BryteFlow’s AWS ETL Tools
No-code AWS ETL Tool, save on development effort and time
BryteFlow makes AWS ETL easier and faster
If you would like to make AWS ETL as easy and convenient as possible, your search ends with BryteFlow. BryteFlow is a single vendor AWS ETL tool that provides data replication using log-based Change Data Capture and ETL on S3 using Apache Spark on Amazon EMR. BryteFlow uses the native capabilities of AWS ETL services for data processing for an automated data lake, “AWS lake house” architecture, and abstracts the underlying complexities – leading to a simpler, intuitive and faster experience.
Check out AWS Glue as an AWS ETL Option
Compare AWS DMS with BryteFlow for ETL in AWS
AWS ETL gets completely automated
Your AWS ETL process gets completely automated whether it is real-time data ingestion by BryteFlow Ingest or the data transformation by BryteFlow Blend. BryteFlow Blend is our data transformation tool that lets you blend and merge virtually any data on Amazon S3 in real-time to prepare data models for Analytics, AI and ML. How to create an AWS Data Lake 10x faster
Change Data Capture Types and CDC Automation
Zero-ETL, New Kid on the Block?
Aurora Postgres and How to Setup Up Logical Replication
Why BryteFlow for AWS ETL
BryteFlow’s AWS ETL tools have a seamless integration with AWS ETL Services and leverage the latter’s native capabilities to the fullest to provide real-time, ready to use data. Get a Free Trial of BryteFlow




A single vendor tool for AWS ETL
Change Data Capture your data to S3 or Redshift with history of every transaction – no programming needed
BryteFlow continually replicates data to S3 and Redshift in real-time, with history intact, through automated log based Change Data Capture. BryteFlow leverages the columnar database by capturing only the deltas, keeping data in the AWS database synced with data at source. Create an S3 Data Lake in Minutes
Bulk data transfer is a breeze
BryteFlow moves bulk data in minutes. Data is transferred to the AWS database at high speeds in manageable chunks using compression and smart partitioning.
Secrets to Fast Bulk Loading of Data to Cloud Data Warehouses
Get reconciled data in your destination database
BryteFlow reconciles your data with data at source and provides alerts and notifications in case of incomplete or missing data.
Other Highlights:
- Near real-time Change Data Capture (CDC) What is Zero-ETL?
- Blend multiple sources including machine and sensor data on S3 e.g. IoT data
- Build Amazon S3 data lakes, data warehouses Build a Data Lakehouse on S3
- Direct load to Redshift
- Direct load to Snowflake
- Very high throughput for CDC for enterprise data
- Fastest replication in the market Aurora Postgres and How to Setup Up Logical Replication
- Multiple sources and destinations
See how BryteFlow works
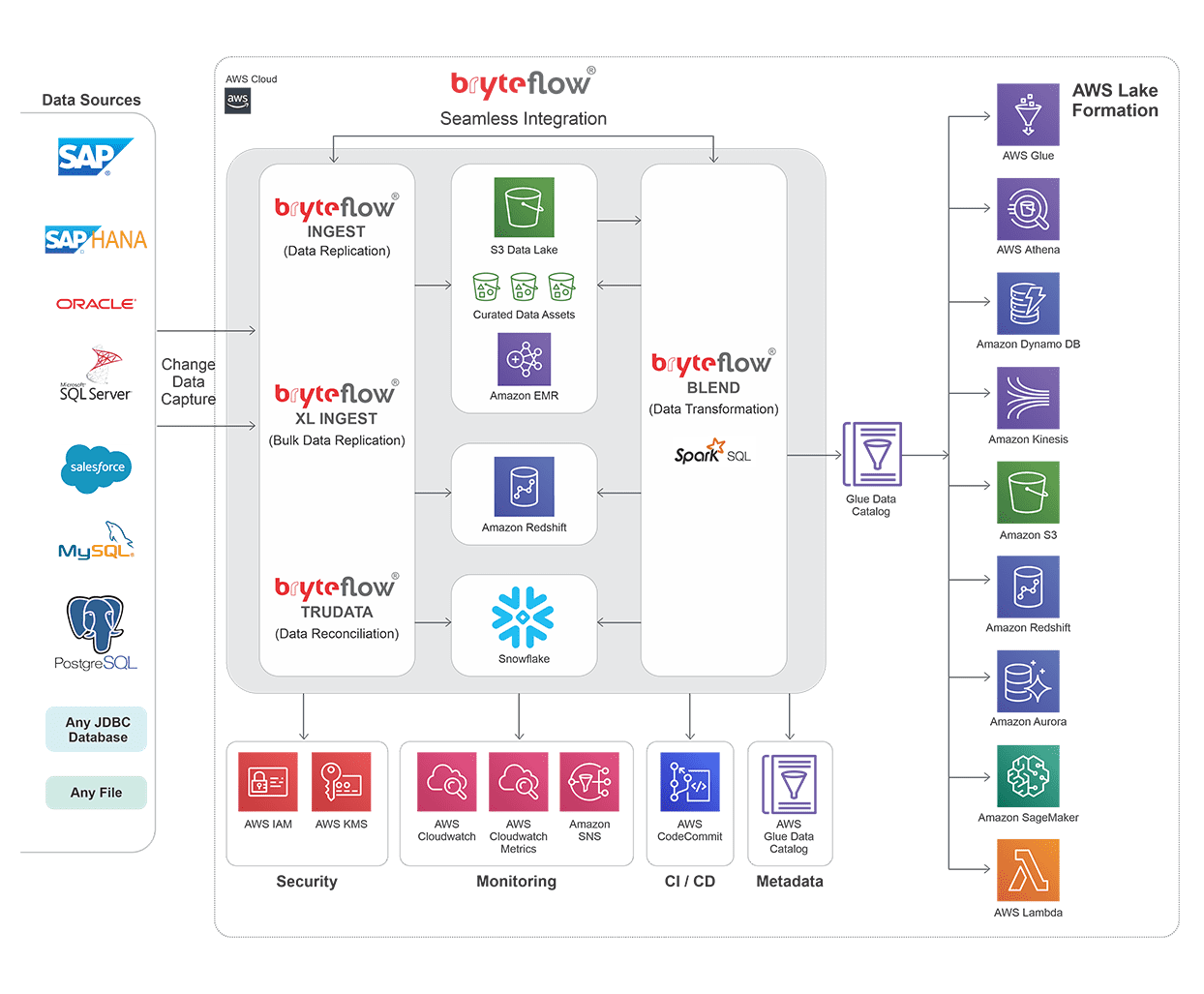
BryteFlow Tools for AWS ETL
BryteFlow’s tools for AWS ETL work synergistically with each other and integrate seamlessly to provide reconciled, ready to use data at the destination in real-time. Get a Free Trial of BryteFlow
Data Replication with BryteFlow Ingest
Watch the video to see BryteFlow Ingest in action
BryteFlow Ingest replicates huge volumes of data from multiple sources in real-time – it has the highest throughput in the market for Oracle sources – a million rows in 30 secs! It is at least 6x faster than GoldenGate.
Compare AWS DMS with BryteFlow for AWS ETL
Key Features
- Log based CDC from databases
- Initial and delta sync Aurora Postgres and How to Setup Up Logical Replication
- Automatic merging or upsert on S3 using an stateless Amazon EMR cluster
- Maintain SCD type2 history or time-series on S3 out-of-the-box
- Integrate with Athena – tables on Athena are created automatically
- Direct API link to Glue Data Catalog and hence AWS Lake Formation
- Configure file formats and compression e.g. Parquet or Orc with Snappy and other compression
- Direct load to Redshift with all the best practices or use Redshift Spectrum
- Direct load to Snowflake with all the best practices
- Very high throughput for Oracle and SQL Server sources
More on BryteFlow Ingest
Check out AWS DMS Limiations for Oracle Replication
Data Transformation with BryteFlow Blend
Watch the video to see BryteFlow Blend in action
BryteFlow Blend is our data transformation tool that lets you blend and merge virtually any data on Amazon S3 in real-time to prepare data models for Analytics, AI and ML.
Key Features
- Real-time batch transformation on S3 using stateless EMR clusters
- Use Spark SQL and drag and drop GUI for blending data
- Transform real-time ingested data from Ingest with sources on S3 e.g. IoT data
- Metadata and data lineage
- Configurable file formats and compression e.g. Parquet, ORC with snappy compression
- Write curated data assets to S3 and then export to Redshift or Snowflake for an AWS lake-house architecture Build a Data Lakehouse on Amazon S3
- Enables use of Redshift Spectrum
More on BryteFlow Blend
Bulk Data Ingestion with BryteFlow XL Ingest
Watch the video to see BryteFlow XL Ingest in action
BryteFlow XL Ingest is recommended for the initial full ingest of data when it comes to replication of very large datasets. It uses smart data partitioning and parallel sync functionality to load data in parallel threads.
Key Features
- Companion to BryteFlow Ingest
- For very large tables for initial sync of historical data
- Automated partitioning and parallel multi-threaded extracts makes ingesting large tables a breeze
- Get a subset of the historical data
- For network dropouts, no data lost other than the current partition
More on BryteFlow XL Ingest
Data Reconciliation with BryteFlow TruData
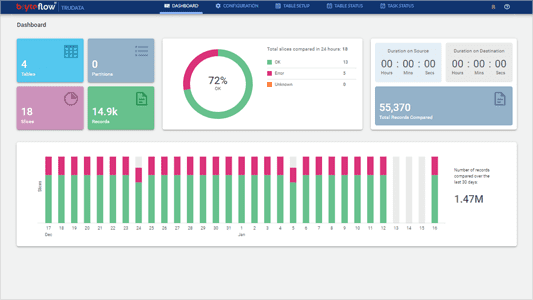
BryteFlow TruData Dashboard
BryteFlow TruData is an automated data reconciliation and validation software that checks for completeness and accuracy of your data against source.
Key Features
- Companion to BryteFlow Ingest
- Data reconciliation for counts and checksums of selected columns
- Can be scheduled as per latency or daily / weekly as desired
- Slices large tables to improve remediation of non-reconciled data. Works at a very granular level to reconcile data
More on BryteFlow TruData
Data Monitoring with BryteFlow ControlRoom
Watch the video to see BryteFlow ControlRoom in action
BryteFlow ControlRoom shows you a unified view of all your Ingest and Blend instances and their statuses.
Key Features
- Operational dashboard to monitor all instances of data ingestion and transformation.
- Configure and customize the BryteFlow ControlRoom as per organization’s standards.
- Receive alerts and alarms about ongoing data ingestion and data transformation processes through AWS services that are tightly integrated with BryteFlow.
- For BryteFlow Ingest view latency, extract and load status, start time, end time, ingest status etc.
- For BryteFlow Blend, view the jobs under Blend instances, their duration and number of times they have been run in 24 hours etc.