
This blog talks about Oracle DB and the Databricks platform, and the reasons it makes sense to connect Oracle to Databricks to transfer data. The blog also discusses approaches for Oracle Databricks migration and presents three ways to do so. These include using Databricks’ native tools, a manual method to convert data to CSV and using the Databricks Add Data UI to load data, and by using BryteFlow as a third-party, no-code CDC tool to connect Databricks to Oracle DB. BryteFlow for Oracle CDC Replication
Quick Links
- What is Oracle Database?
- What is Databricks?
- Why move data from Oracle to Databricks?
- How to connect from Oracle Database to Databricks for loading data
- Different Methods for Connecting Oracle to Databricks
- Databricks’ Native Tools for Loading Data from Oracle Database
1.1 Delta Live Tables (DLT)
1.2 Copy Into Statement
1.3 Auto Loader - Connect Oracle Database to Databricks Manually, using DBeaver and Add Data UI to Load Data
- BryteFlow as a third-party CDC tool to connect and transfer data from Oracle DB to Databricks
- Databricks’ Native Tools for Loading Data from Oracle Database
- BryteFlow as an Oracle Databricks Connector and Replication Tool
What is Oracle Database?
Oracle Database is a highly scalable Cloud-based relational database system, offering comprehensive applications and services. It is favored by enterprises for its ability to handle large data volumes and diverse workloads. Operating across various platforms including Windows, UNIX, Linux, and macOS, it employs SQL as its query language. Oracle’s deployment options range from on-premise installations to managed Cloud solutions. It pioneered Enterprise Grid Computing, optimizing resource management for cost-effectiveness and flexibility. By leveraging grid computing principles, Oracle ensures robustness, affordability, and high-quality service, delivering centralized management, strong security, universal access, and potent development tools to its users. Oracle CDC (Change Data Capture): 13 Things to Know
Oracle’s array of features serves as a cornerstone for enterprise technology, providing many functionalities for use. These features have proven instrumental for both large corporations and smaller enterprises in creating robust applications and services. Now we will explore these features in detail.
- Data Analysis Tools: Analytical computations on business data are expedited through Oracle Advanced Analytics and OLAP (Oracle Analytic Processing) solutions. Oracle Replication in Real Time, Step by Step
- Accessibility: Through technologies like Real Application Clusters (RAC), Data Guard, and Golden Gate, Oracle ensures constant availability, even during planned or unplanned downtimes.
- Seamless Connectivity: Communication between applications on different platforms is simplified through Oracle’s native networking stack. Oracle to SQL Server Migration: Reasons, Challenges and Tools
- Expandability: Oracle’s scalability is assured with features like Real Application Clusters (RAC) and advanced Portability, accommodating various application needs and usage levels. Oracle CDC (Change Data Capture): 13 Things to Know
- Interoperability: Oracle seamlessly integrates across all operating systems (OS), including Windows, macOS, and Linux. Oracle to Postgres Migration (The Whys and Hows)
- Conforming to ACID Principles: With ACID (Atomicity, Consistency, Isolation, and Durability) properties, Oracle DB ensures transaction integrity.
- Simultaneous Processing: Oracle supports concurrent processing, enabling multiple applications to run simultaneously and serve multiple users concurrently. Kafka CDC Explained and Oracle to Kafka CDC Methods
- Networked Architecture: Utilizing a client/server architecture, Oracle Database divides processing between client and server applications while maintaining data consistency and transparency, akin to non-distributed systems.
- Data Protection and Restoration: Oracle’s robust backup and recovery capabilities safeguard against data loss or technical failures, with its RAC architecture ensuring comprehensive backup. Oracle Replication in Real Time, Step by Step
- Efficiency: Performance optimization is facilitated through tools such as Oracle Real Application Testing, Oracle Database In-Memory, and Oracle Advanced Compression, enhancing query execution and data retrieval speed. Oracle to Snowflake: Everything You Need to Know
What is Databricks?
Databricks is a unified Cloud-based platform that combines data science, machine learning, analytics, and data engineering capabilities, along with reporting and business intelligence tools. Compatible with major Cloud providers like Google Cloud, Microsoft Azure, and AWS, it offers scalability and cost-effectiveness. The team that created Apache Spark at UC Berkeley, also founded Databricks in 2013. CDC to Databricks with BryteFlow
Databricks supports multiple programming languages and is suitable for big data environments, enabling organizations to derive insights, build applications, and make data-driven decisions efficiently. With its Lakehouse architecture, it merges the flexibility of a data lake with the management features of a data warehouse. Databricks excels in simplifying data engineering workflows, machine learning modeling, analytics, and visualization, while also emphasizing security and governance in distributed Cloud computing environments. Integrated collaborative features cater to the needs of diverse users, including business analysts, data scientists, and engineers, across various industries. Databricks Lakehouse and Delta Lake (A Dynamic Duo!)
Databricks offers exceptional scalability and cost-effectiveness. Providing a collaborative and interactive workspace, Databricks supports various programming languages, including Python, R, SQL, and Scala. Tailored for big data environments, Databricks enables enterprises to derive insights fast, develop innovative applications, and drive data-informed decisions. Connect SQL Server to Databricks (Easy Migration Method)
Databricks stands out as a comprehensive data engineering and analytics platform, highly regarded by enterprises for its robust features. Renowned among Data Analysts and Data Scientists for its capacity to manage and process vast datasets effectively, here are some of its notable features.
- Optimized Spark Engine: Databricks integrates effortlessly with various open-source libraries, enabling users to set up fully managed Apache Spark clusters quickly. With automatic updates to the latest Spark versions, Databricks ensures optimal performance and reliability without constant monitoring. Databricks vs Snowflake: 18 Differences You Should Know
- Delta Lake: Databricks features an open-source Transactional Storage Layer called the Delta Lake designed to enhance Data Lifecycle management, ensuring scalability and reliability within your Data Lake infrastructure. Connect SQL Server to Databricks (Easy Migration Method)
- Collaborative Notebooks: Equipped with preferred tools and languages, Databricks enables instant data analysis, model building, and discovery of actionable insights through collaborative notebooks. Users can code in Scala, R, SQL, or Python, fostering seamless collaboration and knowledge sharing.
- Data Sources: Databricks seamlessly connects with diverse data sources, including Cloud platforms like AWS, Azure, and Google Cloud, on-premise databases such as SQL Server, CSV, and JSON files, and extends connectivity to platforms such as MongoDB and Avro files.
- Language Support: Databricks supports multiple programming languages, including Python, Scala, R, and SQL, within the same coding environment. This versatility enables users to build algorithms efficiently, using Spark SQL for data transformation, R for visualization, and Python for performance evaluation. Data Integration on Databricks with BryteFlow
- Machine Learning: Databricks provides one-click access to preconfigured Machine Learning environments, featuring advanced frameworks like Tensorflow, Scikit-Learn, and PyTorch. Users can share experiments, manage models collaboratively, and reproduce runs from a centralized repository.
- Unified Data Platform: Databricks offers a unified data platform, consolidating all data sources into a single repository for enhanced data consistency, governance, and accessibility across various analytics and AI applications. Teams can securely access and share high-performing data through Databricks, eliminating the need for independent data sourcing. Databricks Lakehouse and Delta Lake (A Dynamic Duo!)
- Flexibility: Databricks offers flexibility by providing scalability for both small-scale tasks like development and testing, as well as large-scale operations like big data processing. It efficiently scales with every workload, from simple data pipelines to large-scale data processing. Databricks vs Snowflake: 18 Differences You Should Know
Why move data from Oracle to Databricks?
Oracle is an RDBMS and as such, its functions are mostly limited to structured data processing. Oracle DB offers support for advanced SQL functionality, PL/SQL programming language, and data warehousing, and is eminently suitable for enterprises that need high availability and performance. However, moving from Oracle to Databricks allows you to access the awesome versatility of the Databricks platform, using Apache Spark, Unity Catalog, and Delta Lake to aid in complex big data processing tasks covering Analytics, Machine Learning, and Data Engineering. Moving data to Oracle from Databricks is especially advisable if you have massive datasets to process for analytics, or if you need Oracle data for Machine Learning, AI initiatives, or other data science implementations. Databricks provides a collaborative and flexible environment to teams working on AI, ML or Analytics projects. Here are some reasons why moving from Oracle to Databricks may be worth your while.
Databricks offers high performance, scalability and distributed computing
Under the hood of Databricks is Apache Spark, a powerful distributed computing framework. Spark enables distributed data processing across multiple systems, which allows Databricks to process large datasets very fast, delivering performance as well as scalability for big data analytics and machine learning. Databricks enables the creation of new clusters, infrastructure, and addition of technologies within minutes, while Oracle DB is not as scalable in terms of computing power and may need additions to physical infrastructure especially for on-premise implementations.
Databricks supports AI and Machine Learning Applications
If you need data from Oracle DB to be used in innovative applications involving machine learning models or AI, the Databricks platform with Databricks ML allows machine learning teams to use data at scale.
Databricks ML provides a complete lifecycle for Machine Learning that covers generative AI and large language models. Databricks Runtime for Machine Learning includes libraries like Hugging Face Transformers for integrating existing pre-trained models. Users can customize LLMs (Large Language Models) for specific tasks, leveraging open-source tooling like Hugging Face and DeepSpeed for efficient training and accuracy improvements. Databricks and Delta Lake – A Dynamic Duo
Databricks supports a variety of SQL and Programming Languages
Databricks enables you to use Spark SQL and have seamless integration with programming languages like Python, Scala, and R in the same fashion you would use PL/SQL. It allows for SQL, Python, Scala, Java, and R to be used as coding languages which most data professionals are familiar with, reducing the learning curve. Connect SQL Server to Databricks (Easy Migration Method)
Databricks offers Storage and Compute Separation
Databricks may prove more affordable than Oracle since you can separate storage and compute, enabling you to create clusters easily and modify compute power fast. The clusters can be switched on and off as and when required, thus helping to control costs.
Databricks ensures portability of data with Open-Source Formats
Databricks stores data in open-source formats like Parquet and Delta, allowing data to be portable across different environments. These open-source formats provide compression to store data and their columnar structure is great for running analytical queries. Data formats supported by Databricks include Parquet, ORC, JSON, CSV, Avro, Text and Binary.
Databricks has the innovative Data Lakehouse Architecture
The Data Lakehouse architecture of Databricks combines data warehousing aspects with the benefits of a data lake. Besides storing structured data for analytics as in a warehouse, high volumes of raw, unstructured data can also be stored in different formats. Structured, semi-structured and unstructured data can be used for many different purposes like: Data Analytics and BI, ML, AI, or real-time data streaming. In contrast Oracle DB typically processes only structured data. Kafka CDC Explained and Oracle to Kafka CDC Methods
Databricks features that makes ETL easy
Databricks uses Apache Spark and Delta Lake, to make the ETL (extract, transform, load) process easy. Using SQL, Python, and Scala, users can create ETL logic and arrange scheduled job deployment effortlessly. Delta Live Tables also simplifies ETL with intelligent management of dataset dependencies and automates deployment and scaling of production infrastructure. It also helps in processing of incremental and streaming data. Connect SQL Server to Databricks (Easy Migration Method)
Databricks unlike Oracle DB is open-source and has no vendor lock-in
Databricks is open-source and provides users the liberty to select from a wide range of tools, frameworks, and libraries. This flexibility allows enterprises to select those components that are suitable for their operations. This reduces reliance on a single vendor, avoiding worries about licensing, pricing changes or potential lack of support that can disrupt operations. On the other hand, data sharing and processing with Oracle DB might involve expensive licensing and vendor lock-in. About Oracle CDC
Databricks allows for easy data sharing and governance
The Databricks platform has useful features like Delta Lake and Delta Sharing, which allow for easy data access and collaboration among teams. Databricks provides the Delta Sharing tool to share data with users who do not use Databricks. You can easily share live data in Delta Lake without copying it to another system. Recipients can connect directly to Delta Shares from systems like Pandas, Apache Spark™, Rust without needing to implement a particular compute pattern. Very large datasets can be reliably shared by using Cloud repositories like S3, ADLS and GCS. The Unity Catalog, a metadata catalog is another great feature that provides governance, helping in managing and securing access to data effectively. Databricks vs Snowflake: 18 Differences You Should Know
Databricks has Advanced Reporting and Visualization
While Oracle DB offers reporting tools, Databricks Lakehouse integrates with advanced data visualization tools like Tableau, PowerBI, and Looker, enhancing business intelligence capabilities.
Databricks allows long-term retention of data for Historical Data Exploration
Databricks Lakehouse has the capability of long-term data retention and analysis of historical trends that exceeds the limitations of Oracle DB.
How to connect from Oracle Database to Databricks for loading data
We will now discuss three methods you can use to connect Databricks with Oracle DB and transfer the data from Oracle into a Delta Lake-supported Databricks Lakehouse. The migrated data is deposited into the Delta Lake tier within Databricks.
Data Type Mapping for moving data from Oracle Database to Databricks
Before we start, you must know that Databricks has some limitations on supported data types, requiring manual adjustments to match Oracle data types for seamless connection and data loading into Databricks.
The following table displays the recommended data-type mappings for an Oracle source and a Databricks Delta target for mass ingestion from databases.
Source
| Oracle Source Data Type | Databricks Data Type |
| binary_double | double |
| binary_float | float |
| blob | binary |
| char(s byte), 1 <= size <= 2000 | string |
| char(s char), 1 <= size <= 2000 | string |
| clob | string |
| date | timestamp |
| float(precision ), 1 <= p <= 126 |
string |
| integer | string |
| long raw | binary |
| long(2147483648 byte) | string |
| nchar(s char), 1 <= size <= 2000 | string |
| nclob | string |
| number | string |
| number(*,s), -84 <= s <= 127 | string |
| number(p,s), 1 <= p <= 38, -37 <= s <= 38 | decimal(p,s), 1 <= p <= 38, 0 <= s <= 38 |
| number(p,s), 1 <= p <= 38, -84 <= s <= 127 | string |
| nvarchar2(s char), 1 <= size <= 4000 | string |
| raw(size ), 1 <= size <= 2000 |
binary |
| rowid | string |
| timestamp(precision ) with time zone, 0 <= p <= 6 |
timestamp |
| timestamp(precision ) with time zone, 7 <= p <= 9 |
string |
| timestamp(precision ), 1 <= p <= 6 |
timestamp |
| timestamp(precision ), 7 <= p <= 9 |
string |
| varchar2(s byte), 1 <= size <= 4000 | string |
| varchar2(s char), 1 <= size <= 4000 | string |
Different Methods for Connecting Oracle to Databricks
Various techniques exist for transferring Oracle data to your Databricks Lakehouse. You can opt for manual migration from Oracle to Databricks or use third-party no-code CDC tools like BryteFlow. Here we discuss some methods for moving Oracle data to Databricks. How BryteFlow Works
- Leveraging Databricks’ Native Tools for loading Oracle data to Databricks.
- Manually migrating data from Oracle to Databricks using DBeaver and Databricks Add Data UI.
- Using BryteFlow as a third-party tool to replicate data from Oracle to Databricks.
1. Databricks’ Native Tools for Loading Data from Oracle Database
1.1 Delta Live Tables (DLT)
Delta Live Tables or DLT is a declarative framework for building data processing pipelines that are reliable, maintainable, and testable. DLT can be used to perform Change Data Capture with minimal compute resources. You need to define streaming tables and materialized views that the system should create and keep updated. Delta Live Tables will manage the data transformations with queries you define for each step in the processing sequence.
Delta Live Tables handles the orchestration of tasks, managing clusters, monitoring processes, maintaining data quality, and error handling. You can use Delta Live Tables Expectations to define the data quality you expect and specify how to deal with records that do not meet the expectations. Delta Live Tables supports data uploads from any Apache Spark-supported source on Databricks. Delta Live Table Datasets consist of Streaming Tables, Materialized Views, and Views, that are maintained as a product of declarative queries.
Auto Loader functionality is available within Delta Live Tables pipelines, eliminating the need for manual schema or checkpoint location provision, as Delta Live Tables handles these configurations automatically. It extends Apache Spark Structured Streaming functionality, enabling the deployment of production-quality data pipelines with minimal Python or SQL declaration. Learn more
1.2 COPY INTO Statement
The COPY INTO statement, which is a SQL command, enables the efficient loading of data from a file location into a Delta Table, streamlining data movement and reducing the amount of code required. This operation is both re-triable and idempotent, skipping files in the source location that have already been loaded. It supports secure access methods, including the use of temporary credentials.
COPY INTO statement has file or directory filters from cloud storage repositories (e.g. S3, ADLS Gen2, ABFS, GCS, and Unity Catalog volumes) that can be easily configured. It supports multiple source file formats such as CSV, JSON, XML, Avro, ORC, Parquet, text, and binary files. COPY INTO statement is efficient, employing Exactly-once (idempotent) file processing by default, and provides target table schema inference, mapping, merging, and schema evolution.
Learn More
1.3 Auto Loader
AutoLoader is a feature in Databricks Delta Lake that automatically loads data from Cloud storage repositories such as Azure Data Lake, Amazon S3, and Google Cloud Storage to the Delta Lake. It automatically detects the presence of new files in the Cloud location and ingests them to Delta Tables, while also managing the schema evolution. AutoLoader can be configured to load data from various source formats like CSV, Parquet, JSON, and ORC. It can also handle data compression codecs such as gzip, snappy, and bzip2. This makes it ideal for handling very large datasets.
AutoLoader has a Structured Streaming source called cloudFiles. When provided an input directory path, cloudFiles automatically processes new incoming files and also has the option of processing existing directory files. It can handle both, real-time ingestion and batch processing efficiently. It supports large data volumes and is compatible with both Python and SQL within Delta Live Tables. One drawback however is that it cannot load data from on-premise sources.
AutoLoader is highly scalable and can discover millions of files easily. It also supports schema inference and evolution, by detecting schema drifts, alerting you about schema changes, thus helping to uncover lost or ignored data.
Learn More
2. Connect Oracle Database to Databricks Manually, using DBeaver and Add Data UI to Load Data
In this step-by-step guide, we demonstrate a manual approach for connecting and migrating data from Oracle to Databricks. This involves generating data in CSV files using DBeaver, and subsequently loading them into Databricks via the Add Data UI. However, it’s essential to note that potential errors may arise due to disparities in data type compatibility between the two databases.
What is DBeaver?
DBeaver is a flexible database management tool crafted for data professionals. Serving as both a SQL client and administration tool, it harnesses JDBC for relational databases and proprietary drivers for NoSQL databases. With perks such as code completion and syntax highlighting, it showcases a plug-in framework enabling tailoring of database-specific features. Built in Java on the Eclipse platform, DBeaver offers a free and open-source Community Edition licensed under the Apache License, and also an Enterprise Edition obtainable through a commercial license.
What is Add Data UI in Databricks?
The Add Data UI in Databricks is a feature within the platform’s user interface (UI) that simplifies importing data from various sources. It allows users to upload CSV, TSV, or JSON files to create or overwrite managed Delta Lake tables. While data can be uploaded to the staging area without connecting to compute resources, an active compute resource is required for previewing and configuring tables. Users can preview upto 50 rows of data during configuration. Managed table data files are stored in specified locations, requiring appropriate permissions for table creation. However, the Add Data UI has limitations, such as supporting only CSV, TSV, or JSON files, allowing upload of only 10 files at a time, with a maximum total file size of 100 MB, and restrictions on file extensions (Zip, Tar) and compressed file formats.
Here are the main steps involved in the manual migration of CSV data from Oracle Database to Databricks:
2.1 Extract Oracle data into an interim storage location using DBeaver.
2.2 Import the data into Databricks using the Add Data User Interface.
2.3 Modify the table specifications and transform the data types into the format compatible with Databricks Delta Lake.
2.1 Extract Oracle data into an interim storage location using DBeaver.
Use DBeaver to move the data to a temporary storage location before importing it into Databricks. Follow the steps below to begin the process of exporting the data:
Step 1: Open DBeaver and initiate a connection to the Oracle Database. Proceed by expanding your database schemas, locating the desired “Table” for migration, and select “Export Data.”
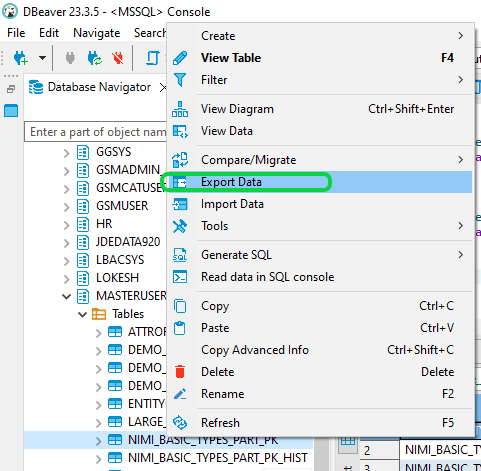
Step 2: In the “Export target” window, choose the file format option labeled “CSV”, and proceed by clicking on “Next”.
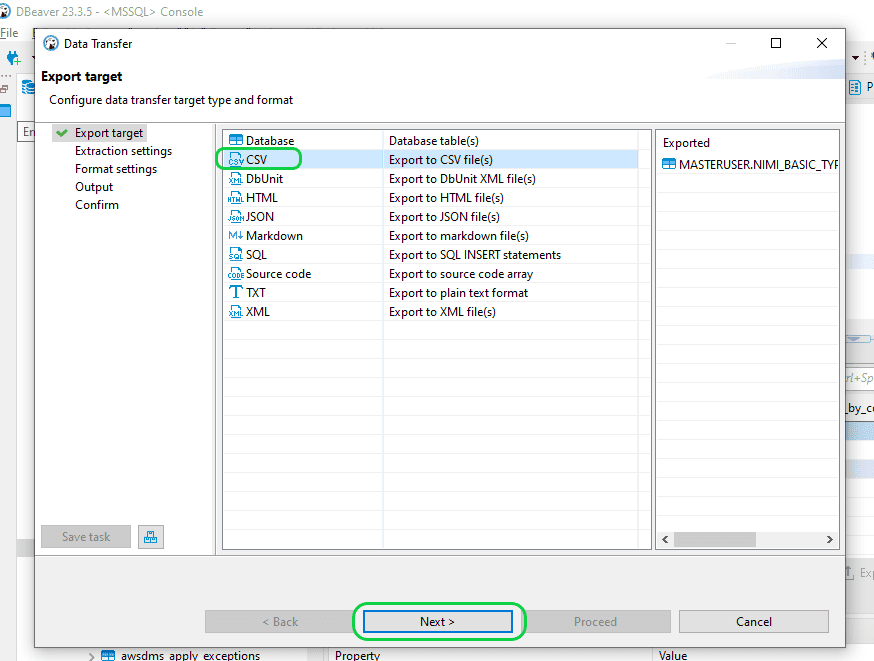
Step 3: In the “Output” window, you can specify the location for generating the output CSV file. Maintain the remaining settings unchanged and proceed by clicking on “Next”. Thereafter proceed by clicking on the “Proceed” button to generate the file.
2.2. Import the data into Databricks using the Add Data User Interface.
Step 1: Access Databricks and ensure that the cluster is active. Once Databricks is opened, navigate to “Workspaces” within the “Account Console” section.
Step 2: Next, navigate to your Workspace and create a new workspace if you don’t already have one, using your Cloud credentials.
Step 3: Then, select “Open workspace” to navigate to the real workspace.
Step 4: Next, navigate to the “New” tab and select “File upload”, which will direct you to the “Add Data” window.
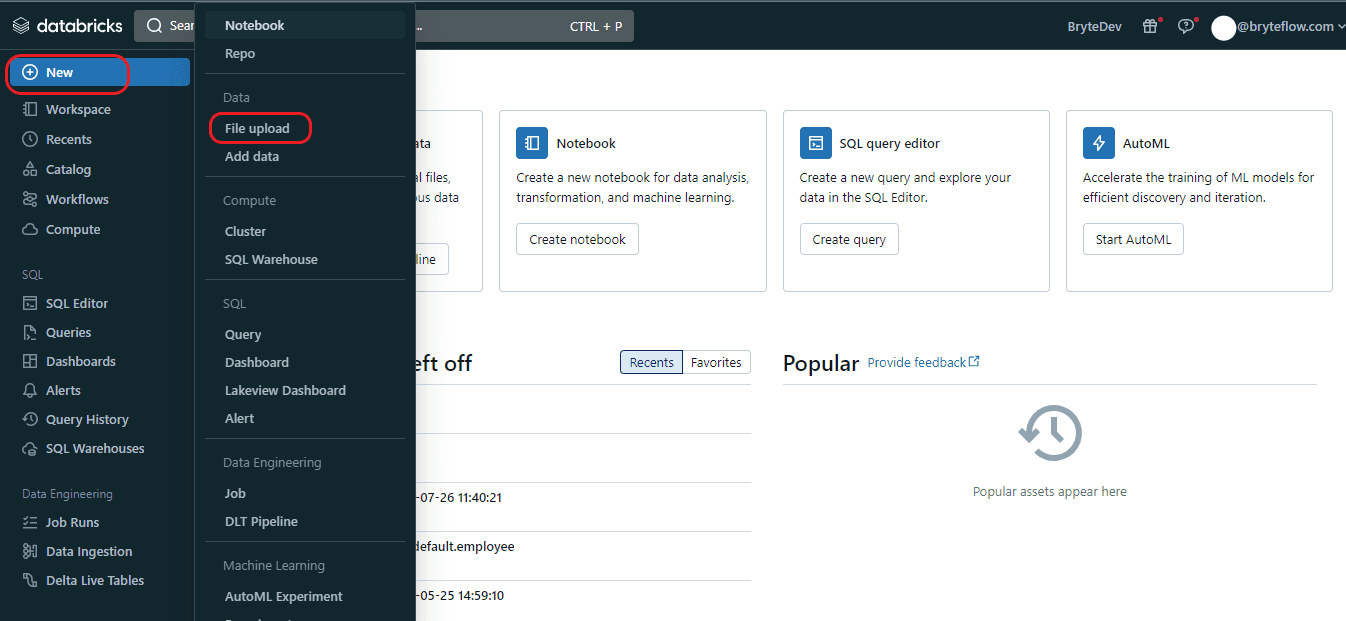
Step 5: Once the “Add Data” tab is open, choose the “Drop one or more files here, or browse” option to upload the CSV file. You can either drag and drop the CSV file or browse for it, select it, and proceed with the upload.
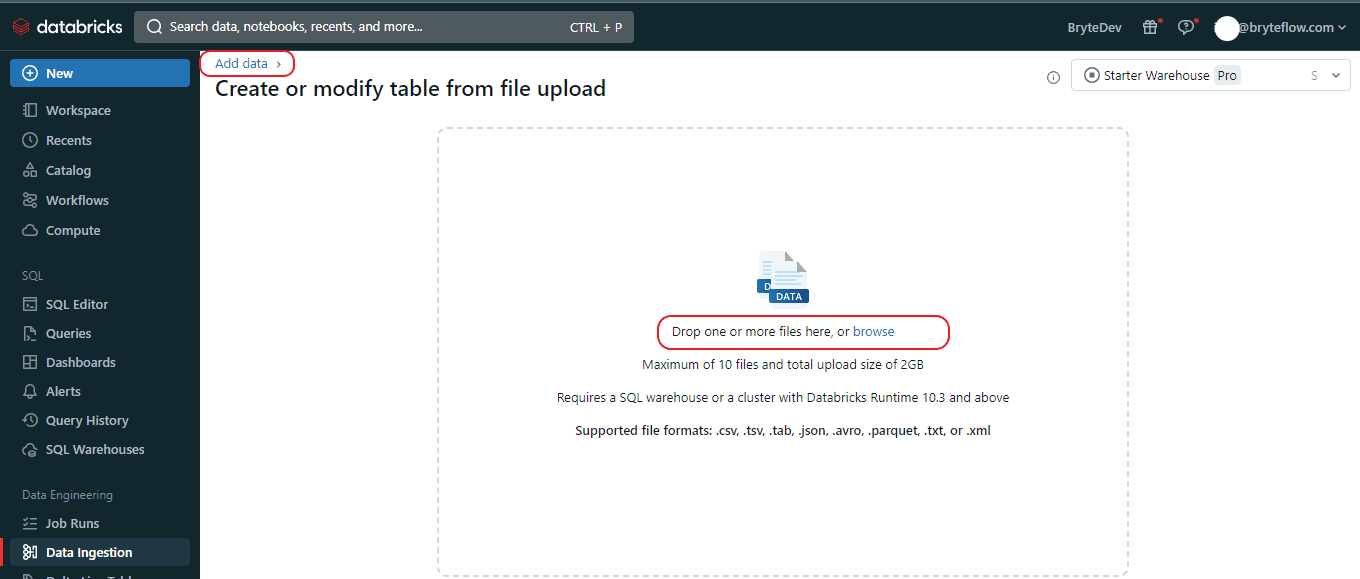
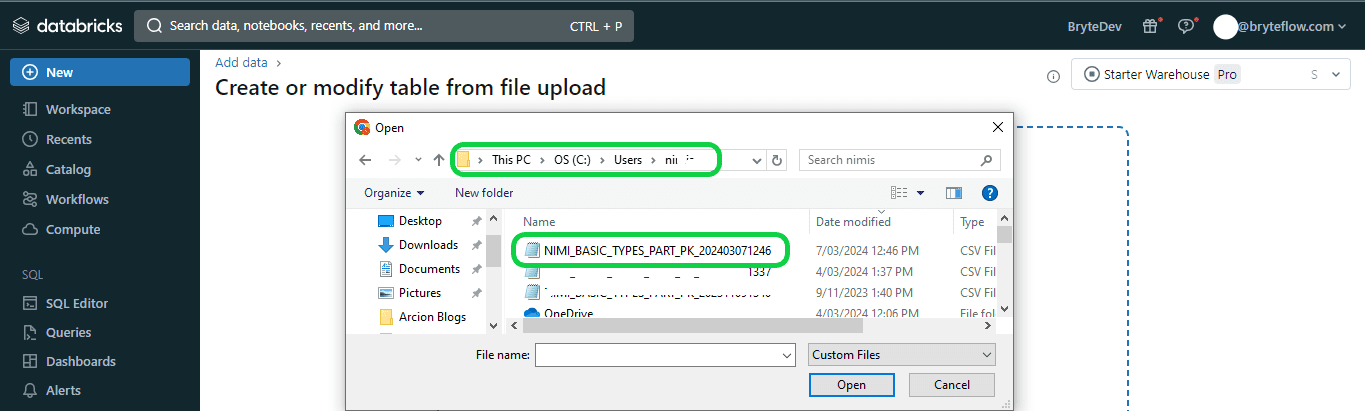
Step 6: Once you’ve chosen or dragged the file into the upload window, the user interface will initiate automatic file upload and display a preview. From there, you can modify table details and convert data types to comply with Databricks Delta Lake format.
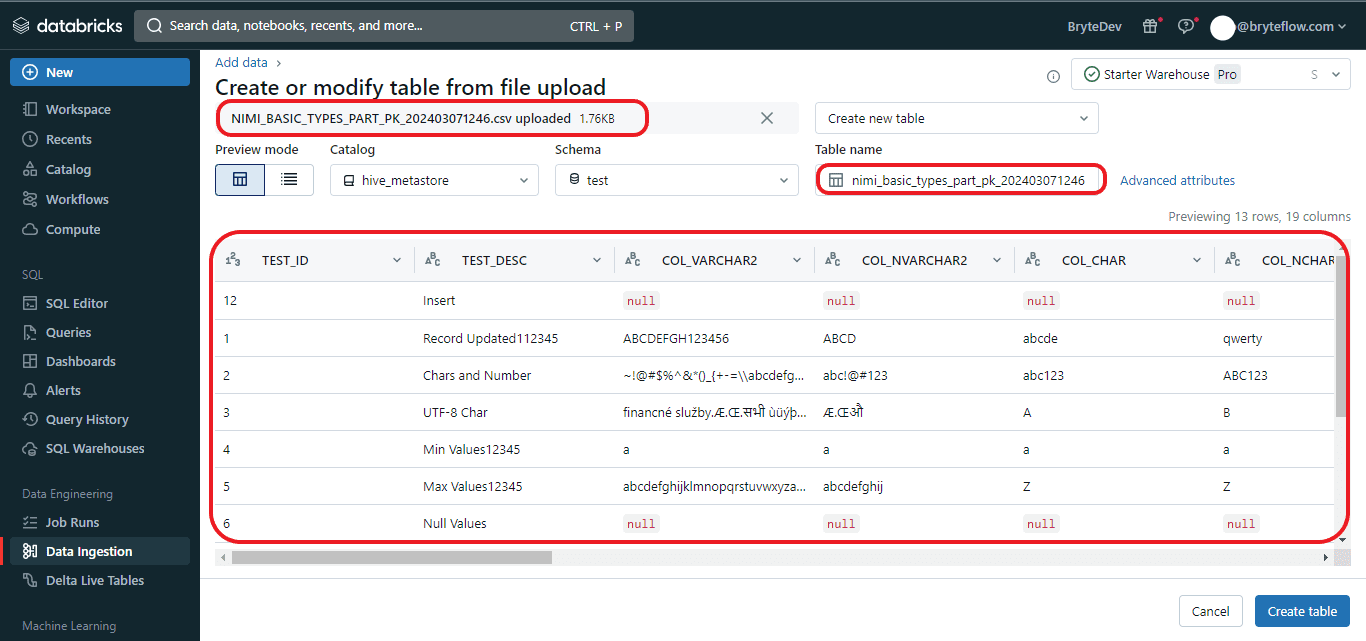
2.3 Modify the table specifications and transform the data types into the format compatible with Databricks Delta Lake.
Step 1: You can also view the preview in the ‘Vertical’ orientation.
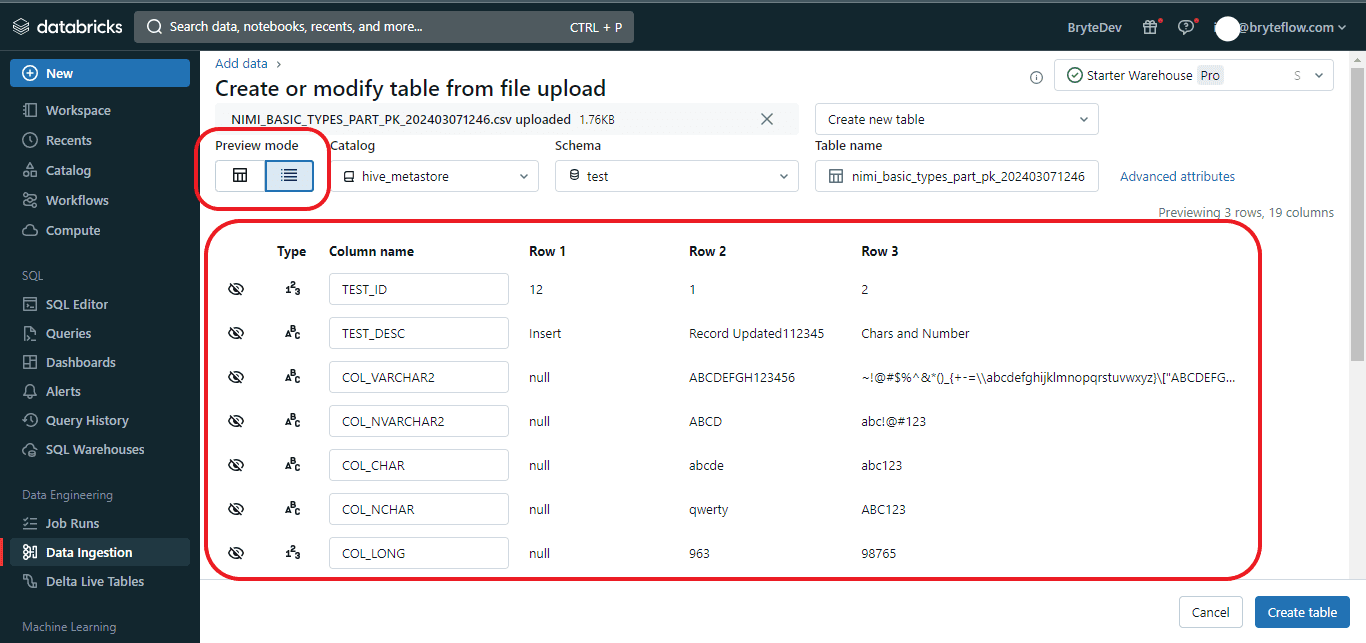
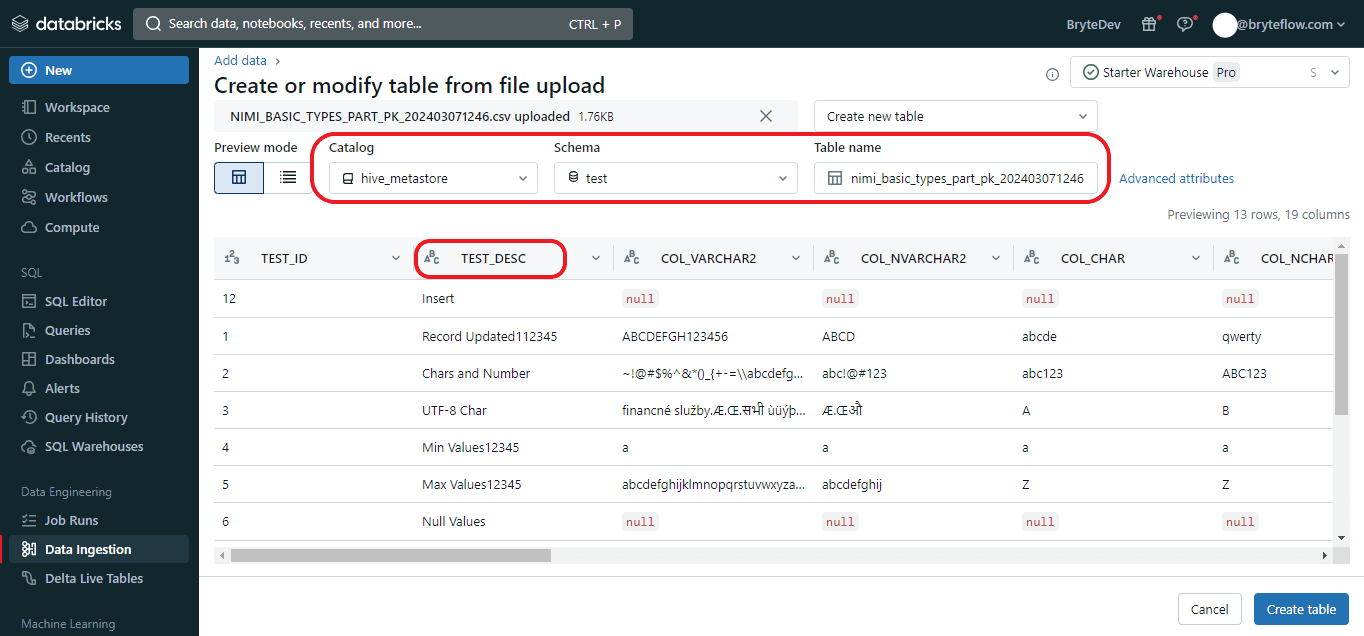
Step 2: Within this interface, you can modify the following aspects:
- Table details including the table name, column names, and selection of various schemas.
- To choose from different schemas, simply click the downward arrow adjacent to the “Default Schema.”
- Table names are constrained to lowercase alphanumeric characters and underscores, with a requirement to commence with a lowercase letter or underscore.
- Column names are restricted from using commas, backslashes, or Unicode characters (such as emojis). To edit a column name, click on the input box situated at the top of the respective column.
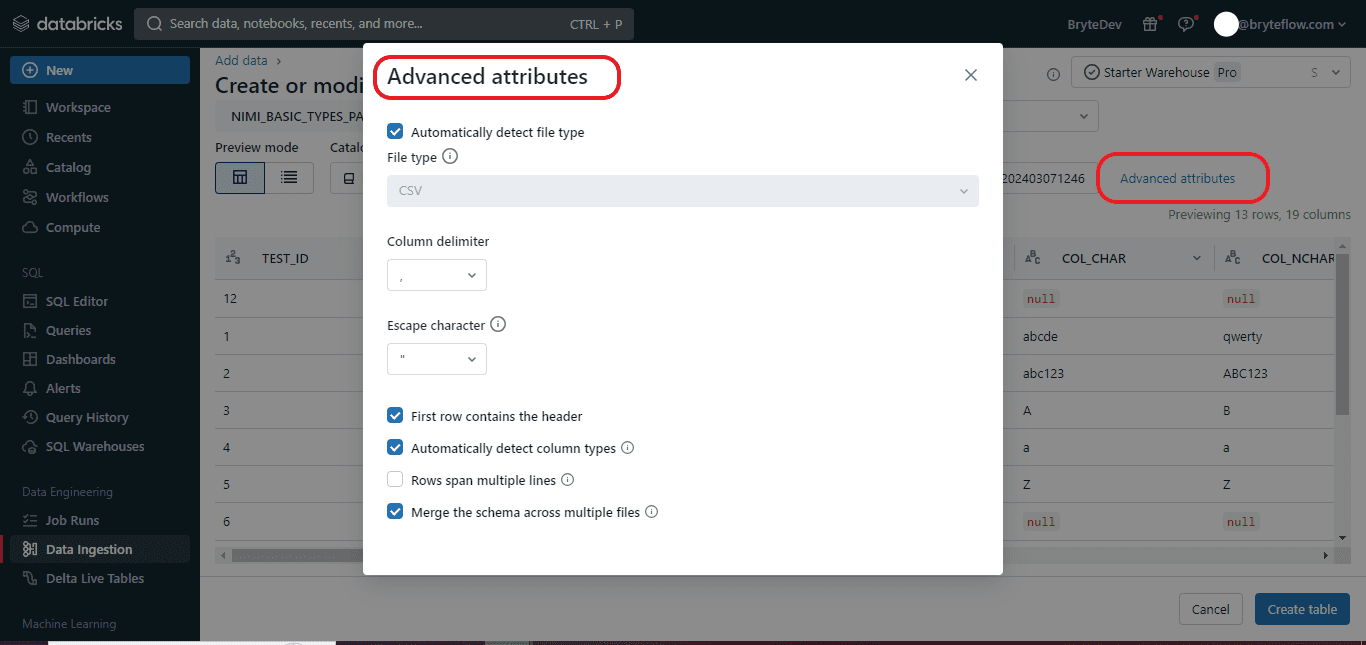
Step 3: The available format options for “Data Types” are dependent upon the file format being uploaded. Common format options are displayed in the header bar and are automatically inferred for CSV and JSON files. You can interpret all columns as STRING type by deactivating “Advanced attributes > Automatically detect column types”.
For CSV files, the following options are accessible:
- First row contains the header (enabled by default): This setting determines whether the CSV/TSV file includes a header row.
- Column delimiter: The character used to separate columns must be a single character and cannot be a backslash. CSV files typically utilize a comma as the default separator.
- Automatically detect column types (enabled by default): The content of the file is automatically analyzed to detect column types. You can modify the types in the preview table. When this setting is disabled, all column types are assumed to be strings.
- Rows span multiple lines (disabled by default): This option assists in identifying each row in a file and spans it into multiple lines, rather than loading all rows as a single row into a file.
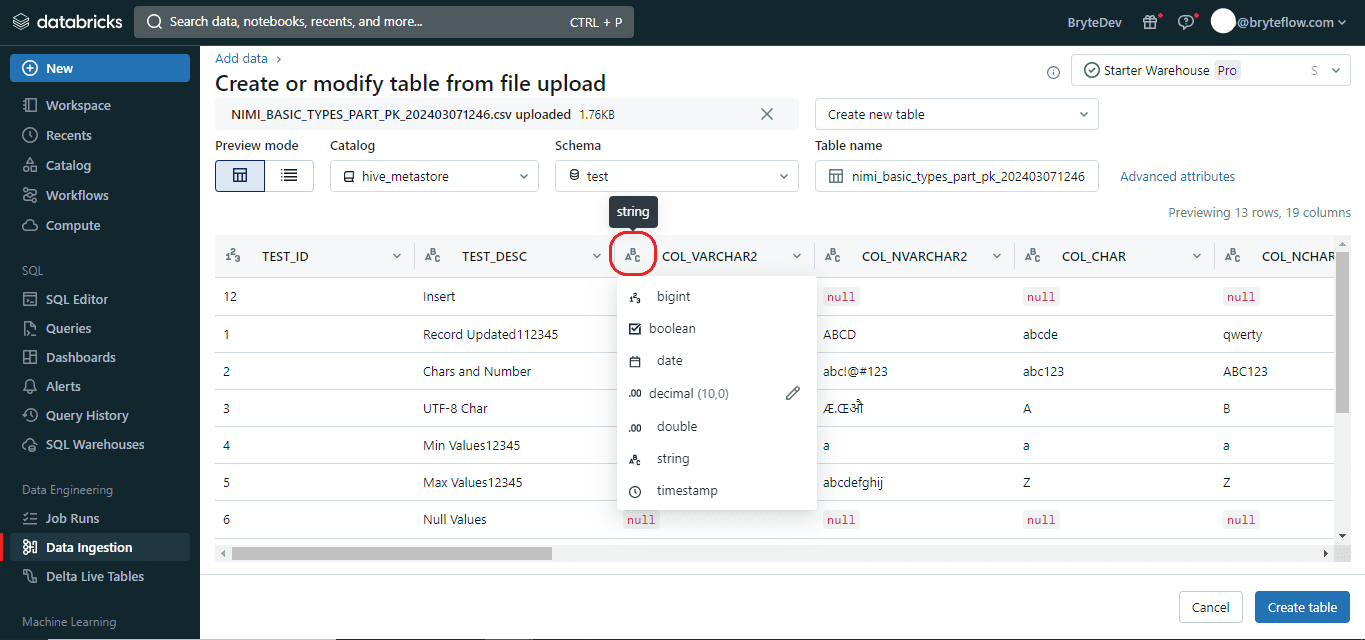
Step 4: After finishing the editing process, select the “Create Table” option located at the bottom left corner to generate the table. The table will be created with data in Databricks, based on the conditions and edits that were provided.
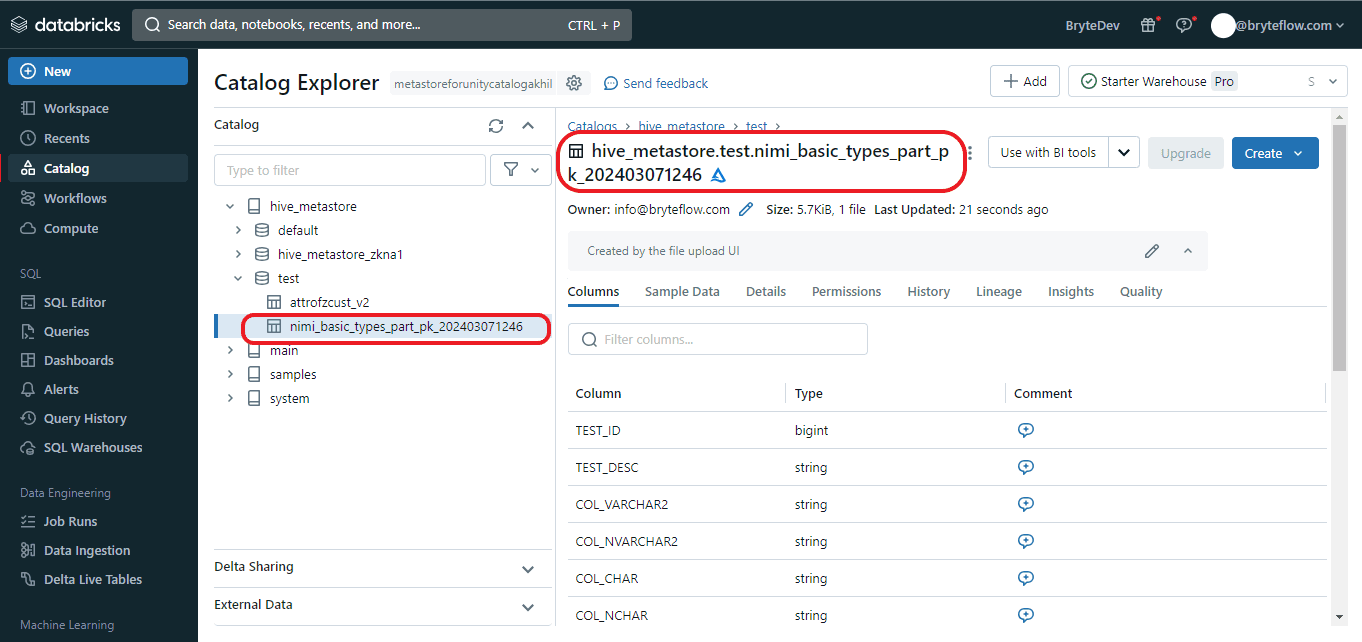
3. BryteFlow as a third-party CDC tool to connect and transfer data from Oracle DB to Databricks
Many data migration tools are available to move Oracle data to your Databricks Delta Lake but what you should look for is a tool that is completely automated, provides high throughput, and low latency with real-time Change Data Capture. BryteFlow Ingest, our no-code replication tool, fits that description exactly. BryteFlow offers support for ELT of massive volumes of enterprise data and delivers optimized performance in line with Databricks’ best practices. It seamlessly connects Databricks to Oracle Database, ensuring a completely no-code migration of data from Oracle to Databricks.
Here is a step-by-step process to show how BryteFlow functions as an Oracle Databricks Connector and how it loads data from Oracle to Databricks on AWS using Change Data Capture.
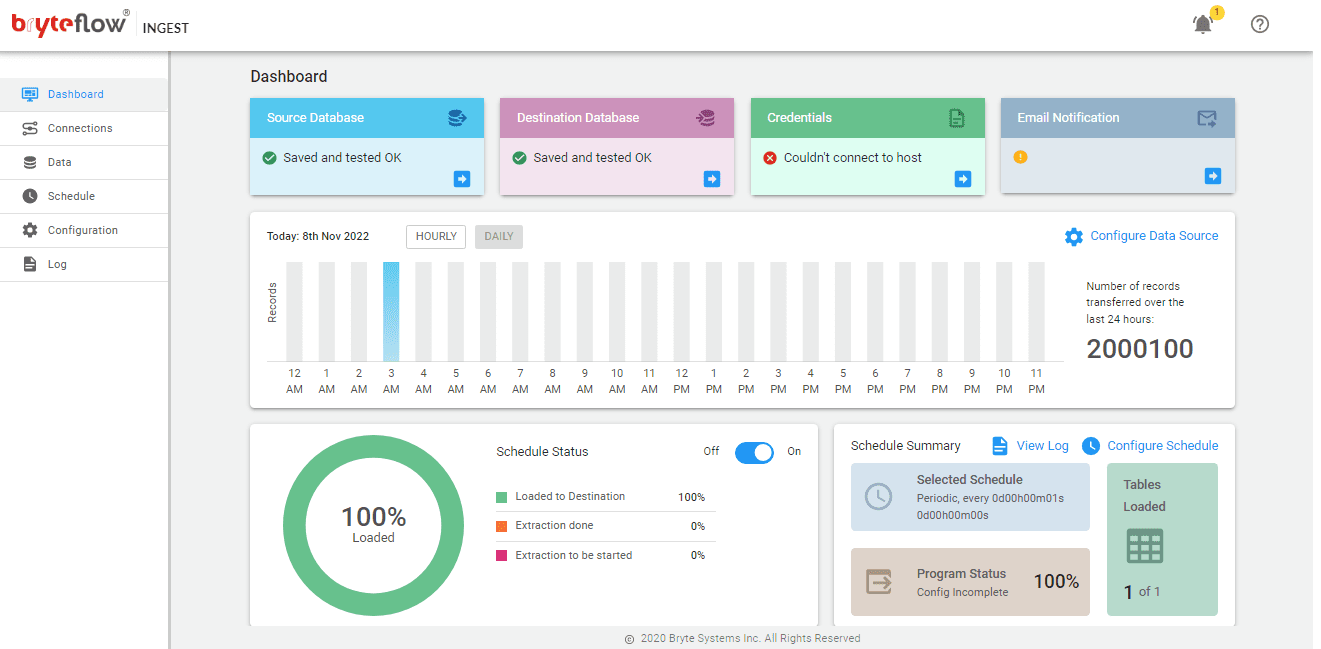
Step1: Install BryteFlow, it can be either downloaded from the AWS Marketplace
Alternatively, contact us to help in installation. Make sure all prerequisites have been met before you begin. The Dashboard is the opening screen where you can view the status of replication tasks. Select ‘Connections’ in the left panel.
Step 2: Set up the Source Connector and key in the configuration details. The Source Connector we have selected is Oracle LogMiner but there is a whole range of Oracle sources you can select from.
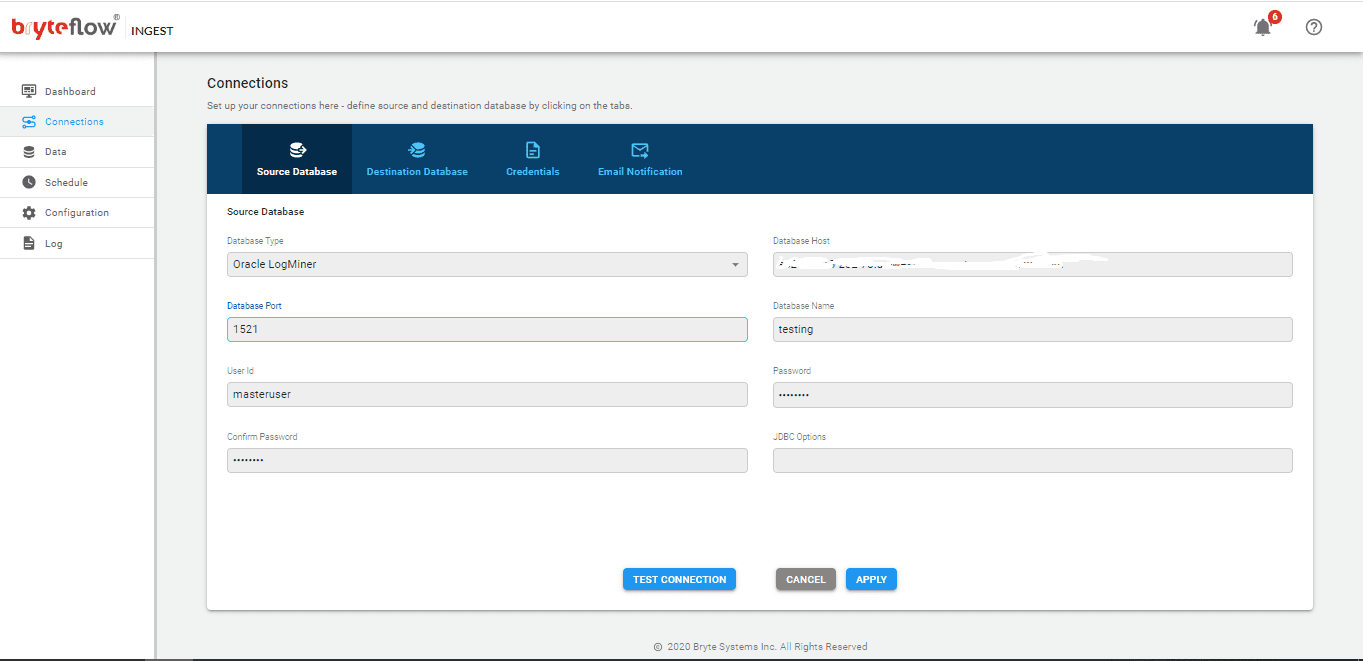
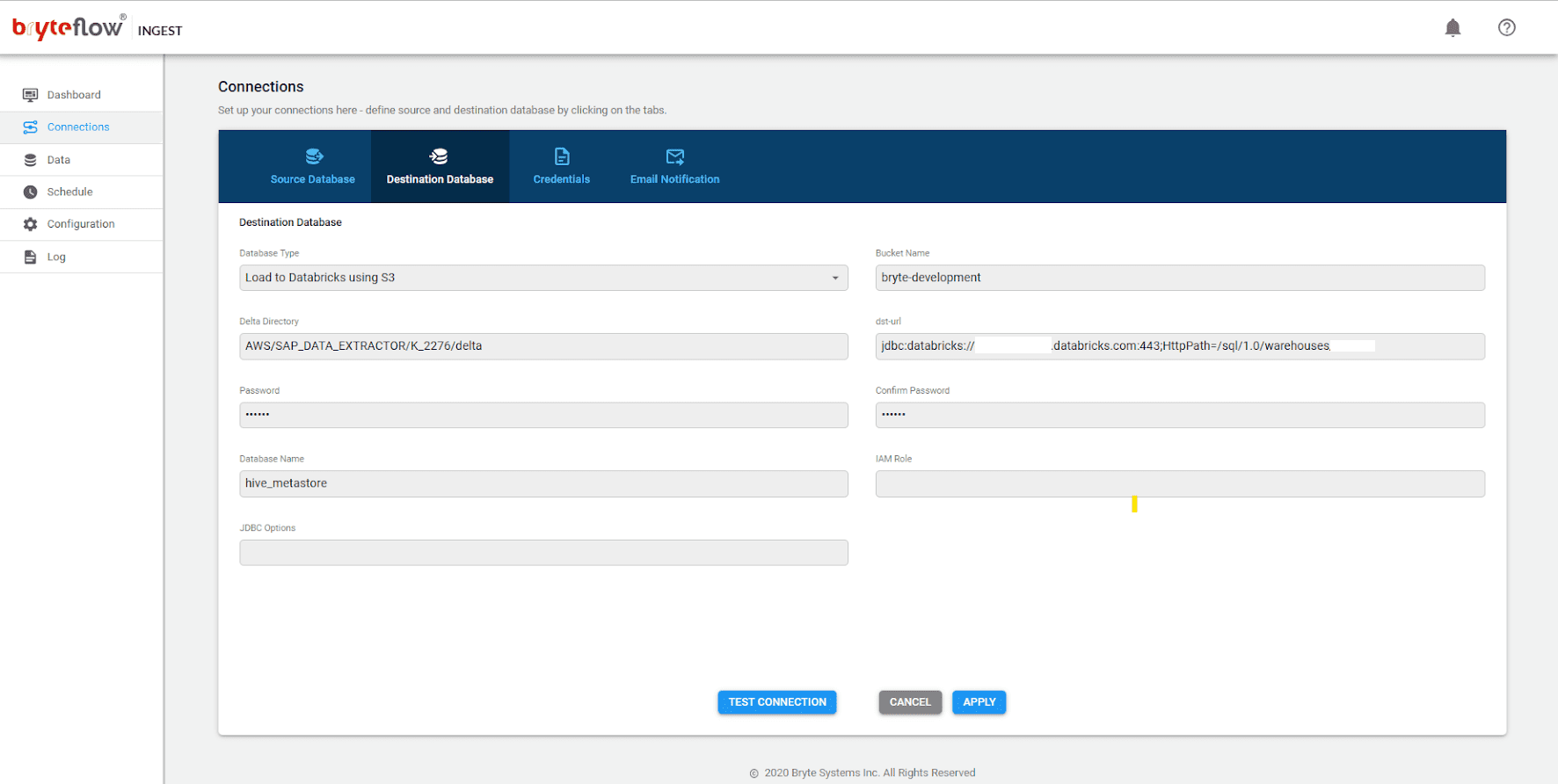
Step 3: Set up Destination Connector, in this case we are selecting the ‘Load to Databricks using S3’ option.
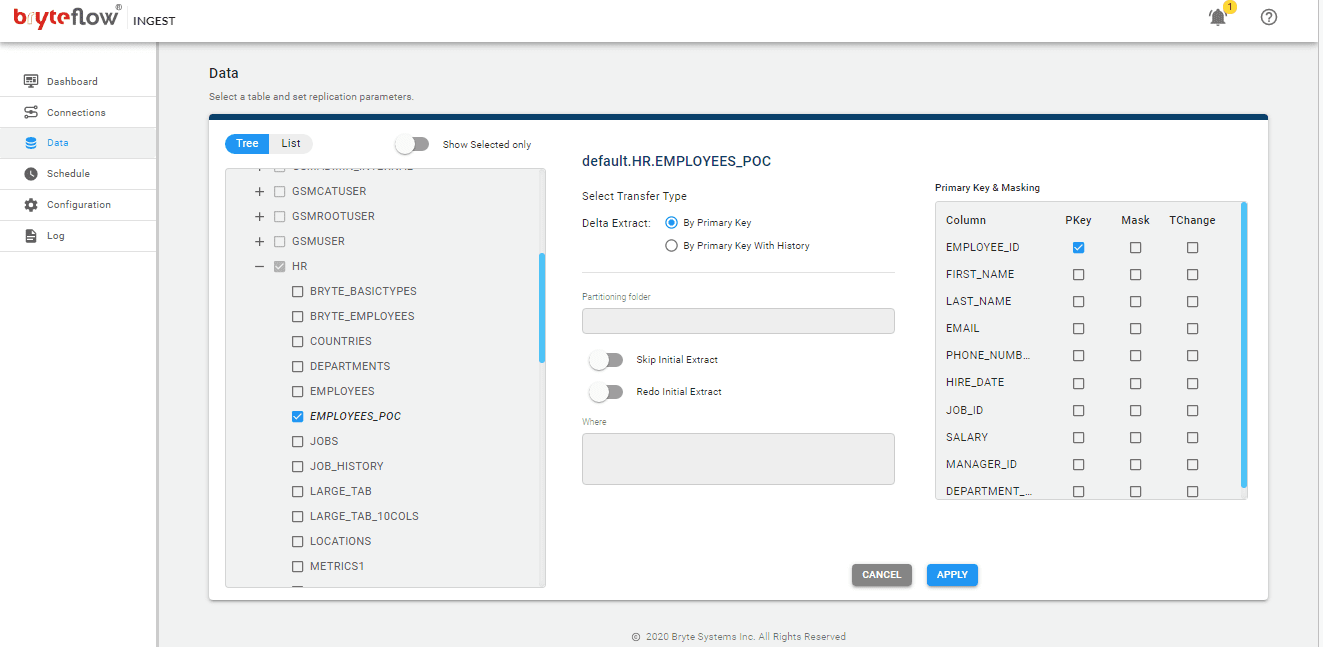
Step 4. Add tables from Oracle source to the replication pipeline.
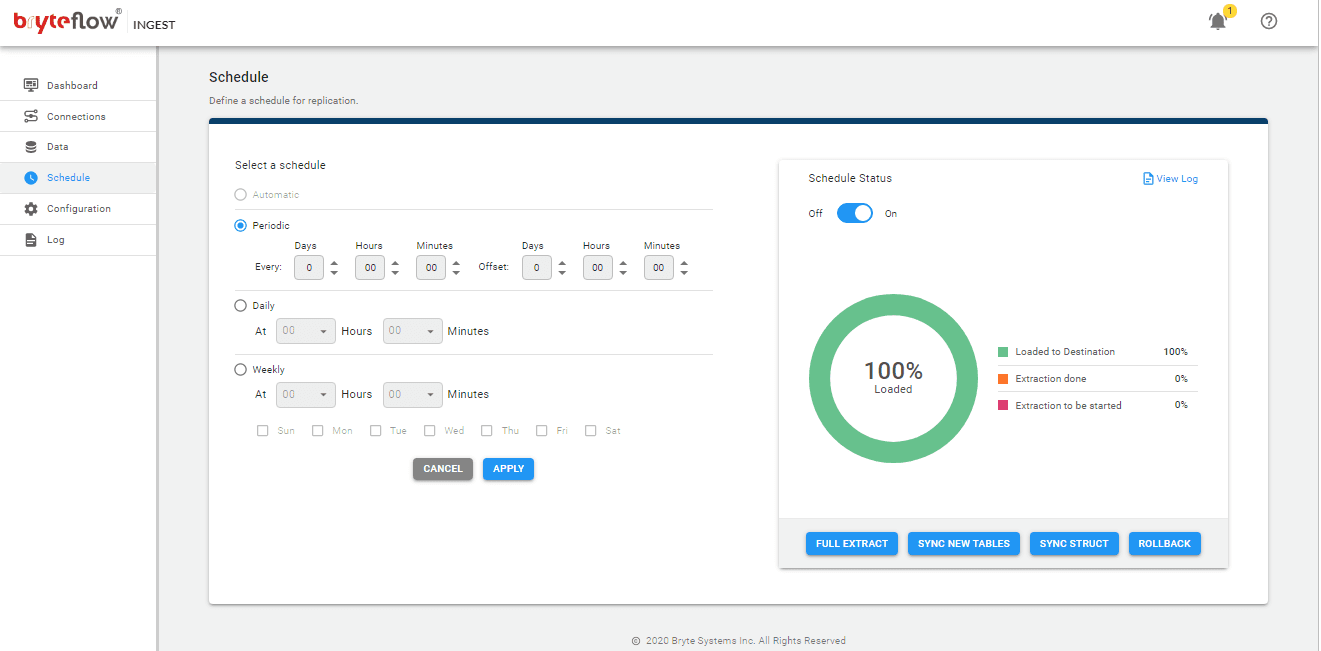
Step 5. Start the Data Replication process by scheduling the replication. If you opt for the ‘Automate’ option, the changes will be replicated as soon as there are changes at source. If you select the ‘Periodic’ option, you can specify a frequency for the replication to happen. You can also opt for ‘Daily’ or ‘Weekly’ replication.
BryteFlow as an Oracle Databricks Connector and Replication Tool
BryteFlow connects Databricks to Oracle Database in just a couple of clicks with its visual, user-friendly UI. It extracts and loads data from Oracle sources and transforms it on Delta Lake. BryteFlow XL Ingest supports the first full ingestion of very high volumes of data with multi-thread parallel loading, smart configurable partitioning, and compression. Incremental data from Oracle DB to Databricks is delivered by BryteFlow Ingest using log-based Change Data Capture, in real-time, or as per scheduled frequency.
BryteFlow automates every process, including data extraction, CDC, data merges, masking, schema and table creation, data mapping and SCD Type2 history. It provides data type conversions out-of-the box (eg. Parquet-snappy, ORC) so data is ready to use on destination. BryteFlow supports all versions of Oracle (On-premise and Cloud), including Oracle 12c, 19c, 21c and future releases for the long term. It delivers data to Databricks on AWS, Azure and GCP and you can start getting delivery of data in just 2 weeks. How BryteFlow Works
Oracle CDC to Databricks with BryteFlow: Highlights
- BryteFlow operates with low latency through log-based CDC replication, ensuring minimal impact on the data source.
- BryteFlow Ingest delivers data from sources like SAP, Oracle, and SQL Server to the Databricks platform on AWS, Azure, and GCP in real-time, using log-based CDC.
- BryteFlow incorporates best practices for optimizing Databricks Lakehouse and Delta Lake environments.
- BryteFlow XL Ingest efficiently manages large data volumes with multi-thread parallel loading and automated partitioning mechanisms, ensuring high-speed data processing.
- It automates every process including data extraction, CDC, data merges, masking, schema and table creation, data mapping and SCD Type2 history, so there is no coding to be done at all.
- It supports time versioning of data with SCD Type2 capabilities, providing a comprehensive transaction history.
- BryteFlow offers long-term support for Oracle databases, including versions 12c, 19c, 21c, and future releases. BryteFlow for Oracle Replication
- Offers easy data conversions with BryteFlow Ingest, which offers a range of pre-configured conversion options.
- BryteFlow automatically configures file formats and compression settings, such as Parquet-snappy and ORC. Parquet, ORC or Avro for S3?
- It delivers consumption-ready data to Databricks Lakehouse, with out-of-the-box data type conversions, enabling immediate use of the data without additional processing.
- With impressive throughput capabilities, BryteFlow moves data at approximate speeds of 1,000,000 rows in 30 seconds, which is 6x faster than GoldenGate and much faster than competitors.
The blog discussed the hows and whys of connecting Oracle DB to Databricks and the great features of each. It also discussed three approaches to loading data from Oracle to Databricks: using native Databricks tools, employing a manual method via CSV export and load, and using BryteFlow as a third-party no-code CDC tool. The blog described how BryteFlow functions as an automated Oracle Databricks connector and delivers data in real-time, using no-code Change Data Capture in the ELT process.
Contact us for a Demo of BryteFlow.



