
Kafka CDC Explained and Oracle to Kafka CDC Methods
This blog is about Kafka CDC and focuses specifically on Oracle CDC to Kafka. We also talk about popular methods to achieve Oracle Kafka CDC, using GoldenGate, JDBC Connectors, and Debezium with Kafka Connect. Also learn what BryteFlow as a Kafka source connector gets to the table, providing the highest throughput of 1,000,000 rows under 30 seconds and a data extraction time of under 8 seconds, among other things. Oracle CDC and 13 things to know
Quick Links
- What is Apache Kafka?
- Kafka CDC (Change Data Capture) and why it is important
- Kafka CDC Types
- Kafka Connect
- Kafka Connectors
- Oracle Kafka CDC
- Creating a Source Connector for Oracle CDC to Kafka with BryteFlow
- Oracle CDC to Kafka Tool Highlights
What is Apache Kafka?
Apache Kafka is an open-source messaging platform that provides distributed event streaming for high performance real-time data pipelines and applications. Streaming data is data generated continuously by multiple data sources that needs to be processed on a sequential and incremental basis. Apache Kafka as a message broker is used by 80% of Fortune 500 companies owing to its ability to process the huge influx of data and events. By event we mean an action, change or occurrence that is identified and stored by applications – this could be website clicks, payments, newsletter subscriptions, feedback and posts on social media etc. Kafka thus publishes and subscribes to streams of records; it stores record streams in the same sequence they were generated and processes the record streams in real-time. Apache Kafka and how to install it
You can build real-time streaming data pipelines and applications with Kafka that adjust to data streams. Kafka integrates processing of streams, messaging, and storage, and enables storage and analytics of historical and real-time data. Kafka CDC and Integration
Kafka CDC (Change Data Capture) and why it is important
Change Data Capture in Kafka or Kafka CDC is integral to processing records in real-time. A mechanism like Change Data Capture is needed to capture all the changes happening at source (records, updates, inserts, deletes) and deliver them to Kafka so data can be updated continuously. Organizations need to capture and sync the latest data in data warehouses and data lakes from various sources for effective Analytics, Machine Learning models and Data Science purposes. Real-time data replication using Kafka CDC (Change Data Capture) is needed to sync real-time streaming data. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
Change Data Capture isn’t just one technique however but refers to different methods that can help you identify and capture data that has changed in the database. Change data capture is more efficient and timesaving than old fashioned batch processing. The reasons why Kafka CDC is preferable for real-time data ingestion to Kafka are:
Kafka CDC in databases allows events and data transference to happen in real-time
As a messaging platform Kafka needs Kafka CDC for optimal performance. Kafka CDC allows streaming of data from databases so data can be transmitted as the events unfold in real-time, sending new transactions to Kafka instead of batching them and resulting in delays for Kafka consumers. Oracle vs Teradata (Migrate in 5 Easy Steps)
Kafka CDC is low impact and sparing of network resources
Kafka CDC continually delivers records that have changed at source and not the large data volumes encountered in batch replication, this means there is less usage of network resources, and it is much more cost-effective and low impact. SQL Server CDC To Kafka (Unbelievably Easy New Connector)
Kafka CDC ensures access to granular data
Since the Kafka CDC mechanism is transmitting changes continually rather than via database snapshots, specific information is easily available about the changes, this granular data availability is instrumental for better reporting and analytical insights. Oracle to Snowflake: Everything You Need to Know
Kafka CDC Types
Kafka CDC is of 2 types: Query based Kafka CDC and Log-based Kafka CDC
Kafka CDC Query-based
For Query-based Kafka CDC a database query that includes a predicate is used to extract changed current data. The predicate helps to identify changes at source and is based on timestamps or identifier columns that will have incremental changes. Kafka CDC that is query-based is enabled by the JDBC Connector for Kafka Connect. Connect Oracle to Databricks and Load Data the Easy Way
Kafka CDC Log- Based
In log-based Kafka CDC the transaction log of the database is used to get the details about every change at source. The transaction log records every insert, delete and update. When 2 rows are transferred to the database, 2 entries are created in the transaction log. These are decoded and the data creates 2 new Kafka events. A benefit of log-based Kafka CDC is that it makes historical data available since it records not only the latest data in the rows but also the state of the rows before the changes were made. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
Kafka Connect
The Kafka Connect API is a component of Kafka along with the Kafka Streams API and Apache Kafka. The Kafka Connect framework functions as a layer on top of the main Apache Kafka, to enable streaming of large volume data. It has pluggable ready to deploy modules that can be used to deliver data from multiple systems into Kafka and to deliver data from Kafka into multiple systems. These are the Kafka Connectors. Kafka Connect provides a degree of automation. If you were to write code for a new source implementation, there would likely be lots of tweaking, failures, and restarts, logging etc. you can avoid this by using Kafka Connect and the Kafka Connectors. With Kafka Connect you get data prep out of the box and even minor transformations on data. Oracle to Azure Cloud Migration (Know 2 Easy Methods)
Kafka Connectors
To connect Kafka with external sources like databases, search applications, and file systems we need Kafka Connectors and there are hundreds of them available. Debezium CDC Explained and a Great Alternative CDC Tool
Kafka Source Connectors
Kafka source connector is a Kafka connector that aggregates data from systems into Kafka. These could be data streams, databases, or message brokers. Source connectors could also collect data (metrics) from application servers to Kafka topics to enable data for low latency stream processing. BryteFlow for Kafka CDC
Kafka Sink Connectors
Kafka sink connectors collect and deliver data from Kafka Topics to multiple systems such as Elasticsearch (a distributed, open-source search and analytics engine for multiple types of data), Hadoop (batch system) and other databases. Many sink connectors are available for well-known systems like JDBC, Amazon S3, Amazon Redshift, PostgreSQL, and Google BigQuery among others. Oracle to Postgres Migration
Oracle Kafka CDC
Oracle CDC to Kafka can make your Oracle to Kafka delivery low impact, reliable and high performance. Oracle is a popular source and sink for Kafka and there are quite a few Oracle Kafka CDC mechanisms to deliver data from Oracle to Kafka
Here we will examine how to get Oracle data to Kafka using CDC and describe some methods that can help do that.
Concept behind Oracle CDC to Kafka
Oracle CDC to Kafka is based on the concept of Publishers and Subscribers. Changes at the database (Publisher) are captured and the data can be accessed by individuals and applications (subscribers) How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
Oracle Kafka CDC features Synchronous and Asynchronous capturing of data
Synchronous Oracle Kafka CDC
Synchronous data capture is based on database triggers and allows for instant capture of changes in data when a DML command is performed.
Asynchronous Oracle Kafka CDC
Asynchronous data capture executes in the absence of triggers. In this method of Oracle Kafka CDC, the data sent to the redo log is read when the SQL statement for the DML operation is committed. What are Redo logs? Think of them as journals of transactions used in serial order and each transaction is recorded in them. Every transaction queues up in Redo log buffers and is written into the redo logs one at a time.
Oracle CDC to Kafka with Oracle GoldenGate
Oracle GoldenGate, Oracle’s native replication tool can be used for Oracle to Kafka CDC (log-based CDC). Other CDC replication tools can also enable Oracle CDC to Kafka including our very own BryteFlow. You can use Oracle GoldenGate directly with Kafka to stream changes happening at source. Every change is captured in the transaction log and Oracle Goldengate sends it on to Kafka. Oracle GoldenGate has an edge over the JDBC source connector since it follows the ‘push’ rather than the periodic ‘pull’ from the source. Oracle GoldenGate for Big Data has a native Kafka handler that captures and streams changes in data from Oracle GoldenGate trails to Kafka topics. The Kafka handler can also enable publishing of messages to separate schema topics. AVRO and JSON formats are supported for this. Real-time Oracle Replication with BryteFlow
Oracle CDC to Kafka with the Kafka JDBC Connector
Another way to perform Oracle CDC to Kafka (query-based CDC) is by using Kafka’s JDBC Connector, it can be used to connect to almost any RDBMS including Oracle. Other databases it can connect to include SAP, SQL Server, MySQL, Postgres, DB2 etc. A drawback of the Kafka JDBC connector is that it may require input from software engineers and a fair amount of coding especially for any transformations required. Kafka JDBC Connector usage will need Kafka Connect runtime. You need to ensure there is an incrementing ID column in the source table and /or update timestamp column for identifying changes in records. If these are not present, only bulk loading of data will be possible every time. Please note the JDBC connector will need to be configured first with parameters defining the connection details. A point to note is that the JDBC connector is effective for getting a snapshot of the table but identifying changed or deleted records is challenging, one way to identify changes is by putting triggers on tables, which is not an optimal approach. More on the Kafka JDBC Connector
How Oracle GoldenGate scores over the Kafka JDBC connector
- GoldenGate has remarkably lower latency than the JDBC connector and requires less usage of resources of the source database since GoldenGate mines the transaction logs rather than the database for timestamp or key-based changes. Oracle CDC: 13 things to know
- GoldenGate can handle higher data volumes with ease since it enables replication of complete databases and schemas with hardly any configuration changes. However, in the case of the JDBC connector, each SQL statement or table needs to be specified. GoldenGate CDC and an easier alternative
- Golden Gate (Big Data) has its own built-in handler for Kafka and enables processing of data in multiple formats directly to Kafka, not needing integration with the Kafka Connect framework, which is convenient. More on Oracle GoldenGate and Kafka Connect
Oracle to Kafka CDC with Debezium and Kafka Connect
What Is Debezium?
Debezium is a distributed streaming open-source platform for CDC that has Kafka Connect connectors for many databases including Oracle. Debezium can be used in tandem with Oracle XStream or Oracle LogMiner for Oracle CDC to Kafka. What is Oracle Xstream? XStream is an aggregation of Oracle DB components and APIs that allow data changes in an Oracle database to be received by client applications and to send changes to Oracle databases. Debezium captures Oracle change events by using the native Oracle LogMiner or the XStream API.
Debezium CDC Explained and a Great Alternative CDC Tool
Debezium’s Oracle Connector
Oracle DB is used widely in conventional enterprise applications and has many use cases – in ERP, cloud-native data implementations, organizational department systems etc. Debezium’s Oracle Connector can capture changes in data from transactional logs and enable their use for data warehousing, real-time replication, and analytics. Debezium leverages the Kafka Connect framework for its connectors. BryteFlow for Oracle CDC
How Debezium’s Oracle Connector works for Kafka CDC
CDC identifies and captures changes happening in database tables at the row level and sends the relevant changes to a data streaming bus. The Debezium connector enables you to connect to the database and get updates from the stream of events happening at source. The connector captures transactions including schema and data changes into Kafka Topics. These can be further used by streaming ETL pipelines or replication tools. Oracle CDC: 13 things to know
Debezium uses Oracle’s LogMiner component (included in Oracle database utilities) to ingest change events with its user-friendly yet sophisticated interface for querying redo log files. At the beginning the Debezium Oracle Connector executes a consistent initial snapshot of the database to generate a complete history of the database. After that the Debezium connector carries on streaming from the position it reads from the current SCN (system change number) in the redo log. Connect Oracle to Databricks and Load Data the Easy Way
Third party Oracle Kafka Connector for CDC: BryteFlow
If you need to use Kafka for data stream processing or message queueing, you can use implementations with native Kafka connectors or use BryteFlow as a source connector. BryteFlow is a completely automated CDC ETL tool that handles Oracle Kafka CDC with ease. At the time of writing, we have already ramped up throughput 1000X as a performance improvement. Oracle to Postgres Migration
Creating a Source Connector for Oracle CDC to Kafka with BryteFlow
BryteFlow Ingest: Oracle to Kafka Connector
BryteFlow can replicate data in near-real time from Oracle (All Versions) to Kafka.
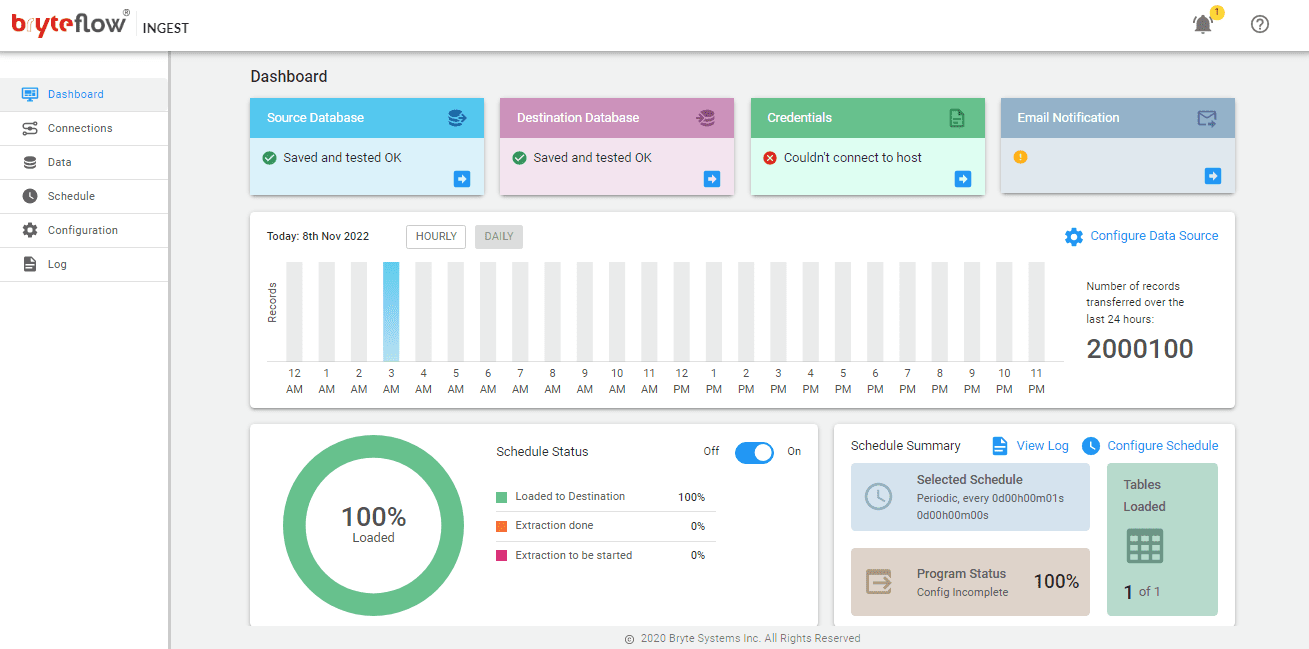
To setup the Oracle to Kafka CDC pipeline in Ingest, all you need is to configure source endpoint, configure destination endpoint and specify a replication schedule. It is extremely easy and intuitive to set up an Oracle to Kafka CDC connector with the point and click interface. Here are the steps:
- Setting up the Oracle source connector:
To begin with Oracle DB as a source, please follow the prerequisites as mentioned here: https://docs.bryteflow.com/bryteflow-ingest-user-guide#verification-of-source
To set up the source database connection to Oracle in BryteFlow Ingest follow the steps below:
- Go to ‘Connections’ tab in Ingest and select the source database type as ‘Oracle Continuous LogMiner (19C)’ and provide the db host, port and user credentials.
- Test the connection of the application by clicking on ‘Test Connection’, this should be successful in order to begin with replication.
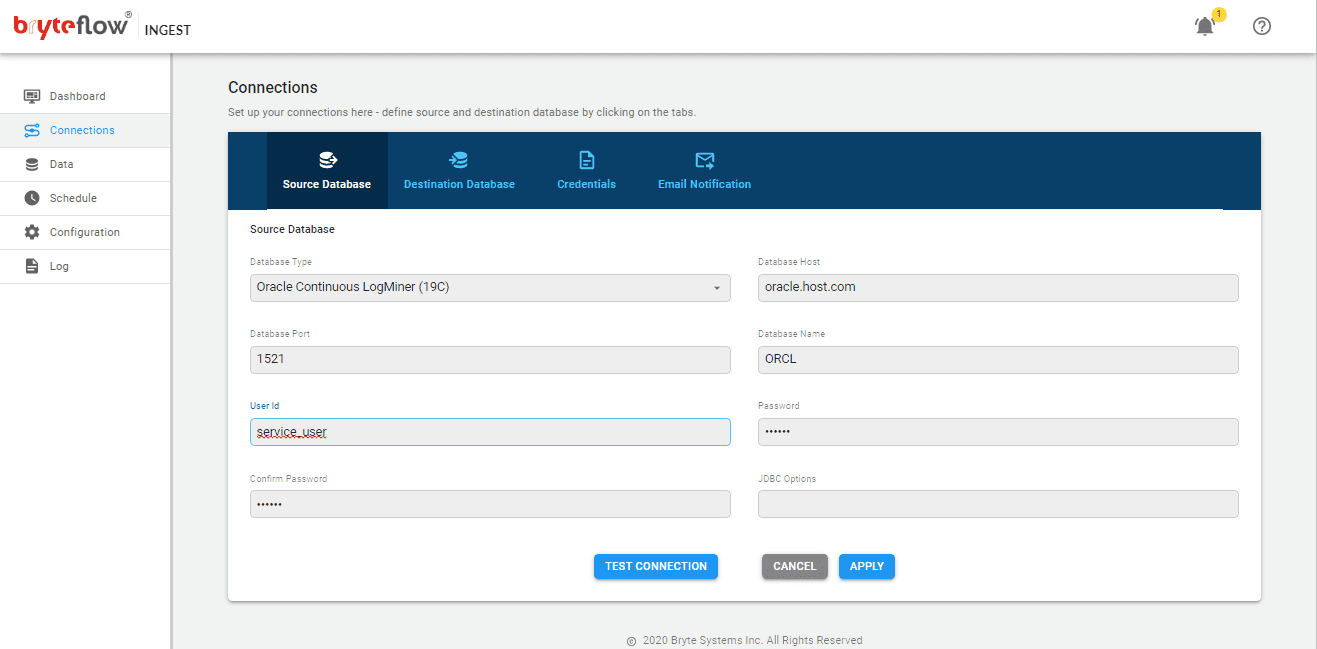
2. Setting up the Destination Kafka Connector:
BryteFlow Ingest supports Apache Kafka as a destination. It integrates changes into the Kafka location.
Kafka Message Keys and Partitioning is supported in BryteFlow. The Kafka messages contain a ‘key’ in each JSON message and messages can be put into partitions for parallel consumption.
BryteFlow Ingest puts messages into Kafka Topic in JSON format by default.
The minimum size of a Kafka message sent is 4096 bytes.
Prerequisites for Kafka as a target:
- Kafka Host URL or Kafka Broker
- Kafka Client
- Kafka Topic Name
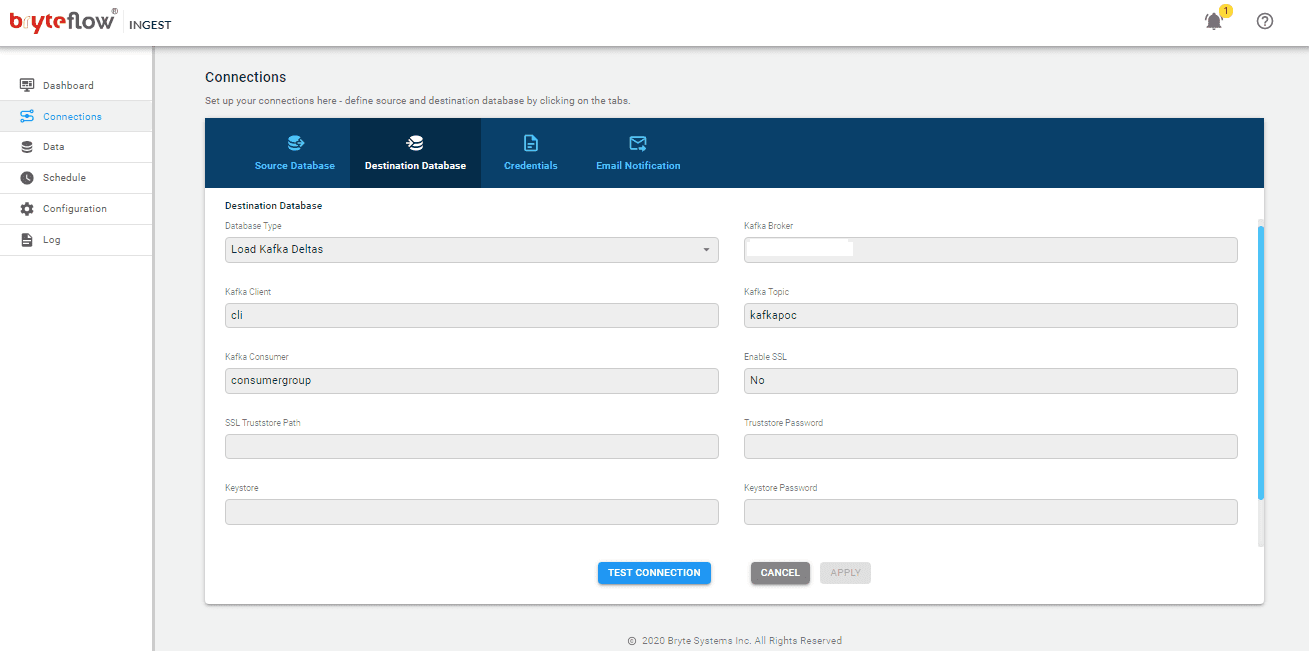
3. Adding objects/tables to the pipeline
To select the table for transferring to the Kafka destination database perform the following steps.
- Go to ‘Data’ tab and expand the Database.
- Browse to the table you want to be synced.
- Select the checkbox next to the table and then click on the table.
- On the right-hand side pane, select the type of transfer for the table i.e. By Primary Key or By Primary Key with History. With the Primary Key option, the table is replicated like for like to the destination. With the Primary Key with History option, the table is replicated as time series data with very change recorded with Slowly Changing Dimension type2 history (aka point in time)
- In the Primary Key column, select the Primary Key for the table by checking the checkbox next to the column name.
- You can also mask a column by checking the checkbox. By masking a column, the selected column will not be transferred to the destination.
- Type Change can be specified for the columns that needs a datatype conversion by selecting the ‘TChange’ checkbox against the column(s).
- Click on the ‘Apply’ button to confirm and save the details
4. Assign the ‘Schedule’ for incremental/ongoing loads
Please assign a periodic schedule to the pipeline by specifying the interval in the ‘Schedule’ tab. It can be at regular intervals as low as a second, or a daily extraction can be done at a specific time of the day by choosing hour and minutes in the drop-down. Extraction can also be scheduled on specific days of the week at a fixed time by checking the checkboxes next to the days and selecting hours and minutes in the drop-down.
The pipeline is ready to begin CDC replication from the Oracle source to Kafka. Begin by doing a first Initial sync by clicking on ‘Full Extract’. Thereafter the incremental loads will happen at the assigned schedule.
Oracle CDC to Kafka Tool Highlights
- Bryteflow serves as an automated source CDC connector from Oracle to Kafka and for other RDBMS sources like SAP, SQL Server, and Postgres. Real-time Oracle to SQL Server Migration
- BryteFlow provides real-time log-based CDC from Oracle to Kafka using Oracle LogMiner and transaction logs. No coding involved. Change Data Capture Types and Automating CDC
- BryteFlow Ingest extracts data in 8 seconds and the end-to-end process takes under 30 seconds Oracle Kafka CDC.
- BryteFlow handles partitioning on Kafka with no coding. This can be specified as a configuration.
- Kafka JSON Format can be specified as a configuration as well.
- BryteFlow populates the Kafka schema registry automatically.
- BryteFlow offers remote log mining with Oracle LogMiner so logs can be mined on a separate server and there is no impact on the source server. Oracle to Snowflake: Everything You Need to Know
- Supports large bulk loads with multi-threaded parallel and partitioning, to load large data volumes with high speed.
- BryteFlow has high availability and automated network catchup
- BryteFlow has a user-friendly Point and Click UI, real-time dashboards and monitoring to monitor Oracle Kafka integration.
- As a CDC tool, BryteFlow can be deployed on-premise, on any major cloud, or even as a hybrid combination. BryteFlow for Oracle Replication
- BryteFlow provides replication support for all Oracle versions, including Oracle 12c, 19c, 21c and future releases for the long term and the replication is at least 6x faster than Oracle Goldengate. Real-time Oracle Replication step by step




