
In our guide to Data Migration, we look at what data migration is all about, the different types of data migration, the processes and strategies followed in a data migration implementation, challenges encountered and what features an ideal data migration tool should have. There is also a step-by-step demo of BryteFlow XL Ingest, our specialist data migration tool that can move very large data in seconds. If you would like to know about Bryteflow Ingest and hop across to the demo immediately, click here
Quick Links
- What exactly is Data Migration?
- Benefits of Data Migration
- Types of Data Migration
- Data Migration Strategies
- Data Migration Process and Planning
- 13 Data Migration Challenges and Risks
- Data Migration Methods
- About Data Migration Tools
- Cloud Data Migration Tools – Must-have Features
- BryteFlow XL Ingest – Data Migration Tool for Large Volumes
- Migrating Data with BryteFlow XL Ingest Step by Step
What exactly is Data Migration?
Data Migration is the process by which data is moved from one storage or computing platform to another. It may also involve moving or converting data from one format to another and shifting data from one application to another. The data migration may be triggered by the need for legacy systems to be replaced or complemented by new applications, or a decision to move on-premise databases to resource and cost-efficient Cloud storage and Cloud computing platforms. The overarching goal is to optimize data operations for the organization and possibly enable real-time data analytics. SQL Server to Snowflake Migration (Compare BryteFlow with Matillion and Fivetran)
Benefits of Data Migration
The benefits of data migration are many and especially pronounced when migrating data to the Cloud. These are some of the benefits that accrue to organizations migrating data. Learn about ERP Cloud Migration
Data migration reduces costs and increases operational efficiency
Data migration can centralize your data so different stakeholders can collaborate, access the same data, and derive better business insights (no more data silos). Data migration to the Cloud can simplify data management with better performance, reliability, and drastically reduced downtime. Also, older technologies attract higher maintenance time and costs – migrating data to the Cloud can reduce costs of hardware and technical resources since you need fewer people to manage data. Oracle to Postgres Migration (The Whys and Hows)
Data migration enables better data analytics
Data migration is usually done to improve data efficiency and depending on the data architecture and requirements you could enable real-time data for efficient business analytics. Modern data migration software delivers data ready for analytics that can be used easily by modern BI tools. This analyzed data can deliver powerful insights based on actual customer demand and trends to influence better decisions and favorable business outcomes. Cloud data migration allows for centralized access of data from any location so chances of inaccurate data are highly reduced. SQL Server to Databricks (Easy Migration Method)
Data migration provides flexibility, agility, and scalability
This data migration will very likely not be your last one. The world of big data is always evolving with better analytics software, faster Cloud warehouses and newer applications coming into play. What if you need to move your data again or enable access to it with a new application? Migrating data especially to the Cloud can enable you to pack up your data and move between platforms and applications easily if required. Scalability is also guaranteed since spinning up more computing power on the Cloud can be easily done to process a sudden high-volume influx of data. Oracle to SQL Server Migration (Reasons, Challenges & Tools)
Data migration can mean better security and compliance
As part of the data migration process you need to ensure that the data is secure, properly protected and in line with regulatory compliance. Migrating to the Cloud can enable multi-layered and role-based security with complete protection against threats. It also allows data to be accessed and deleted if it is not according to regulations and non-GDPR compliant. Oracle vs Teradata (Migrate in 5 Easy Steps)
Data migration can make staff more productive
Migrating to the Cloud usually means access to fully managed data services and infrastructure. This means your valuable tech resources do not have to be involved in the nitty gritty of managing data and servers. Their time can be more productively used for high-end tasks which means a higher ROI on data for your organization. About Oracle to Postgres Migration
Data migration can mean lower data costs thanks to autoscaling and lower storage costs
If you are migrating data to the Cloud, a great benefit is that of auto-scaling where compute servers can be scaled up or down automatically as per requirement. Users can opt for additional servers if needed and can turn them off when not required. In effect you pay only for the time the resources were actually used. The cost of storing data is also very low on the Cloud which is another great reason for data migration. For e.g. data storage on Amazon S3 is as low as $0.023 per GB to start with and there is no infrastructure to manage. Learn about AWS DMS (AWS Data Migration Service)
Types of Data Migration
Data migration can be categorized under various types. Each data migration can comprise of one or more types. Zero-ETL, New Kid on the Block?
Cloud Migration: Migrating data to the Cloud
Cloud migration is increasingly being seen these days when organizations move databases, digital assets, services, applications and operations from on-premise servers completely or partially to the Cloud. Cloud migration could also mean moving from one Cloud to another e.g. moving from Azure to AWS Cloud. Cloud platforms include Amazon S3, Amazon Redshift, Azure Synapse, Azure Data Lake Gen2, Google BigQuery, Snowflake, Databricks, PostgreSQL, SQL Server and Apache Kafka.
Database Migration: Migrating the database from one DBMS to another
Databases are used to store data electronically in a structured, organized way in computer systems and are typically organized in rows and columns in tables for easy access, processing, and data querying. A database is managed by a DBMS (Database Management System). The data, the DBMS, associated applications are collectively referred to as the Database. Database migration typically means migrating from one DBMS to another or upgrading to the latest version of the DBMS being used. The first option can throw up some issues if data structures at source and destination are different. BryteFlow uses automated Change Data Capture to migrate data from databases like SAP, Oracle, SQL Server, MySQL, Postgres etc. About Oracle to Postgres Migration
Application Migration: Migrating data for applications
Application migration is required when an organization changes the application or the software vendor. A new application environment may need drastic transformations to support new application interactions. The fact that both new and old infrastructures may use different data models and data formats is a known obstacle. How BryteFlow scores against Matillion & Fivetran for SQL Server to Snowflake Migration
Storage Migration: Migrating data to new storage
When an organization needs to migrate its data from one storage place to another it is called Storage migration. Reasons to do this could include upgrading old storage equipment to modern, technologically sophisticated storage equipment. Please note, this usually does not change the data format or content but only the mode of storage. For e.g., migrating data from physical on-premise servers to virtual servers in the Cloud. SQL Server to Databricks (Easy Migration Method)
Data Center Migration: Migrating data to a different physical location or simply to new equipment
Data center migration refers to migration of data to new data center infrastructure, this could be a different physical location, or it could mean transferring data from old equipment to new equipment within the same facility. A data center has servers, switches, routers, computers, storage etc. which may become old and glitchy and this may call for migration of data to newer equipment. Oracle vs Teradata (Migrate in 5 Easy Steps)
Business Process Migration: Migrating data after business reorganization
After business restructuring or mergers and acquisitions, data of business processes, key metrics and applications may need to be moved to a different computing environment, this is business process migration. Key metrics could include data about customers, products, operations and more. About Oracle to SQL Server Migration
Data Migration Strategies
By now you must have realized moving high volumes of data to a different environment is not exactly easy. Data migration needs to be planned for and strategized. Here are some data migration strategies or approaches that are popularly followed. Zero-ETL, New Kid on the Block?
Big Bang Data Migration
Big Bang data migration is exactly what it sounds like, all the data is moved in one go from source to target. This is done in a small space of time and operational systems are shut down and unavailable for the duration of the data migration and transformation on the target. Big Bang data migration is typically done on a holiday or the weekend so as to not impact business operations and users. This data migration strategy is more applicable to small and medium size businesses (assuming they have smaller volumes of data). Successful Data Ingestion (What You Need to Know)
Big Bang Data Migration: Advantages and Disadvantages
The advantage of Big Bang data migration is that it is a simple process, users don’t need to work on old and new systems in parallel and data migration is carried out in a short amount of time. The disadvantage is that high data volumes can overwhelm the network throughput and API gateways during transmission leading to a high risk of costly failure. The Big Bang strategy is not appropriate for mission-critical applications and data that needs to be available 24×7. Postgres to SQL Server with BryteFlow
Trickle Data Migration
Trickle Data migration as the name suggests, is based on Agile methodology where data is migrated in phases. Trickle data migration is also called phased or iterative migration. The complete process is divided into sub-migrations defined with objectives, scope, timelines, and quality checks individual to each. With Trickle data migration old and new systems are run concurrently, and data is moved in small increments. This means that the new system and the old system run in parallel, preventing downtime or operational interruptions. However, this data migration strategy requires an excessive amount of effort, time, and resources. The design of these implementations can be quite complex as compared to that of the Big Bang data migration. Learn about Oracle CDC
Please note that the process’s iterative nature makes it more complicated and long drawn. Data must be synchronized between the old system and the new environment throughout the entire process. The trickle migration strategy is ideal for large organizations that have huge volumes of data and cannot afford system downtime. Learn about SQL Server CDC
Trickle Data Migration: Advantages and Disadvantages
The advantages are that the trickle data migration strategy offers zero downtime and 24×7 availability of applications, so operations are not disrupted. There are also fewer chances of unanticipated failure. It is much simpler to evaluate each sub-migration for success since the enormous amount of data has been broken down into smaller pieces. The disadvantage is that it is a more costly and complex process, consumes more time and needs more effort from tech resources to keep systems running in parallel and to monitor them. The data migration team needs to monitor and track data being transported and to ensure users can toggle between systems to access data. How to Manage Data Quality (The Case for DQM)
Another strategy is to keep the old system fully operational till the data migration has ended and let users switch to the new system on target only after the entire data has been migrated. This method too calls for greater efforts on part of the tech team to make sure data is synchronized in real-time across source and target when it is created or changed. It is imperative that any changes in data at source should trigger updates in the target. A Trickle migration can be a zero-downtime migration, where the source database remains available and accessible to users even when the migration process is going on. However, there may be a small time frame where users are disconnected after the migration in order to connect to the new target. Oracle vs Teradata (Migrate in 5 Easy Steps)
Data Migration Process and Planning
Every data migration process requires intensive planning. These are the key phases:
Data Migration Process: Pre-migration plan
Planning in the pre-migration phase is the 1000 ft view of the data migration. Here you will set timelines, budgets, schedules, and deadline for the data migration. You may need to hire an ETL developer or data engineer to spearhead the data migration. Other specialists like system analysts and business analysts may also be needed and brought on board. About Automated Data and ETL Pipelines
Data Migration Process: Assessing and reviewing source
This is the step when you need to review the data at source. You need to define the data and applications to be migrated and decide whether it is a good fit for the target system. Does the data have many fields? You may not need to map all of these for your requirements. If there are missing data fields, they may need to be inserted from another location. Decide what needs to be migrated and what can be excluded. Examine the data if it is accurate, complete, and worth migrating. The bandwidth and hardware requirements should also be reviewed, and a framework should be laid down that includes data mappings, tests, automation scripts etc. Also, there is a need to examine the amount of data preparation and transformation that will be required to optimize the data for the new system. Learn the Whys and Hows of Oracle to PostgreSQL Migration
Data Migration Process: Defining and designing the migration
Do you need a Big Bang or Trickle migration? You need to select the appropriate migration strategy for your organization, then work on customizing the process. Put down the solution’s technical architecture and examine and validate the hardware and software required, this may call for some pre-validation testing to confirm whether requirements and settings are right for the project. Start setting timelines, defining schedules, and considering potential issues by reviewing the type of data, design and the target system. What steps you will take to secure the data; all of this will need to be documented before the data is migrated. Learn about Oracle to SQL Server Migration
Migrating schema and table creation: Two methods can be followed here, either you get an understanding of your original schema and recreate it exactly on the target or trust an automated data integration tool like BryteFlow to automate table creation and updates on target. The Easy Way to CDC from Multi-Tenant Databases
Data Migration Process: Building the migration solution
It is important to get the data migration implementation just right, and not compromise with ‘just ok’ results. This can be done by dividing the data into partitions or subsets, migrating one partition at a time and testing the results. If the data volumes are very large, a ‘build and test in parallel’ mode can be adopted. Oracle vs Teradata (Migrate in 5 Easy Steps)
Data Migration Process: Backing up your data before moving it
You need to back up all your data before it is migrated. This is important and protects you in case of data migration failure resulting in data loss.
Data Migration Process: Execution and validation
This is the point where your data migration goes live and the ETL (Extract Transform Load) process begins. If yours is a Big Bang migration it will not take more than a couple of days, but a Trickle or phased migration might need more time. Before starting, make sure your data fields at target are the same as the ones at source. Track and validate the process to ensure there is no failure or downtime. Communicate actively with business teams to define the schedule of sub-migrations to be rolled out and to which users. Successful Data Ingestion (What You Need to Know)
Data Migration Process: Conducting live tests
Data migration testing must be carried out across all phases including design, execution, and post- migration. In case of a Trickle strategy, each subset of migrated data must be tested to address issues before they snowball. Test often and test well to ensure data is migrated to the target accurately and completely, with all data elements intact and in line with requirements. Please note that though code might have been tested in the build phase it is imperative to use actual data to test the migration design as well. Debezium CDC Explained and a Great Alternative CDC Tool
Data Migration Process: Auditing the data
After the implementation goes onstream and before the migrated data can be used, it is important to validate the migrated data with the main business users. This audit verifies that the data is accurate, has been properly migrated and logged and that the old data system can be decommissioned. About Postgres CDC and 6 Easy Methods of Data Capture
Data Migration Process: Decommissioning and monitoring
This is a post-migration process stage where the old data system is decommissioned and retired since all users are now using the new data system. The new system may need to be monitored closely for some time to ensure smooth working. Postgres to SQL Server with BryteFlow
13 Data Migration Challenges and Risks
Data migration on the face of it sounds like an easy concept but is notoriously challenging. Here are some key data migration risks that are commonly encountered including loss of data, unanticipated file formats, failure to do due diligence for planning and reviewing source data, and not doing thorough documentation etc. SQL Server to Databricks (Easy Migration Method)
Data Migration Challenge 1: Not knowing or analyzing source data
You should know about issues in source data like incomplete or missing data, wrong spellings and inaccurate data. This gap has to be fixed before your data can earn user acceptance. Data can be obscured in old systems, and data fields may be missing, this is another scenario where incomplete and inaccurate data might be migrated leading to problems down the road. A rigorous data analysis before the migration can prevent this.
Data Migration Challenge 2: Data incompatibility
A successful data migration must ensure data from different sources and in different formats can be migrated to the target and used for analytics easily. If the data format and database structure of the old system and the new system differ, the incompatibility must be addressed. Incompatibility may come up even when data is moved to another system that has different character encoding. Cloud Migration (Challenges, Benefits and Strategies)
Data Migration Challenge 3: Not enough documentation
If organizations try to rush the data migration without getting enough documentation about data being migrated it can be challenging to understand the data and how to migrate it, this could be a classic ‘Nightmare on Data Street’ scenario.
Data Migration Challenge 4: Lack of data governance
A data governance plan should be in place early on to decide the roles and responsibilities of each person in the data migration team, the data quality standards, and data security processes. If data governance is missing, data quality of the migrated data would be sub-par and put data security at risk. Source to Target Mapping Guide
Data Migration Challenge 5: Ignoring cross-object dependencies
Very often it may happen that dependent datasets are forgotten and not included in the data migration plan. It would be helpful to have a contingency plan for cross-object dependencies, so the implementation deadline is not impacted.
Data Migration Challenge 6: Processes are not integrated
Different people using different technologies may end up in a failure to transfer and transform data properly and design that does not perform well in analysis, development, testing and implementation phases, leading to wasted time and money. It would be advisable to have a common platform and collaborative software to link and store inputs, outputs, feedback etc. from each stage to ensure a successful data migration process.
Data Migration Challenge 7: Specifications not validated
You need to validate data transformation specifications with actual data very early in the process. This ensures that the data migration process will not suffer from flawed specifications that may prove expensive to fix and lead to unfavorable outcomes down the line.
Data Migration Challenge 8: Lack of testing
Testing is crucial in the data migration process. You need to test the migration early with different test scenarios and test cases. Testing with the full volume of real-world data for worst case scenarios and possibilities is helpful to pinpoint potential issues, rather than using smaller data samples.
Data Migration Challenge 9: Lack of communication
Lack of communication with stakeholders can lead to problems later. Get buy in from users before the data migration begins, ideally at the planning stage. Explain to the key stakeholders how the data migration will affect them, what formats etc. the data will be delivered in, training required (if any), data migration schedule, information about the data to be moved etc. You don’t need users to be questioning the migration and messing up the schedule later. After this, keep stakeholders apprised of the progress of the data migration and see to it that they get status reports regularly in case of errors or glitches. Oracle vs Teradata (Migrate in 5 Easy Steps)
Data Migration Challenge 10: Data loss and data leaks
Data being migrated could be very sensitive, so it is necessary to encrypt the data. Equally important is to prevent data loss for which planned backups of data can be instituted.
Data Migration Challenge 11: Results are not evaluated in time
The results that are projected after the final data migration should be tested and evaluated in good time. imagine the situation if after all the effort, users find the data migrated is incompatible with the new system. This is a very expensive, time-consuming mistake and can be avoided with agile testing done early in phases and getting users to create test cases once they start getting samples of the actual data output.
Data Migration Challenge 12: Time and budget overruns
It is easy to go over budget with a data migration since hiring of experts, vendor software costs can easily exceed the pre-determined budget. Data migration schedules too might get frustratingly lengthened due to delayed transmission, owing to slow networks and connections, blockages, glitchy infrastructure etc. Many of these factors can be studied and planned for at the outset to minimize the occurrences of overruns.
Data Migration Challenge 13: Lack of expertise and high-quality tools
Data migration is a complex task, and you can save lots of money be ensuring you have the right technical expertise for the job. The team involved must have a deep knowledge of data integration tools, to make your data migration project complete on schedule successfully. Also important are the data migration tools they use, these must be proven and of top quality, preferably with a lot of automation in place so the team can concentrate on crucial tasks instead of mundane tasks like data prep and cleansing. Low quality tools may be less expensive but cost more in the long run, in terms of delays and glitches. Source to Target Mapping Guide (What, Why, How)
Data Migration Methods
What are some of the methods that can be used to migrate data? Here are 4 main ones.
Data Migration with Hand Coding
Hand coding is a long laborious process where developers will write code to perform the data migration. Hand coding for a data migration is not very effective since today’s data environment is extremely changeable. New sources can be added, new specifications may crop up. Newer data formats and incompatibility of old data formats with the new data system – all these issues need to be dealt with. With hand coding this can be a very expensive, long drawn process. Getting real-time data also may be near impossible.
Data Migration with Data Replication Tools
Data migration can be performed with data replication tools but usually the data is taken across in its original form when data is copied from one database to another. Replication tools that transform data are not commonly found. Data replication tools are good for backups and failovers but have limitations when data is migrated to a new system with different formats, architectural differences, and usage patterns. Debezium CDC Explained and a Great Alternative CDC Tool
Data Migration with Data Integration Platforms
Data integration platforms continually ingest and integrate data (very often in real-time) on the target to provide data for Analytics and operational applications including ERP, CRM, and BI tools. These data integration platforms can extract and merge data from different sources, load and transform it to a format that can be used on target. Compare BryteFlow to Fivetran and Matillion
Data Migration with Built-in Database Replication Tools
Licensed databases often come equipped with their native database replication tools for e.g. GoldenGate with Oracle Enterprise Edition and SSIS (Microsoft SQL Server Integration Services) with SQL Server (Learn about SQL Server CDC). These tools are easy to use but the visibility and transformation capabilities may often be lacking. See how BryteFlow scores over Oracle GoldenGate for CDC
About Data Migration Tools
Data migration tools are the crucial factor in a successful data migration. There are broadly 3 types of data migration tools broadly categorized by their origin, goal, source, and destination of the migration. These are On-premise migration tools, Cloud based migration tools and Self-scripted migration tools. Depending on requirements, organizations could use one or all of them. Let’s take a closer look.
Self-scripted Data Migration Tools
Self-scripted migration tools are usually meant for data migration involving sources and targets not handled by other tools. Look on them more as a quick fix. Though they may require a short time to implement, self-scripted migration tools require a high degree of coding dexterity. They can take up time of data engineers that can be used in more productive tasks. It can also prove an expensive and difficult process when requirements change and if the process is not well documented.
On Premise Data Migration Tools
On Premise data migration tools are used within organizations that have fixed data requirements with no scaling anticipated. The sources and destinations are all part of one location. These organizaions may have compliance and security requirements that restrict them from moving data to a Multi-tenant or Cloud-based platform. On-premise data migration tools offer low latency and the IT team has a large role to play in maintenance of tools and managing security and software updates. They also have complete control of the full stack of physical and application layers.
Cloud Based Data Migration Tools
Cloud based data migration tools are ideal for organizations that need to migrate data from multiple sources and platforms to Cloud based targets. They have auto-scaling to respond to changing data requirements. Cloud based data migration tools can provide concurrent access to users in different locations to access data in common data warehouses with common tools so there is a unified view of data. Cloud-based migration tools are scalable and agile and provide on-demand compute power and storage as dictated by requirements. They have redundant architecture but may elicit concerns about security among stake holders. Pricing is usually pay-as-you-go which provides a higher ROI. Postgres to Oracle with BryteFlow
Cloud Data Migration Tools – Must-have Features
Though we have discussed other types of data migration tools, in today’s environment it makes sense to look at Cloud data migration tools since they offer scalability, flexibility, agility, collaboration and ease of use, not to mention the economies of storing data on the Cloud. The Cloud data migration tool you select depends on the use case and other requirements. However, it must have some important features.
Data migration tool compatibility with sources and destinations
What are the number and types of data sources and destinations you have? Will the data migration tool and the operating platform it runs on support these? Most cloud-based migration tools like our very own BryteFlow are compatible with a wide range of data sources and destinations like Azure, AWS and GCP. Cloud Migration (Challenges, Benefits and Strategies)
The data migration tool must offer reliability
Cloud based migration tools have redundant architectures and are highly available, so they have minimal or no downtime. Some like BryteFlow even offer automated catchup in case of network failure.
Is security addressed by the data migration tool?
The data migration tool must offer data protection measures like encryption and masking of sensitive data. It must allow role-based access and should be compliant with SOC 2, HIPAA, GDPR, and other governance regulations. Related features like disaster recovery services are also desirable.
The speed of the data migration tool matters
What is the throughput of the data migration tool? How quickly does it process data? Is it suitable for enterprise scale data and can it move petabytes of data accurately and easily to target? For e.g. BryteFlow Ingest provides a throughput of 1,000,000 rows in 30 seconds. It offers parallel, multi-threaded loading and smart partitioning to process huge volumes of data. BryteFlow processes Oracle data approx. 6x faster than GoldenGate. Oracle CDC (13 Things to Know)
Transformation offered by the data migration tool
Is the migration tool capable of transforming data to make it cloud-ready, and synchronizing data between source and destination to keep data updated at destination? BryteFlow Blend for Data Transformation
The data migration tool must respond to data drift
Check to see if the solution can recognize and respond to drift modifications pertaining to schema, semantics, and infrastructure, it should ideally.
The data migration tool should offer multi-modal methods for handling real-time data
The data migration tool must have the capability to handle Batch, CDC, and real-time stream processing for real-time use cases, such as initial load and ongoing synchronization of data. BryteFlow provides real-time, analytics-ready data on target using log-based CDC. Change Data Capture and why automate it
The data migration tool must have the ability to handle terabytes of data easily
How much data can be processed by the data migration software? Even if your future data requirements go beyond these limits, can the software handle it? BryteFlow can extract and process petabytes of enterprise data effortlessly. More on BryteFlow Replication
Connectivity and flexibility must be part of the data migration tool
The data migration tool must be compatible with and support the software and systems that your organization uses. Besides compatibility with today’s systems, it must also support new and changing business requirements in the future. The Easy Way to CDC from Multi-Tenant Databases
The data migration tool should perform on Cloud and On-premise
Is the data migration tool versatile enough to perform in multi-cloud, hybrid, on-premise, and cloud environments?
The data migration tool should have reusability
Make sure that the design details and best practices of the data migration tool can be easily shared and used over again.
Portability is a must-have feature in your data migration tool
The data migration tool must be robust and flexible enough that you can switch targets and sources and connect to these with a couple of clicks. No coding should be required, and the implementation should be unbreakable. BryteFlow for e.g., is completely automated, no coding required.
BryteFlow XL Ingest – Data Migration Tool for Large Volumes
If you want to solve large data migration challenges, the BryteFlow XL Ingest for data migration and replication of very large datasets is the right tool for you. BryteFlow XL Ingest, our data ingestion tool was created especially for huge volumes of data. It uses smart partitioning technology to partition the data and parallel sync functionality to load data in parallel threads. Successful Data Ingestion (What You Need to Know)
BryteFlow XL Ingest, how it helps to migrate big data
- XL Ingest uses smart partitioning technology and parallel multi-threaded loading to load data fast.
- Can extract and deliver ready-to-use data in near real-time – faster time to value.
- Data migration tool saves time with completely no-code and automated data migration.
- Data migration tool provides high availability out-of-the-box.
- BryteFlow XL Ingest moves huge datasets with tables of unlimited size, provides analytics-ready data on target.
- Easy to use point-and-click interface for data replication, no coding needed.
- High throughput, data migration tool delivers terabytes of data at high speed (1,000,000 rows in 30 secs.) without slowing down of source systems.
- Loads data to target using log-based Change Data Capture, does not impact source systems.
- Automates schema creation, DDL and table creation on the destination with best practices for performance. How BryteFlow Works
- Data migration tool provides SCD Type2 history, time-stamped data and incremental changes are merged with existing data to keep it current.
- Automated data reconciliation is provided by BryteFlow TruData with granular control using row counts and columns checksum.
- Moves in data from different data sources like like SAP, Oracle, SQL Server, MySQL, Postgres etc. to On-premise and Cloud platforms like Amazon S3, Amazon Redshift, Azure Synapse, Azure Data Lake Gen2, Google BigQuery, Snowflake, Databricks, PostgreSQL, SQL Server, SingleStore, Teradata and Apache Kafka.
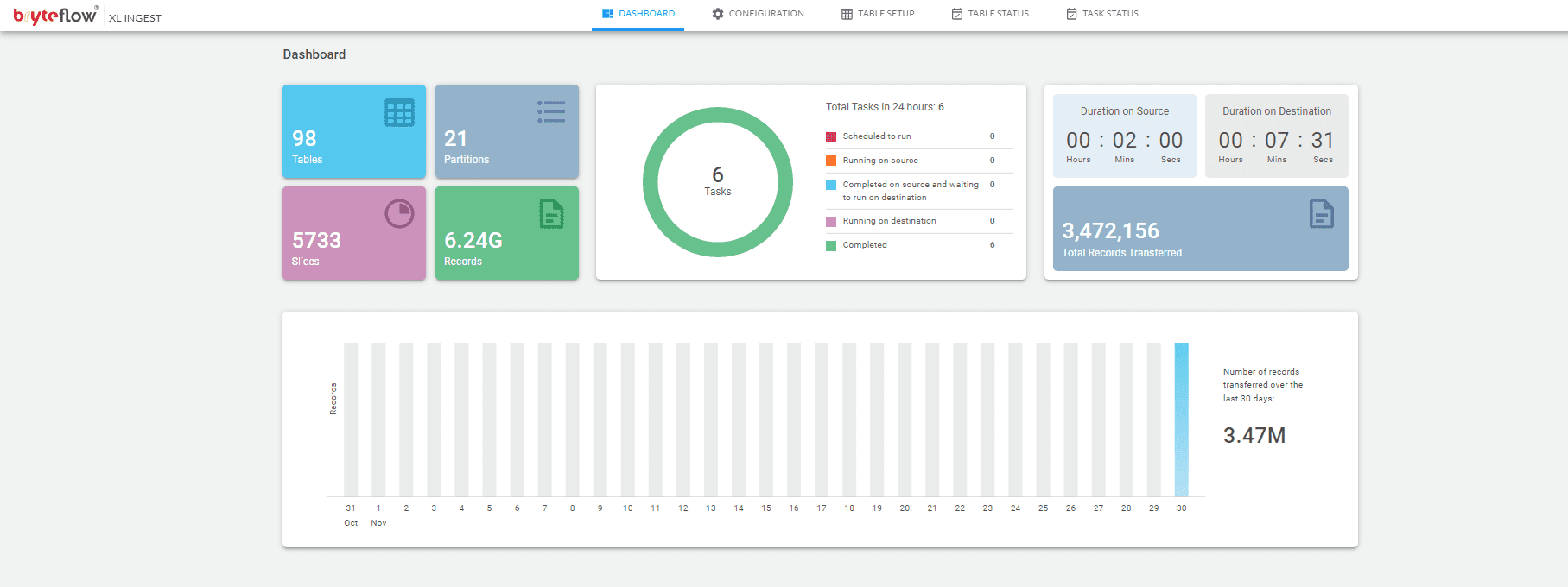
- Data migration is continuously monitored by a built-in dashboard that monitors the performance and validates the data passing through the automated pipeline.
If you are interested in BryteFlow Ingest and XL Ingest for data migration, please Contact us for a Demo
Migrating Data with BryteFlow XL Ingest Step by Step
Please observe how in a couple of clicks you can set up data migration with the BryteFlow XL Ingest tool. The initial full refresh of data is carried out by BryteFlow XL Ingest and incremental data and deltas are captured by Bryteflow Ingest using CDC. All inserts, updates, and deletes are automatically merged with initial data continually (or as per the schedule selected) to synchronize with source.
Step 1
Under the Configuration tab, point the XL ingest to the ‘Configuration of Ingest’. From which XL ingest will automatically pick the DB connection details.
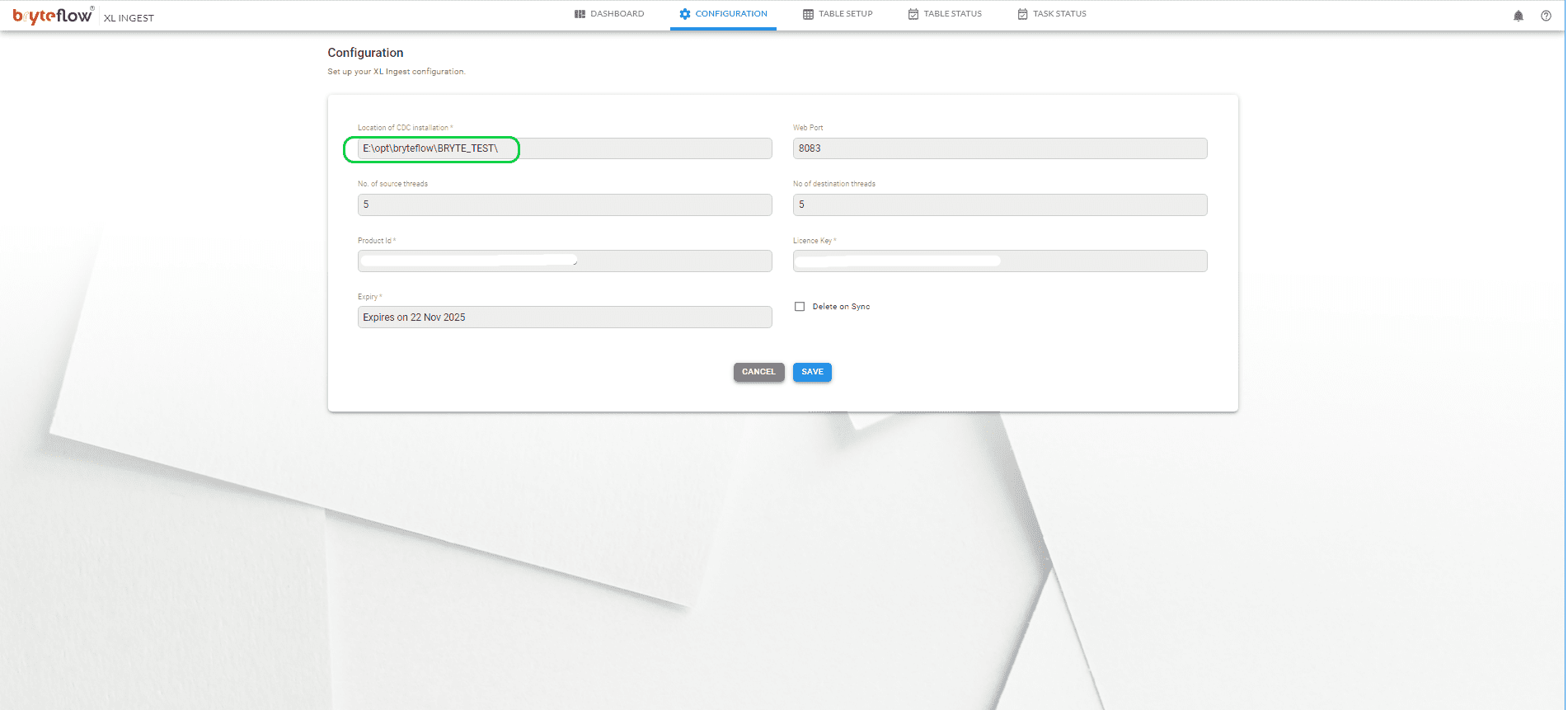
Step 2
On the Table Setup screen configure the table to be brought across. Select the column to slice and use table partitioning mode – Auto or Manual.
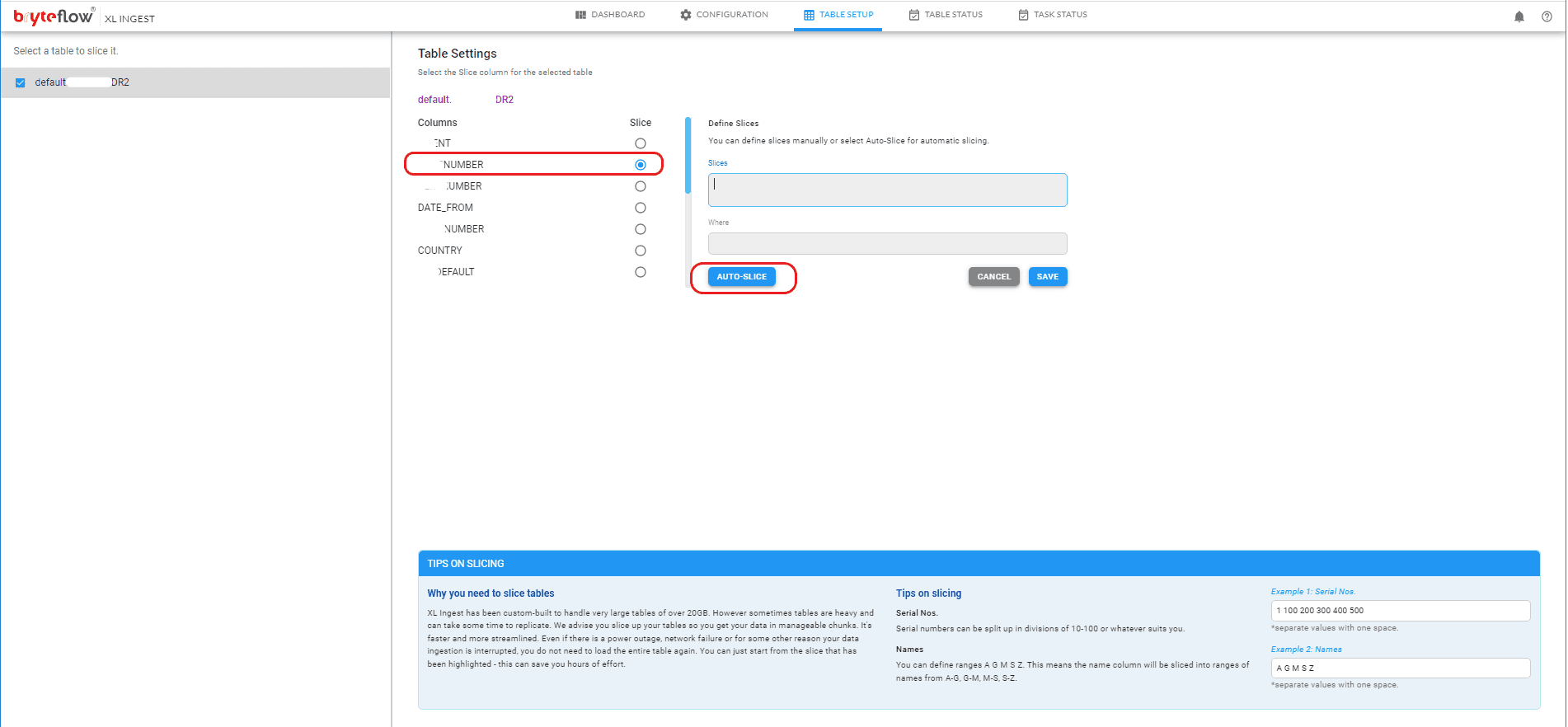
Step 3
For “Auto Slice”, update the number of slices and prefix as below,
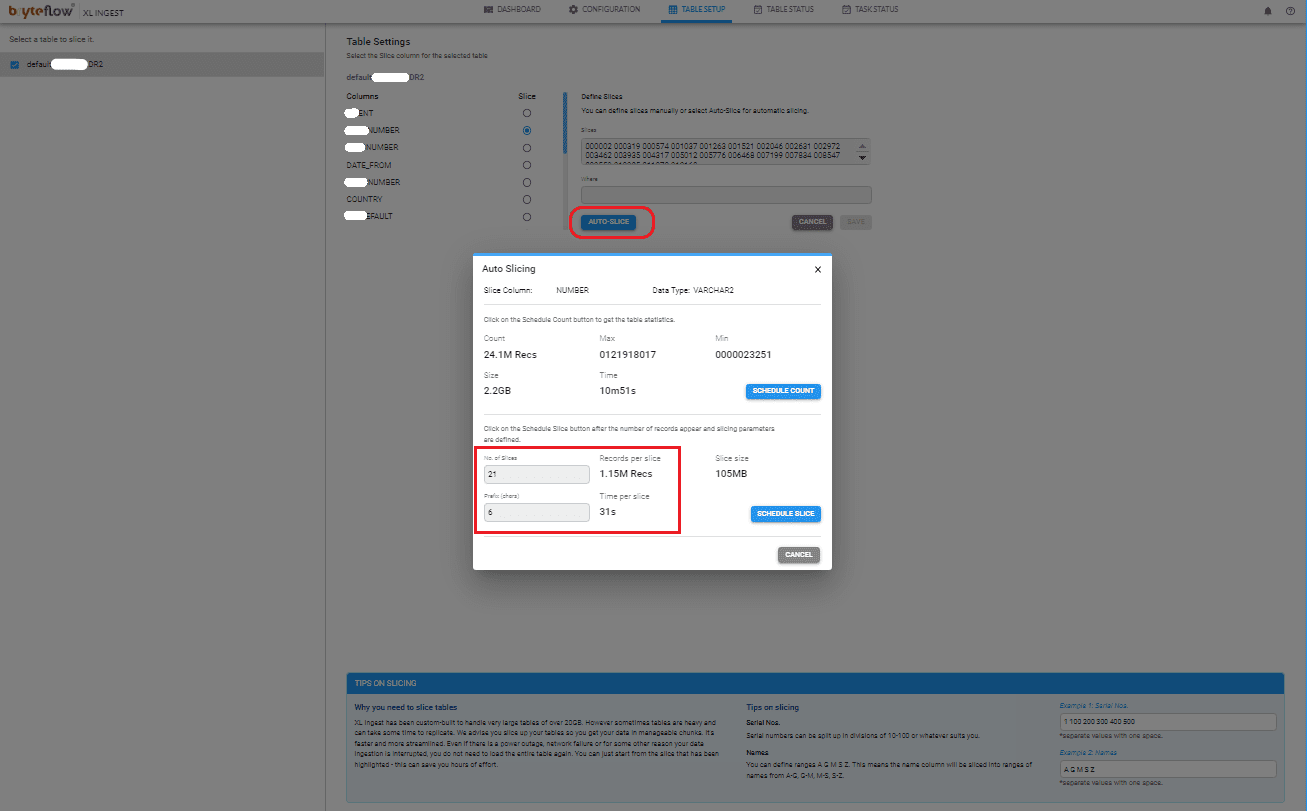
Step 4
Once the slicing is complete, the details of the slice and number of records assigned to each slice can be seen under the tab “Table Status”.
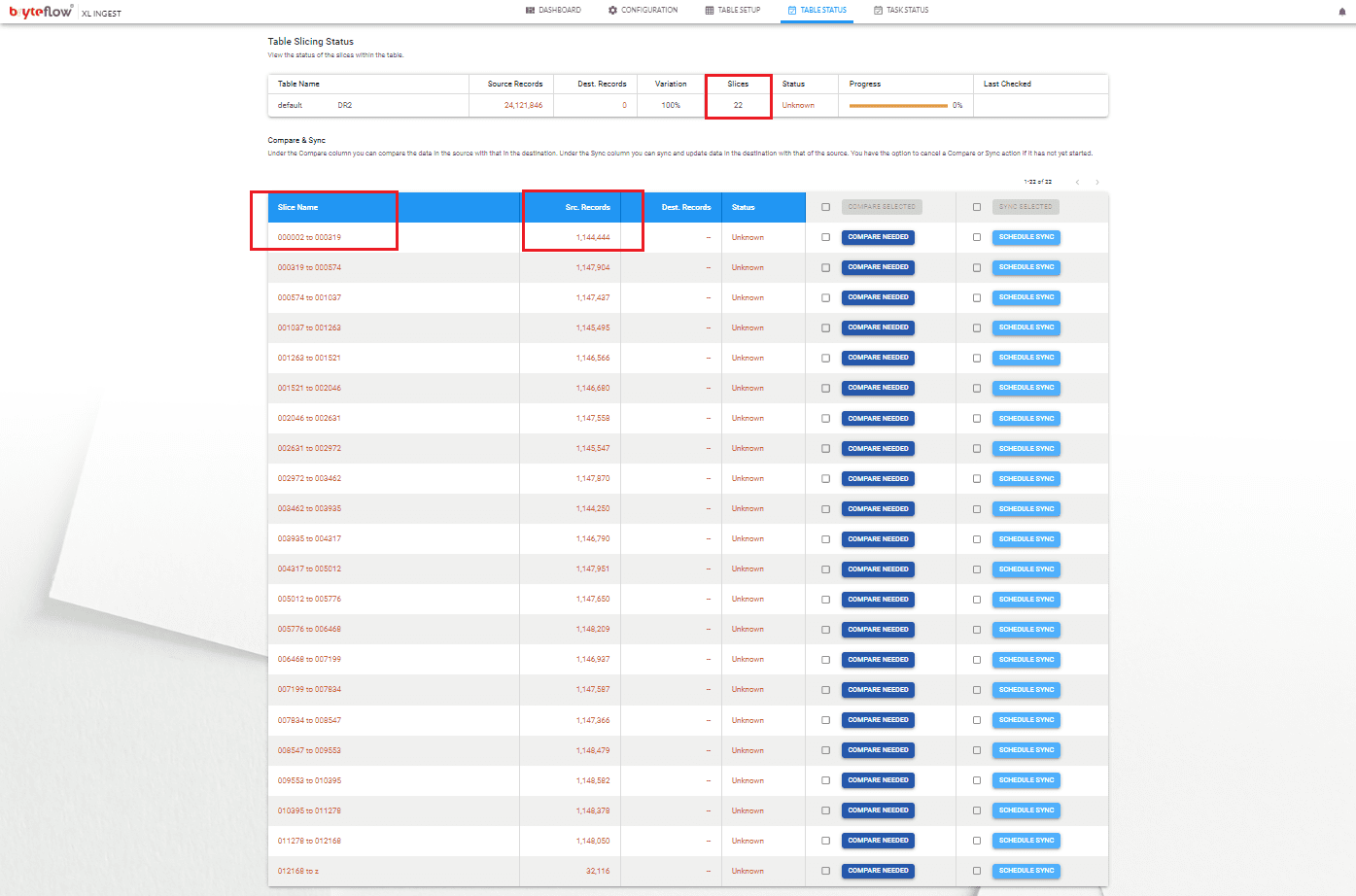
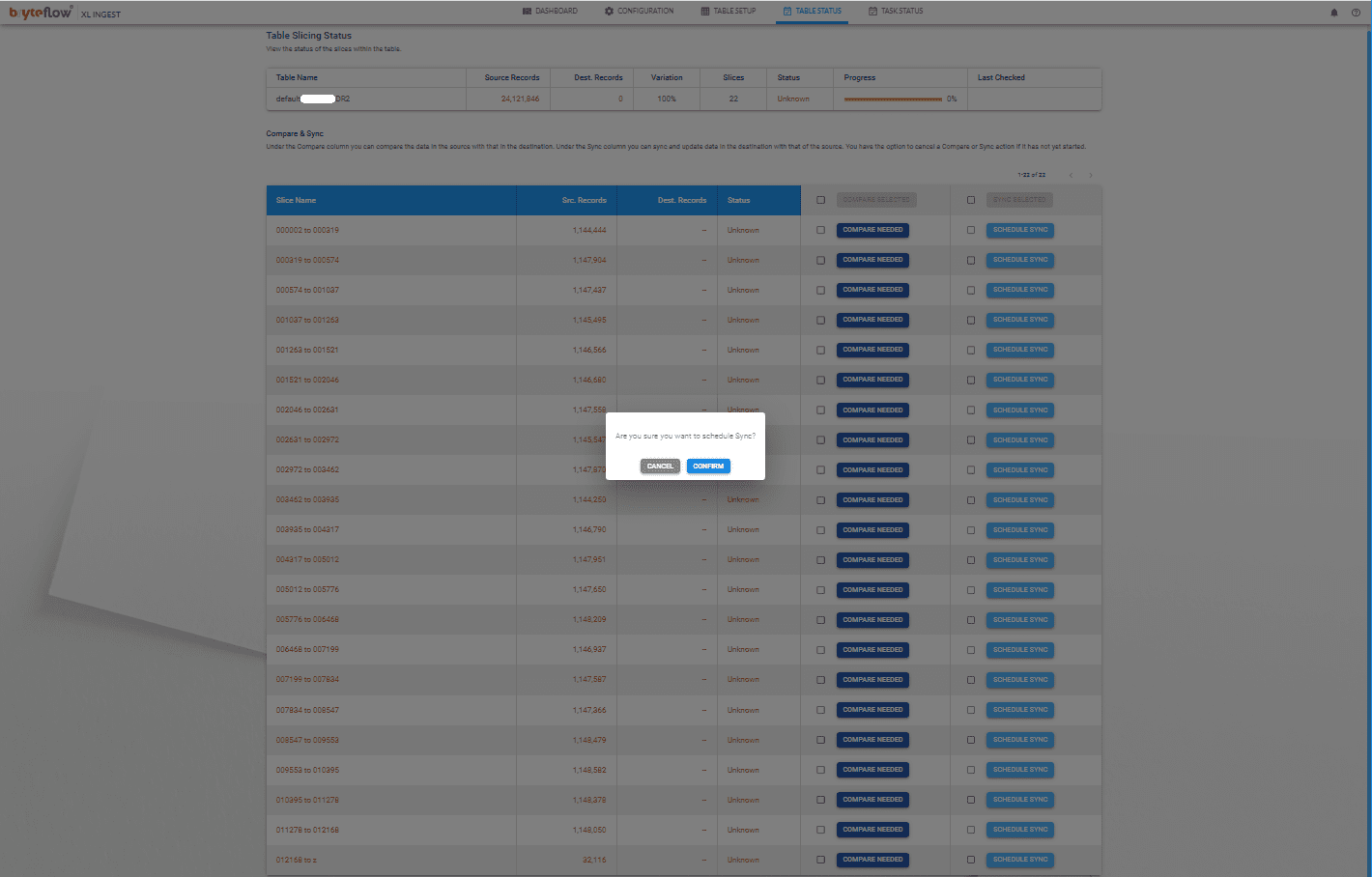
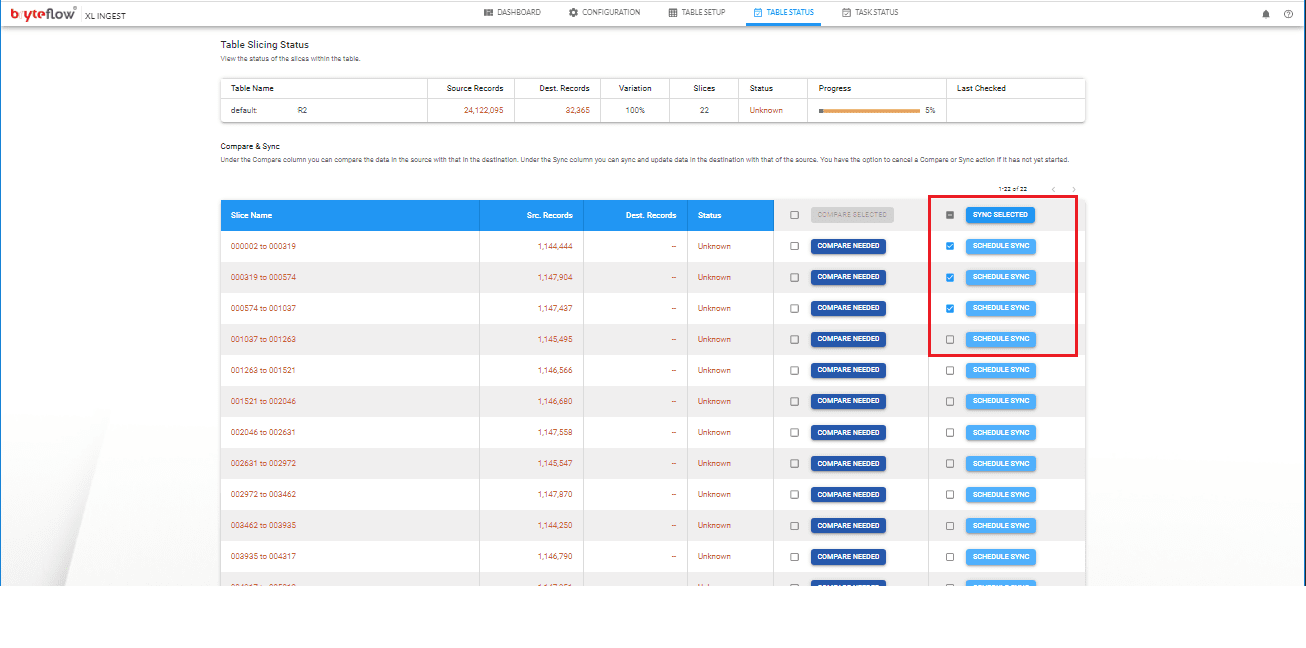
Step 5
Then select the number of slices that you want to load in parallel and hit “Sync selected” or select only one slice and click on “Schedule Sync”
Step 6
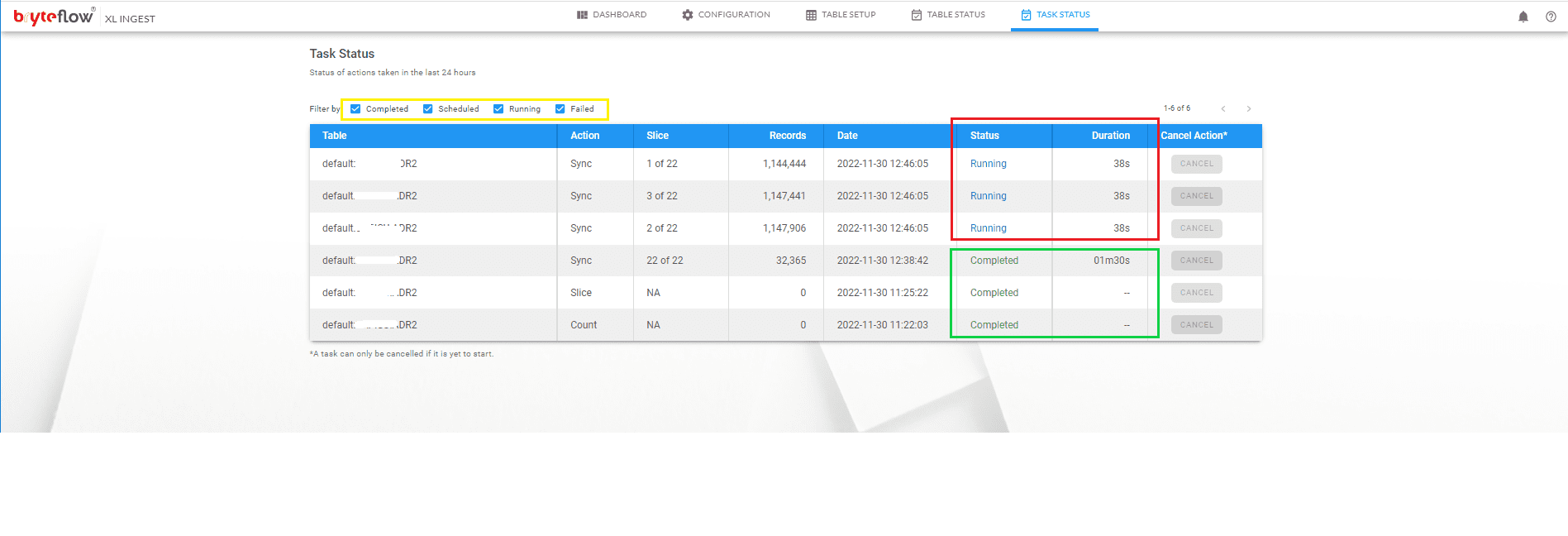
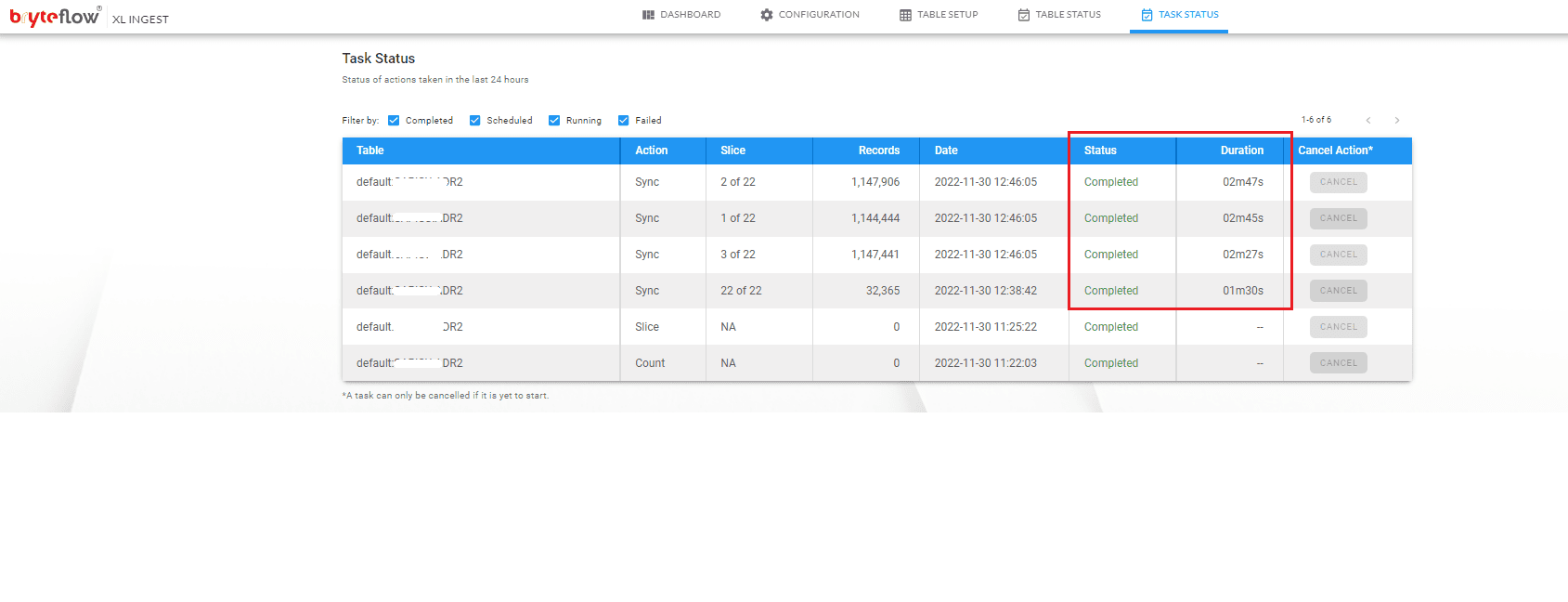
The progress of the load can be monitored under “Task Status”
Step 7
The overall performance can be monitored under the XL Ingest dashboard which gives the details of the number of tables scheduled to run, total number of records loaded so far, time taken to extract at source, time taken to load at the destination etc.
Besides a Demo, you can also opt for a Free Trial of BryteFlow



