
A blog on Change Data Capture, what is CDC, why CDC is better than Batch Processing, Change Data Capture types, CDC advantages, and how an automated CDC tool like BryteFlow can make your life (and data management) easier. BryteFlow Ingest, our CDC Tool
Compare BryteFlow with Fivetran and Matillion for SQL Server to Snowflake migration
Quick Links
- What is Change Data Capture?
- Batch Processing vs Change Data Capture
- Change Data Capture Advantages
- Types of Change Data Capture
- BryteFlow CDC Tool: Automating CDC Replication
What is Change Data Capture?
Change Data Capture or CDC is a technical process that highlights and monitors every change that occurs in a source database and moves the changed data downstream in real-time to a process or target application. Change Data Capture allows for real-time movement of data from sources to repositories like data lakes and data warehouses. It particularly tracks the INSERT, UPDATE, and DELETE transactions performed on a table to capture data changes. SQL Server CDC Replication with BryteFlow
CDC syncs data between source and destination by keeping the latter updated with all changes at source, usually in real-time. Continuous CDC replication captures changes continually to deliver updated data for real-time analytics and data science, and for cloud migration instances where zero-downtime is essential. This is especially true for critical databases that cannot be offline for long durations. Oracle CDC Replication with BryteFlow
Batch Processing vs Change Data Capture
What is Batch Processing of Data?
Traditional ETL (Extract Transform Load) operations rely on batch processing of data. In this organizations will do a big query usually at night (to not affect business systems) to extract data from the source database and write it to the data warehouse. Or they could set a parameter to query the database at a specified frequency, possibly hourly or half-hourly to get the fresh data and load it to the data warehouse. However, this has some disadvantages:
Network Provisioning and Strain
Loading high volumes of data can strain the network. Not to mention, adding onto network costs. Provisioning the network becomes essential to facilitate peak traffic and peak data volumes involved in batch processing of data. GoldenGate CDC and a better alternative
Overloads source database with high volumes of querying and results in load spikes
Very large queries can impact the source database and affect user experience adversely. It can increase latency, leading to frustration all around. This is one of the reasons why batch loading is restricted to low traffic times like nighttime. Successful Data Ingestion (What You Need to Know)
Batch processing does not deliver Real-time data leading to delayed decisions
There will always be a time gap of at least a day from when data is loaded and when it is queried. If the data is updated after work hours at night every day, you can query it only the next day, this means business decisions may be delayed and may be based on not-so-fresh data. Zero-ETL, New Kid on the Block?
Deletes cannot be tracked easily while using incremental replication
Monitoring Deletes is difficult because only new or updated rows are visible with incremental batch processing. You don’t know what has been deleted. Oracle vs Teradata (Migrate in 5 Easy Steps)
Why Change Data Capture is a better option to capture data changes
Change Data Capture moves data continuously and loads only the changed data, so data volumes are much smaller than heavy batch loads. This prevents spiky loads; data movement is smoother and costs less. Change feeds are cheaper and distributed more evenly in the day, overall, it is low impact and sparing of source systems. Debezium CDC Explained and a Great Alternative CDC Tool
Change Data Capture transfers data continuously and in smaller loads, you don’t need as much provisioning of your network, thereby reducing network costs. With Change Data Capture, business insights are based on real-time data, leading to better, more informed business decisions. Data pipeline and 6 reasons to automate them
Change Data Capture Advantages
CDC is much more efficient than other database replication methods
Change Data Capture is more efficient since only data changes after the previous replication are synced with data in the data warehouse, unlike full replication that scans and writes the entire source database to the destination. Kafka CDC and Oracle to Kafka CDC Methods
CDC delivers real-time data and enables real-time processing
Some CDC methods like log-based CDC update transaction logs as per changes in the database. This ensures data in the data warehouse can be updated in real-time, a feat that is not possible with batch processing, that runs at periodic intervals. GoldenGate CDC and a better alternative
CDC can detect Deletes in source database
Unlike incremental batch processing that cannot detect Deletes but only shows new and updated rows in source tables, CDC monitors Delete operations as a matter of course, and they can be carried out on the destination data. About Oracle to Postgres Migration
CDC is sparing of source systems
If source databases are part of production systems, it is necessary not to overload them. Databases like Postgres, MySQL, and SQL Server have native CDC implementation which means they maintain transaction logs. A technique can be implemented to read the CDC logs, detect changes, and write them to the target without having to query the database for changes regularly. SQL Server to Databricks (Easy Migration Method)
Types of Change Data Capture
Change Data Capture or CDC can be implemented in a variety of ways:
Change Data Capture with DATE_MODIFIED
This CDC method involves monitoring changes in metadata for every row, including who created it/who most recently modified it as well as the dates of these actions. The CDC method tracks when the changes were extracted and then runs a filter on the DATE_MODIFIED column to only retrieve rows with changes in data since the last extraction. DATE_MODIFIED method of CDC is useful for ETL (Extract Transform Load) operations in traditional data warehouse systems where deletes are not processed by source tables. Snowflake CDC With Streams and a Better CDC Method
Disadvantages of Change Data Capture with DATE_MODIFIED statement
Data deletes cannot be tracked since a deleted row does not have DATE_MODIFIED applicable. Also, DATE_MODIFIED needs to be set properly on all tables. Change extraction may involve heavy use of resources. Indexation of DATE_MODIFIED is possible, but storage costs will increase, and the additional index created will need to be continuously updated. Oracle vs Teradata (Migrate in 5 Easy Steps)
Change Data Capture with Triggers
Some databases like Postgres, SQL Server and MySQL have trigger functions that carry out actions defined by users when events like data insertions, updates and deletes happen. Triggers can capture changes in a specific table and track them in a different table that functions as an event queue. Trigger functions can be enabled for data pipelines so only data that has changed since the last extraction is processed but this needs repeated querying of the event table. Triggers can detect insertions, updates, and deletes and support tracking of custom information like the identity of the user performing the operation. SQL Server to Databricks (Easy Migration Method)
Disadvantages of Change Data Capture with Triggers
When a trigger is fired, storing row changes in a shadow table can vastly increase execution time, sometimes upto 100% of the transaction. Even if you consider a lower impact alternative like storing the primary key of a table only, it will require a join back to the source table to get the changes, thereby increasing the load. The Easy Way to CDC from Multi-Tenant Databases
You also need to take into account that intermediate changes will be lost, if more than one change happens on the same row. In case of changes to schema of the table in the database, it will have to be manually recreated on the event table. Also, if there is truncation of the source application, the trigger probably will not fire, and changes will not get recorded. Debezium CDC Explained and a Great Alternative CDC Tool
In case of custom code introduced by vendors for implementing triggers, it may impact migrations to other databases in the future. Overall, trigger-based CDC may involve quite a bit of coding and can reduce database performance since multiple writes to a database will be required every time a row is inserted, deleted, or updated. Cloud Migration (Challenges, Benefits and Strategies)
Change Data Capture with Diff
Diff-based CDC relies on capturing data changes by comparing the current state of the data source against the state of the data source when the last extract in the data pipeline took place. This CDC method is resource-intensive since the system would need to access all the data to determine what changed and use of space required would greatly increase too, since a snapshot of the data from the latest run would always be required for Diff-based CDC implementation. Diff-based CDC can work well with low data volumes. Source to Target Mapping Guide (What, Why, How)
Disadvantages of Diff-based Change Data Capture
Real-time Change Data Capture is virtually impossible since the Diff CDC operation is compute-intensive and requires too many resources to be performed very often. There will also be a proportional increase in resource usage in tandem with growth in data volumes. Also, the data extraction is done via the query layer in Diff-based CDC, which can slow down data source systems. It also requires recurrent querying of tables which is again taxing on compute resources. Postgres CDC (6 Easy Methods to Capture Data Changes)
Log-based Change Data Capture
Log-based CDC uses database transaction logs that are updated in real-time. These are basically logs of operations carried out on a database table and are maintained for data recovery or data replication purposes. Most database systems have them as a feature. Log-based CDC uses these transaction logs to extract and capture change events and is a low-impact process. About Oracle CDC
A great advantage of log-based CDC is that it updates data in real-time and does not affect performance of source systems unlike trigger-based CDC or Diff-based CDC. Log-based CDC can detect all data events like Inserts, Updates and Deletes. Though most databases have logs, for e.g. MySQL’s Binary Log, Oracle’s Redo and Archive logs, or PostgreSQL’s logical replication, log-based CDC cannot be applied on all databases, this is true of very old DB versions that may not have the functionality. About SQL Server CDC
Disadvantages of Log-based Change Data Capture
A point to note is that transaction logs only store transactions on a database done within a specific period, for e.g. within the last week, month etc. The full transaction history is not usually available. Transaction log implementation is usually vendor-specific, and coding done may hamper movement of data to other databases in the future. About Kafka CDC
Real-time, Automated Log-based CDC with BryteFlow
BryteFlow is a no-code CDC replication tool that follows a real-time, automated Change Data Capture process. There is no coding for anything including extraction, CDC, masking, partitioning, SCD Type2. This is a plug and play GUI driven, self-service CDC tool. About Oracle to Postgres Migration
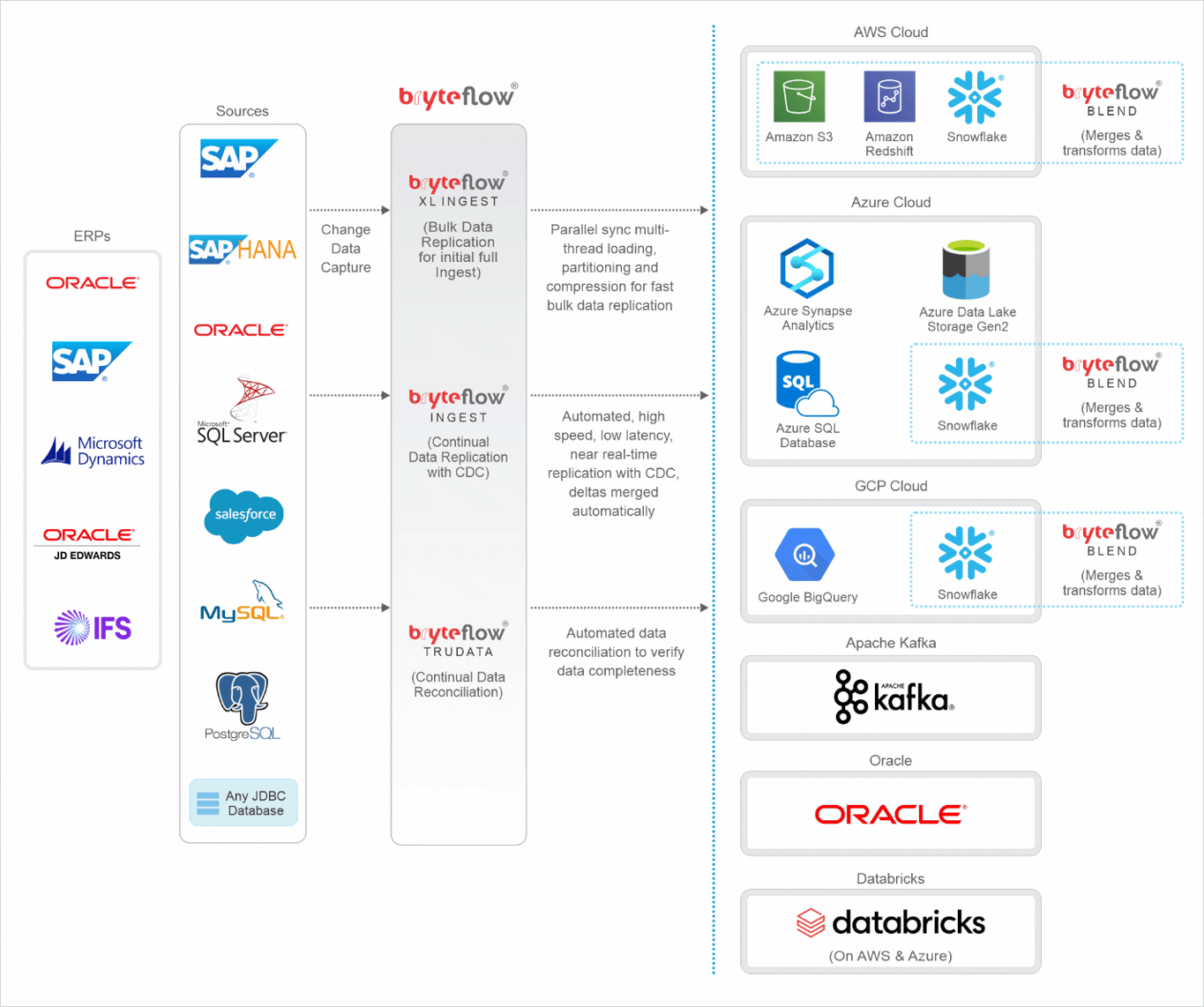
BryteFlow CDC Tool: Automating CDC Replication
- The CDC Tool does the first full ingest with parallel, multi-thread loading and smart compression, and captures incremental data changes with log-based CDC in real-time. How BryteFlow Works
- Data Capture with Automated Upserts: The BryteFlow CDC tool automatically merges change data with existing data instead of creating new rows. This is very low-impact and does not affect source systems. No third-party tool or coding is required. Snowflake CDC With Streams and a Better CDC Method
- Every process is automated including data extraction, merging, mapping, masking, or SCD type 2 history. A range of Data Conversions are available out-of-the-box. Zero-ETL, New Kid on the Block?
- CDC Tool provides Time-series data and a history of every transaction. Oracle vs Teradata (Migrate in 5 Easy Steps)
- Extremely fast CDC Replication at approx. 1,000,000 rows in 30 seconds. *Much faster than Oracle GoldenGate, Qlik Replicate or HVR (*results during a client trial) Kafka CDC and Oracle to Kafka CDC Methods
- CDC Tool supports SAP ETL- extracts data from SAP at application level or database level with SAP Data Lake Builder
- Tool supports CDC to On-premise and Cloud platforms such as S3, Redshift, Snowflake, Synapse, ADLS Gen2, SQL Server, Kafka, Teradata, SingleStore, BigQuery and Databricks.
- Automated Data Reconciliation, checks data completeness with row counts and columns checksum Postgres CDC – 6 Methods
- The CDC Tool delivers data ready to use for Analytics or Machine Learning. Try BryteFlow Free
BryteFlow as an Alternative to Matillion and Fivetran for SQL Server to Snowflake Migration




