
This blog provides an overview of Debezium, a widely used Change Data Capture platform, the ways Debezium CDC can be deployed, its advantages and disadvantages. It also introduces BryteFlow as an alternative to Debezium CDC, comparing them and showcasing BryteFlow’s unique features that makes it an ideal software for enterprise-scale, real-time Change Data Capture.
Quick Links
- Change Data Capture – What It Is
- Change Data Capture with Debezium
- How Debezium CDC Works
- Debezium CDC Architecture
- Can you use Debezium independently of Kafka?
- Debezium Change Data Capture Advantages
- Why you need an alternative to Debezium
- Disadvantages of Debezium – Some Limitations
- BryteFlow, a No-Code, Real-Time, CDC Tool
- BryteFlow as a Debezium Alternative: The Differences
- BryteFlow CDC Highlights
Change Data Capture – What It Is
Change Data Capture, or CDC, is the process that monitors changes that happen in a source system and replicates them with the needed transformations on the target database or storage system in real-time. The primary purpose of CDC is to ensure that multiple data systems are synchronized with the source almost immediately, in contrast to the batch method that processes changes at predefined intervals. The latter very often results in delayed responses, bottlenecks and slowing down of source systems, and is not conducive to real-time business insights or data requirements. Oracle CDC: 13 Things to Know
Change Data Capture enables users to have access to the latest data and efficiently replicates data to analytics platforms like Snowflake or Databricks, allowing critical business decisions to occur precisely when they are most relevant. CDC serves modern Cloud architectures well, facilitating real-time data replication between databases and automating the synchronization of target databases, eliminating the need for time-consuming bulk load updates. CDC is focused on the INSERT, UPDATE, and DELETE transactions in the database. There are several methods of enabling Change Data Capture, including Triggers, Timestamps, Snapshots and Log-based CDC. Continuous CDC replication is integral for real-time analytics, data science purposes and cloud migrations where zero-downtime is necessary. SQL Server CDC for Real-Time Replication
Change Data Capture with Debezium
What is Debezium?
Debezium is a distributed, open-source, low-latency, data streaming platform for Change Data Capture that is built on Apache Kafka and uses it to facilitate CDC. Debezium basically treats your existing databases as event streams, so applications can view and respond to the changes accordingly in real-time. Debezium’s core function is to monitor and record row-level changes in source database tables by way of transaction logs, allowing applications to respond to incremental data changes (new entries, modifications, and deletions). Debezium has 4 main components: Apache Zookeeper, Kafka, Kafka Connect and DB Connector. How to install Kafka
Overview of Debezium CDC
Debezium CDC largely uses transaction log files. SQL Server, Postgres, and other transactional databases keep a list of log files so that slave/master databases are in sync. The changes that happen in any row are recorded in the log files. Debezium connectors that work with Kafka Connect, stream these files, and the files are then stored in a Kafka Topic. Each Kafka Topic co-relates to an individual table in the database and each Kafka Connect service corresponds to a particular instance of the database. Please note, there can be many connectors deployed with a Kafka Connect cluster. This enables data to be consumed by multiple consumer applications through sink connectors. Learn about Kafka CDC
Debezium continuously tracks database changes and enables various applications to stream these changes in chronological order (in the same sequence they occurred). You can use the event streams to update caches, search indexes, create derived data, synchronize other data sources, and more, transferring this functionality from your applications to separate services. BryteFlow’s Data Integration on Kafka
Debezium offers connectors for databases like MySQL, MongoDB, PostgreSQL, SQL Server, Oracle, and others, allowing the monitoring and recording of database changes. The connectors support various output data formats, including Avro, JSON Schema, Protobuf, and schemaless JSON. Each table’s events are recorded in individual Kafka topics for easy consumption by applications and services. Additionally, Debezium connectors are fault-tolerant, saving event positions in the database log. If a Debezium connector encounters interruptions, it can resume reading from the last recorded position after a restart, ensuring no events are missed. Oracle to Kafka with BryteFlow
How Debezium CDC Works
Debezium as a platform, consists of a huge set of CDC connectors designed for Apache Kafka Connect. Each connector is tailored to extract modifications from diverse source databases, leveraging their inherent Change Data Capture (CDC) capabilities. When a Debezium connector initially connects to a database or cluster, it captures a consistent snapshot of the table data and database schemas. Once this snapshot is secured, the connector consistently tracks changes at the row level, covering INSERT, UPDATE, or DELETE actions committed to CDC-enabled databases. By initially establishing a uniform data view, the connector continually reads changes without skipping any modifications that happened during the snapshot process. Please note, that a table created after the snapshot process has begun, will be skipped by the Debezium connector. The change events for these tables will be transmitted later after the snapshot is complete, when the connector starts streaming. For every data change, the Debezium connector generates events and channels them to a Kafka topic. Each table’s events are streamed to a specific Kafka topic, allowing applications and services to consume these data change records from the designated topic. SQL Server to Kafka with BryteFlow
How Debezium enables CDC in the Source Server
For the Debezium connector to record database changes, enabling CDC on the database is crucial. This action generates the essential schemas and tables housing the history of changes in the specified tracked tables. CDC activation is required at both the overall database level, and individually on each desired table for capture. Once CDC is configured in the source database, the Debezium connector can then capture INSERT, UPDATE, and DELETE operations at a row level. Event records are written by the connector to a distinct Kafka topic for each table being captured. Applications accessing these Kafka topics can interpret and act upon the received row-level events pertinent to the associated database tables. Postgres CDC (6 Easy Methods to Capture Data Changes)
Debezium CDC Architecture
Debezium architecture is three-pronged, consisting of three main elements – external source databases, the Debezium Server and downstream applications like Amazon Kinesis, Google Pub/Sub, Redis and Pulsar. Debezium Server acts as a middleman, capturing and streaming data changes in real-time between external source systems and consumers. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
Debezium’s source connectors track and capture real-time changes from databases and store the change updates in Kafka topics within the Kafka servers. The captured changes become part of the commit log. The commit log organizes and stores the messages in the order received, so consumers can get data updates in the right sequence. The change event records are then fetched from the Kafka topics by downstream applications through use of the sink connectors like ElasticSearch and the JDBC connector. Learn about Kafka CDC
Implementing Debezium relies on your existing infrastructure, but most frequently, Apache Kafka Connect is the framework it is based on. Kafka Connect functions as an independent service in conjunction with the Kafka broker. It facilitates the seamless transfer of data between Apache Kafka and various external systems. Further, it allows the creation of connectors to efficiently move data both in and out of Kafka. The connectors include Source connectors such as Debezium that move data from source systems into Kafka and Sink connectors that move data out of Kafka to target systems like data warehouses, Elasticsearch, analytics systems and caches. SAP to Kafka with BryteFlow
Debezium Connectors – detecting and capturing data changes for Debezium CDC
Debezium works as a Source connector, recording the changes as they happen in the database management systems. Every Debezium connector is specific to a particular DBMS. (e.g. Debezium Connector for Oracle, Debezium Connector for PostgreSQL) The Debezium connector detects changes happening in its particular DBMS in real-time via the database transaction logs, and streams a record of each event to a Kafka topic. Sink connectors then transmit the change events to downstream applications, which can then consume the change event records. Also learn about Postgres CDC
Debezium CDC is highly fault-tolerant and reliable
In case there is an application shutdown or loss of connection, Debezium ensures no event that occurred during the outage is missed. The application resumes reading the topic from the point of stoppage once it restarts. By using the dependable streaming of the Kafka platform, Debezium enables applications to consume database changes completely and accurately. Installing Debezium Connectors
This diagram represents the typical CDC architecture based on Debezium and Kafka Connect.
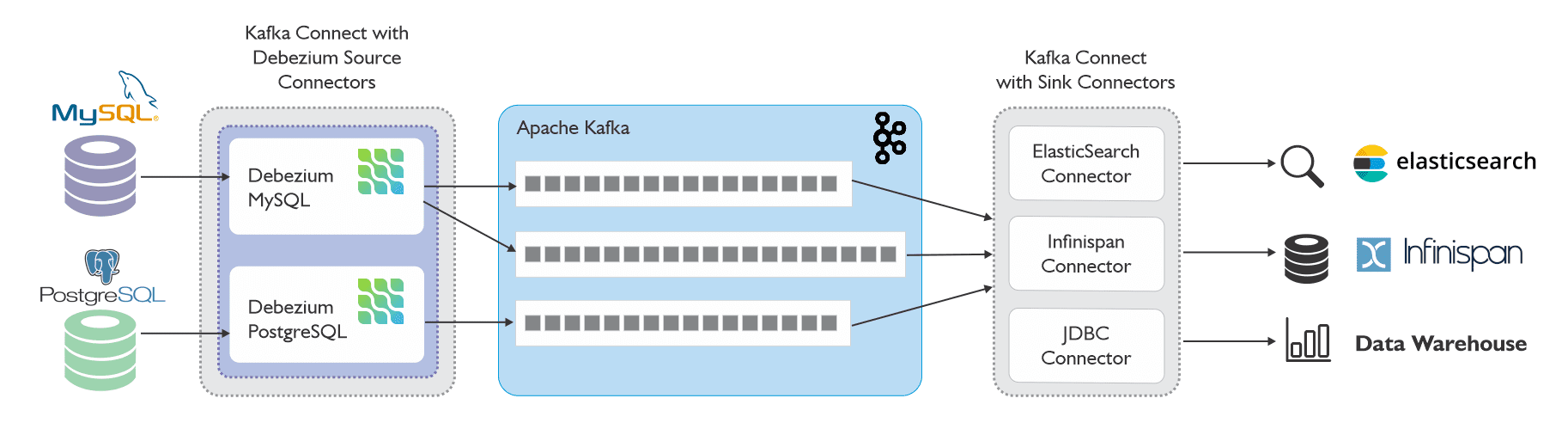
Debezium integrates Kafka within its architecture, while also providing alternative deployment options to meet varied infrastructure requirements. It can function either as an independent service utilizing the Debezium server, or it can be incorporated into your application code as a library.
Debezium Server is an adaptable, configurable, and ready-to-use application designed to seamlessly stream change events from a source database to diverse messaging infrastructures. It is a standalone Java application built on the Qurkus framework. The application itself contains the core module and a set of modules responsible for communication with different target systems. The server is set up to employ one of the Debezium source connectors for capturing database changes. These change events can then be transformed into various formats, such as JSON or Apache Avro, before being dispatched to a range of messaging infrastructures, including but not limited to Amazon Kinesis, Redis, Google Cloud Pub/Sub, or Apache Pulsar.
The following image illustrates the structural design of a Change Data Capture pipeline employing the Debezium server.
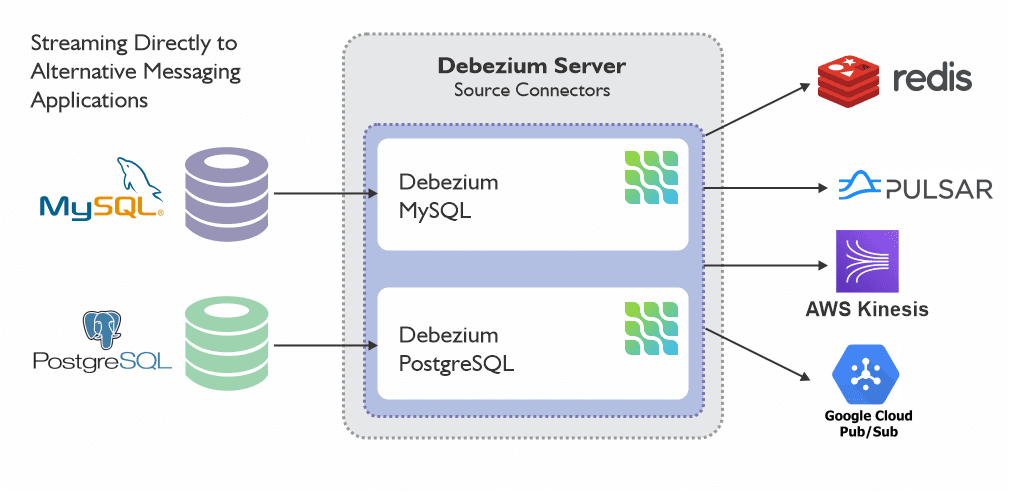 Embedded Debezium Engine
Embedded Debezium EngineEmbedded Debezium engine represents another way to stream changes. If your use case does not need extremely high reliability and you would like to reduce infrastructure costs, you can embed the Debezium engine within your application. In this scenario, Debezium operates not through Kafka Connect but as a library integrated directly into your custom Java application. This approach proves beneficial for consuming change events within your application and avoids the expensive deployment of complete Kafka and Kafka Connect clusters. The Debezium engine enables streaming of change events directly to alternative messaging platforms like Amazon Kinesis, instead of storing them in Kafka.
Can you use Debezium independently of Kafka?
Although Apache Kafka is commonly a part of Debezium-based Change Data Capture (CDC) setups, its usage is not obligatory. Debezium Server has expanded its capabilities to connect with alternative message processing platforms such as Google Pub/Sub, AWS Kinesis, among others. It now supports an embedded mode, allowing the use of custom event subscription and processing mechanisms.
Debezium Change Data Capture Advantages
Debezium enables businesses to swiftly react to database changes with minimal latency. Here are several key attributes of Debezium.
- Data Masking:Debezium provides an option for users to conceal sensitive information like card numbers and bank details, ensuring data privacy during data streaming.
- Incremental Snapshots: Supports incremental snapshot creation through signaling.
- Message Transformation: Debezium offers various message transformations for tasks like message routing, filtering, and event flattening.
- Database Authentication: Debezium utilizes password authentication.
- Filters: Debezium allows configuration of schema, table, and column capture settings using include/exclude list filters.
- Low Latency Streaming: Debezium enables real-time data updates even in low latency settings by using Kafka Connect, to promptly capture change data.
- Tasks per Connector: Organizations can operate multiple Debezium connectors with a restriction of one task per connector (“tasks.max”: “1”).
- Monitoring: Most Debezium connectors can be monitored through JMX.
- Comprehensive Capture: Debezium ensures the capture of all data changes.
- Automatic Topic Creation: Debezium automatically generates Kafka topics using a specific naming convention and predefined properties for tables. (e.g.”Maximum Message Size”).
- Minimal Delay: Generates change events with extremely low latency without significantly increasing CPU usage. For instance, for MySQL or PostgreSQL, the delay is within the millisecond range.
- Snapshot Mode: Permits defining criteria for running a snapshot without necessitating alterations to the existing data model.
- Deletion Capture: Debezium has the capability to capture table deletes.
- Tombstones on Deletion: Debezium allows for configuration to decide whether a tombstone event should be created post a delete event; default setting is true.
- Capture Capabilities: Debezium can capture the previous record state and additional metadata, like transaction ID and causing query, based on the database’s capabilities and setup.
- Table Inclusion and Exclusion: Enables the selection of tables to monitor for changes, with the default setting monitoring all non-system tables.
- Output Formats: Supports Avro, JSON Schema, Protobuf, or JSON (schemaless) output for Kafka record values and various formats for Kafka record keys. Schema Registry integration is required for Schema Registry-based formats like Avro, JSON Schema, or Protobuf.
Why you need an alternative to Debezium
Debezium, despite being open-source and free, incurs substantial hidden costs due to the significant engineering effort and expertise required to set up Change Data Capture (CDC) pipelines. Moreover, finding skilled engineers to manage these pipelines is challenging and expensive. Often, data pipelines designed to solve immediate problems overlook long-term implications and evolving system needs. As an organization expands, this can lead to pipeline overloads, emphasizing the importance of seeking scalable and well-supported solutions. Implementing Debezium-based production pipelines poses multiple obstacles, necessitating a proficient team with technical knowledge in Kafka and DevOps for ensuring scalability and reliability due to inherent architectural limitations. This is where a CDC tool like BryteFlow wins, because it is completely automated and self-service. An ordinary business user can use it with ease, with no or minimal involvement of your DBA or tech resources, leading to high ROI. Automating Change Data Capture
Disadvantages of Debezium – Some Limitations
The following are some of the limitations of Debezium:
- Manual intervention is necessary for getting historical data: Setting up a new consumer that requires both historical and real-time change events might require manual effort for historical data loads while performing Debezium CDC. This need arises unless the data is continuously stored in a Kafka log (which can be costly) or the topic can be suitably compacted. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
- Ensuring zero data loss: Dealing with performance, availability, and potential data loss becomes a concern, especially when using Debezium CDC to handle large tables. Achieving absolute data integrity and zero loss is not guaranteed if any component in the system fails. The responsibility for maintaining integrity lies solely with the development team, which is an onerous task.
- Specific expertise required for Debezium CDC and associated packages: Proficiency in Kafka, Kafka Connect, and ZooKeeper is essential for data teams intending to establish Change Data Capture (CDC) pipelines using Debezium. ZooKeeper itself is resource-intensive and requires a comprehensive tech stack. Mastery in Java is also crucial for managing the implementation process. 6 Reasons to Automate Data Pipelines
- Ensuring scalable pipeline architecture: Despite the numerous connectors Debezium has, scalability issues can arise with certain connectors. For instance, even with widely used databases like Postgres, problems such as out-of-memory exceptions might occur when employing plugins like wal2json to convert write-ahead log outputs to JSON. Moreover, the inability to snapshot tables while allowing incoming events can lead to prolonged unavailability of tables, especially with large datasets. BryteFlow XL Ingest for heavy data
- Manual handling of complex schema changes and migrations: Change Data Capture with Debezium does not seamlessly manage schema evolution. While there is support for schema evolution in some source databases, the implementation process differs across various databases. Consequently, substantial custom logic needs to be developed within Kafka processing to manage schema evolution effectively. Although Debezium CDC can transmit row-level changes to the Kafka topic (unless in a snapshotting state), schema changes that are more complex must be manually handled.
- Supporting diverse data types across connectors: Certain connectors have limitations concerning specific data types. For example, Debezium’s Oracle connector faces constraints in handling BLOB data types.
- Table Restriction: Debezium snapshotting for CDC renders tables inaccessible during the process.
- Limitation on the connector: Entities can operate multiple connectors, however each is limited to one task per connector (i.e., “tasks.max”: “1”).
- Directory authentication: Presently, there is no support for Active Directory authentication.
- Network Restrictions: Various network access restrictions for Debezium CDC might be present based on the service environment. Ensure that the Debezium connector has access to your service. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
- Event Overflow: Accumulated pipelines and data loss due to rapid creation of millions of change events by DML.
These constraints present significant challenges when developing enterprise CDC pipelines using Debezium, emphasizing the importance of alternative solutions like BryteFlow. CDC with BryteFlow
BryteFlow, a No-Code, Real-Time, CDC Tool
BryteFlow is no-code software for real-time data replication to Cloud and on-premise destinations. It uses automated log-based CDC to replicate data from transactional databases like SAP, Oracle, PostgreSQL, MySQL and SQL Server to Cloud platforms like Amazon S3, Amazon Redshift, Snowflake, Azure Synapse, Azure Data Lake 2, PostgreSQL, Google BigQuery, SQL Server, Teradata, Kafka and Databricks in real-time. BryteFlow delivers ready-to-use data on the destination and operates through a user-friendly graphical interface. It is self-service and easily supports transfer of very large data volumes. BryteFlow Ingest stands out for its powerful enterprise-grade replication and is capable of transferring petabytes of data within minutes — approximately 1,000,000 rows in just 30 seconds. BryteFlow can be deployed in just a couple of hours, with delivery of data in only 2 weeks, as compared to months taken by competitors. How BryteFlow Works
BryteFlow as a Debezium Alternative: The Differences
Here you can compare how using BryteFlow instead of Debezium for replication can make your task easier.
| Feature | Debezium | BryteFlow |
| ELT | Only performs Extract. Loading and Transformation operations need to be coded. | Performs full ELT with automated extraction, merging, schema and table creation and data type conversion. |
| Scalability | May face scalability issues with certain connectors. Logical decoding plug-ins like wal2json can run out of memory in case of large volumes of data. | No issues, can handle immense volumes of enterprise data without impacting source systems. |
| Schema | Does not handle schema evolution very well. Needs coding for custom logic and complex schema changes | Creates schema automatically without coding. Handles complex schema changes automatically. |
| Data Types | Some Debezium connectors do not support certain data types. For e.g. Oracle connector has restrictions in handling the BLOB data type. | BryteFlow provides data type conversions automatically, without limitations. |
| Software Type | Open-source | Commercial |
| Affordability and Speed | Though open-source, costs can add up due to the requirement for engineering resources needed to run Kafka, Kafka Connect, and ZooKeeper. The need to code also increases time to data. | Self-service tool can be easily used by any business user via the user-friendly GUI. Can be deployed in a couple of hours. Delivery of data is within 2 weeks. |
| Target | Small to mid-sized enterprises. | Mid, large, and very large enterprises. |
| Data Validation | No built-in data validation tools. | Seamless automated data reconciliation with BryteFlow Trudata to check incomplete or missing data. |
| Impact of CDC | Snapshotting is incremental and not concurrent. Large tables with millions of rows may need hours to snapshot. Snapshotting process makes tables inaccessible till it is finished. | CDC is log-based. Replicates with parallel, multi-thread loading, partitioning and compression. This does not impact source systems.
|
| Historical Data Loading | Need to manually trigger DB for historical data if a consumer application needs both -historical and real-time change events, (storing data in a Kafka log permanently is expensive). | SCD Type2 data is automatically available as an option, so data versioning and getting historical data is easy.
|
BryteFlow CDC Highlights
- Cuts down on time spent by DBAs on implementation, by providing entirely no-code CDC replication processes. These include data extraction, Change Data Capture, merging, masking, schema and table creation, SCD-Type2 data and more. How BryteFlow Works
- BryteFlow provides completely automated CDC to Kafka and has a multi-threaded, log-based Change Data Capture system, ensuring high throughput and efficiency. Also learn about Oracle CDC, Postgres CDC and SQL Server CDC
- BryteFlow enables data extraction from SAP, at application level (keeping business logic intact) and at database level through the use of the BryteFlow SAP Data Lake Builder.
- Effortlessly performs ELT operations on Snowflake, S3, Redshift, and PostgreSQL in real-time without the need for coding. BryteFlow Blend seamlessly manages the data transformation.
- BryteFlow has an intuitive visual interface and delivers data that is ready to use, with automated data type conversions.
- BryteFlow XL Ingest transfers huge data volumes for the initial full refresh of very heavy datasets with multi-threaded parallel loading, configurable partitioning, and compression.
- BryteFlow Ingest loads incremental data and deltas, merging the updates, deletes and inserts with existing data. Successful Data Ingestion (What You Need to Know)
- Our replication software boasts remarkably high throughput, performing 6x faster than GoldenGate, handling approximately 1,000,000 rows in just 30 seconds. About GoldenGate CDC
- The data replication software automates schema and DDL creation at the destination while adhering to best practices for optimal performance.
- It delivers pre-processed data on various cloud platforms such as Amazon S3, Amazon Redshift, Snowflake, Azure Synapse, Azure Data Lake 2, PostgreSQL, Google BigQuery, SQL Server, Teradata, Kafka and Databricks
- BryteFlow TruData enables automated data reconciliation to verify data completeness, contributing to overall data quality.
- The replication system is highly resilient, offering Automated Network Catch-up in the event of power or network outages for uninterrupted operation.
- BryteFlow ControlRoom serves as a monitoring center, displaying the status of each ingest and transform instance.
This blog has provided information on Debezium CDC, its architecture and advantages, the limitations of using Debezium, and introduced BryteFlow as an alternative CDC solution to overcome Debezium’s constraints. If you are interested in experiencing BryteFlow’s replication to Kafka, do contact us for a Demo



