as they happen. BryteFlow’s Kafka CDC reduces the impact on source systems drastically, by using transaction logs for Change Data Capture. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
BryteFlow CDC for Kafka is very low impact
Our Log-based CDC for Kafka streaming does not affect performance of source systems and neither do they need to be modified. Continual replication of streaming data with Kafka CDC also makes for efficient usage of network bandwidth rather than delivering data in batches. The data flow is also more granular and delivers more accurate, up-to-the-minute data from sources.
Oracle CDC (Change Data Capture): 13 Things to Know
Oracle to Kafka Replication
SAP to Kafka Replication
SQL Server to Kafka Replication
What is Apache Kafka and some Kafka Use Cases
What is Apache Kafka?
Apache Kafka is an open-source platform for distributed event streaming and processing and can handle trillions of events in a day. Kafka is optimized for ingesting and processing streaming data in real-time. Streaming data is generated by thousands of data sources and Kafka as a data stream processing platform needs to process this continuous ingestion of data both sequentially and incrementally as it happens. At its simplest, Kafka is based on the concept of a distributed commit log and was created as a messaging queue to begin with. It was created in 2008 at LinkedIn and open-sourced in 2011. Over time, Apache Kafka evolved from a messaging queue to a complete event-streaming platform.
What is Apache Kafka used for?
Apache Kafka is used by thousands of organizations including at least 80% of the Fortune 100 companies. Kafka is used to build efficient, high speed data pipelines, streaming analytics, integrating data for critical applications. It combines storage, messaging, and processing of streams. It is used by various verticals including financial services, healthcare, software, social media, logistics, transportation and more. Companies using Kafka include Airbnb, Netflix, LinkedIn, Spotify, Box, Target, Goldman Sachs, Intuit, Uber, and Cisco. With Kafka, users can publish and subscribe to streaming records, store records sequentially according to order of generation and process streams in real-time.
Apache Kafka Use Cases
- An important Apache Kafka use case is tracking user activity like purchase, registration, logins, time spent on a page, feedback, products added without purchase etc.
- Real-time processing of data is a Kafka use case that can unearth fraudulent transactions – events like a credit card being used for transactions simultaneously in different locations – this would raise a red flag leading to the card being blocked.
- Communicating between microservice architectures for e.g. Between Ordering, Payments and Confirmation is another Kafka use case. Using Kafka streaming improves application performance, making it faster.
- Kafka can be used as a central hub to read and send data from IoT sensors and devices. Many IoT devices can be configured to send data to Kafka which can be scaled up as more devices are added on. Based on real-time sensor data predictive analytics can be enabled for maintenance of equipment.
- Kafka can be used as a transport layer for raw log data. This is especially useful when you need to distribute log data for various purposes to different platforms at the same time.
Get a Free Trial of BryteFlow