
In this blog post, we will explore what source to target mapping is, its significance, use cases, and data mapping techniques. Users typically have the choice to either manually map data or use automated tools. Bryteflow is one such tool which automates source to target mapping as part of the ingestion and data integration process. Discover how source to target mapping works and understand why it plays a vital role in maintaining data quality.
Quick Links
- Source to Target Mapping – What it is
- Why is Source to Target Data Mapping necessary?
- Example of Source to Target Mapping
- Where is Source to Target Mapping used?
- How Source to Target Mapping Works: The Steps
- Common Source to Target Mapping Techniques
- The Source to Target Mapping Template
- How BryteFlow Automates Source to Target Mapping
Source to Target Mapping – What it is
Source to target mapping is a blueprint or process that defines rules and instructions that dictate how data from a source system should be converted and adapted to meet the requirements of a target system. It establishes the link between data sources and their corresponding destinations in data integration or migration projects. The data mapping process entails identifying source data elements, understanding their structure, and specifying any necessary transformations to ensure they align with the structure and content needed in the target system. Cloud Migration Challenges
Source to target mapping enables users to pinpoint specific columns or keys in the source system and map them to corresponding columns or keys in the target system. Source to target mapping also allows users to map data values in the source system to fit within the acceptable range of values in the target system. In essence, it streamlines the process of harmonizing data from one system or format to another, making data integration or migration more efficient and accurate. Zero-ETL, New Kid on the Block?
Why is source to target data mapping necessary?
Source to Target mapping is an essential part of data management, ensuring the accuracy, completeness, and consistency of data as it moves between systems. Data in source systems will be part of a particular schema which will almost certainly differ from the schema on target. Data may also be present in a specific file format which will need to be converted to a format that is accessible to users on the target database. Source to target mapping also specifies which fields the data will populate in the target database or application it moves to. Also note, every source can specify similar data points in different ways, (for e.g., a source may display the full state name e.g., ‘California’ in addresses but the target may store abbreviations i.e., ‘CA’ so, the data will need to be standardized to make sense of it. Faulty source to target mapping can have an adverse impact on business decisions, project timelines, and financial allocations. That’s why before any data analysis can take place, you need to harmonize and accurately map your data from source to target. Effective data mapping enables you to aggregate and understand data from different sources, homogenize and refine it, so it can be subjected to analytics, for enabling meaningful business insights. About Data Quality Management
Example of Source to Target Mapping
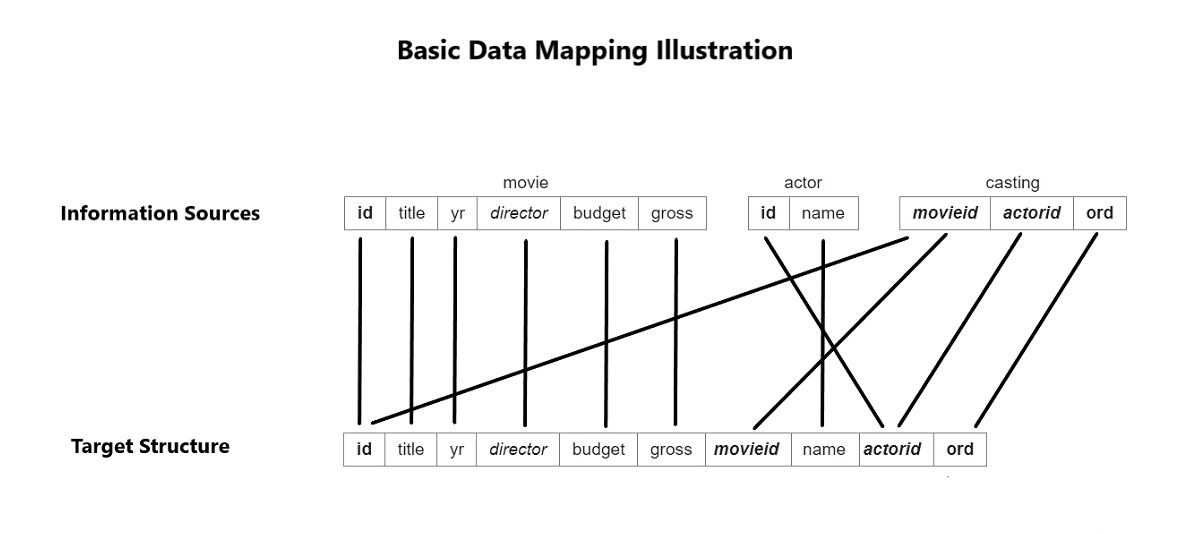
To understand data mapping from source to target, here’s an example. Let’s imagine three separate databases with data related to actors and movies. Each one has data organized into columns and fields with different structures. These are the three databases.

Each database has some similar information and some specific information. For example:
The “id” column in the Movie database and the Casting database “movieid” column have the same information.
The Gross earnings information (“gross”) is only found in the Movie database.
The name information (“name”) is only found in the Actor database.
By merging the three databases into a data warehouse allows the data to be queried like a single database. A data map is required to clarify where the information overlaps. Also, you need to define which database’s data from which database should be used in cases of duplicate data and how new information should be handled.
The graphic below is a basic data map for the movie and actor databases. The connecting lines indicate the mapping of the data sources to the target schema.
Source
Where is Source to Target Mapping used?
Source to target mapping is primarily used in 3 main processes.
- Data Migration
- Data Integration
- Data Transformation
Data Migration
Data migration refers to the process of relocating data from one system to another. Its primary purpose is to ensure that multiple systems have identical copies of the same data. While this may increase storage requirements for the data, it enhances its accessibility and reduces the strain on an individual system. The initial step in data migration involves data mapping, where attributes from the data source are matched with corresponding attributes in the destination system. This mapping facilitates the smooth transfer of data between various storage systems and computing environments. Automating Data Pipelines
Data Integration for the Data Warehouse
Data integration involves the regular transfer of data from one system to another, typically from operational databases to data warehouses. Its primary goal is to combine and centralize data from multiple sources and provide a unified view in a destination system, so the data can be queried and analyzed. An important element of successful data integration is data mapping, which defines the connections between the source data and the data warehouse’s target tables or schemas. This mapping provides instructions on how multiple data sources intersect, handling of duplicate data, and more. Successful Data Ingestion (What You Need to Know)
Data Transformation
In the data transformation process, data is converted from its source format into the format required on target. This encompasses a range of operations such as changing data types, enriching data, deleting nulls or duplicates, and aggregating data, among others. Data mapping, the primary step in data transformation, defines how data should be mapped, modified, joined, filtered, or aggregated to meet the requirements of the destination system. Data mapping includes transformation formulas that define how the data should be prepared to deliver it in the right format for analytics. ELT on Snowflake
How Source to Target Mapping Works: The Steps
When transferring data between two systems, matching schema between the source and target systems is nearly impossible. This task becomes a lot more challenging when data must be consolidated from diverse data sources, each characterized by different schemas. Therefore, a mechanism is needed to establish mappings between attributes in the source system and their counterparts in the target system.
The Source to Target Mapping process includes several steps. An automated data mapping tool can make this process much easier (BryteFlow provides automated data mapping, creating tables and schema automatically on destination).
Source to Target Mapping Steps
Source to Target Mapping Step 1: Identify the Data Sources
Before starting data collection, determine the sources from which you will extract data. The initial step in data mapping would be to define the data that needs to be restructured or moved. This includes tables, fields within tables and the required format of the field after being moved. A helpful practice is to create a data mapping template outlining the expected mapping structure. You should also consider the frequency at which data integration will occur. For integrations that are large and frequent, an automated data mapping tool will make sense. Zero-ETL, New Kid on the Block?
Source to Target Mapping Step 2: Understand the Data Formats
After identifying your data sources, it’s important to grasp the nature of the data formats you’ll encounter. Dealing with unstructured and hierarchical data formats can lead to complexity in the data mapping process. To enhance your data mapping efforts, it’s essential to have a clear understanding of both the source and target database or system structures. Valuable aids in this regard include Entity-Relationship Diagrams (ERD), database schemas, system access details, and database access credentials. These resources will greatly assist in achieving a smooth and accurate data mapping process. How to choose between Parquet, Avro or ORC?
Source to Target Mapping Step 3: Identify the fields for mapping
When it comes to field mapping, particularly in the context of data integration, one of the key considerations should be the number of data sources you have. Do the source and target fields align? Which data needs to be combined, how often will the integration happen, what is the destination format and which file formats will need conversion? Should you move all the data or only what is essential for your objective? All these decisions will need to be taken.
Source to Target Mapping Step 4: Specify Standard Naming Conventions
After determining the data fields for mapping, you need to identify the data format for each field and record this in a data mapping document. Then determine the target format. For e.g. If the source has a date format of MM/DD/YYYY but the target database takes DD/MM/YY, you will need to specify this in the document so the conditions for the final format are clear. Consistency in naming and data type formats is of utmost importance when mapping data from multiple sources. Managing Data Quality
Source to Target Mapping Step 5: Create Data Mapping Flows
After establishing naming conventions, the next step involves data mapping. Data flows must be identified and mapped, and source fields need to be matched to destination fields to align them. In a manual process, logs need to be maintained, and process needs to be monitored to prevent bottlenecks and glitches. Mapping for integration into a data warehouse may call for some denormalization of data as the process is more complex, and may attract errors. Automated data mapping tools may help here. BryteFlow automates data mapping while replicating data. How to make CDC Automation easy
Source to Target Mapping Step 6: Set Data Transformation Rules
This step examines the conversion of data from source format into a format compatible with the destination system while ensuring consistency. Given the likelihood of non-standardized and diverse data formats, data transformation becomes essential. It’s vital to establish transformation rules or logic to guide the process. Data mappings can include transformation tasks like:
- Joiner transformation (combining data from different sources).
- Router transformation (moving the data according to the data direction or defined target criteria).
- Lookup transformation (finding specific values in a row, flat files, tables, flat files etc.)
- Filter transformation (refining data according to query). Only selected information is pushed to the target.
- Data masking transformation (hiding or encrypting confidential data as it passes through the data pipeline).
- Expression transformation (calculating values from data).
A single mapping can have multiple transformations applied and the data is processed as per the sequence defined in the workflow. Many transformation rules can be combined in a Mapplet and reused for convenience.
Source to Target Mapping Step 7: Test and Deploy the Data Mapping
After completing the foundational steps, the next phase involves testing the process using sample data sources. This step ensures that the correct data attributes are accurately mapped to the destination system in their proper format. This not only validates that the process is on the right track, but also saves considerable time as compared to migrating the entire dataset without prior testing, and subsequently spending a large amount of time fixing any issues that may arise. After successful testing, the data mapping can be deployed on the live data.
Source to Target Mapping Step 8: Maintain and Update the Data Map
In the case of ongoing data integration when new sources are added, or when there are changes at source, the source to target map will need to be updated and changed. This would be needed even if the target requirements change. Think of a data map as a work in progress.
Common Source to Target Data Mapping Techniques
The choice of technique depends largely on your specific needs, primarily determined by the nature and quantity of data you’re dealing with. In source to target data mapping, three primary methods are commonly employed:
- Manual Source to Target Mapping
- Semi-Automated Source to Target Mapping
- Automated Source to Target Mapping
Manual Source to Target Mapping
Manual data mapping involves the labor-intensive task of hand-coding and manually connecting each data source field to its corresponding field at destination. To execute manual data mapping, you’ll require skilled coders and data mappers who will painstakingly code and map your data sources. While this method grants you complete control and customization over your mappings, it’s a laborious and expensive exercise that requires the involvement of professionals. It necessitates developers to manually establish connections between the source and destination systems, making it suitable only for small integrations with few sources and minimal data volume. Manual processes must also deal with the issue of human error. This can lead to delays and impose a substantial burden on the IT team. Considering the vast volume of data generated by companies today, the manual method is not an optimal choice.
Semi-automated Source to Target Mapping
Semi-automated data mapping is also called Schema Mapping and is a hybrid process that combines automated and manual data mapping. In this process developers use software that creates connections between various sources and their targets. After this is done, developers manually validate the system and make the needed adjustments. This is good when working with small amounts of data for basic data integrations, data migrations, or transformations. Data transformation with BryteFlow Blend
Automated Source to Target Mapping
Automated data mapping can be done by using specialized, often zero-code tools designed to effortlessly extract data from multiple sources, perform necessary transformations, and seamlessly load it into the desired destination without the need for manual intervention.
When it comes to integrating data into a data warehouse, you need to consider today’s growing number of data sources and ever-increasing volumes of data. Under these circumstances, automated data mapping offers scalability, speed and convenience. It can simply match the new data to your existing schema automatically. Automated tools can extract data from multiple inputs seamlessly. You will not need technical experts to run the process. You can easily understand the data flows with engaging visuals and the software typically offers an intuitive drag-and-drop mapping interface. You can even receive alerts for issues that may develop, while also helping to troubleshoot problems.
The Source to Target Mapping Template
A data mapping template can be invaluable while mapping and moving your data. It helps track variables and can serve as a guidepost on how to translate values from the source to the target.
If you would like to create a data mapping template, here’s how you go about it and what you should include. Keep in mind the data mapping template will be used for a long time, so it should have all the relevant information about ingestion, transformation, analytics in it and this must be maintained and updated if there are changes in the future. A data mapping template can also help while troubleshooting and onboarding and training of new team members. Data Ingestion with BryteFlow Ingest
Your source to target data mapping template should include these details:
- Source database name (where the data originates)
- Target database name (where the data is headed)
- Columns and values being mapped
- Variable data descriptions and data rule definitions
- Prescribed format for the data after transformation
- Triggers to initiate data transfer or data integration
- Automation documentation (when and how it will run, the outcome needed, potential failure points)
Please note for large datasets, using an automated data mapping tool is advisable. However, a data mapping template can help you get a better understanding of your data and provide a data management framework for all involved.
How BryteFlow automates source to target mapping
BryteFlow is a powerful replication and data integration tool that includes automated data mapping among its many attributes. It creates tables and schema automatically on the destination, essentially mirroring the source schema. It provides multiple data type conversions out-of-the-box and delivers data on target that can be used immediately for analytics or machine learning models. About Postgres CDC
BryteFlow is a completely automated, no-code tool that delivers data in real-time from transactional databases like SAP, Oracle, PostgreSQL, SingleStore, MySQL and SQL Server to on-premise and Cloud destinations like Amazon S3, Amazon Redshift, Snowflake, Azure Synapse, Azure Data Lake 2, PostgreSQL, Google BigQuery, SQL Server, Teradata, Kafka and Databricks.
BryteFlow Highlights
- BryteFlow syncs data with source using automated, log-based Change Data Capture, the CDC replication does not impact source systems.
- BryteFlow XL Ingest loads petabytes of data in minutes with parallel, multi-threaded loading and automated partitioning and compression.
- BryteFlow can automate CDC from multi-tenant SQL Server databases easily. About SQL Server CDC
- Zero coding for any process including data extraction, CDC, schema and table creation, DDL, merging, masking or SCD type 2 history. About Oracle CDC
- Point-and-click user-friendly interface for data ingestion. About BryteFlow Ingest
- Reconciles data automatically with row counts and columns checksum with BryteFlow TruData
- High availability, very low latency and high throughput – approx. 1,000,000 rows in 30 seconds. BryteFlow as an alternative to Matillion and Fivetran
- Data is ready-to-use on the destination and can be queried immediately with BI tools of your choice. Successful Data Ingestion (What You Need to Know)
- Automated network catch-up feature allows the software to resume where it left off, when normal conditions are restored.
Contact us for a Demo or a Free POC of BryteFlow




