BryteFlow Data Replication
BryteFlow for SAP BryteFlow for Oracle BryteFlow for SQL Server BryteFlow for PostgreSQL BryteFlow for MySQLReplication Platforms
Amazon S3 Amazon Redshift Snowflake SQL Server Azure Synapse Analytics ADLS Gen2 Apache Kafka Google BigQuery PostgreSQL Databricks Teradata SingleStore
Real-Time Data Replication
Data Replication from BryteFlow is automated, real-time and no code
BryteFlow data replication is real-time, ingests data easily from a multitude of sources (even from difficult legacy databases like SAP and Oracle) and comes with the assurance of consistency, integrity, security and high availability. More on SAP Data Integration
Replicates data from all your different sources fast
BryteFlow ingests data to all major platforms like Amazon S3, Amazon Redshift, Snowflake, SQL Server, ADLS Gen2, Kafka, Postgres, SingleStore, Teradata, Databricks, BigQuery and Azure Synapse in real-time, it merges and transforms data so users can get a unified view of the data for business intelligence, reporting and analytics. You can distribute and access data across your organization with ease and in real-time. Data pipelines and ETL pipelines and why automating them
Data replication with enterprise grade Change Data Capture
BryteFlow data replication features Change Data Capture (CDC) technology using transaction logs. It continuously updates only the deltas, merging changes with existing data so data at destination is always synced with source. BryteFlow data replication with log based Change Data Capture has zero impact on the source system. Change Data Capture Types and CDC Automation
Superfast bulk data ingestion with no load on the source
You can ingest petabytes of data in just a few minutes with BryteFlow XL Ingest’s multi-threaded parallel loading , partitioning and compression technology -especially useful for bulky initial data ingests. BryteFlow Ingest handles incremental data replication with CDC. Overall BryteFlow is a data ingestion tool providing extremely high performance with minimal source impact and low latency.
Debezium CDC Explained and a Great Alternative CDC Tool
Data ingestion and replication without coding. No worries. no hassle.
BryteFlow completely automates CDC data replication and integration. It is a self-service data ingestion tool with a point and click interface so you never need to code. BryteFlow creates tables automatically on the destination so there is no need to spend time on tedious data prep. BryteFlow enables data replication from all major transactional databases including SAP, Oracle, SQL Server, MySQL and PostgreSQL.
Set up in a day, get data delivery in 2 weeks
Amazingly easy to set up and use, you can deploy BryteFlow in one day and get data delivery in 2 weeks, as compared to competitors who routinely take more than 3 months to provide data. Zero-ETL, New Kid on the Block?
Automated Data Reconciliation ensures completeness of data
BryteFlow TruData our data reconciliation tool meshes seamlessly with BryteFlow Ingest so the replicated data is automatically reconciled with source. It compares row counts and columns checksum and slices large tables for fast and easy remediation of non-reconciled data.
How to Manage Data Quality (The Case for DQM)
Successful Data Ingestion (What You Need to Know)
Snowflake CDC With Streams and a Better CDC Method
Postgres Replication Fundamentals You Need to Know
Data Replication with Change Data Capture
Data Replication refers to the process where data from a database on one server is copied to another database on a different server enabling users to share the same information across the organization. Data replication makes data available, accessible and consistent for all users in real time. BryteFlow’s Data Replication Tool ingests and replicates data in real time without coding, at lightning speed.

SAP CDC
SAP data replication gets fast and automated with BryteFlow Ingest. It replicates SAP data fast and efficiently, in real-time from SAP applications to your data warehouse or data lake using Change Data Capture. Supports all versions including SAP HANA, ECC, S/4 HANA and also Pool and Cluster tables.

Oracle CDC
BryteFlow replicates Oracle data with Change Data Capture, 6x faster than GoldenGate. It provides the highest throughput for Oracle with parallel extraction and loading, and can be configured to work on a remote server, so that there is zero impact on source. BryteFlow’s Oracle CDC is no code and real-time.
Oracle Data Replication

SQL Server CDC
BryteFlow’s SQL Server Change Data Capture (CDC) ensures your SQL Server replication loads data continuously from source to destination with all changes and updates – in real-time. Fast and automated, BryteFlow’s SQL Server CDC supports all versions of SQL Server and keeps data synchronized at all times.
SQL Server Data Replication
Data Replication Tool: Fast, Real-Time, No Code
BryteFlow Ingest and XL Ingest are BryteFlow’s Data Replication Tools. For the initial full ingest, XL Ingest ingests the data with automated partitioning, compression and parallel multi-thread loading, replicating data in minutes. BryteFlow Ingest takes over for incremental data replication with log-based Change Data Capture, syncing data with source in real-time continually or at specified intervals.

Fast Data Replication: 6x faster than GoldenGate
BryteFlow Ingest and XL Ingest replicate data at an approx. speed of a million rows in 30 seconds. Our data replication is at least 6x faster than GoldenGate’s and much faster than that of competitors.
About GoldenGate CDC

No Code Table Partitioning and Parallel Loading
Parallel, multi-thread loading, compression and partitioning make ingesting bulk data a super-fast process. XL Ingest is especially useful for extraction and ingestion of initial full data ingests.
Debezium CDC Explained and a Great Alternative CDC Tool
Automated Data Reconciliation included
Besides data replication, BryteFlow includes automated data reconciliation to validate data completeness. It reconciles data between source and destination and issues alerts and notificaions for missing or incomplete data.
How to Manage Data Quality (The Case for DQM)
BryteFlow Ingest & XL Ingest Highlights
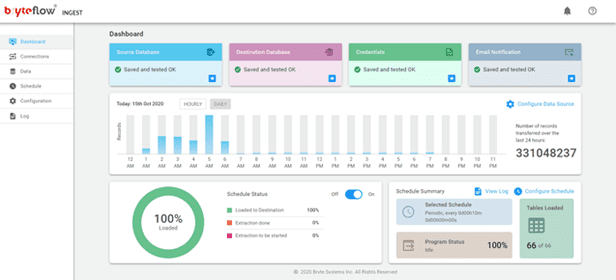
BryteFlow Ingest, our data replication tool
- No Code, Automated Data Replication in real time.
- Real-time, automated data ingestion from hundreds of sources.
- Access data immediately with real-time replication of your source in the data lake.
- CDC to manage transactional data and sync changes continuously.
- Get data conversions out of the box including Typecasting and GUID data type conversion.
- Retrieve data from any point on the timeline with timestamping feature.
- Automatic catch-up from network dropout.