BryteFlow for AWS Data Integration
Replication to Amazon S3
Why an Amazon S3 Data Lake?
An Amazon S3 Data Lake is scalable, flexible and cost-efficient
An Amazon S3 data lake is infinitely scalable in terms of storage and performance. Amazon S3 stands for Amazon Simple Storage Service but in terms of function, it handles a lot more than just storage. An Amazon S3 data lake can store structured, unstructured, and semi-structured data in its native format. You can aggregate data from diverse sources and run analytical queries on it, acquiring deep insights and business intelligence from the data. Build an S3 Data Lake in Minutes (S3 Tutorial – 4 Part Video)
A No-Code, Real-time Amazon S3 Data Lake with BryteFlow
- BryteFlow Ingest delivers data to the S3 data lake from relational databases like SAP, Oracle, SQL Server, Postgres, and MySQL in real-time or changed data in batches (as per configuration) using log-based CDC.
- The upsert on the S3 data lake is automated and requires no coding nor integration with Apache Hudi. CDC to Amazon S3
- BryteFlow offers super-fast replication to Amazon S3, approx. 1,000,000 rows in 30 seconds.
- S3 Bulk Inserts are easy and fast with parallel, multi-thread loading and partitioning by BryteFlow XL Ingest.
- Our Amazon S3 data lake solution is automated from end-to-end and includes all best practices for security, S3 data lake partitioning and compression. BryteFlow for AWS ETL
- BryteFlow enables seamless integration with Amazon Athena and AWS Glue Data Catalog in the S3 data lake and easy configuration of file formats and compression e.g. Parquet-snappy. Learn about S3 Security Best Practices
- BryteFlow Ingest maintains SCD type2 history or time-series data on your S3 data lake out-of-the-box. Build a Data Lakehouse on Amazon S3 without Hudi or Delta Lake
- Automated transformation – BryteFlow Blend enables you to transform and merge any data including IoT and sensor data on Amazon S3 in real-time, to prepare data models for Analytics, AI and ML. Why Machine Learning Models need Schema-on-Read
- Data analysts and engineers get ready-to-use data in their S3 data lake and can spend their valuable time analyzing data rather than prepping it. How BryteFlow Data Replication Software Works
Data Integration on Amazon Redshift
Build a Snowflake Data Lake or Data Warehouse
Aurora Postgres and How to Setup Up Logical Replication
S3 Data Lake Architecture
This technical diagram explains our S3 Data Lake Architecture. Try BryteFlow Free
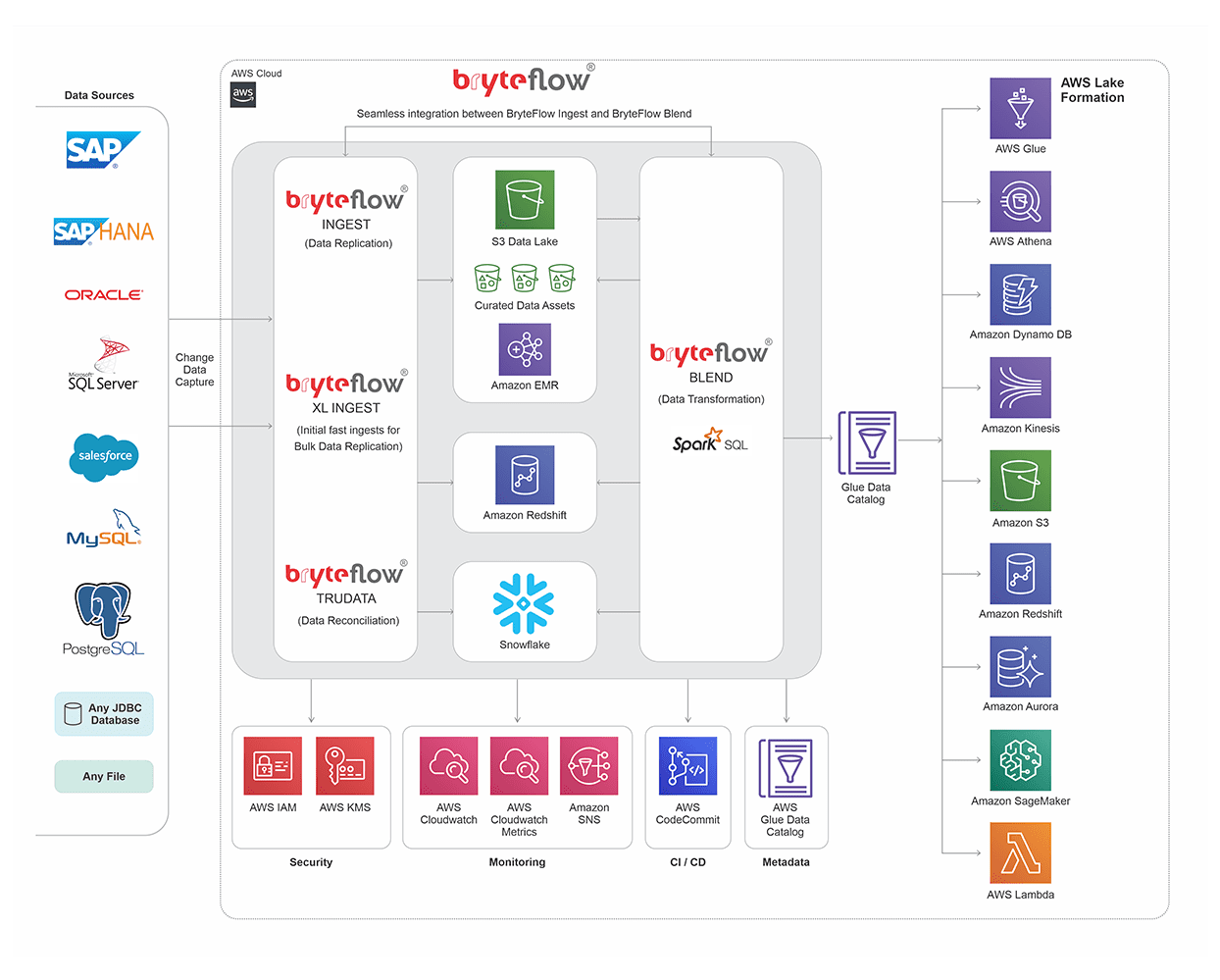
A real-time, updated Amazon S3 Data Lake with BryteFlow
BryteFlow provides seamless integration of AWS services with your S3 Data Lake, delivering real-time, updated data that is ready to use for Analytics, ML and AI. Get a Free Trial of BryteFlow

Fastest Replication
1,000,000 rows in 30 secs

Data Sync with
Change Data Capture

Data Transformation
on Amazon S3

Automated Data
Reconciliation
BryteFlow uses log based CDC (Change Data Capture) to replicate incremental loads to the Amazon S3 Data Lake
Continually replicate data with log-based CDC to your Amazon S3 data lake from transactional databases and files. Update and merge data with changes at source continually or as configured with BryteFlow Ingest.
Data Replication Tool with highest throughput, 6x faster than GoldenGate.
BryteFlow replicates data at an approx. speed of 1,000,000 rows in 30 seconds. It is at least 6x faster than GoldenGate. BryteFlow data replication with log-based Change Data Capture has zero impact on source systems.
SAP to AWS (Specifically S3)
BryteFlow automates DDL on the Amazon S3 Data Lake
Our data replication software automates DDL (Data Definition Language) creation in the S3 data lake and creates tables automatically with best practices for performance – no tedious data prep or coding needed! Build a Data Lakehouse on Amazon S3
No-code Data Lake Implementation on Amazon S3
While doing the S3 data lake implementation, there is no coding to be done for any process including data extraction, merging, masking, mapping or type 2 history. No external integration with third party tools like Apache Hudi is required.
6 reasons to automate your data pipeline
Ready to use data in your S3 Data Lake with out-of-the box conversions
BryteFlow Ingest provides a range of data conversions out of the box including Typecasting and GUID data type conversion to ensure that your data is ready for analytical consumption. BryteFlow enables configuration of custom business logic to collect data from multiple applications or modules into AI and Machine Learning ready inputs. Create an S3 Data Lake in Minutes
Time-stamped data in the S3 Data Lake with history of every transaction
BryteFlow provides an option to maintain the automated SCD Type 2 history of your data in the Amazon S3 data lake. It provides time-stamped data and preserves the referential integrity of your data.
Easy migration to Redshift and Snowflake from Netezza and Teradata
BryteFlow can migrate your data from on-prem data warehouses like Teradata and Netezza to cloud warehouses like Redshift and Snowflake by uploading data to Amazon S3. ELT in Data Warehouse
Merge and transform data in your S3 Data Lake with BryteFlow Blend
Merge and transform data from multiple sources (including IoT and sensor data) with BryteFlow Blend using an intuitive drag and drop user interface. Access analytics-ready data on your S3 data lake in real-time.
Validate data completeness with Automated Data Reconciliation
BryteFlow TruData provides automated data reconciliation on your S3 data lake by comparing row counts and columns checksum. It verifies data completeness and provides notifications for missing or incomplete data.
Bulk inserts to the S3 Data Lake are super-fast with XL Ingest
For bulk loading, BryteFlow XL Ingest ingests the initial full load on Amazon S3 at high speed with multi-threaded parallel loading, smart partitioning and compression. BryteFlow Ingest captures incremental loads to update data continually with log-based Change Data Capture.
Prepare data on the S3 Data Lake, move data to Redshift and Snowflake for querying
BryteFlow enables you to replicate and prepare data on the S3 data lake and move only the data you need to Redshift or Snowflake for querying. This helps preserve the compute resources of Redshift or Snowflake for the actual querying while the heavy hitting is done in the S3 data lake. BryteFlow for AWS ETL
Prepare your data and query it on S3 and using Redshift Spectrum
BryteFlow prepares data on the Amazon S3 data lake that can be queried using Redshift Spectrum. You don’t have to wait for the data to load on Redshift – Amazon Redshift Spectrum can query your data with SQL on Amazon S3 itself.
Amazon Athena vs Redshift Spectrum
Data replication with S3 Data Lake best practices baked in
BryteFlow leverages AWS services like Amazon Athena, AWS Glue, Amazon Redshift, Amazon SageMaker etc. and integrates them with your S3 data lake for seamless functioning. It replicates data using S3 data lake best practices automatically to achieve high throughput and low latency. S3 Security Best Practices
Get built-in resiliency in your S3 Data Lake
BryteFlow has an automatic network catch-up mode. It just resumes where it left off in case of power outages or system shutdowns when normal conditions are restored. Aurora Postgres and How to Setup Up Logical Replication
Amazon S3 as a Data Lake
Using Amazon S3 as a Data Lake has built-in advantages as seen below

- S3 as a data lake is cost-efficient. It has cheap storage and allows for separation of storage and compute, so you only pay for the compute you use.
- The Amazon S3 data lake can be used as a convenient staging area when replicating data to Redshift and Snowflake.
- S3 as a data lake has unlimited scalability and seamlessly scales up from gigabytes to petabytes if more storage is needed. It is designed for 99.999999999% durability.
- Amazon S3 integrates with a wide range of AWS services and third -party data replication and processing tools for efficient data lake implementation.
- Amazon S3 has centralized data architecture – users can analyze common datasets with their individual analytics tools and avoid distribution of multiple data copies across various processing platforms, leading to lower costs and better data governance.
- Using S3 as a data lake provides a very high level of security with data encryption, access control, and monitoring and auditing of security settings.
- With an Amazon S3 data lake, performance is infinitely scalable, you can launch virtual servers as per requirement with Amazon Elastic Compute Cloud (EC2), and you can process data using AWS analytics tools.