Kafka Connections
SAP Kafka Connect with Bryteflow
SAP Kafka Streaming is automated and real-time with BryteFlow.
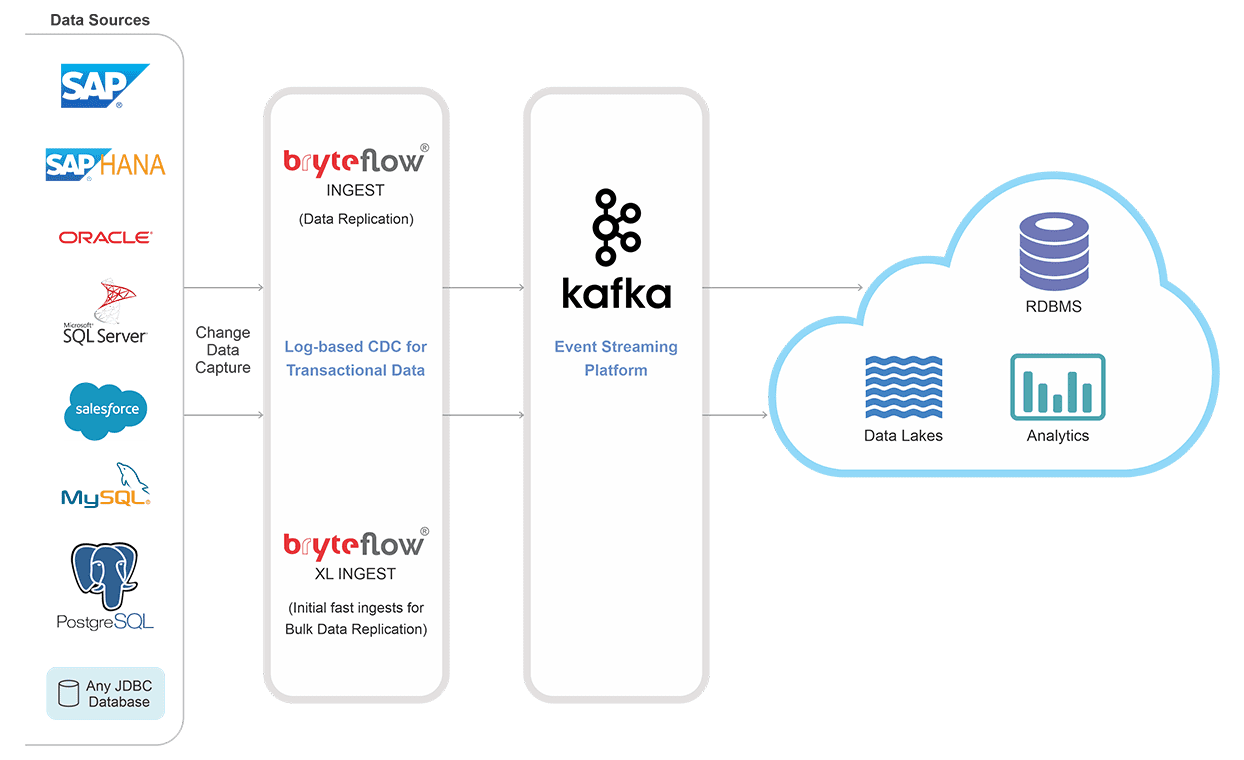
BryteFlow delivers data from SAP sources to Kafka using CDC. BryteFlow’s SAP replication tool delivers real-time data streams to Kafka and all the changes at the SAP source are delivered continuously as they happen. BryteFlow’s Change Data Capture to Kafka has minimal impact on SAP source systems and data can be extracted from SAP applications as well as databases. The process is completely automated and requires no coding. Change Data Capture Types and CDC Automation
Apache Kafka Overview and how to install it
BryteFlow as an SAP Kafka Connector
- BryteFlow delivers SAP Kafka replication with extremely low latency after the first full one time load into Topics. Every insert, update and delete in the SAP source is captured and delivered in near real-time to Kafka by BryteFlow Ingest, our data replication tool
- Besides SAP, BryteFlow delivers real-time streaming from your relational databases like Oracle, SQL Server, Postgres, and MySQLto Kafka. Create an SAP Data Lake with Bryteflow
- Our SAP Kafka connector has automated partitioning and compression for efficient replication of data to Kafka. About Kafka CDC
- BryteFlow delivers data in the JSON format to Kafka. Read about CDS Views in SAP HANA
- BryteFlow supports flexible connections to SAP including: ECC, HANA, S/4HANA . Create an SAP OData Service in SAP BW
- Population of the schema registry is automatic with BryteFlow. How to Carry Out a Successful SAP Cloud Migration
- Graphical point-and-click interface enables automated data flows, alerts and monitoring of data with no coding. About SAP BODS
Learn about BryteFlow SAP Data Lake Builder
SAP Extraction using ODP and SAP OData Services (2 Easy Methods)
SAP ECC and Data Extraction from an LO Data Source
RISE with SAP (Everything You Need to Know)
Automated, Real-time SAP Kafka Integration
BryteFlow loads large volumes of streaming data using CDC for SAP to Kafka replication in real-time
BryteFlow Ingest uses Change Data Capture for SAP Kafka replication, delivering changes at source in real-time to your Kafka platform.
Kafka CDC and Oracle to Kafka CDC Methods
Populating the Schema Registry
The Schema Registry serves as a distributed storage layer for schemas using Kafka as the underlying storage platform. BryteFlow enables automatic population of the Schema Registry without manual coding.
BryteFlow for Apache Kafka Integration
SAP Kafka Integration is completely automated
BryteFlow automates SAP data extraction and CDC, using OData services to extract the data, both initial and incremental or deltas. The tool can connect to Data extractors or CDS views to get the data.
CDS Views in SAP HANA and how to create one

Your Database Administrator will not need to spend a lot of time on managing the SAP to Kafka journey
You need to work out how much time your DBAs will need to spend on the solution, in managing backups, managing dependencies until the changes have been processed, in configuring full backups and then work out the true Total Cost of Ownership (TCO) of the solution. The replication user in most of these replication scenarios needs to have the highest sysadmin privileges.
With BryteFlow, it is “set and forget”. There is no involvement from the DBAs required on a continual basis, hence the TCO is much lower. Further, you do not need sysadmin privileges for the replication user.
How to Carry Out a Successful SAP Cloud Migration

SAP to Kafka replication is completely automated
As an SAP Kafka connector software, BryteFlow requires no coding at all, unlike other replication software where there is usually coding involved at some point. With BryteFlow all processes are automated and self-service, with a point and click interface that any business user can use with ease.
SAP BW and how to create an SAP OData Service for Extraction

SAP Kafka Data Loading is monitored continuously
BryteFlow provides end-to-end monitoring of data. Unlike other software which set up connectors and pipelines to SAP source applications and stream your data without checking the data accuracy or completeness, BryteFlow makes it a point to track your data from start to finish.
BryteFlow for Kafka CDC and Integration
Support for flexible connections to SAP
BryteFlow supports flexible connections to SAP including: Database logs, ECC, HANA, and S/4HANA. Import any kind of data from SAP into Kafka with BryteFlow.
SAP S/4 HANA Overview and 5 Ways to Extract S/4 ERP Data
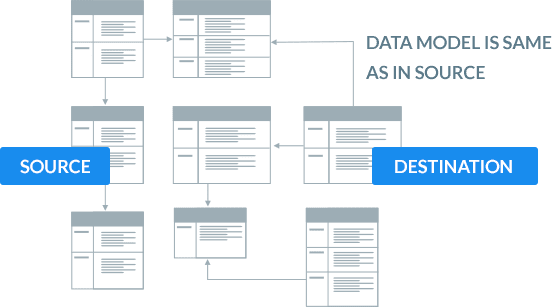
BryteFlow’s SAP Kafka replication delivers modeled, transformed data
BryteFlow replicates data directly from SAP sources via CDS Views and SAP extractors and delivers modeled, transformed data to Kafka.
SAP Extraction using ODP and SAP OData Services (2 Easy Methods)

Data gets automatic catch-up from network dropout
If there is a power outage or network failure you don’t need to start the SAP to Kafka replication over again. The process renews automatically from the point of stoppage when normal conditions are restored.
BryteFlow Replication for SAP

Secure encryption of data
BryteFlow enables automated secure encryption of your data in transit and at rest. This is particularly useful in case of sensitive information.
RISE with SAP (Everything You Need to Know)
Kafka as a target
The BryteFlow replication tool works as a Kafka connector delivering data from sources to Kafka. BryteFlow treats Kafka as a target for data replication.
Kafka Overview and Installation
About SAP
SAP is an acronym for Systems Applications and Products in Data Processing. SAP is an Enterprise Resource Planning software. It consists of a number of fully integrated modules, which cover most business functions like production, inventory, sales, finance, HR and more. SAP provides information across the organization in real-time adding to productivity and effiency. SAP legacy databases are typically quite huge and sometimes SAP data can be challenging to extract.
About Apache Kafka
Apache Kafka is a distributed messaging platform created to manage real-time data ingestion and processing of streaming data. Kafka builds real-time streaming data pipelines and real-time streaming applications. Kafka servers or brokers consume and process high volumes of streaming records from millions of events per day combining queuing and publish-subscribe messaging models for distributed data processing. This allows data processing to be carried out across multiple consumer instances and enables every subscriber to receive every message. More on Apache Kafka