Kafka Connections
Easy Oracle CDC to Kafka
Oracle Kafka Streaming is Real-time and No-code with BryteFlow.
Oracle CDC to Kafka with Bryteflow is automated and real-time. BryteFlow’s Oracle Change Data Capture delivers real-time data streams to your Apache Kafka platform. The Inserts, Deletes and Updates in the Oracle database are delivered in real-time to Kafka. BryteFlow’s log-based CDC to Kafka uses Oracle logs to capture changes at source and has almost no impact on source systems. Since only the changed data is loaded, the network bandwidth is used optimally. BryteFlow’s Oracle Kafka CDC delivers granular, high quality, reliable data.
Apache Kafka Overview and how to install it
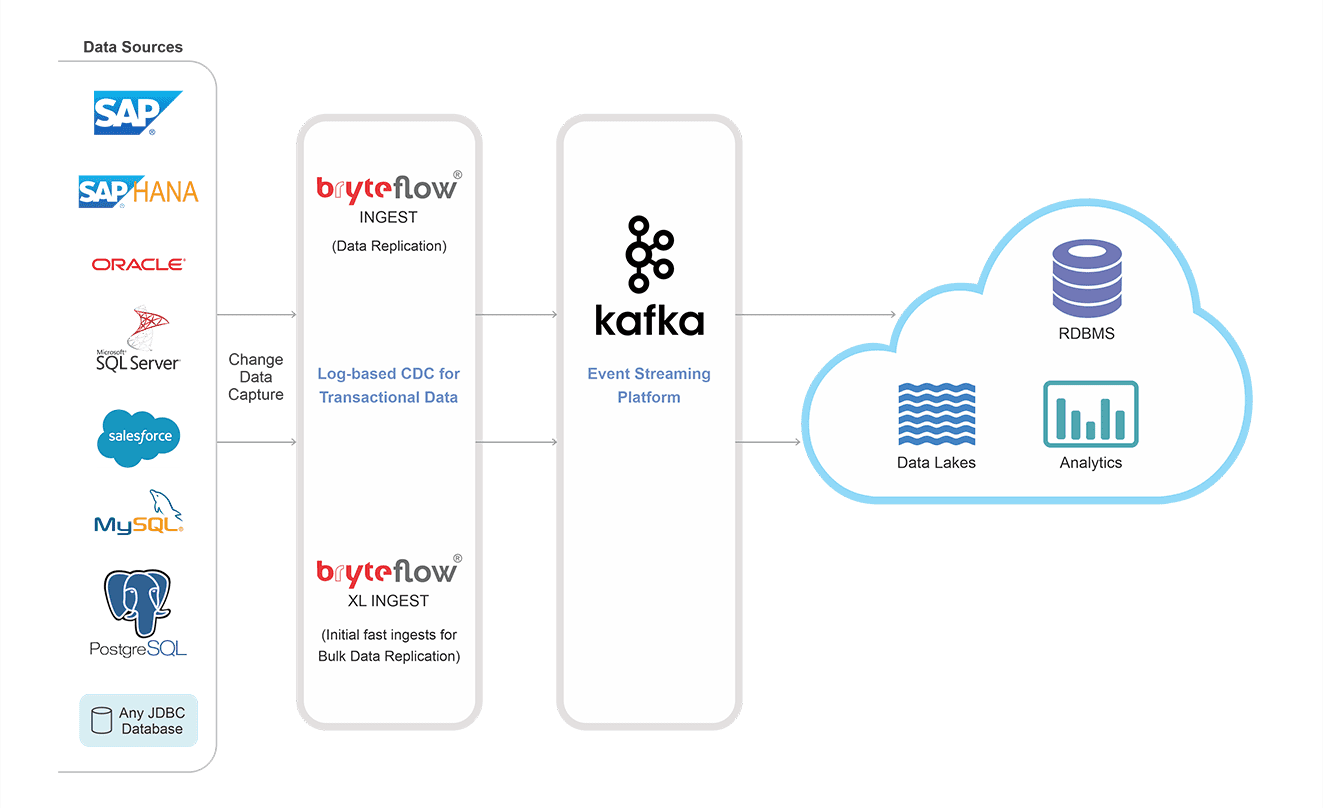
BryteFlow as an Oracle Kafka Connector
- BryteFlow delivers data from sources to Kafka with extremely low latency, using log-based CDC after the first full one time load into Topics. Every insert, update and delete in the Oracle database is captured and delivered in near real-time to Kafka. About BryteFlow Ingest, our data replication tool
- Log-based CDC from Oracle to Kafka ensures there is no impact on Oracle source systems. Oracle to Azure Cloud Migration
- Besides Oracle, BryteFlow enables real-time streaming from your relational databases like SAP, SQL Server, Postgres, and MySQL to Kafka SQL Server CDC To Kafka (Unbelievably Easy New Connector)
- BryteFlow provides automated partitioning and compression for efficient replication of data to Kafka
- With BryteFlow you get the highest throughput for Oracle CDC to Kafka with parallel extraction and loading which is completely configurable. Oracle CDC (Change Data Capture): 13 things to know
- BryteFlow delivers data in the JSON format to Kafka. Oracle to Snowflake: Everything You Need to Know
- BryteFlow provides replication support for all Oracle versions, including Oracle 12c, 19c, 21c and future releases for the long term and the replication is at least 6x faster than Oracle Goldengate. Real-time Oracle Replication step by step
- BryteFlow populates the schema registry automatically How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
- Easy to use, graphical point-and-click interface enables automated data flows, alerts and easy monitoring of data with zero coding.
Learn about BryteFlow for Oracle CDC
Kafka CDC and Oracle to Kafka CDC Methods
GoldenGate CDC and a better alternative
Real-time, No-code, Oracle to Kafka CDC

The BryteFlow replication tool loads large volumes of streaming Oracle data to Kafka really fast
BryteFlow Ingest uses Change Data Capture for Oracle Kafka replication, delivering changes at source in real-time to your Kafka platform at a speed of approx. 1000,000 rows in 30 seconds.
How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
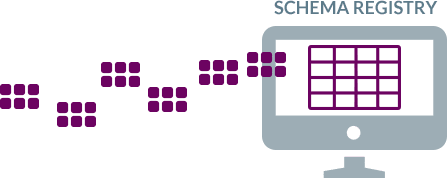
Populating the Schema Registry
The Schema Registry serves as a distributed storage layer for schemas using Kafka as the underlying storage platform. BryteFlow enables automatic population of the Schema Registry without manual coding.
Oracle to Snowflake: Everything You Need to Know
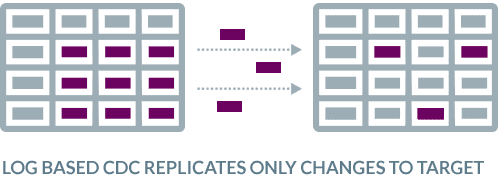
Oracle CDC to Kafka has zero impact on source systems
BryteFlow’s Oracle CDC to Kafka is zero impact and uses database transaction logs to query Oracle data at source and copies only the changes into Apache Kafka. The Kafka data is updated in real-time or at a frequency of your choosing, automatically .
Oracle CDC (Change Data Capture): 13 things to Know

How much time do your Database Administrators need to spend on managing Oracle Kafka CDC?
You need to work out how much time your DBAs will need to spend on the solution, in managing backups, managing dependencies until the changes have been processed, in configuring full backups and then work out the true Total Cost of Ownership (TCO) of the solution. The replication user in most of these replication scenarios needs to have the highest sysadmin privileges.
With BryteFlow, it is “set and forget”. There is no involvement from the DBAs required on a continual basis, hence the TCO is much lower. Further, you do not need sysadmin privileges for the replication user.
Kafka CDC and Oracle to Kafka CDC Methods

Oracle to Kafka CDC replication is completely automated
Most Oracle Kafka replication software will set up connectors to stream your Oracle data to Kafka but there is usually coding involved at some point for e.g. to merge data for basic Oracle CDC. With BryteFlow you never face any of those annoyances. Oracle data replication, CDC to Kafka, data merges etc. are all automated and self-service with a point and click interface that ordinary business users can use with ease.
Oracle to SQL Server Migration: Reasons, Challenges and Tools
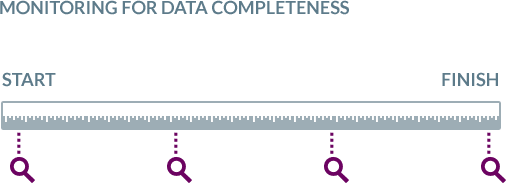
Data loading from Oracle to Kafka is monitored continuously
BryteFlow provides end-to-end monitoring of data. Reliability is our strong focus as the success of the analytics projects depends on this reliability. Unlike other software which set up connectors and pipelines to Oracle source applications and stream your data without checking the data accuracy or completeness, BryteFlow makes it a point to track your data from start to finish.
BryteFlow for Kafka CDC and Integration

Remote log mining possible with the software
With BryteFlow you can use remote log mining. The logs can be mined on a completely different server therefore there is zero load on the source. Your operational systems and sources are never impacted even though you may be mining huge volumes of data.
GoldenGate CDC and a better alternative

Data replication tool faster than Oracle GoldenGate
BryteFlow replication of Oracle data is the fastest that we know of. It is at least 6x faster than Goldengate. Average speed is 1,000,000 rows ler second. BryteFlow can be deployed in one day and you can start getting delivery of data in two weeks.
Oracle to Azure Cloud Migration (Know 2 Easy Methods)

Data gets automatic catch-up from network dropout
If there is a power outage or network failure you don’t need to start the Oracle to Kafka CDC replication over again. Yes, with most software but not with BryteFlow. You can simply pick up where you left off – automatically.
SQL Server CDC To Kafka (Unbelievably Easy New Connector)

Secure encryption of data
BryteFlow enables automated secure encryption of your data in transit and at rest. This is particularly useful in case of sensitive information.
Kafka Overview and how to install it
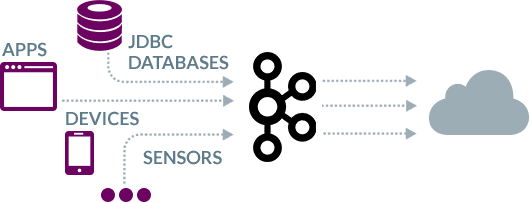
Kafka as a target
The BryteFlow replication tool works as a Kafka connector delivering data from sources to Kafka. BryteFlow treats Kafka as a target for data replication.
Kafka CDC and Integration with BryteFlow

About Oracle Database
Oracle DB is also known as Oracle RDBMS (Relational Database Management System) and sometimes just Oracle. Oracle DB allows users to directly access a relational database framework and its data objects through SQL (Structured Query Language). Oracle is highly scalable and is used by global organizations to manage and process data across local and wide area networks. The Oracle database allows communication across networks through its proprietary network component.
About Apache Kafka
Apache Kafka is a distributed messaging platform created to manage real-time data ingestion and processing of streaming data. Kafka builds real-time streaming data pipelines and real-time streaming applications. Kafka servers or brokers consume and process high volumes of streaming records from millions of events per day combining queuing and publish-subscribe messaging models for distributed data processing. This allows data processing to be carried out across multiple consumer instances and enables every subscriber to receive every message. More on Apache Kafka