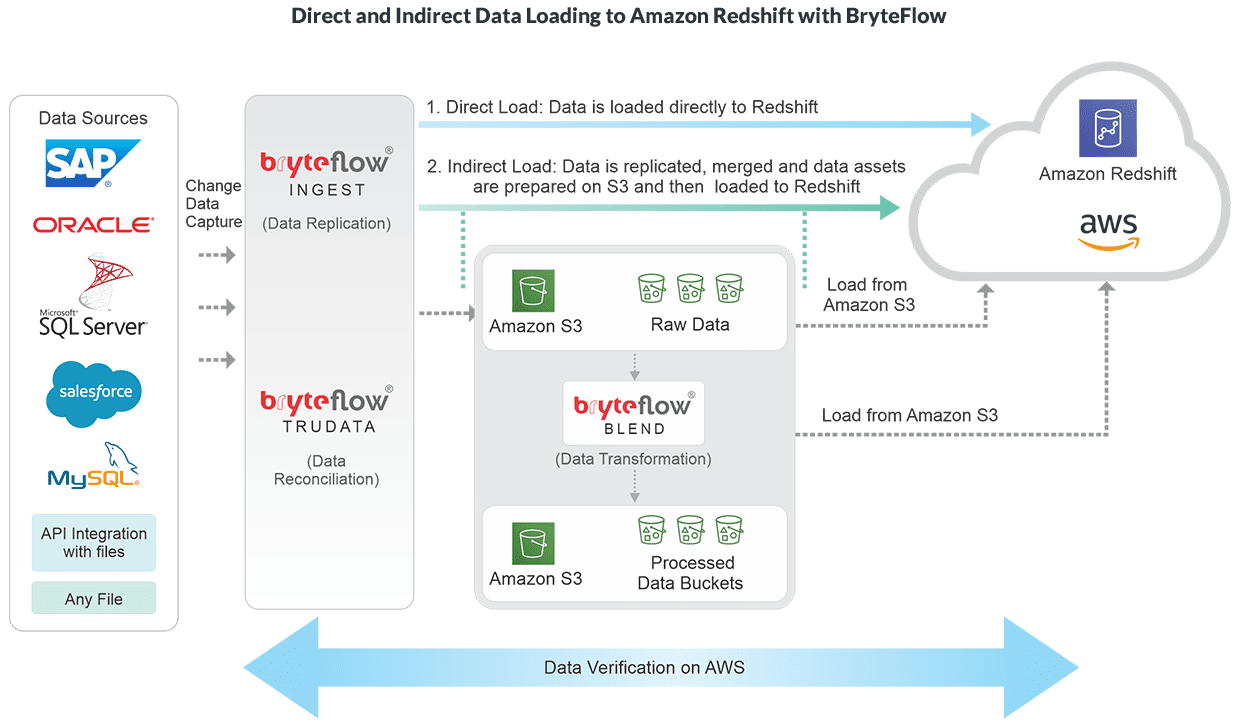
Data Replication to Redshift
Load Oracle data to Redshift
Why using BryteFlow to get your Oracle data to Redshift works.
When you need to load Oracle data to Amazon Redshift, you may be thinking about which Oracle replication tool to use. After all there are a lot of automated data replication tools out there that say they will ETL your Oracle data to Amazon Redshift in minutes. That’s great, but here are some points you may need to consider. Learn about AWS DMS Limitations for Oracle Sources
Learn about BryteFlow for Oracle
Data Integration on Amazon Redshift
- Low latency, log based replication with minimal impact on source. Oracle Replication in Real-time
- Optimised for Redshift, dist keys and sort keys are created automatically. Oracle to Redshift Migration Made Easy (2 Methods)
- No coding needed, automated interface creates exact replica or SCD type2 history on Redshift.
- Bulk load data easily with automated partitioning mechanisms for high speed.
- S3 and Redshift can be loaded in parallel – saves time. AWS ETL with BryteFlow
- BryteFlow provides replication support for all Oracle versions, including Oracle 12c, 19c, 21c and future releases for the long term.
Oracle CDC (Change Data Capture): 13 things to know
Oracle Replication in Real-Time Step by Step
Oracle to Azure Cloud Migration (Know 2 Easy Methods)
Real-time, codeless, automated Oracle data replication to Redshift

Can your replication tool replicate really, really large volumes of Oracle data to your Amazon Redshift database fast?
When your data tables are true Godzillas, including Oracle data, most data replication software roll over and die. Not BryteFlow. It tackles terabytes of data for Oracle replication head-on. BryteFlow XL Ingest has been specially created to replicate huge Oracle data to Amazon Redshift at super-fast speeds.

Access Operational Metadata out of the box
BryteFlow keeps operational metadata out of the box of all the extraction and load processes. This can be saved on Aurora if required. The metadata includes currency of data and data lineage. Currency of data shows the status of the data whether it is active, archived, or purged. Data lineage represents the history of the migrated data and transformation applied on it.
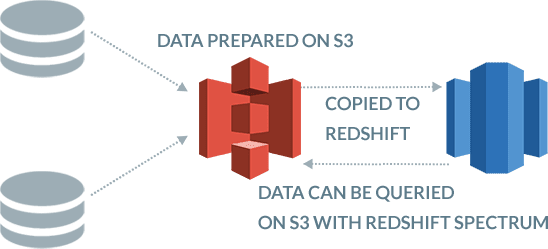
Prepare data on Amazon S3 and copy to Amazon Redshift or use Redshift Spectrum to query data on Amazon S3
BryteFlow provides the option of preparing data on S3 and to copy it to Redshift for complex querying. Or you can use Redshift Spectrum to query the data on S3 without actually loading it onto Redshift. This distributes the data processing load over S3 and Redshift saving hugely on processing and storage cost and time.

How much time do your Database Administrators need to spend on managing the replication?
You need to work out how much time your DBAs will need to spend on the solution, in managing backups, managing dependencies until the changes have been processed, in configuring full backups and then work out the true Total Cost of Ownership (TCO) of the solution. The replication user in most of these replication scenarios needs to have the highest sysadmin privileges.
With BryteFlow, it is “set and forget”. There is no involvement from the DBAs required on a continual basis, hence the TCO is much lower. Further, you do not need sysadmin privileges for the replication user.

Are you sure Oracle replication to Redshift and transformation are completely automated?
This is a big one. Most Oracle data tools will set up connectors and pipelines to stream your Oracle data to Redshift but there is usually coding involved at some point for e.g. to merge data for basic Oracle CDC. With BryteFlow you never face any of those annoyances. Oracle data replication, data merges, SCD Type2 history, data transformation and data reconciliation are all automated and self-service with a point and click interface that ordinary business users can use with ease.

Is your data from Oracle to Amazon Redshift monitored for data completeness from start to finish?
BryteFlow provides end-to-end monitoring of data. Reliability is our strong focus as the success of the analytics projects depends on this reliability. Unlike other software which set up connectors and pipelines to Oracle source applications and stream your data without checking the data accuracy or completeness, BryteFlow makes it a point to track your data. For e.g. if you are replicating Oracle data to Redshift at 2pm on Thursday, Nov. 2019, all the changes that happened till that point will be replicated to the Redshift database, latest change last so the data will be replicated with all inserts, deletes and changes present at source at that point in time.

Does your data integration software use time-consuming ETL or efficient Oracle CDC to replicate changes?
Very often software depends on a full refresh to update destination data with changes at source. This is time consuming and affects source systems negatively, impacting productivity and performance. BryteFlow uses Oracle CDC to Redshift which is zero impact and uses database transaction logs to query Oracle data at source and copies only the changes into the Amazon Redshift database. The data in the Redshift data warehouse is updated in real-time or at a frequency of your choice. Log based Oracle CDC is absolutely the fastest, most efficient way to replicate your Oracle data to Amazon Redshift.

Does your data maintain Referential Integrity?
With BryteFlow you can maintain the referential integrity of your data when replicating Oracle data to AWS Redshift. What does this mean? Simply put, it means when there are changes in the Oracle source and when those changes are replicated to the destination (Redshift) you can put your finger exactly on the date, the time and the values that changed at the columnar level.

Is your data continually reconciled in the Redshift cloud data warehouse?
With BryteFlow, data in the Redshift cloud data warehouse is validated against data in the Oracle replication database continually or you can choose a frequency for this to happen. It performs point-in-time data completeness checks for complete datasets including type-2. It compares row counts and columns checksum in the Oracle replication database and Redshift data at a very granular level. Very few data integration software provide this feature.
Do you have the option to archive data while preserving SCD Type 2 history?
BryteFlow does. It provides time-stamped data and the versioning feature allows you to retrieve data from any point on the timeline. This versioning feature is a ‘must have’ for historical and predictive trend analysis.

Can your data get automatic catch-up from network dropout?
If there is a power outage or network failure will you need to start the Oracle data replication to Redshift process over again? Yes, with most software but not with BryteFlow. You can simply pick up where you left off – automatically.
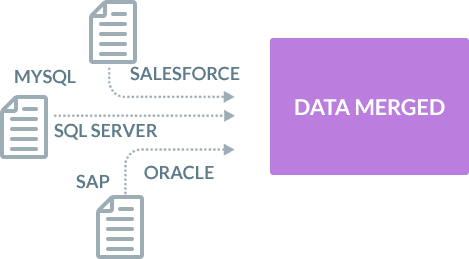
Can your Oracle data be merged with data from other sources?
With BryteFlow you can merge any kind of data from multiple sources with your data from Oracle for Analytics or Machine Learning.
More on BryteFlow’s Data Integration for Redshift

Is remote log mining possible with the software?
With BryteFlow you can use remote log mining. The logs can be mined on a completely different server therefore there is zero load on the source. Your operational systems and sources are never impacted even though you may be mining huge volumes of data.

Is the data replication tool faster than Oracle GoldenGate?
BryteFlow replication of Oracle data definitely is. This is based on actual experience with a client and not an idle boast. Try out BryteFlow for yourself and see exactly how fast it works to migrate your Oracle data to Snowflake.

About Oracle Database
Oracle DB is also known as Oracle RDBMS (Relational Database Management System) and sometimes just Oracle. Oracle DB allows users to directly access a relational database framework and its data objects through SQL (Structured Query Language). Oracle is highly scalable and is used by global organizations to manage and process data across local and wide area networks. The Oracle database allows communication across networks through its proprietary network component.
About Amazon Redshift
Amazon Redshift is the fully managed , petabyte scale cloud data warehouse of AWS. Amazon Redshift is characterized by its super fast speed in executing queries against large datasets aided by its Massively Parallel Processing and columnar database. Redshift is comprised of nodes (computing resources) that are organized in clusters. Each Redshift cluster has its own processing engine and at least one database. On Redshift, processing power can be scaled up immediately by adding more nodes to your cluster or even spinning up more clusters.