BryteFlow for SQL Server Replication
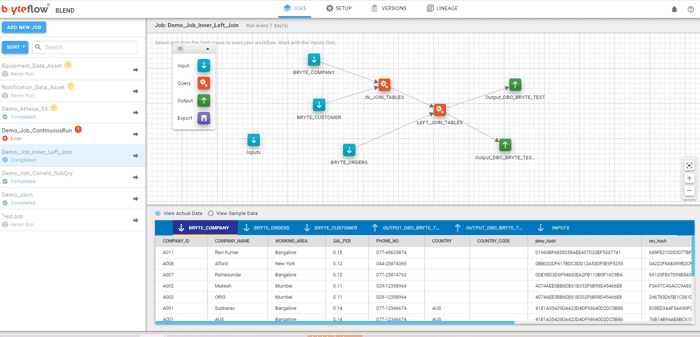
BryteFlow Blend, our data transformation tool
SQL Server Change Data Capture: Availability guaranteed and lightning fast replication across a wide range of platforms.
BryteFlow SQL Server Change Data Capture (CDC) is simpler to set up than any other comparable software. No need for admin access or access to logs. With BryteFlow for SQL Server’s log-based technology you can continuously load and merge changes in data to the destination with no slowing down of source systems. SQL Server Change Data Capture can be tricky, as some mechanisms require a Primary Key set up in the database. BryteFlow provides several mechanisms to suit your environment and supports all versions and SQL Server editions, works whether Primary Keys are available or not and does this with the highest performance for extraction and loading. It is easy to use and set up – you could be up and running in a matter of hours! SQL Server to Databricks (Easy Migration Method)
BryteFlow provides several options for SQL Server CDC to suit your specific needs. These include:
- Using SQL Server Change Tracking for Real-time replication
- Using SQL Server Change Data Capture for Real-time replication
- Using timestamps to identify changed records
- BryteFlow supports on-premises and cloud hosted SQL Server sources. (eg AWS RDS, Azure SQL DB etc.) Data Pipelines and why automate them
- BryteFlow can be installed on-premises or on the cloud
Solution Highlights:
- BryteFlow replicates data in real-time to the destination with zero impact, using SQL Server Change Data Capture or SQL Server Change Tracking or a combination of both.
- High performance – parallel threaded initial sync and delta sync for large amounts of data SQL Server to Snowflake in 4 Easy Steps
- Zero coding – Automated table creation using best practices on destination with data upserted or kept with SCD type 2 history ELT in Data Warehouse
- BryteFlow enables CDC from multi-tenant SQL Server databases easily, delivering ready-for-analytics data in near real-time that can be queried immediately by BI tools. Data is tagged by Tenant Identifier or Database ID. SQL Server CDC To Kafka (Unbelievably Easy New Connector)
- Multiple SQL Server CDC options to cover any SQL Server version and edition
- Analytics ready data assets on S3, Redshift, Snowflake, Azure Synapse, Databricks, PostgresSQL, BigQuery, Kafka and SQL Server
- Support for terabytes of SQL Server data, both initial and incremental
- Automated Data reconciliation with checksums
- Data Preparation for Machine Learning on Amazon S3
- High Availability
SQL Server vs Postgres – A Step-by-Step Migration Journey
SQL Server to Databricks (Easy Migration Method)
The Easy Way to CDC from Multi-Tenant Databases
Key Features

- Zero coding – for extraction, merging, masking or type 2 history for all destinations including S3
- SQL Server Change Data Capture or SQL Server Change Tracking with Enterprise – level security
- High performance, parallel threaded initial or historical sync
- High Throughput and performance
- Time series your data
- Supports all versions and editions of SQL Server
- Self-recovery from connection dropouts
- Smart catch-up features in case of down-time
- Transaction Log Replication
Unlock your SQL Server Data with a BryteFlow enabled automated Data Lake.
With BryteFlow, you can extract data from any SQL Server version and edition with just a few clicks. The software provides high performance and multiple options for capturing changes and ensures your SQL Server data is ready for analytical consumption without any engineering. It converts data types seamlessly and provides conversion on the destination for different character sets.

Zero impact on SQL Server source
BryteFlow eliminates the need for complex application procedures or queries to extract SQL Server data. It extracts data from the SQL Server application’s database level logs and does not require any additional agents or software to be installed in your SQL Server environment.
An Alternative to Matillion and Fivetran for SQL Server to Snowflake Migration

Analytics Ready Data
BryteFlow eliminates the need for any engineering and delivers SQL Server data that is ready to use for your destination. It extracts the data and loads the data to the data lake, with appropriate conversion of data types and character sets.
SQL Server to Snowflake in 4 Easy Steps

Near real-time replication of data
With frequent incremental extractions, compression and parallel streams, BryteFlow ensures your data is constantly kept up-to-date and available to enable real-time analytics.
Change Data Capture and Automated CDC

SQL workbench to blend data sources
An easy to use drag-and-drop workbench delivers a codeless development environment to build complex SQL jobs and dependencies across SQL Server and non-SQL Server data on Amazon S3.
SQL Server CDC To Kafka (Unbelievably Easy New Connector)

Dashboard for monitoring
BryteFlow for SQL Server displays various dashboards and statistics so you can stay informed on the extraction process as well as reconciling differences between source and target data. SQL Server to Databricks (Easy Migration Method)

Automatic catch-up from network dropout
Pick up where you left off – automatically. In the event of a system outage or lost connectivity, BryteFlow for SQL Server features an automated catch-up mode so you don’t have to check or start afresh.
Successful Data Ingestion (What You Need to Know)

Masking & Tokenization
BryteFlow for SQL Server provides enterprise grade security to mask, tokenize or exclude sensitive data from the data extraction processes.

Time-scale history
BryteFlow for SQL Server provides out-of-the-box options to maintain the full history of every transaction from SQL Server with options for automated data archiving. You can go back and retrieve data from any point on the timeline.
Data Migration 101 (Process, Strategies and Tools)

James Weakley,
Enterprise Architect,
NIB Health Funds
BryteFlow acts like a bridge between our legacy systems and digital technologies like Kinesis events stream to enable our digital initiatives.
“At nib Health funds we needed to publish a real-time data feed to AWS Kinesis from a third-party application and considering the massive volumes of data, needed an industrial strength data management solution that would achieve this. The Bryte team did an outstanding job of configuring their BryteFlow product to track and publish changes on the underlying SQL Server database. It has been over a year now and our BryteFlow solution is working like a dream. It acts like a bridge between our legacy systems and digital technologies like Kinesis events stream to enable our digital initiatives. The solution is resilient, cost-effective and very low maintenance. The team at Bryte worked hard with us to accommodate our requirements, modifying the application where necessary.”
NIB HEALTH FUNDS
Improving customer experience across multiple touchpoints.
nib Health funds operates in an industry with very high “lapse propensity”. nib was looking to improve customer experience across the multiple touchpoints on offer, including online and call centre.
BryteFlow helped sync SQL Server to AWS Kinesis stream.
Using BryteFlow’s point-and-click interface, nib Health Funds was able to sync SQL Server to AWS Kinesis stream. A third party tagging software was able to match the telephony stream to clickstreams, creating a unified persona across these different channels. With the solution fully operational, whenever a visitor fills out an online quote and quits before completion and when he/she contacts the call centre, the operator will have relevant contextual information to facilitate the caller in a meaningful way.
What is SQL Server CDC?
SQL Server CDC or Change Data Capture for SQL Server is a process that detects changes to tables in a SQL database when doing SQL Server data replication to a destination database. It captures all the inserts, updates and deletes on the tables in the SQL Server database and accordingly updates the data in the destination database so data in the destination aligns with the SQL Server data at source.
Why is CDC preferable for SQL Server data replication to the destination?
Unlike ELT (Extract Load Transform) or ETL (Extract Transform Load), with SQL Server CDC (Change Data Capture) you don’t need a tedious full refresh to sync destination data with source data. CDC captures and ingests ONLY data that has changed and replicates it on the destination, saving hours of time and effort. This ensures data is always current.
What are the challenges encountered in SQL Server CDC ?
The challenges when doing SQL Server CDC involve integrating all the deltas or changes for the various tables so that the data is correct and readable on the destination. A record may have changed in multiple ways - for example, an insert and an update or an update or a delete. They need to be processed intelligently to ensure the last record is captured correctly. Further, the processes need to be streamlined and fast as this could easily cause bottlenecks.
How does BryteFlow overcome these challenges?
BryteFlow Ingest uses log based CDC and processes the changes automatically on the destination, whether it is Amazon S3, Redshift, Snowflake, Azure Synapse or SQL Server. It uses smart partitioning and compression to replicate files really fast and maintains SCD type2 history on the destination automatically. It requires no coding and has high performance and resilience built in. It is a point and click, end-to-end solution that a business user can handle.