Data Integration, why you need it
Data Integration Processes
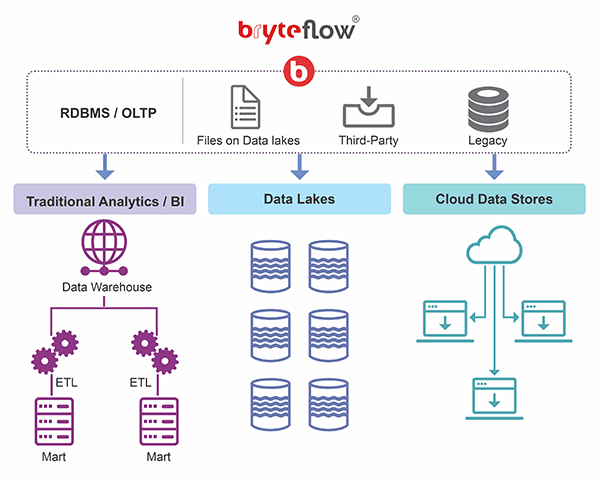
What is data integration and why does it matter?
Data integration refers to the method by which data from different sources can be aggregated to present a unified view to users. This makes the data easily accessible and consummable for a number of purposes, including reporting, analytics, machine learning, artificial intelligence and more. Effective data integration can actually reduce data costs, increase productivity, help organizations innovate more besides generating helpful business insights to grow operations. Learn how BryteFlow Works
Real-time Data Integration is the need of the hour
In an increasingly fast-paced world with growing data sources, data is needed in real-time for a lot of analytics use cases. Real-time data integration captures and prepares data as it is is generated to power real-time data analytics. This could be streaming data from IoT sensors, ecommerce transactions, social media interactions, stock market trading operations, electricity grid monitoring, data from machinery and equipment for predictive analytics, GPS, banking transactions and airline bookings etc.
Suggested Reading
SQL Server Change Data Capture (CDC) for Real-Time SQL Replication
Oracle CDC (Change Data Capture): 13 Things to Know
Postgres CDC (6 Easy Methods to Capture Data Changes)
Change Data Capture and How to Make CDC Automation Easy
BryteFlow is a Real-Time
Data Integration Tool
BryteFlow is a real-time data integration tool for end-to-end workflows. When you install the BryteFlow enterprise edition, you get real-time data ingestion, transformation and data reconciliation with a single software. BryteFlow is Cloud-native and runs on AWS, Azure and GCP.
High throughput replication and CDC for real-time data integration
BryreFlow delivers data in real-time with log-based automated CDC and syncs data with source to keep data updated. It merges deltas including inserts, deletes and updates automatically on target. It has one of the highest throughputs, moving 1,000,000 rows in 30 seconds. This is 6x faster than GoldenGate.
Data integration with scalability for very high data volumes
BryteFlow XL Ingest transfers initial data with multi-threaded parallel loading and smart configurable partitioning so it can replicate petabytes of data in minutes. After that BryteFlow Ingest replicates incremental data using log-based Change Data Capture.
BryteFlow supports On-Prem and Cloud platforms for data integration
Whether you need data delivered on-premise or on Cloud platforms, BryteFlow integrates data in real-time on Amazon S3, Redshift, Snowflake, Azure Synapse, Azure Data Lake Gen2, Teradata, Databricks, Google BigQuery, SQL Server, Postgres, and Kafka.
BryteFlow automates every process of the data integration process
Data integration includes a lot of processes including data extraction, Change Data Capture, data mapping, schema and table creation, masking, SCD Type2 history. BryteFlow automates all of these with a point-and-click user-friendly interface so there is no coding to be done ever. How BryteFlow Works
BryteFlow data integration offers automated data reconciliation
BryteFlow TruData offers automated data reconciliation with data completeness checks by using row counts and columns checksum. It provides alerts and notifications for missing or incomplete data.
Data integration with BryteFlow provides time-series data with versioning
BryteFlow provides SCD Type2 history and time-series data so you can get a history of every transaction. You can get a version of the data from any point in the timeline.
BryteFlow data integration provides ready for use data
BryteFlow provides data conversions out-of-the-box (e.g. Parquet-snappy, ORC) so data can be immediately consumed on target for reporting, analytics, AI and Machine Learning purposes. How to choose between Parquet, ORC and Avro for S3
BryteFlow is fast to implement and easy to deploy
Data integration using BryteFlow can be up and running in as little as 2 weeks, compared to months taken by competitors. Configuration takes just a couple of hours.
BryteFlow has automated Network Catchup
In the event of a system outage or lost connectivity, BryteFlow Ingest features an automated catch-up mode so the process resumes automatically from where it left off. How to Manage Data Quality (The Case for DQM)
Data Integration Architecture
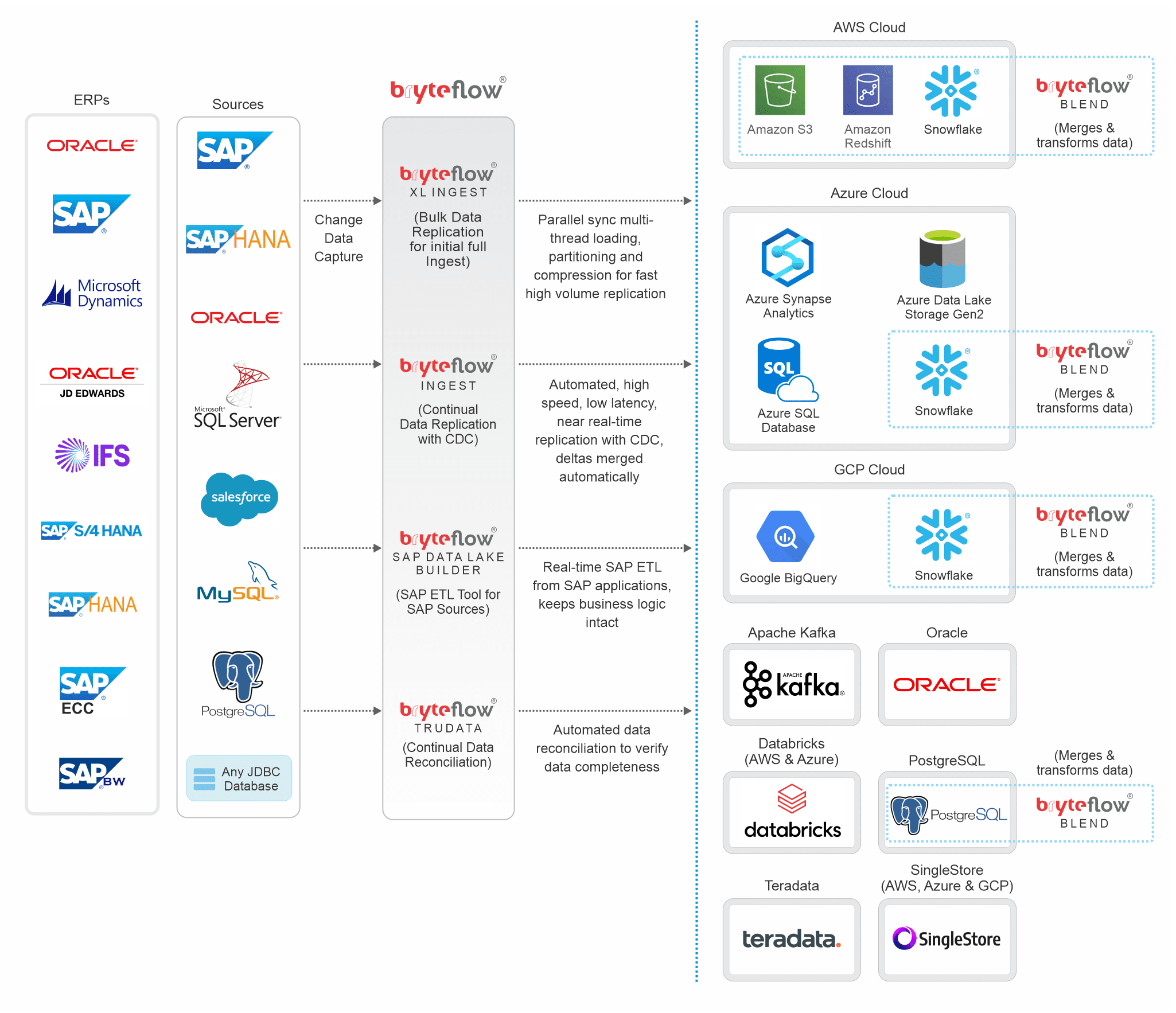
Data Integrations
Sources
Source databases and applications
BryteFlow data integration supports a wide range ofsources including relational databases, cluster, cloud, flat files and streaming data sources. We can easily add more sources if required. Let us know if you need another source added, we’ll be happy to oblige.
SAP
SQL Server
MySQL
MariaDB

Amazon Aurora

SAP HANA
Oracle
Salesforce

PostgreSQL

Any JDBC Database
Destinations
BryteFlow replicates your data across a large range of platforms.

Amazon S3

Amazon Redshift

Amazon Aurora

Amazon Kinesis
SQL Server

Azure SQL DB
Azure Synapse Analytics

Azure Data Lake Gen2

Snowflake
Oracle
Google BigQuery
Apache Kafka
PostgreSQL
Databricks
