Kafka Connections
SQL Server to Kafka in Real-time
BryteFlow as a SQL Server Kafka Connector
Need to stream your data from SQL Server to Kafka with CDC, in real-time? Bryteflow transfers your SQL server data to Kafka without coding and with complete automation. BryteFlow’s Change Data Capture is low impact and sparing of source systems. All changes in the SQL Server database are delivered in real-time to Kafka. Kafka CDC and Oracle to Kafka CDC Methods
SQL Server CDC Kafka Highlights
- After BryteFlow’s first full one-time load into Topics, subsequent changes in the SQL Server database are delivered to Kafka in real-time with high throughput and low latency using SQL Server CDC or SQL Server CT
- BryteFlow’s replication to Kafka has automated partitioning and compression for a faster, more efficient process
- BryteFlow provides configurable parallel extraction and loading and data is delivered in JSON format to Kafka.
- BryteFlow supports replication from all SQL Server versions and editions. About SQL Server Change Tracking
- The schema registry is populated automatically. Apache Kafka Overview and how to install it
- User-friendly point-and-click interface provides access to automated data flows with no coding required for any process.
- High availability with automated network catch-up. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
BryteFlow for SQL Server
SQL Server vs Postgres – A Step-by-Step Migration Journey
SQL Server CDC To Kafka (Unbelievably Easy New Connector)
No-Code SQL Server Kafka Connector

SQL Server to Kafka CDC is really, really fast
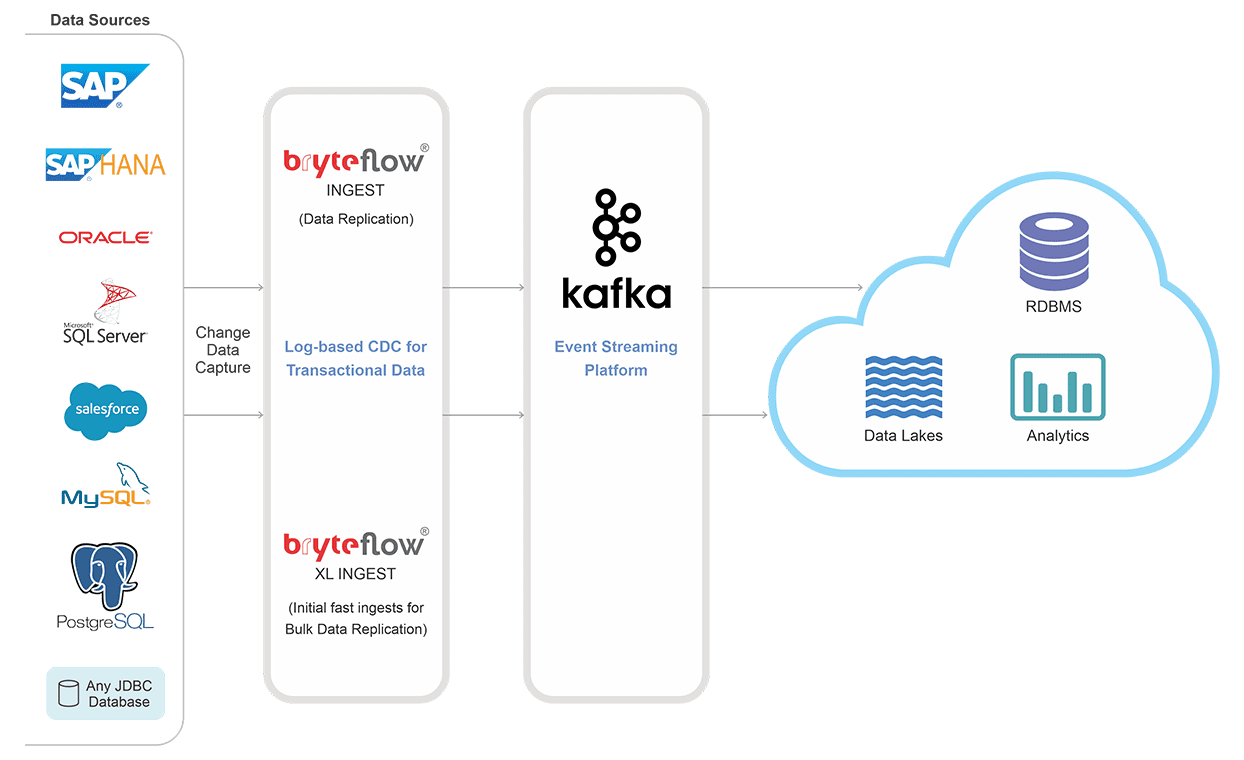
BryteFlow Ingest delivers large volumes of SQL Server data to Kafka in real-time using log-based Change Data Capture or Change Tracking. BryteFlow has very high throughput, replicating a million rows in 30 seconds approx.
Kafka CDC and Oracle to Kafka CDC Methods
Populating the Schema Registry
An feature that is very convenient for users is the automatic population of the Schema Registry with zero coding, making the overall process much faster. Since Kafka moves data only in byte format, the Schema Registry has to provide the schema to producers and consumers by storing a schema copy in its cache.
How to install Apache Kafka
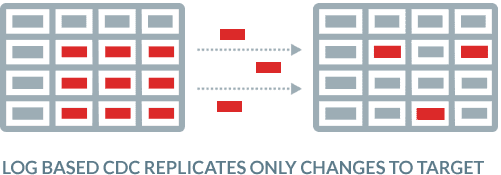
Load SQL Server to Kafka in real-time
BryteFlow’s SQL Server Kafka replication is zero impact and uses CDC or Change Tracking to query SQL transaction logs and transfers only the changes to Kafka. The data you get is real-time or you can schedule the replication as you like.
SQL Server CDC for real-time SQL Server replication

SQL Server Kafka replication does not require DBA time
BryteFlow provides ‘Set and Forget’ replication to Kafka. Your DBA dos not need to get involved at all whether it is managing backups, configuring full backups or managing dependencies until the changes have been processed, which means the TCO of the solution is significantly lower. Also no sysadmin privileges for the replication user are required.
SQL Server CDC To Kafka (Unbelievably Easy New Connector)

Fully automated SQL Server Kafka Connector
BryteFlow as a SQL Server Kafka connector is fully automated. You can forget about coding – for any process. SQL Server Kafka replication usually involves coding for some processes e.g. merging data for basic CDC. With BryteFlow you get a point and click interface that even a non-technical user can use with ease and complete automation.
Read about SQL Server Change Tracking
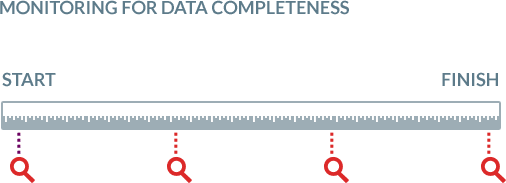
SQL Server Kafka loading is monitored continually
BryteFlow monitors your data from beginning to end. It checks data accuracy and completeness, letting you know of errors and stoppages if any so you can take action immediately to rectify the situation.
CDC to Kafka with BryteFlow

Automated catch-up from network dropout
If the SQL Server to Kafka transfer process is halted by network failure or a power breakdown, you don’t need to start the process from the beginning. The replication process simply resumes from the point it left off automatically.
How to Make PostgreSQL CDC to Kafka Easy (2 Methods)

Secure encryption of data
Your data is encrypted automatically and securely, in transit and at rest from SQL Server to Kafka. This is critical for sensitive info you may be transferring.
SQL Server vs Postgres – A Step-by-Step Migration Journey
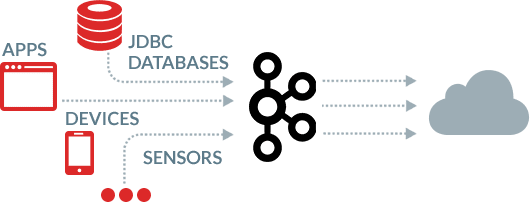
Kafka as a target
Get data from multiple sources to Kafka with BryteFlow. Data from devices, sensors, apps and databases like SAP and Oracle is delivered in real-time to Kafka in a continuous stream with BryteFlow, treating Kafka as a replication target .
Kafka CDC and Integration with BryteFlow
About Microsoft SQL Server
Microsoft SQL Server is a software that is a relational database management system owned by Microsoft. It’s primary objective is to store data and then retrieve it when other applications request it. It supports a huge range of applications including transaction processing, analytics and business intelligence. The SQL Server is a database server that implements SQL (Structured Query Language) and there are many versions of SQL Server, engineered for different workloads and demands.
About Apache Kafka
Apache Kafka is a distributed messaging platform created to manage real-time data ingestion and processing of streaming data. Kafka builds real-time streaming data pipelines and real-time streaming applications. Kafka servers or brokers consume and process high volumes of streaming records from millions of events per day combining queuing and publish-subscribe messaging models for distributed data processing. This allows data processing to be carried out across multiple consumer instances and enables every subscriber to receive every message. More on Apache Kafka