PostgreSQL Connections

No-Code CDC to Postgres in real-time
What is the PostgreSQL database?
PostgreSQL also known as Postgres, is an open source database which is fast gaining popularity with organizations to get access to their real-time data for mission critical requirements. PostgreSQL is known for its advanced features, versatility and its use in applications like Etsy and Skype. However what is interesting, is that Postgres is a RDBMS database that doubles up as a data warehouse. Many businesses are migrating their data to Postgres to cut down on IT costs. PostgreSQL database can be used interchangeably as a data ETL source for streaming data to BI tools for analytics or as a destination platform that functions as a data warehouse where data can be loaded from multiple sources for querying. ELT in Data Warehouse
BryteFlow for PostgreSQL Replication
Data Migration Tool for PostgreSQL
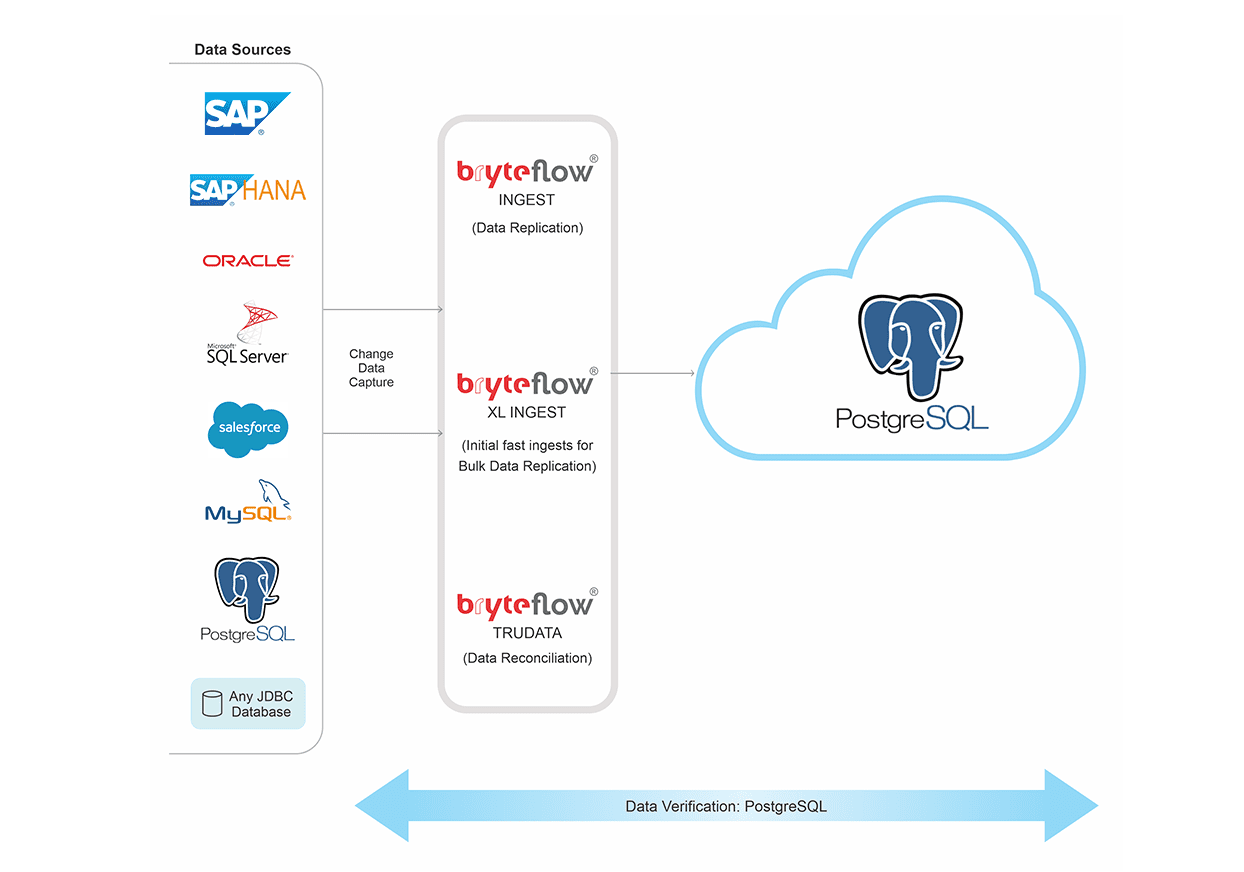
Data migration and data replication to PostgreSQL can be easily done with tools like BryteFlow. BryteFlow for PostgreSQL migration is a fully automated ETL and replication tool that extracts, transforms and loads data in real-time to your Postgres database. BryteFlow provides ready to use data in your Postgres data warehouse without coding. It replicates data from legacy databases like SAP, Oracle, SQL Server, applications, and other sources to PostgreSQL in real-time using proprietary log-based CDC (Change Data Capture) technology. It also provides automated data reconciliation to check the completeness of your data. Postgres CDC (6 Easy Methods to Capture Data Changes)
Migration to PostgreSQL Highlights
- BryteFlow’s log-based CDC for Postgres does not impact source systems. SQL Server vs Postgres
- Multi-threaded configurable data extraction and loading to Postgres for high performance.
- Replicate data to PostgreSQL using CDC, with best practices and optimization baked in.
- Migrate to Postgres with zero coding for processes including extraction, merging, masking or type 2 history.
- BryteFlow provides automated data reconciliation with row counts and columns checksum.
- Supports ingestion of large volumes of enterprise data, both initial full refresh and incremental sync.
- Loads data to PostgreSQL in minutes with high throughput – approx. 1,000,000 rows in 30 seconds.
- BryteFlow supports both -cloud and on-premise Postgres installations. Data Migration 101
- It also supports Amazon Aurora that is compatible with Postgres. Aurora Postgres and How to Setup Up Logical Replication
- Provides high availability and resilience with Automated Catchup in case of network failure.
Data Pipelines, ETL Pipelines and 6 reasons to automate them
Oracle to Postgres Migration (The Whys and Hows)SQL Server vs Postgres – A Step-by-Step Migration Journey
Postgres Migration Tool with
Real-time CDC
BryteFlow provides fast, automated CDC to Postgres in real-time. Here’s what you can do with BryteFlow
in your PostgreSQL Data Warehouse. Get a Free Trial of BryteFlow





Change Data Capture data to PostgeSQL with history intact
BryteFlow uses log-based CDC to replicate data to PostgreSQL in real-time, with a history of every transaction. BryteFlow Ingest captures the deltas, merges them automatically with existing data (automates upserts) syncing data in Postgres continuously with source, to keep data current. Change Data Capture and why automate it
Data on PostgreSQL is ready to use for Analytics or Data Science
BryteFlow Ingest on Postgres provides a range of built-in automated data conversions to ensure the delivered data is immediately ready for analytical consumption or for Machine Learning. ELT in Data Warehouse
Load data to PostgreSQL with very high throughput
BryteFlow Ingest uses real-time log-based CDC to replicate your data to the Postgres data warehouse. Data is loaded to Postgres in real-time at a high throughput of approx. 1,000,000 rows in 30 seconds. Oracle to Postgres Migration
Automated DDL and high performance with PostgreSQL best practices baked in
BryteFlow automates DDL (Data Definition Language) on Postgres. Other processes like masking, extraction, SCD Type2 history too are completely automated, providing a fully automated data pipeline
Automated database schema management
BryteFlow manages schema changes automatically. It can add columns to tables, add new tables if needed, and even change datatypes of columns.
Supports PostgreSQL installations On-premise and in the Cloud
Whether it is a Postgres on-premise database or a Cloud implementation, BryteFlow can replicate your data to the PostgreSQL database in real-time, using built-in best practices and optimization.
Successful Data Ingestion (What You Need to Know)
Support for Amazon Aurora PostgreSQL
BryteFlow offers support for Amazon Aurora PostgreSQL. This is a high performance relational database management system (RDBMS) on AWS Cloud with complete PostgreSQL compatibility and offers sizable cost advantages. Aurora Postgres and How to Setup Up Logical Replication
Migrate data to Postgres with automated data reconciliation
BryteFlow provides automated data reconciliation with BryteFlow TruData. It can automatically serve up flexible comparisons and match datasets of source and destination, and provides alerts and notifications in case of incomplete or missing data. Data Migration 101 (Process, Strategies and Tools)
Initial full refreshes to Postgres are fast with BryteFlow XL Ingest
When you have huge petabytes of data to load to PostgreSQL, BryteFlow XL Ingest carries out the initial full refresh of very large datasets. It uses multi-threaded parallel loads, smart partitioning and compression to transfer heavy data fast. This is followed by BryteFlow Ingest’s incremental refresh of data using CDC to update data with changes at source. Postgres CDC (6 Easy Methods to Capture Data Changes)
User-friendly, point and click UI for replication to PostgreSQL
BryteFlow enables end to end management of the ETL process with an easy, point-and-click UI, deploy it in a couple of hours and get delivery of data in just 2 weeks.
Dashboard to monitor data ingestion instances
Keep an eye on data ingestion statuses with the BryteFlow ControlRoom. You can monitor the status of BryteFlow replication instances, displaying latency, operation start time, operation end time, volume of data ingested etc.
Get built-in resiliency for CDC to PostgreSQL
BryteFlow has an automatic network catch-up mode to deal with power outages, system shutdowns and the like . It resumes operations from the point where it stopped, when normal conditions are restored, so the Postgres CDC process continues smoothly.
Postgres Advantages




What is PostgreSQL?
PostgreSQL is an open source , enterprise-grade database that supports querying of both SQL (relational) and NoSQL data (non relational – JSON). It has a very solid database management system and is used by many web, mobile, analyticl and geo-spatial applications as a data repository and data warehouse. It is known for its support of advanced data types and enables high levels of performance optimization, usually found in commercial relational databases like Oracle and SQL Server.
Postgres as a data warehouse
Postgres can serve very well as a cost-effective data warehouse owing to its powerful SQL querying capabilities. It is also compatible with many BI tools and can be used for data analytics, business intelligence and data mining purposes.
Powerful and Flexible, Postgres supports SQL and NoSQL data
Postgres can be used as a typical RDBMS to query transactional data and also as a NoSQL repository to store JSON files. This helps reduce database management costs and enhance security, since using a single database management system precludes the need to set up multiple database systems.
PostgreSQL has extensions for multiple use cases
PostgreSQL is easily extensible and offers extensions that cover a lot of use case requirements. Postgres can have customized extensions to cater to very specific needs. Extensions act as built-in features to extend the functionality of the database, for example, extensions for handling of time-series and geospatial data, support for particular data types, extended logging functionality etc. You can even script your own extensions or have a developer do the scripting.
PostGIS transforms the PostgreSQL database into a Spatial one
A powerful advantage of Postgres is that it has the open source PostGIS database extender. GIS stands for Geographical Information Systems and the PostGIS extender helps transform the PostgreSQL database to a spatial database with functions like area, union, intersection, and specialty geometry data types. Spatial databases store and work with spatial objects and are used by companies that need geo-spatial data like transportation, logistics, mining, oil exploration etc.
Postgres has high quality of code and is open source
PostgreSQL is an open-source database and has a committed community behind it. Every piece of code that gets added is reviewed by experts, so fixing glitches , bug reporting and validation gets done fast. Also since Postgres is open source, there are no licensing costs and users can use and customize it as they wish.
Availability, resiliency and security
PostgreSQL being a highly resilient database is used in organizations that routinely process large data volumes and need high levels of security such as financial services companies, government and healthcare organizations etc. Privately implemented and supported Postgres database versions can be used to achieve even better levels of availability and security.
Postgres can be used to run websites and applications
PostgreSQL is a robust database and can be used to power dynamic websites and web applications through the LAMP stack option. LAMP stands for Linux, Apache, MySQL, and PHP, and provides elements needed to manage web content. Postgres also has write-ahead logging that marks it as a highly fault-tolerant database.