Replicate data in real-time to your Snowflake Data Lake. Reduce Snowflake compute costs.
The case for building a Data Lake on Snowflake AWS or Snowflake Azure
A single repository for all your raw data is a compelling proposition. The Snowflake Data Lake whether on AWS or Azure, can be used to store data from all your disparate sources and create real-time dashboards to report on the data quickly or run analytics to uncover fresh insights. An Alternative to Matillion and Fivetran for SQL Server to Snowflake Migration
Replicate in real-time and get ready-to-use data to your Snowflake Data Lake without coding
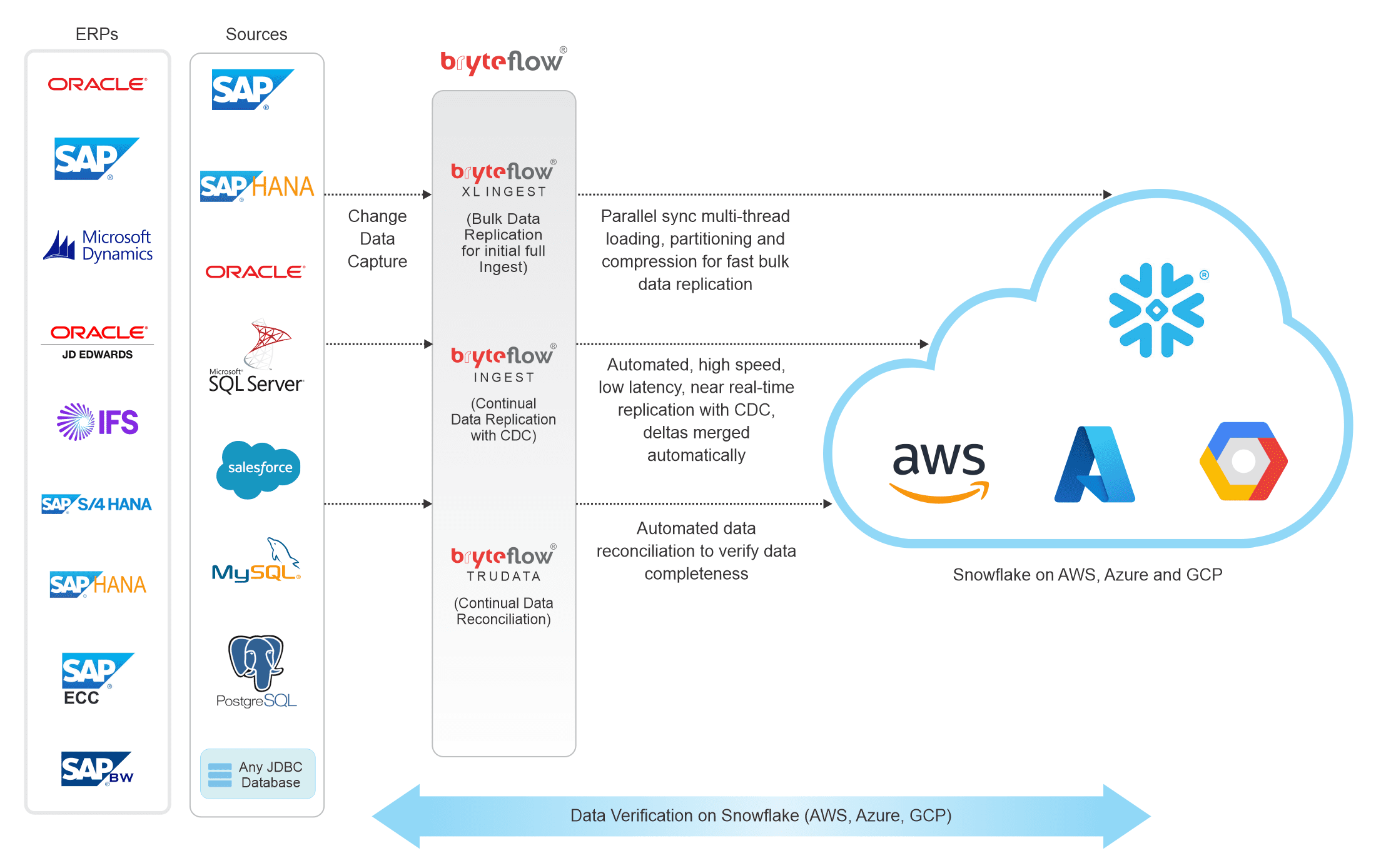
BryteFlow replicates data to your Snowflake Data Lake in real-time, without coding. BryteFlow is a completely automated data replication tool and does this in a couple of ways:
Directly: It replicates data from transactional sources to the Snowflake data warehouse in real-time using proprietary log-based Change Data Capture technology, it merges and transforms data automatically, making it ready for use instantly. Snowflake ETL with BryteFlow
Indirectly: It loads data from the sources in real-time to Amazon S3 in ready-to-use formats like Parquet, ORC etc., transforms the data if required and then loads it to the Snowflake data warehouse for analytics. Postgres to Snowflake : 2 Easy Methods of Migration
BryteFlow uses enterprise log-based change data capture on legacy databases like Oracle, SQL Server, SAP, MySQL and more, and from applications like Salesforce etc. to move data from the sources to the Snowflake data warehouse in real-time. It maintains a replica of the source structures in Snowflake and merges the initial and delta loads automatically with SCD type 2 history if required.
SQL Server to Snowflake in 4 Easy Steps
Snowflake CDC With Streams and a Better CDC Method
Databricks vs Snowflake: 18 differences you should know
Here’s Why You Need Snowflake Stages (Internal & External)
Loading data into Snowflake Data Warehouse
Set up your Snowflake Data Lake in one day.
BryteFlow’s automated Snowflake ETL process makes data integration a breeze.
FREE TRIAL
We offer complete support on your free trial including screen sharing, online support and consultation.
Are you looking to set up your Snowflake Data Lake fast? Or possibly you already have one and are looking for data migration to Snowflake? BryteFlow represents the easiest and fastest route to Snowflake.
No-code, self-serve data migration to the Snowflake data warehouse with our automated data replication tools for Snowflake
When migrating data to Snowflake you need to have a data replication solution that will get you there with minimum effort and minimum time. BryteFlow Ingest is ideal for Snowflake ETL since it is a completely automated data replication tool for Snowflake and the AWS environment. After you configure your account on Snowflake, you can install BryteFlow and connect to sources with just a couple of clicks -you should be up and running in a day. Your tables are created automatically on Snowflake – no coding needed! Databricks vs Snowflake: 18 differences you should know
Bulk data ingestion? Upload data to Snowflake fast
If you have huge datasets to replicate, bulk ingestions to your Snowflake data lake or data warehouse are easy. BryteFlow XL Ingest uses smart partitioning, compression and multi-thread parallel loading to ingest petabytes of data in minutes.
How to load terabytes of data to the Snowflake data warehouse fast
Get reconciled data on you Snowflake data warehouse or data lake
No more worries about missing data or incomplete data – BryteFlow is the only data integration tool for Snowflake that offers built-in data reconciliation. BryteFlow Trudata reconciles data in the Snowflake data warehouse with data at source and alerts you if data is missing so you can rest easy. SQL Server to Snowflake in 4 Easy Steps
Reduce Snowflake Compute Costs
BryteFlow uses the lowest compute when replicating data to Snowflake. It has best practices for Snowflake baked in and replicates data to Snowflake fast, capturing only incremental loads after the initial full ingest. You can deploy in one day and get delivery of data in less than 2 weeks. How to cut down Snowflake costs by 30%
Fast Data Ingestion to the Snowflake Data Warehouse
BryteFlow provides Snowflake replication in real-time without coding. Here’s what you can do with BryteFlow on your Snowflake data lake or data warehouse. Get a Free Trial of BryteFlow





Change Data Capture your data to the Snowflake data warehouse with history of every transaction
BryteFlow continually replicates data to the Snowflake data lake in real-time, with history intact, through log based Change Data Capture. BryteFlow Ingest leverages the columnar Snowflake database by capturing only the deltas and merging them automatically with existing data, keeping data in the Snowflake data warehouse synced with data at source. Snowflake CDC With Streams and a Better CDC Method
Data is ready to use – Get data to dashboard in minutes
BryteFlow Ingest on the Snowflake data warehouse provides a range of data conversions out of the box including Typecasting and GUID data type conversion to ensure that your data is ready for analytical consumption or for Machine Learning purposes. Change Data Capture Types and CDC Automation
Transfer data with speed and performance to Snowflake
BryteFlow Ingest uses fast log-based CDC to replicate your data to the Snowflake data warehouse. Data is transferred to the Snowflake data lake at high speeds in manageable chunks using compression and smart partitioning.
How to load terabytes of data to Snowflake fast
Automated DDL and performance tuning in the AWS-Snowflake environment
BryteFlow helps you tune performance on the AWS-Snowflake environment by automating DDL (Data Definition Language) which is a subset of SQL.
SQL Server to Snowflake in 4 Easy Steps
Snowflake S3 Integration for flexibility in data preparation
BryteFlow offers Snowflake S3 integration so you have the choice of transforming and retaining data on AWS S3 and pushing it selectively to Snowflake data warehouse – for multiple use cases including Analytics and Machine Learning. Or replicating and transforming data directly on the Snowflake data lake itself.
Postgres to Snowflake : 2 Easy Methods of Migration
ETL or ELT your data in Snowflake
BryteFlow frees up the resources of the Snowflake data warehouse by preparing your data on Amazon S3 and only pushing the data you need for querying onto Snowflake. You can also extract, load and transform (ELT) data in Snowflake directly.
Snowflake S3 Storage Integration
You can choose to save all your data on Amazon S3 where typically storage costs are much lower. On the Snowflake data warehouse you need to only pay for the resources you actually use for the compute – this can translate to a large savings on data costs. This Snowflake S3 storage integration also enhances the performance of the Snowflake cluster. Integration on Amazon S3
Automated Data Reconciliation on the Snowflake data warehouse
You are assured of getting high quality, reconciled data always with BryteFlow TruData, our data reconciliation tool. BryteFlow TruData continually reconciles data in your Snowflake data lake or data warehouse with data at source. It can automatically serve up flexible comparisons and match datasets of source and destination. Databricks vs Snowflake: 18 differences you should know
Ingest large volumes of data automatically to your Snowflake database with BryteFlow XL Ingest
If you have huge petabytes of data to replicate to your Snowflake data lake or data warehouse, BryteFlow XL Ingest can do it automatically at high speed in a few clicks. BryteFlow XL Ingest is used for the initial full ingest in case of very large datasets. It uses smart partitioning and parallel sync with multi-thread loading to load bulk data fast.
Dashboard to monitor data ingestion and data transformation instances on the Snowflake data warehouse
Stay on top of your data ingestion and data transformationto the Snowflake data lake or data warehouse with the BryteFlow ControlRoom. It displays the status of BryteFlow Ingest and BryteFlow Blend instances displaying latency, operation start time, operation end time, volume of data ingested, transformation jobs etc.
Data transformation with data from any database, incremental files or APIs
BryteFlow Blend our data transformation tool enables you to merge and transform data from virtually any source including any database, any flat file or any API for querying on your Snowflake data lake or data warehouse.
No-code, automated data migration from Teradata and Netezza to the Snowflake data warehouse
BryteFlow can migrate your data from data warehouses like Teradata and Netezza to your Snowflake data warehouse without coding. BryteFlow automatically creates your tables on Snowflake – no coding needed. About Snowflake Stages
Get built-in resiliency for data integration on Snowflake
BryteFlow has an automatic network catch-up mode. It just resumes where it left off in case of power outages or system shutdowns when normal conditions are restored. This is ideal for Snowflake’s big data environment which routinely handles data ingestion and preparation of thousands of petabytes of data.
An Alternative to Matillion and Fivetran for SQL Server to Snowflake Migration
The advantages of creating a
Snowflake Data Lake
A Snowflake Data Lake provides the flexibility to store and use your data as you choose.




Raw data for Machine Learning and AI in your Snowflake data lake
Unlike a data warehouse which stores data in structured format, a Snowflake data lake has the ability to store tons of raw data that can be used successfully for Machine Learning and AI purposes. You can model the raw data the way you want using BryteFlow Blend with Apache Spark to build models for Machine Learning.
Storage costs are low on the Snowflake data lake
The Snowflake data lake allows you to store all of your data at a lower cost. You don’t have to sift through and discard data on account of your budget. You only pay for compute when you are loading or querying data.
The Snowflake data lake gets rid of your data silos
You are not restricted by formats on the Snowflake data lake. Data can be stored in its native form including structured and semi-structured data (JSON, CSV, tables, Parquet, ORC, etc.). All kinds of data types can be collected and stored.
A Snowflake data lake offers instant elasticity and unlimited scalability
Being in the cloud means you can dynamically scale up compute resources on the Snowflake data lake as per required without impacting running queries or even enable the resources to scale up automatically when there is heavy concurrency.
You can accommodate all your users on the Snowflake data lake
The Snowflake data lake supports heavy concurrency and a huge number of workloads. An unlimited number of users can query a single copy of data without any impact on performance.
Snowflake data is extremely secure
The Snowflake data warehouse automatically encrypts all data. Multi-factor authentication and granular access control is reassuring. The Snowflake cloud data warehouse uses third party certification and validation to make sure security standards are met. Access control auditing is available for everything including data objects and actions within your Snowflake data lake.
The Snowflake data lake is fully automated as is Bryteflow
Built-in monitoring, performance tuning and best practices are all accounted for, so you can focus on getting the most out of your data.
Using BryteFlow to replicate, merge and transform data on your Snowflake data lake or data warehouse makes for a seamless, fast performance and even faster access to insight.
Read: How to load terabytes of data to the Snowflake data warehouse fast