
Do you need to move data from Oracle to Teradata? Or maybe you are undecided and need to review whether an Oracle Teradata migration is worth your while? Whatever your reasons, we’ll present an overview of Teradata, its architecture, an Oracle vs Teradata comparison and reasons why you should move from Oracle to Teradata. You will learn how BryteFlow can make this a fast, no-code, painless process. Click here to skip to the BryteFlow section. BryteFlow for Oracle Replication
Quick Links
- What is Teradata?
- Teradata Architecture and Components
- Teradata Architecture -How it Works
- Teradata Features and Advantages
- Oracle vs Teradata
- Oracle to Teradata Migration
- Oracle Teradata Migration with BryteFlow
- Oracle to Teradata in 5 Steps with BryteFlow Ingest
What is Teradata?
Teradata Database is a massively parallel relational database management system (RDBMS) designed for enterprise scale data warehousing and analytical processing applications. It can process huge volumes of data and support multiple data warehouse operations simultaneously using parallelism. Teradata is innovative in approach and offers features for fast access, advanced analytics, and better governance. It can support multiple users concurrently and can run on Unix, Linux, and Windows platforms. Data Integration on Teradata
First introduced in 1979, Teradata has evolved significantly to become the database of choice for management of large-scale data warehouses and data marts. Teradata performs complex analytical functions on data with powerful OLAP (Online Analytical Programming) capabilities. Teradata is an open RDBMS and actively contributes to open-source collaborations with Hadoop. Oracle to Azure Cloud Migration (Know 2 Easy Methods)
Open-source initiatives by Teradata
Teradata has an active community of developers and sponsors and helps to develop open-source applications often using other open-source applications like Apache Hadoop, Apache Spark, ElasticSearch, and Apache NiFi as building blocks.
Some of Teradata’s open-source initiatives are:
Presto: Implements SQL queries on Hadoop and helps performance and SQL manageability across Hadoop distributions and other data sources.
Covalent: Open-source platform for building user interfaces for web applications.
Kylo: A framework to create industrial-scale data lakes, governance, and processing at scale.
Viewpoint: Provides broad management and monitoring capabilities for Teradata systems, Hadoop, and others. Allows management of open source and commercial data processing platforms from a single point of control.
QueryGrid: Allows breaking up of a single query that can be pushed in parallel to various engines.
Teradata Studio: for moving data seamlessly between Hadoop and Teradata.
Teradata Architecture and Components
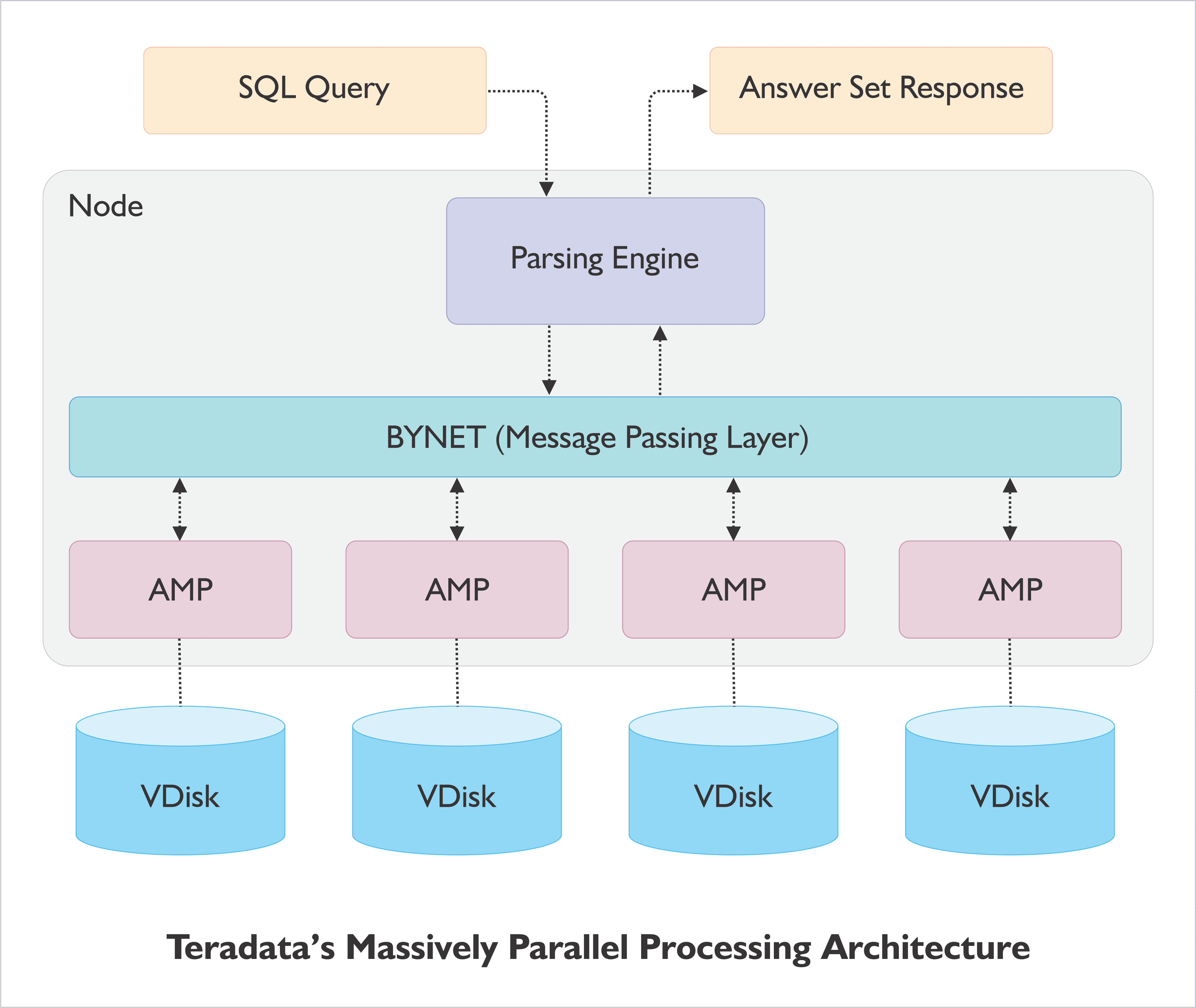
Teradata was designed for parallelism and as such Teradata architecture is a Massively Parallel Processing Architecture. There are four main elements in Teradata architecture: Node, Parsing Engine (PE), BYNET, and Access Module Processors (AMPs). Let’s have a quick look at these.
Teradata Node
The fundamental building block in Teradata is known as a Node. A Node functions as an independent unit with its own operating system, CPU memory, a duplicate of the RDBMS software, and disk space. Depending on processing needs, a cabinet can be made up of one or more Nodes.
Teradata Parsing Engine
The Parsing Engine is the component responsible for parsing incoming queries and preparing the execution plan for each one. Additionally, the Parsing Engine manages user sessions and optimizes requests, ensuring that data is processed quickly and seamlessly. When a client submits a query for inserting records, the Parsing Engine takes charge, sending the records to the Message Passing layer for further processing. It is the foundation of the entire query processing system, receiving and processing queries from clients to ensure that data is managed effectively.
Parsing Engine Functions
- Parsing Engine receives the SQL query from the client.
- Checks for the syntax errors by parsing the SQL query.
- Checks if the objects used in the query are relevant & existing.
- Checks if the user is authenticated against the objects used in the query.
- Prepares an efficient execution plan, based on the query, and sends it to BYNET.
- Gets the result from the AMPs and sends it back to the client.
Teradata BYNET
This is the Message Passing layer, also known as the networking layer. It plays a crucial role in enabling communication between different components. This layer acts as a bridge between the parsing engine, AMPs, and nodes and includes software and hardware components. BYNET receives the execution plan from the parsing engine and sends it to the respective AMPs and nodes for processing. Once the processing is complete, it collects the output from the AMPs and delivers it back to the parsing engine. To maintain uninterrupted availability, Teradata has two BYNETs – BYNET 0 and BYNET 1. This setup guarantees that a secondary BYNET is available if the primary BYNET fails.
Teradata AMP (Access Module Processor)
AMPs (Access Module Processors) are virtual processors (VPROCS) that are essential components of Teradata architecture and store records on disks. AMPs receive the execution plan and data from the message passing layer, and handle tasks like conversion, filtering, aggregation, sorting, joins etc., before forwarding the data to the appropriate disks for storage.
To ensure balanced distribution of table records for optimal storage, data is evenly spread across each AMP. Each AMP is assigned a specific set of disks, and only that AMP has the access and permissions to read or write data to those disks. This approach helps maintain data integrity and security while improving query performance. Data Integration on Teradata
AMP Functions:
- Manages a portion of the database.
- Manages a portion of each table.
- Performs all the tasks associated with generating a result set, such as conversion, filtering, aggregation, sorting, joins etc.,
- Performs Lock and Space management.
The components included in the Teradata Database system to support Data Communication Management are:
- Call Level Interface (CLI)
- WinCLI and Open Database Connectivity (ODBC)
- Teradata Director Program (TDP)
- Micro TDP
The Teradata Client Software Components include:
- Basic Teradata Query
- C
- CLI
- ODBC
- TDP
- Archive
- QueryMan
- FastLoad
- MultiLoad
- FastExport
- Open Teradata Backup
- Tpump
- Teradata Manager
- WinDDI
Teradata Architecture: How it works
Teradata architecture is Massively Parallel Processing. Teradata architecture functions in 2 modes using the components we mentioned before: Nodes, Parsing Engine, BYNET and AMPs. These are:
- Teradata Storage Architecture
- Teradata Retrieval Architecture
Teradata Storage Architecture
When a client requests data to be added, the Parsing Engine forwards the records to BYNET which receives and forwards the relevant rows to the associated AMP for insertion. The AMP then stores the rows on its disks.
Teradata Retrieval Architecture
When a client queries the Teradata database for some data to be retrieved, the Parse Engine sends the query to BYNET which in turn forwards it to the associated AMPs. The AMPs do a parallel search on the disks. After the record is found and retrieved, it is sent back to BYNET and then to the Parsing Engine which sends it to the client.
Teradata Database – Features and Advantages
Why choose Teradata – the Advantages
Teradata Database is a reliable and flexible data warehousing solution built for high volume data analytics. With its innovative open architecture, ability to run on different platforms and fast adaptation to newer, faster devices, Teradata can grow and evolve with today’s modern organizations. Its Massively Parallel Processing Architecture can support up to 50+ petabytes of data and sports a single operation view for multi-node systems – all of which makes Teradata a frontrunner in the handling of large and complex data sets. 6 Reasons to Automate ETL Pipelines
What is remarkable about Teradata Database is its compatibility with a wide range of business intelligence tools, making it easy to access and analyze your data. And with its high performance, in-database analytics, and sophisticated workload management capabilities, Teradata can help you get the most out of your data. Connect Oracle to Databricks and Load Data the Easy Way
Perhaps best of all, Teradata allows you to access the same data across multiple deployment options, so you can choose the option that works best for your business. Teradata has a lot of great features that earn it a place of honor at the table of terabyte scale data processing. Making CDC Automation Easy
Teradata Features
Uses the same Teradata database software across multiple deployment models
A vital feature of the Teradata Database is that it provides a hybrid and multi-cloud capability using the same database software across different modes of deployment. Whether you are running Teradata on-premise, in a virtual environment, in a private cloud or public cloud (AWS, Microsoft Azure), or a hybrid of these environments you can use the same database software without needing to modify it. Cloud Migration Challenges
Teradata offers linear scalability
One of the key advantages of Teradata Database is its linear scalability, which allows organizations to add nodes to the system as needed to process growing volumes of data. This scalability is incredibly powerful, with Teradata systems capable of scaling up to 2048 nodes. Adding on nodes increases the capacity to process data manifold and makes for faster performance. Oracle to Redshift Migration Made Easy (2 Methods)
Teradata Database has Massively Parallel Processing (MPP) Architecture
Teradata Database uses Massively Parallel Processing (MPP) to process large volumes of data efficiently. Teradata’s MPP architecture divides complex tasks into smaller processes and runs them in parallel, ensuring speedy execution. The system distributes the workload evenly across its processors, enabling load distribution among multiple users. Teradata’s MPP architecture was designed to be parallel from inception, enabling efficient processing of complex tasks.
Teradata Mature Optimizer handles complex analytical queries easily
Teradata Mature Optimizer is a component of the Teradata database management system that optimizes the execution of SQL queries to deliver better performance and use resources effectively. It is designed to handle complex analytical queries that involve large datasets and complex joins, aggregations, and window functions. The Mature Optimizer considers various factors such as data distribution, indexes, and available system resources to come up with the best execution plan for a given query. It can handle a remarkable 128 joins in just one query.
Teradata’s Shared Nothing Architecture
Teradata Database is known for its Shared Nothing architecture, which offers a unique approach to data processing and resource management. Each node is independent and self-sufficient, with its own CPU, memory, and disk storage and does not share its resources with other nodes. This is a distributed computing model where each node works on a portion of the data in parallel, providing high scalability, fault tolerance, and faster query execution.
Teradata Database provides a Single Version of Business
The Teradata database enables a single data store to be accessible on a range of client architectures. There could be multiple data deployments with just a single data store and a single version of the company’s data, whether these deployments are on-premise, on Cloud or a mixture of both. The single version of business enables a consistent and unified view of a company’s operations, processes, and data across all departments and business units. This ensures all users have access to the same information and can make decisions based on accurate and current data. It also allows for heterogeneous client access and flexibility of deployment. Data Migration 101 (Process, Strategies and Tools)
Teradata has Low TCO (Total Cost of Ownership)
Teradata is a cost-effective solution with a low total cost of ownership. Its simple setup, easy maintenance, and streamlined administration make it a top choice for businesses looking to optimize their data management processes. Teradata contributes to open-source initiatives, adding to its affordability.
Teradata offers seamless connectivity
Teradata’s MPP system allows for seamless connectivity with both – channel-attached systems, such as mainframes, and network-attached systems. This means greater flexibility and efficiency in managing and processing data across various platforms.
Teradata supports usage of SQL (Structured Query Language) for data interaction
An important benefit of Teradata Database is that it supports ANSI SQL standards so you can interact with stored data using SQL commands – something most engineers are familiar with. This includes SQL commands like CREATE TABLE, INSERT, UPDATE, DELETE. You can use the SELECT statement to retrieve data from the tables and various clauses like WHERE, ORDER BY, GROUP BY, and HAVING to filter, sort and aggregate data. Teradata Database conforms closely to the ANSI/ISO SQL standard and also provides its own unique extensions that help users to benefit from Teradata parallelism efficiency. This special language is called Teradata SQL. You can execute transactions in either Teradata SQL or ANSI SQL.
Teradata has robust and convenient Load & Unload utilities
Teradata offers powerful tools for transferring data to and from Teradata systems, such as FastExport, FastLoad, MultiLoad, and TPT. These utilities are designed for efficient and reliable import and export of data, helping businesses to manage and access their data easily.
Teradata automates data distribution
Teradata Database automates the balanced distribution of data to disks, eliminating the need for manual intervention. Data is distributed evenly across multiple nodes in a cluster. Each node contains a portion of the data and can process queries independently. Teradata’s automated data distribution is based on a hashing algorithm. Each row is assigned a hash value, which determines which node the data should be stored on. This feature ensures queries can be executed in parallel, improving performance. Data Integration on Teradata
Oracle vs Teradata
Oracle as an RDBMS has been around a long time, is known for its OLTP capabilities and is an integral part of many data implementations. However, Oracle-based data warehouses are finding it a bit challenging to keep up with the increasing data requirements of modern organizations. For e.g. customizations done for a set of users are not available to other parts of the business, additionally there is the risk of performance slowdown due to growth in numbers of users, rising data volumes and increase in complex datasets and queries. Due to this, there may be delays in responses to business-critical queries, brought on by slow data aggregation, indexing, and modeling. This can force organizations to limit the number of users or reduce the complexity of data or queries. Oracle’s sizable licensing costs is another reason organizations may turn to more affordable database options like the massively scalable Teradata. About Oracle to SQL Server Migration
As data warehouse requirements continue to increase, technical limitations can lead to higher maintenance costs and lower ROI. Decision makers are realizing that general-purpose DBMS solutions like Oracle (designed for OLTP) are finding it challenging to meet the business requirements of the real world. Today organizations need a DBMS like Teradata that can scale along multiple dimensions such as data volume, complexity, query volume and complexity simultaneously. Newer DBMS also allow organizations to adopt the technology directly without having to negotiate contracts with salespeople and they allow end-users to select their tools easily without constraint. The cloud data warehouses can also be deployed without needing too many DBAs and large maintenance teams. Oracle to Postgres Migration (The Whys and Hows)
Oracle vs Teradata: Key Differences
Oracle vs Teradata: They are designed for different goals
Oracle excels in transaction-based processing and manages inserts, updates, and deletes easily in transactions. It is a RDBMS created for online transaction processing (OLTP), e.g. a purchase tracking system, while Teradata is known for online analytical processing (OLAP) and its data warehousing and analytics capabilities. OLTP databases may find it hard to adapt to a dynamic, high volume data environment. About Oracle to Teradata Migration
Oracle vs Teradata: Differences in Architecture
In Oracle’s shared everything architecture, all nodes in the system share a common pool of resources, such as memory and storage. Though this allows for easier sharing of data and computation, it can result in resource contention and bottlenecks as nodes compete for resources. Oracle CDC: 13 Things to Know
With Teradata’s shared nothing architecture, each node in the system has its own CPU, memory, and storage, and there is no sharing of resources between nodes. Each node is responsible for its own compute and storage, and nodes communicate with each other through messaging. This enables high scalability, and fast performance, for high volume data analytics. Migrate Teradata to Snowflake
Oracle vs Teradata: Teradata has very high scalability compared to Oracle
Oracle can be scaled up but needs planning and monitoring on part of the DBA to do so. Storage, compute resources, monitoring scripts may need to be added if an increase in users, queries, complex datasets, or higher volumes are expected, to avoid performance degradation. In comparison, Teradata has powerful linear scalability, so organizations can add nodes to the system when needed (can go up to 2048 nodes) to process and store growing volumes of data. Oracle to Azure Cloud Migration (Know 2 Easy Methods)
Oracle vs Teradata: Programming Languages and Operating Sytems
Oracle supports programming languages like Python, R, C, C++, Java, Cobol, Perl, Visual Basic besides others. Teradata supports almost the same languages, except Visual Basic.
As far as operating systems go, Oracle can run on Unix, Linux, Windows, Mac OS X, z/OS, Teradata cannot run on Mac OS X, z/OS but can run on the others. BryteFlow for Oracle Replication
Oracle vs Teradata: The Parallelism Difference
Oracle has conditional parallelism while Teradata has unconditional parallelism. In Oracle, parallelism is conditional, meaning that it is applied only under certain circumstances such as involvement of large tables or complex operations. This is determined by Oracle’s cost-based optimizer and only if it believes scaling up will result in better performance. With Teradata, parallelism s default and unconditional, so all queries are run in parallel using multiple processor nodes. This is a big factor behind Teradata’s high volume OLAP and efficient handling of complex analytic queries. Oracle to Teradata with BryteFlow
Oracle vs Teradata: Pricing
Oracle offers a range of licensing models, including per-core, per-user, and per-instance. Oracle’s pricing can be complex and can vary depending on the specific features and options that are required. Teradata’s pricing too involves multiple pricing options like per-node, per-terabyte, and per-user but is easier to understand and more competitive than Oracle especially for enterprise-scale analytics and data warehousing deployments. Migrating from Oracle to SQL Server
Oracle to Teradata Migration
If your data usage involves a lot of data warehousing and analytics, it may make sense to migrate from Oracle to Teradata. The good thing is that Teradata itself has a special ‘Teradata Solution for the Oracle Professional’ migration training curriculum to help migrate your data from Oracle to Teradata. This includes a set of formal migration processes and procedures to make the migration process easy and short and support in the form of access to highly experienced consultants and field staff. Oracle to Redshift Migration Made Easy (2 Methods)
The process outlines these 3 basic steps for Oracle to Teradata migration
Step 1 for Oracle to Teradata migration
Move the data residing on Oracle to the Teradata database. There are two ways to do this: by transferring the data directly from one platform to the other (known as a forklift upgrade) or by recreating the target datasets from scratch using the source data. However, in most cases, a combination of both methods is used for the data migration.
Step 2 for Oracle to Teradata migration
To perpetuate the end user’s business requirements on Teradata, there are two possible approaches that can be taken: migrating the current application and report set to work seamlessly with the Teradata solution or building a new set of applications and reports from scratch that can offer even more advanced features and functionality. Cloud Migration (Challenges, Benefits and Strategies)
Step 3 for Oracle to Teradata migration
To load a new data warehouse with updated information from Oracle to Teradata, the extract, transform, and load (ETL) processes may need to be updated. This can involve pulling data from both old and new Oracle sources. Fortunately, the Teradata migration program offers a range of efficient procedures and automated tools to simplify this migration step. For instance, if the current data warehouse implementation relies on Oracle’s proprietary procedural language PL/SQL, the Teradata migration accelerator can automatically translate and optimize Oracle PL/SQL, Oracle SQL, and SQL Plus code into Teradata code. Teradata also offers data integration tools that can help in migrating data from Oracle to Teradata.
Oracle to Teradata Migration Tools
The first two tools are Teradata data integration utilities while Oracle GoldenGate is a software owned by Oracle DB. 13 Things to know about Oracle CDC
Teradata Parallel Transporter (TPT)
Teradata Parallel Transporter or TPT is a modern tool that can serve as a one stop shop for all tasks related to loading and exporting of date to and from the Teradata database. Most people prefer TPT over existing utilities such as FastLoad, FastExport, MultiLoad and TPump. TPT can be used to extract data from Oracle and load it into Teradata and it provides high speed, parallel data extraction and loading.
Teradata QueryGrid
Teradata QueryGrid provides seamless, performant data access, processing, and data transfer across systems in heterogeneous analytical environments. It can also be used to monitor queries running between local and remote servers and to review potential problems.
Teradata describes QueryGrid as a high-speed data fabric that performs native pushdown processing and parallel data movement, it eliminates performance bottlenecks. QueryGrid can integrate data from multiple sources, including Oracle and Teradata. It allows users to access and query data stored in Oracle as if it were on Teradata, and vice versa. Oracle to Snowflake: Everything You Need to Know
Oracle GoldenGate
Oracle GoldenGate is another tool that can replicate data from Oracle to Teradata. It supports real-time data integration between multiple heterogenous systems. It replicates, filters, and transforms data from one database to another, including Oracle and Teradata. GoldenGate enables replication to Flat Files, Java Messaging Queues and supports Big Data destinations, with replication being performed in a uni-directional or bi-directional manner as per requirement. GoldenGate provides high availability and validation between operations and analytical systems. GoldenGate and a GG Alternative
While GoldenGate moves data in real-time with log-based CDC (Change Data Capture), you may need to license the Oracle GoldenGate XStream module to enable real-time CDC from an Oracle 19c database. Earlier the log-based Oracle CDC functionality was available in Oracle versions 12c and lower without extra licensing, through Oracle Streams and the LogMiner Continuous Mining feature, both of which are now deprecated.
Please Note: With BryteFlow you will not need additional licensing for the Oracle GoldenGate XStream module, BryteFlow delivers real-time data with CDC from Oracle 19c redo logs via its own log parser tool and has a 10x faster capture rate than LogMiner-based CDC. BryteFlow as a GoldenGate Alternative
Oracle Teradata Migration with BryteFlow
BryteFlow was created for the Cloud and delivers enterprise-scale data in real-time from transactional databases (On-prem and Cloud) like SAP, Oracle, PostgreSQL, MySQL and SQL Server to cloud platforms like Amazon S3, Amazon Redshift, Snowflake, Azure Synapse, Azure Data Lake 2, PostgreSQL, Google BigQuery, SQL Server, Kafka and Databricks. BryteFlow replicates data in real-time using automated CDC and automates every process, creating schema and tables automatically on the destination. Learn about Oracle to Kafka CDC
Highlights of BryteFlow as an Oracle Teradata Migration Tool
BryteFlow is an automated, real-time migration tool, and makes the Oracle to Teradata CDC process no-code, highly performant and accurate. How BryteFlow Works
- Every process is automated with BryteFlow including data extraction, data mapping, partitioning, masking, schema creation, DDL, table creation, SCD Type2 history and more. BryteFlow for Oracle
- BryteFlow provides replication support for all Oracle versions, including Oracle 12c, 19c, 21c and future releases for the long term. Oracle to Kafka CDC
- With BryteFlow, you do not need the GoldenGate XStream module to enable real-time Oracle CDC to Teradata. It gets real-time data from Oracle 19c redo logs with its own log parser tool. This sidesteps additional licensing costs. BryteFlow as an alternative to GoldenGate
- BryteFlow works with Oracle RAC environments effortlessly. Oracle to Teradata with BryteFlow
- It works with high throughput environments and catch-up situations by mining logs in parallel and hence scaling the CDC replication process to the destination or target. Data Integration on Teradata
- Remote log mining is possible with BryteFlow Ingest so there is no impact on the source Oracle database. Oracle to Snowflake: Everything You Need to Know
- For the initial full ingest to Teradata, BryteFlow XL Ingest replicates data from Oracle with parallel multi-threaded loading and smart parallel partitioning to quickly get the data to the destination. This is followed by real-time ingestion of incremental data by BryteFlow Ingest using log-based CDC.
- It maintains referential integrity by taking all the commit data synchronized for the replication frequency.
- BryteFlow does the data reconciliation between source and destination, with row counts and columns checksum, and can repair or correct data that does not reconcile, without doing an initial extract. Connect Oracle to Databricks and Load Data the Easy Way
- It builds automated SCD type2 history on the destination i.e., Teradata with the commit timestamp in Oracle. Any constantly updated audit source fields can be removed from replication, so that the changes captured are true changes on the source. Oracle to Redshift Migration Made Easy (2 Methods)
- BryteFlow is an extremely fast Oracle replication tool with high throughput, replicating over 1,000,000 rows in just 30 seconds. It is at least 6x faster than GoldenGate and also faster than competitors like HVR and Qlik Replicate*.
*Based on results during a client trial
Oracle to Teradata in 5 Steps with BryteFlow Ingest
Here you can see just how easy it is to move your data from Oracle to Teradata with BryteFlow Ingest. Just point and click – no coding required!
Prerequisite: – Please ensure that all prerequisites have been met and all security and firewalls have been opened between all the components.
After configuring the BryteFlow Ingest software, follow these steps:
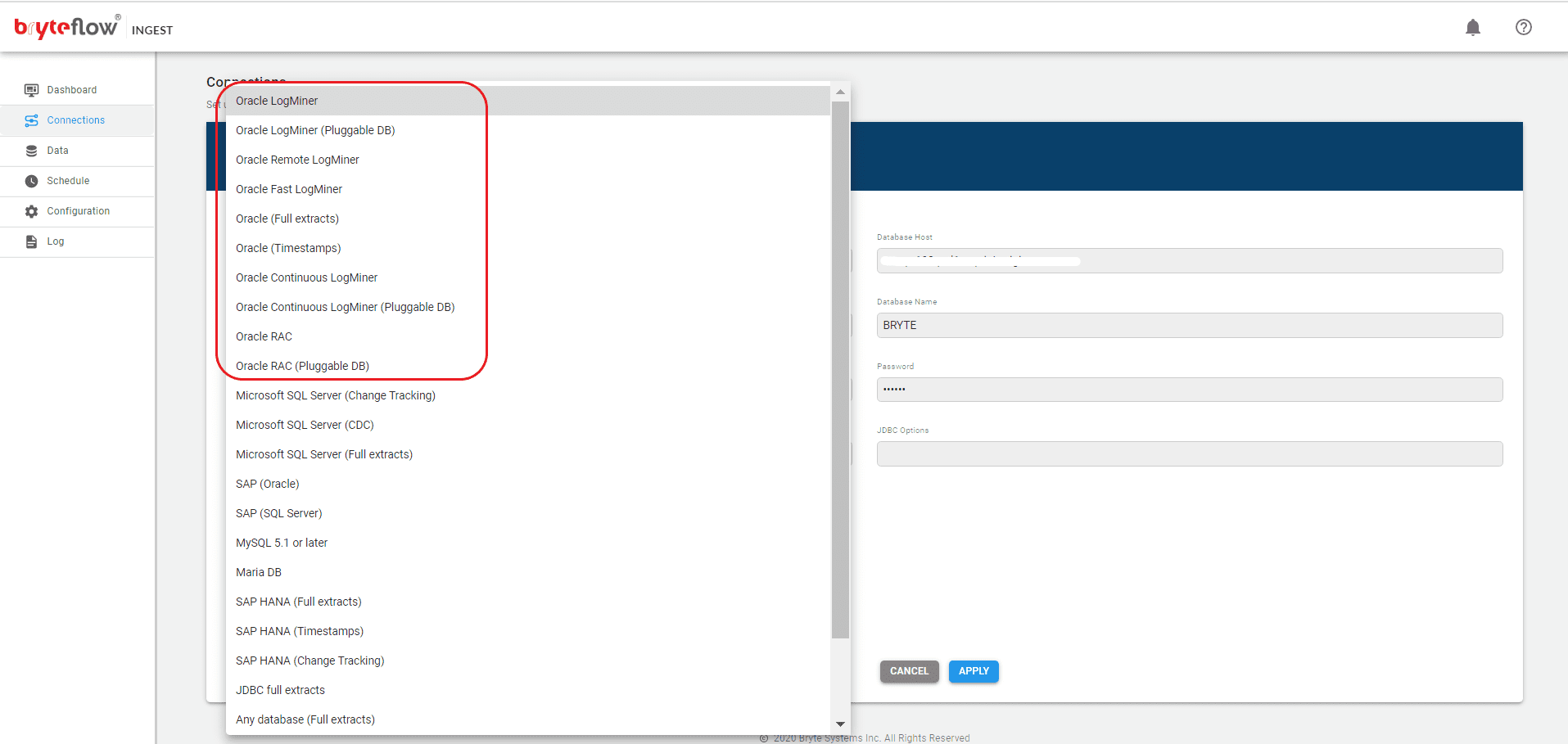
Step 1
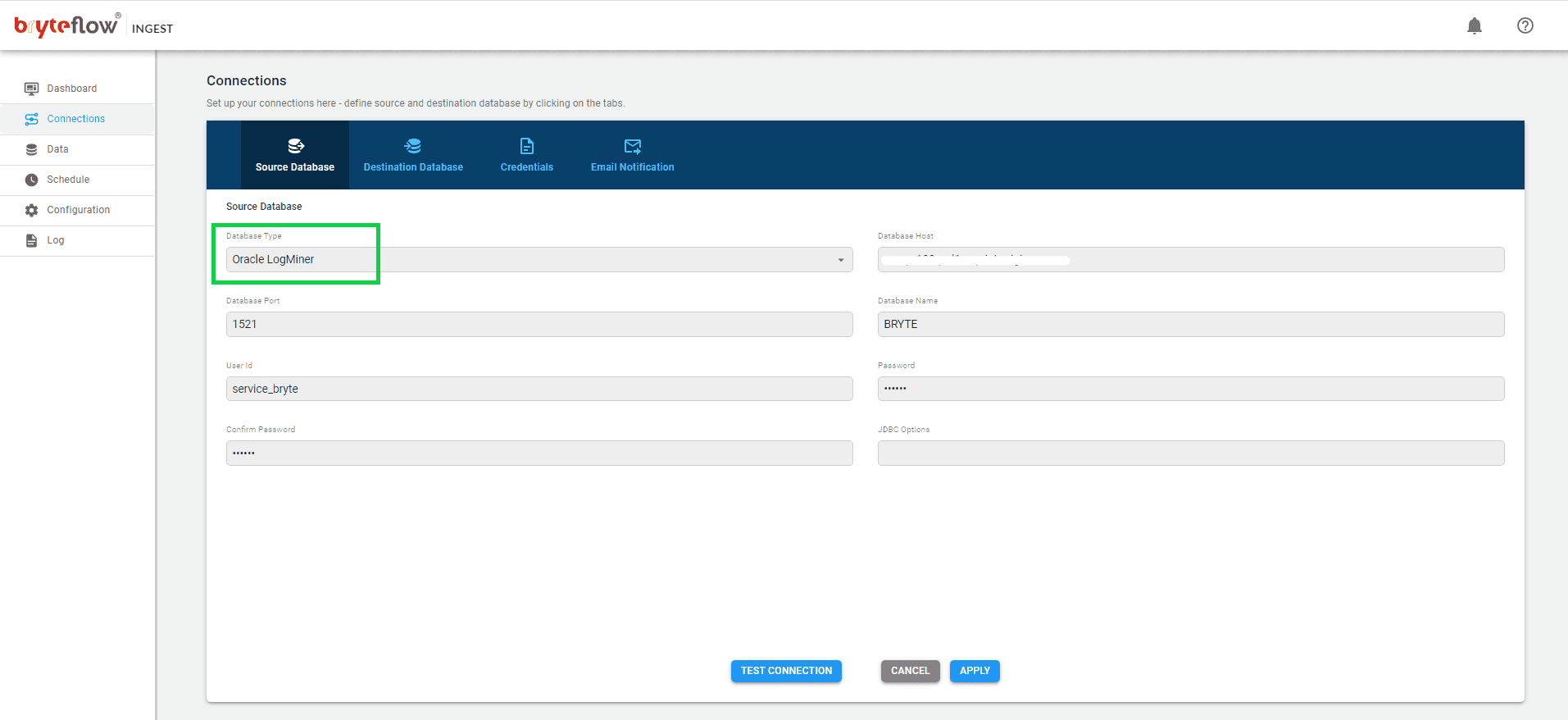
Set up the source connection details, for your Oracle source. A variety of Oracle connections are supported, including Oracle LogMiner, Oracle (Full Extracts), Oracle (Timestamps), Oracle RAC etc.
Put in the Oracle source database details. The Oracle source can be on the Cloud or On-premise.
Step 2
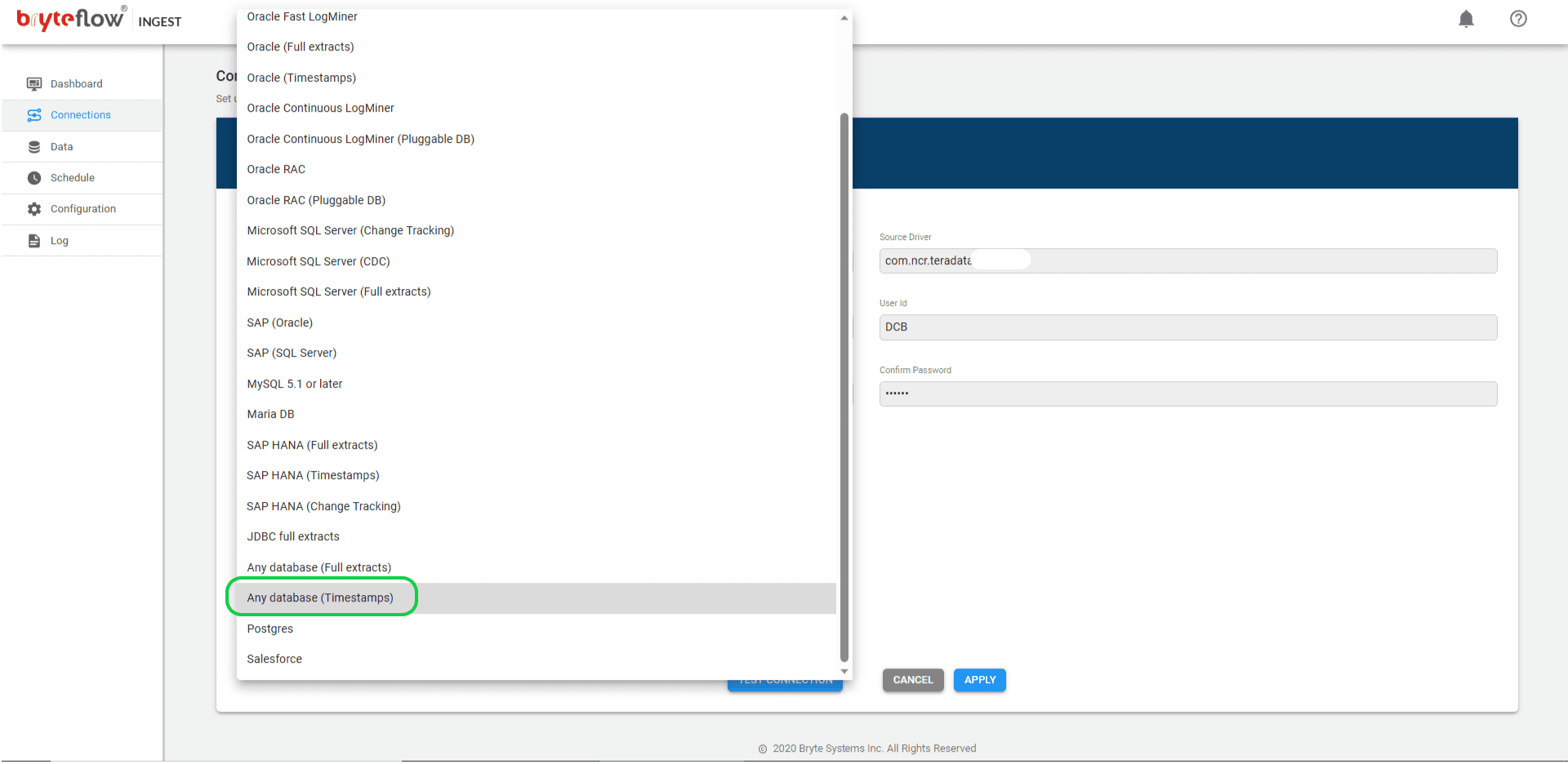
Click on the Destination database tab to set up the destination. Select ‘Any Database’ option from the dropdown menu and key in the Teradata destination details.
Step 3
Select the table(s) to be replicated and select the ‘Transfer Type’ option for Delta Extracts. Selecting the ‘Primary Key’ transfer type option provides a mirror of the source, without history. Selecting the ‘Primary Key with History’ option automatically maintains SCD Type2 history on Teradata with your data.
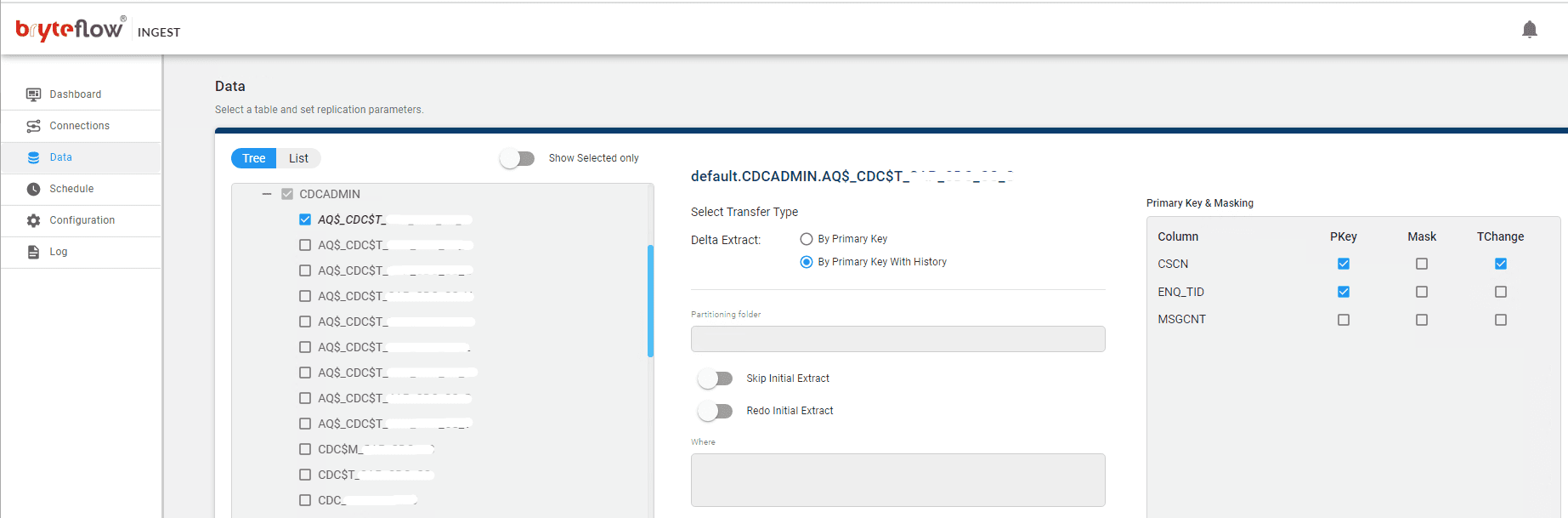
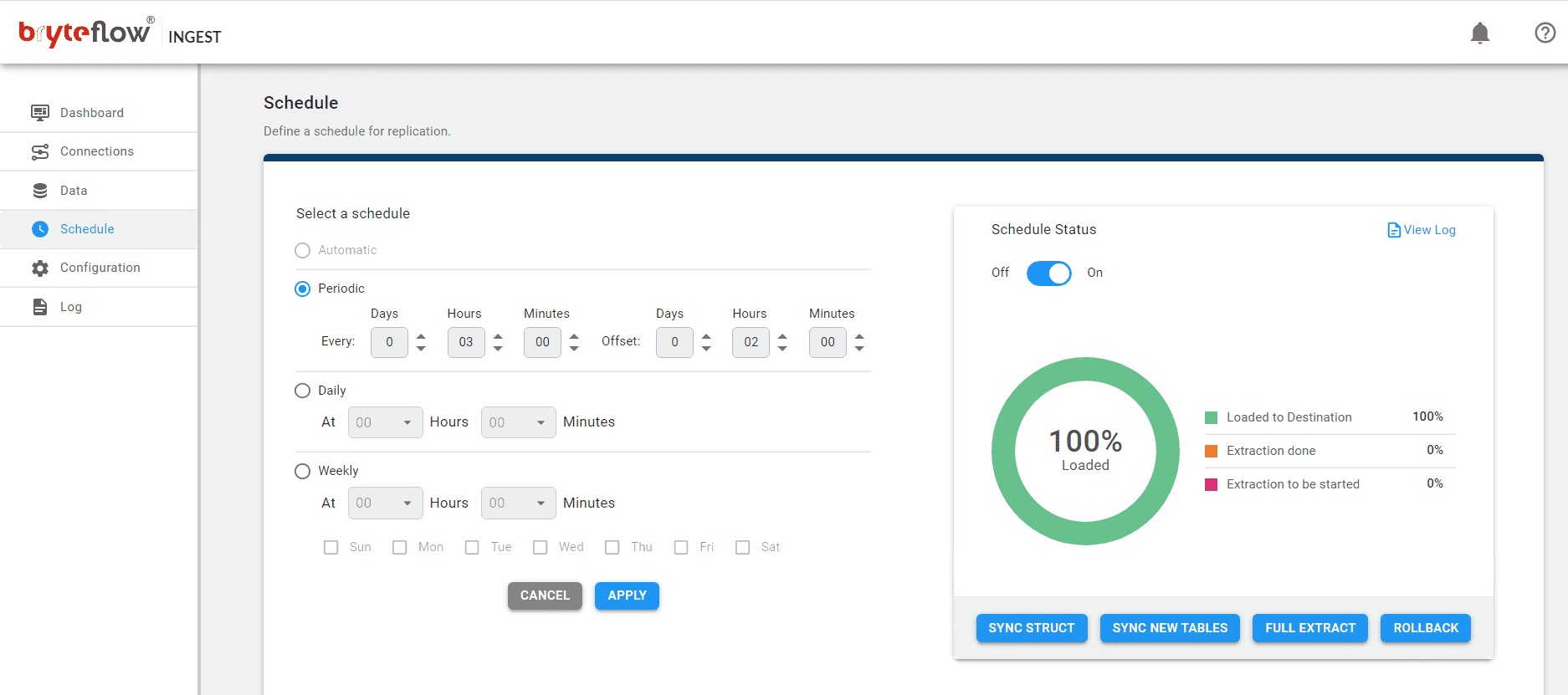
Step 4
Define your data replication schedule, whether automatic, periodic, daily, or weekly and get your data flowing to Teradata in near real-time. From the Schedule Status box, you can see the status of extraction.
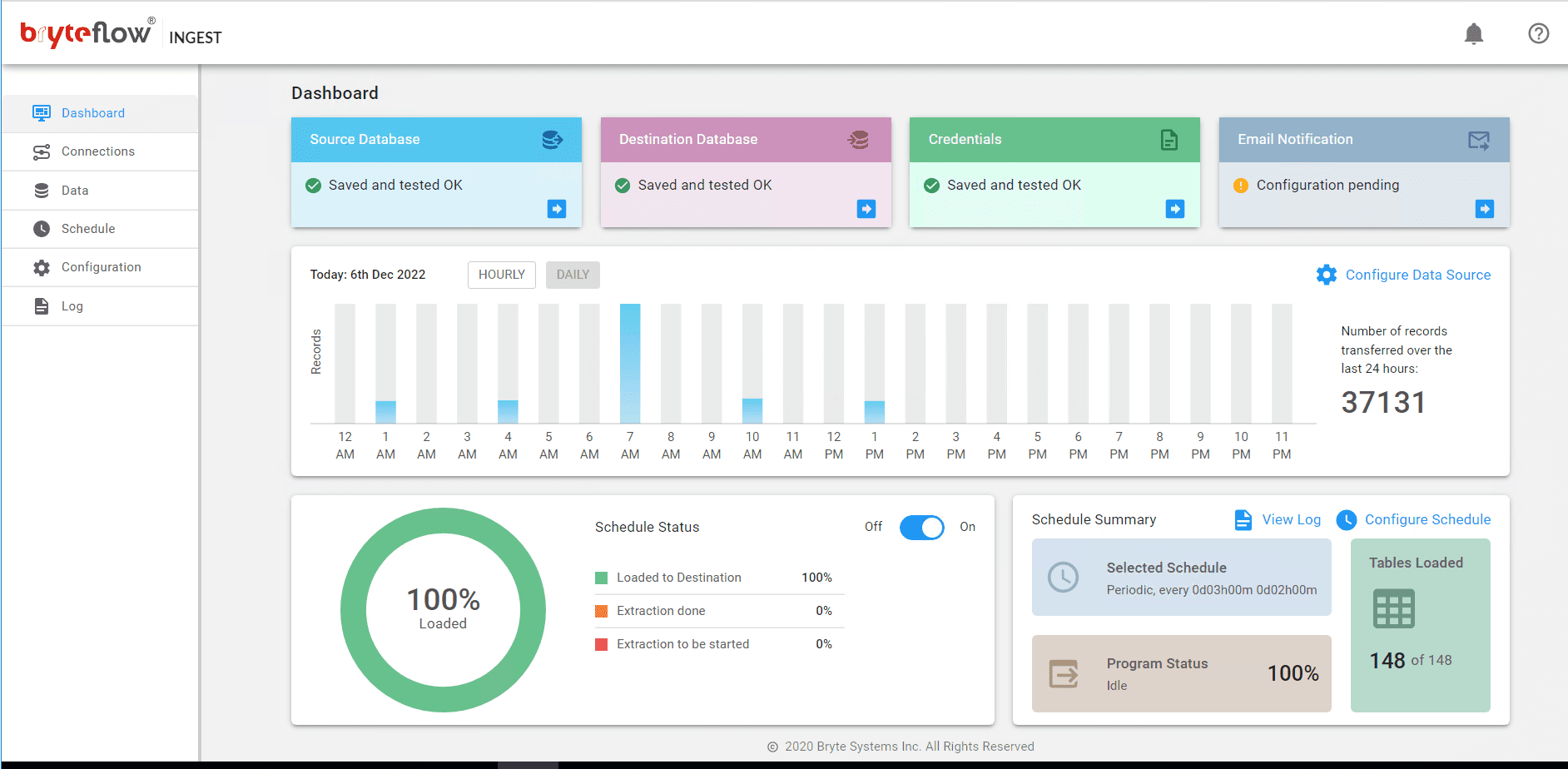
Step 5
Monitor the progress of your Oracle Teradata replication from the Dashboard.
If you are interested in making your Oracle to Teradata migration easy, try out BryteFlow. Start your Free POC or alternatively Contact Us for a Demo




