Databricks Connections
No-Code Databricks ETL Tool
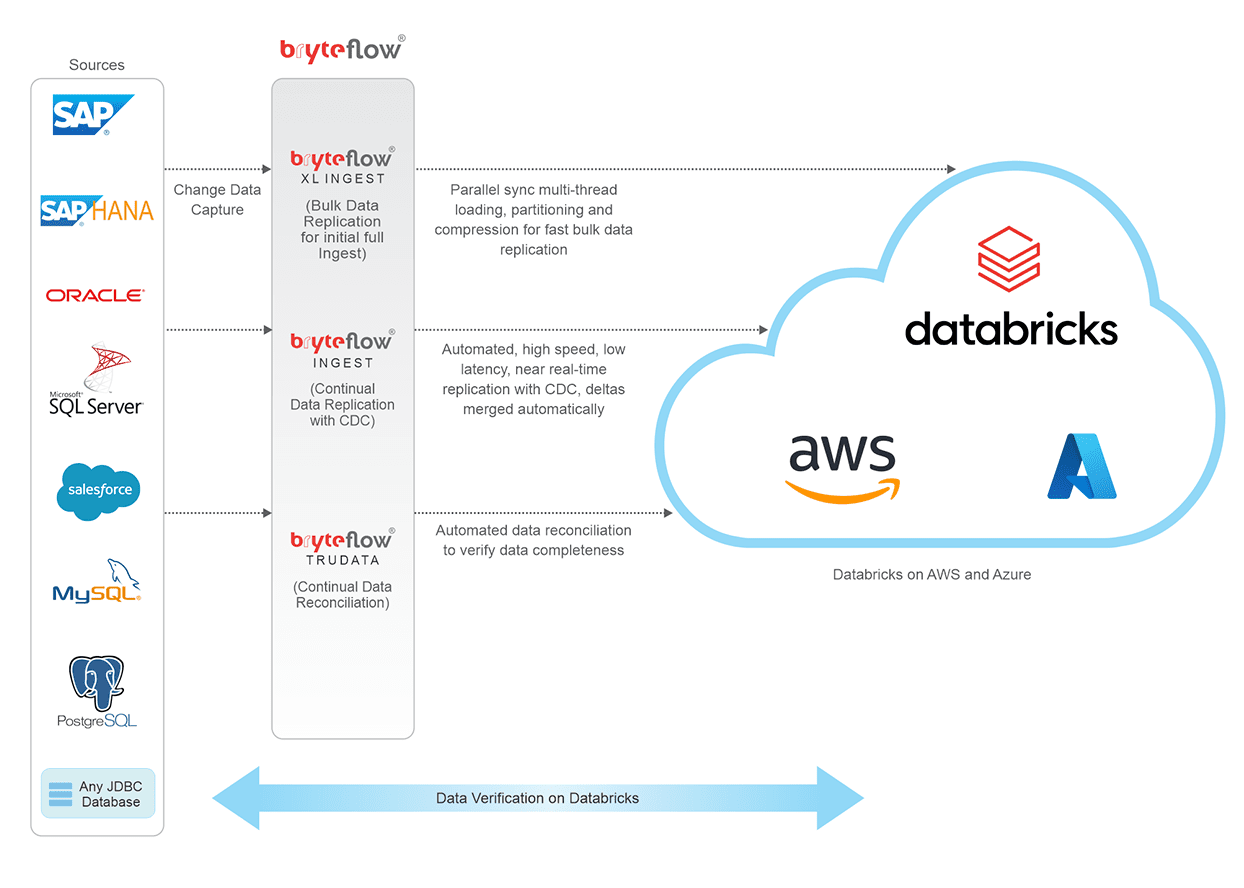
Real-time data ingestion in your Databricks Lakehouse with Bryteflow
Getting ready-to-use data to your Databricks Lakehouse has never been easier. Bryteflow extracts data from multiple sources like transactional databases and applications to your Databricks Lakehouse in completely automated mode and delivers ready to use data. Historically it has always been challenging to pull in siloed data from different sources into a data lakehouse and integrate it for Analytics, Machine Learning and BI – it usually needs some amount of custom coding. BryteFlow enables you to connect source to destination in just a couple of clicks, no coding required. You don’t need a collection of source-specific connectors or a stack of different data integration tools -just BryteFlow is enough to do the job. You can start getting delivery of data in just 2 weeks. Databricks Lakehouse and Delta Lake (A Dynamic Duo!)
BryteFlow ETLs data to Databricks on AWS, Azure and GCP using CDC
BryteFlow Ingest delivers data from sources like SAP, Oracle, SQL Server, Postgres and MySQL to the Databricks platform on Azure and AWS in real-time using log-based CDC. BryteFlow replicates initial and incremental data to Databricks with low latency and very high throughput easily transferring huge datasets in minutes (1,000,000 rows in 30 secs approx.) Every process is automated, including data extraction, CDC, DDL, schema creation, masking and SCD Type2. Your data is immediately ready to use on target for Analytics, BI and Machine Learning. Databricks vs Snowflake: 18 differences you should know
Data Integration in your Databricks Delta Lake with BryteFlow: Highlights
- BryteFlow delivers real-time data from transactional databases like SAP, Oracle, SQL Server, Postgres and MySQL to Databricks on AWS and Azure. Automating the ETL Pipeline
- BryteFlow Ingest replicates data to the Databricks Lakehouse using low impact, log-based Change Data Capture to deliver deltas in real-time, keeping data at destination continually updated with changes at source. Successful Data Ingestion (What You Need to Know)
- Our Databricks Delta Lake ETL is completely automated and has best practices built in. The initial full load of large data volumes to the Databricks Lakehouse is easy with parallel, multi-thread loading and partitioning by BryteFlow XL Ingest. Databricks vs Snowflake
- BryteFlow delivers ready-to-use data to the Databricks Delta lake with automated data conversion and compression (Parquet-snappy). ELT in Data Warehouse
- BryteFlow provides very fast replication to Databricks – approx. 1,000,000 rows in 30 seconds. Data Migration 101
- The BryteFlow SAP Data Lake Builder can ETL data directly from SAP applications with business logic intact to the Databricks Lakehouse -no coding needed.
How BryteFlow Data Replication Software Works
Databricks Lakehouse and Delta Lake (A Dynamic Duo!)
Databricks vs Snowflake: 18 differences you should know
Databricks Data Lakehouse Architecture
This technical diagram explains how BryteFlow works to integrate data on Databricks. Try BryteFlow Free
ETL Data to the Databricks Lakehouse in Real-time with BryteFlow
Build a Data Lakehouse with Databricks and BryteFlow. Access data that is ready to use for Analytics, ML and AI. Get a Free Trial of BryteFlow

Fastest Replication
1,000,000 rows in 30 secs

Data Sync with
Change Data Capture

Time to Data Delivery
is just 2 Weeks

Every Process
Automated
BryteFlow uses log-based CDC (Change Data Capture) to sync data in the Databricks Lakehouse with source
BryteFlow replicates data with log-based CDC (Change Data Capture) to deliver deltas continually to your Databricks Lakehouse from transactional databases and applications with zero impact on source systems. Learn about Oracle CDC and SQL Server CDC
Replicate data to the Databricks Delta Lake with very high throughput
BryteFlow replicates data to your Databricks Delta Lake on AWS and Azure at an approx. speed of 1,000,000 rows in 30 seconds.
2 Weeks to Delivery of Data in your Databricks Delta Lake
The BryteFlow solution can be deployed at least 25x faster than other products. You can deploy BryteFlow in one day and get data delivery in just 2 weeks, as compared to our competitors’ average of over 3 months. How BryteFlow Works
BryteFlow automates DDL in the Databricks Lakehouse
BryteFlow automates DDL (Data Definition Language) in the Databricks Lakehouse and creates tables automatically with best practices for performance, no tedious data prep required. About BryteFlow Replication
No-code Data Lake Implementation on Databricks
While doing the Databricks Data Lake implementation, there is no coding to be done for any process including data extraction, schema creation, partitioning, masking, SCD Type2 etc. Every process is automated. Databricks vs Snowflake: 18 differences you should know
Access ready to use data in your Databricks Lakehouse with out-of-the box data conversions
Get a range of data conversions out of the box with BryteFlow Ingest, including Typecasting and Data Type conversions to deliver data ready for analytical consumption in your Databricks Lakehouse. BryteFlow enables configuration of custom business logic to aggregate data from multiple applications or modules into ready inputs for AI and ML. Data Migration 101 (Process, Strategies and Tools)
Load heavy volumes of data to the Databricks Delta Lake easily
BryteFlow XL Ingest uses multi-threaded parallel loading, smart partitioning, and compression for the initial full refresh of data to your Databricks Delta Lake, followed by BryteFlow Ingest that captures incremental loads continually with log-based Change Data Capture to update data with changes at source.
Built-in resiliency and Automated Network Catchup in your Databricks Delta Lake
BryteFlow has an automatic network catch-up mode. It just resumes where it left off in case of power outages or system shutdowns when normal conditions are restored. Successful Data Ingestion (What You Need to Know)
BryteFlow ETLs data to AWS Databricks and Azure Databricks
BryteFlow delivers data in real-time to Databricks on AWS and Azure. Being a Cloud-native tool, BryteFlow has best practices built in for automated ETL to the Cloud. Databricks Lakehouse and Delta Lake
About Databricks Delta Lake
Why building a Data Lakehouse on Databricks is worth your while
-
Databricks, the unified data analytics platform
Databricks can be described as an open and unified data analytics platform for data engineering, data science, machine learning, and analytics. Databricks is a cloud – based platform centered around Spark and needs no active management. Databricks uses Apache Spark to process data and combines the scalable storage of a data lake and the analytical capabilities of a data warehouse through it’s innovative Data Lakehouse architecture. Databricks can be implemented on cloud platforms such as AWS and Azure.
-
The Databricks Delta Lake
Databricks created the innovative Delta Lake which is an open source storage layer for Spark that sits atop a data lake and enables the data lake to have many of the analytical features of traditional databases. Handling metadata, ACID transactions, enabling streaming and batch data processing, schema validation and enforcement, data versioning through transaction logs, time travel capabilities to enable rollback to a previous version, using timestamps or version number etc. It brings reliability and performance to data lakes.
-
The Databricks Lakehouse
The Delta Lake on Databricks is referred to as a Databricks Lakehouse. The Databricks Lakehouse presents a unified system that encompasses the data governance and ACID transactions of data warehouses with the cost-efficiency, scalability and flexibility of data lakes. This means the data lakehouse has data structures and data management features that were hitherto only found in a data warehouse. Users can access their data that much faster since the data is now in a single system. Business Intelligence (BI) and Machine Learning (ML) can also be easily enabled on the data. The Databricks Lakehouse has massively scalable Cloud storage and allows users to access and work their data with unlimited flexibility whenever they want.
Advantages of the Databricks Delta Lake
-
Based on Parquet and supports real-time streaming of data
The Databricks Lakehouse is built on Parquet, the open source data format. This allows the Delta Lake to experience the benefits of Parquet ike columnar storage, improved filtering performance and nested structure support. Delta Lake supports streaming real-time data so you can get fresh data updated every minute if needed. It also supports batch ingestion. Data formats -Parquet, ORC or AVRO?
-
Databricks Delta Lake data has quality and consistency
In traditional data lakes, data is often found in a corrupted state due to failure of production jobs. Also a lack of schema enforcement, multiple concurrent writes and lack of versioning lead to inconsistent, low quality data. Databricks Delta lakes or data lakehouses on the other hand, provide high quality consistent data due to schema enforcement, metadata and versioning features.
-
Delta Lake makes metadata available
The Delta Lake layer allows data lakes to store metadata in a layer on top of the data in open file formats. This means tracking of files within different table versions is possible, enabling ACID-compliant transactions. The availability of metadata layers allows for other features like streaming I/O support, doing away for the need of event streaming platforms such as Kafka. Users can also time travel to access older table versions, enforce schema and evolution and validate data.
-
A Databricks Lakehouse means better performance
The data lakehouse is fast when it comes to query performance. What sets the data lakehouse apart is the availability of metadata layers, new designs of query engines that enable high performance SQL-based queries, optimized access for data science and machine learning software and easy handling of very large datasets.