
- What is Oracle Database?
- What is Oracle Replication?
- What does Oracle Replication do?
- The Oracle Replication System
- Oracle Replication: Synchronous Replication and Asynchronous Replication
- Real-time Oracle Replication with Change Data Capture
- Why Oracle CDC (Oracle Change Data Capture)?
- Oracle Change Data Capture: Synchronous CDC and Asynchronous CDC
- Steps to Perform Asynchronous Change Data Capture on Oracle DB
- Automated Oracle Replication Tool
- BryteFlow’s Oracle Replication Tool Highlights
What is Oracle Database?
Oracle is an RDBMS (Relational Database Management System) and is used across the world by organizations to manage their data. Oracle is incredibly versatile and supports all kinds of data models. The Oracle database is usually referred to just as Oracle. It has five editions namely Standard Edition, Enterprise Edition, Express Edition, and Personal Edition. It is a popular choice among organizations for managing data since it is scalable, secure and offers high performance. Users can use SQL to query and interact with the Oracle database, which makes it even more attractive. Learn about BryteFlow for Oracle Replication
What is Oracle Replication?
Oracle usage is increasingly prevalent, and organizations need a way to distribute, share and consolidate their data. Oracle Replication is the mechanism that makes it possible. Oracle Replication allows organizations to create, synch and distribute data over multiple locations, enable data sharing with users like partners or vendors, aggregate data from different offices, local and global. It can reduce analytics overhead with query offload, by splitting up online transaction processing (OLTP) and report generation onto different systems. Oracle to Azure Cloud Migration (Know 2 Easy Methods)
What does Oracle Replication do?
In a distributed environment, be it homogenous or heterogenous, Oracle Replication enables users access information when and where they need it. Oracle database replication creates synchronized, multiple copies of an Oracle database for purposes like business reporting, testing, backups for disaster recovery, and distributed data processing. Oracle replication software can provide real-time data so companies can improve the performance of important databases and applications, provide data availability across the organization and benefit from real-time analytics and reporting for crucial business insights. Oracle to SQL Server Migration: Reasons, Challenges and Tools
The Oracle Replication System
The Oracle Replication system includes basic components like Replication Objects, Replication Groups, and Replication Sites. Database Replication Made Easy – 6 Powerful Tools
Oracle Replication Objects
A distributed database system will have replication objects or database objects on multiple servers. Any changes or updates made to a replication object at one site will be applied to copies on other sites as well. Oracle Replication enables replication of these objects: Tables, Indexes, Views, Packages and Package Bodies, Procedures and Functions, Triggers, Sequences, Synonyms. Oracle CDC to Kafka with BryteFlow
Oracle Replication Groups
In the Oracle environment, replication is managed through Replication Groups. A Replication Group is just an aggregation of Replication Objects that are logically inter-related and are managed together in the process. Oracle to Oracle Replication
Oracle Replication Sites
A single Replication Group may exist at different Replication Sites. Replication environments can have two kinds of sites: Master sites and Snapshot sites and a replication site can even be both at the same time. A master site contains a copy of all replication objects in a replication group (master group) while snapshots at a snapshot site may contain all or just a subset of the table data. A snapshot may be refreshed at periodic intervals to synch with the master site. Snapshots can be grouped together to form a Refresh Group and they can all be refreshed together to make sure that the data of all the snapshots corelates to the same point in time. Oracle to Redshift Migration Made Easy (2 Methods)
Oracle Replication: Synchronous Replication and Asynchronous Replication
Database Replication functions in two broad modes -Synchronous Replication and Asynchronous Replication.
What is Synchronous Replication?
Synchronous Replication replicates data to the primary and secondary area concurrently. Hence data is identical and updated at both sites. There is very little chance of error and due to this it is perfect for disaster recovery purposes or if the project in question requires zero data loss. Synchronous Replication costs more than Asynchronous Replication. Connect Oracle to Databricks and Load Data the Easy Way
What is Asynchronous Replication?
Asynchronous Replication replicates data to primary and secondary areas but with Asynchronous Replication there is a slight delay when copying data from primary to secondary site. This method is called ‘Store and Forward’. Asynchronous Replication has data first written to the primary array and later committed for replication to a secondary source. The data can be copied at specified intervals to the target and this Asynchronous Replication can be done over long distances, unlike Synchronous Replication. AWS DMS Limitations for Oracle Replication
Real-time Oracle Replication with Change Data Capture
Oracle data is very often replicated to an external data warehouse. This enables data from Oracle to be integrated with data from other sources for data analytics. Oracle Replication mechanisms update data in the warehouse when changes happen at the Oracle source. This Oracle Change Data Capture mechanism enables real-time, continuous data sync between the Oracle source and data in the warehouse. Learn more about Oracle CDC
Why Oracle CDC (Oracle Change Data Capture)?
Oracle CDC is by far the most effective method of capturing and delivering changes from an Oracle database to a target destination. It is a feature in Oracle that identifies and captures every data change at the source and records all inserts, updates, and deletes. The Change Data can be used by applications or users to update data on the destination in the same sequence as it occurs. This method of Oracle Replication is low impact and sparing of source system resources. Also learn about SQL Server CDC
Oracle Change Data Capture: Synchronous CDC and Asynchronous CDC
Synchronous CDC
With Synchronous CDC, Oracle change data can be captured by implementing Triggers on the source database tables, it allows change data to be captured immediately, as each data manipulation language (DML) operation (INSERT, UPDATE, or DELETE) is made. Oracle to Snowflake: Everything You Need to Know
In this mode, the transaction is not closed in the DB until change data has not been captured, making it seem real-time with NO latency issues. The change tables are populated when DML operations on the source table are committed.
The synchronous mode does add additional overhead to the source database at capture time, but it can reduce costs by simplifying the extraction of change data. Kafka CDC and Oracle to Kafka CDC Methods
Asynchronous Change Data Capture
In this mode change data will be captured once the transaction has completed, which means it is not a part of the transaction. Change data will be captured with the help of redo logs. This mode of Change Data Capture is dependent on the level of supplemental logging enabled at the source database. Supplemental logging adds logging overhead at the source database, so it must be carefully balanced with the needs of the applications or individuals using Change Data Capture. Loading data from Oracle DB to Oracle platforms
There are three modes of Asynchronous Change Data Capture: Hot Log, Distributed Hot Log and Autolog.
a. Hot Log: – In this mode, change data is captured from the online redo log files at source . There is a small time lag between committing source tables transactions and the arrival of change data to change tables. Change tables in this mode must be present in the source database. Oracle vs Teradata (Migrate in 5 Easy Steps)
b. Distributed Hot Log:- In Distributed Hot Log mode, Source tables are in Source database and change tables are in the staging database. In this mode too change data is captured through online logs. Source and Staging databases can be on different platforms and can have different OS installed. Learn about Oracle to Databricks Replication
c. Auto Log:– In Auto Log mode change data is captured from a set of redo log files managed by Redo transport services. It controls the automatic transfer of redo log files from source database to staging database. In this mode, change data can be captured from online logs as well as from archive logs. These modes are called Asynchronous Autolog Online and Asynchronous Autolog Archive. Oracle to Postgres Migration
Publisher and Subscribers
A database administrator (DBA) who creates and maintains schema objects that make up the Change Data Capture system is usually the Publisher. The Publisher publishes change data to change tables from source tables. The multiple applications and individuals who want to access that change data are called Subscribers. Oracle to Azure Cloud Migration (Know 2 Easy Methods)
Steps to Perform Asynchronous Change Data Capture on Oracle DB
Step 1: Set Database to FORCE LOGGING Mode
The first step is to enable FORCE LOGGING mode on your database. Run the following query to achieve that.
ALTER DATABASE FORCE LOGGING;

Step 2: Enable Supplemental Logging
This is to enable the database to log in case of UPDATE statements.
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;

Step 3: Enable Logging for all Columns in the required Table
First, you would need to identify the columns that you need to capture changes from. If you choose to capture changes from all columns, you can run the following query.
ALTER TABLE DEMO_CUSTOMER ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;

Step 4: Prepare the Source Tables for Log Data Capture
BEGIN DBMS_CAPTURE_ADM.PREPARE_TABLE_INSTANTIATION(TABLE_NAME => ‘DEMO_CUSTOMER’); END;

Step 5: Create a Change Set
Note: Oracle does not support these packages from Oracle 12c onwards.
To create a change set, use the below command in Sql Plus command Line.
Create a Change set using DBMS_CDC_PUBLISH package
BEGIN
DBMS_CDC_PUBLISH.CREATE_CHANGE_SET(
change_set_name => 'DEMO_CUSTOMER',
description => 'DEMO_CDC',
change_source_name => 'HOTLOG_SOURCE',
stop_on_ddl => 'y',
begin_date => sysdate,
end_date => sysdate+100);
END;
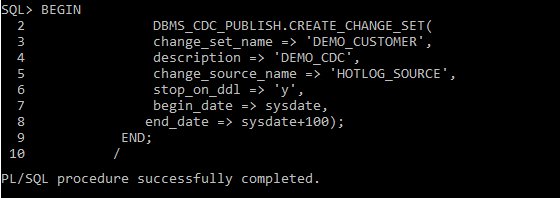
This change set will capture the changes starting from today and will stop capturing after 100 days.
HOTLOG_SOURCE is a predefined source defined by oracle for asynchronous change data capture.
Step 6: Create Change Table
Create a Change table that will contain changes to source tables. Here Source table is ‘Customer’
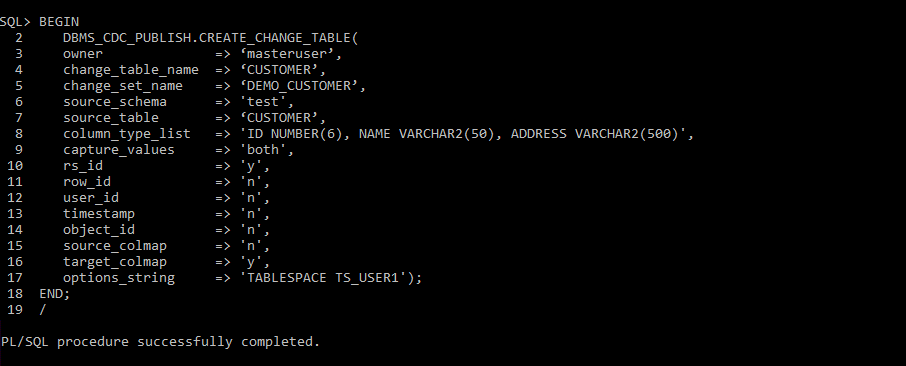
Step 7: Enable Change Set
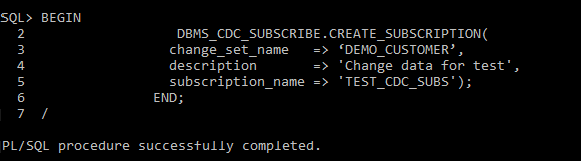
Step 8. Create a subscription which can access the change data in the Change tables :-
Step 9. Subscribe the subscriber to source table and columns in source table :-
SQL> BEGIN
DBMS_CDC_SUBSCRIBE.SUBSCRIBE(
subscription_name => 'TEST_CDC_SUBS',
source_schema => 'TEST',
source_table => 'CUSTOMER',
column_list => 'ID,NAME,ADDRESS',
subscriber_view => 'SUBS_VIEW');
END;
/
PL/SQL procedure successfully completed.
Step 10. Activate the subscription
SQL> BEGIN
DBMS_CDC_SUBSCRIBE.ACTIVATE_SUBSCRIPTION(
subscription_name => 'SUBS_TEST');
END;
/
PL/SQL procedure successfully completed.
Step 11. This PL/SQL block will get you the next set of change data. Whenever data changes in the source table and is captured in the Change table then this PL/SQL block will get you data in the subscription window.
SQL> BEGIN
DBMS_CDC_SUBSCRIBE.EXTEND_WINDOW(
subscription_name => 'SUBS_TEST');
END;
/
PL/SQL procedure successfully completed.
Step 12. Check that the Changes made to the source table reflects in subscription window:-
SQL> BEGIN
DBMS_CDC_SUBSCRIBE.EXTEND_WINDOW(
subscription_name => 'SUBS_TEST');
END;
/
PL/SQL procedure successfully completed.
SQL> select OPERATION$,to_char(COMMIT_TIMESTAMP$,’dd-mon-yyyy hh24:mi:ss’),ID,NAME from subs_view;
| OP TO_CHAR(COMMIT_TIMESTAMP$,’DD | ID NAME |
| I 28-aug-2013 10:56:30 | 1 ABC |
| I 28-aug-2013 10:56:30 | 2 XYZ |
| I 28-aug-2013 10:56:30 | 3 LMN |
Whatever changes we have made to the source table is reflected in the change table and listed in the subscription window.
If we insert data in the Source table, all records details will be reflected in Change tables. If we update, then both data before update and data after update will be recorded in Change tables and reflected in the subscription window.
Automated Oracle Replication Tool
Why bother with Oracle replication the long way when there is a much easier automated Oracle Replication tool on hand? BryteFlow provides automated Change Data Capture for Oracle Replication, no coding to be done for any process. How BryteFlow Data Replication Software Works
BryteFlow’s Oracle Replication Tool Highlights
- Faster replication than Oracle GoldenGate, Qlik Replicate and HVR Connect Oracle to Databricks and Load Data the Easy Way
- Oracle Replication with Change Data Capture – zero impact on source GoldenGate CDC and an easier alternative
- High performance – multi threaded configurable data extraction and loading What to look for in a Real-Time Data Replication Tool
- Zero coding – for data extraction, merging, data mapping, masking or type 2 history Oracle to Postgres Migration
- Analytics-ready data assets on Amazon S3, Amazon Redshift, Snowflake, Azure Synapse, ADLS Gen2, SQL Server, BigQuery, Postgres, Teradata, SingleStore and Kafka
- Automated Data Reconciliation with checksums Source to Target Mapping Guide (What, Why, How)
- Data Preparation for Machine Learning on Amazon S3 Oracle to Redshift Migration Made Easy (2 Methods)
- BryteFlow provides replication support for all Oracle versions, including Oracle 12c, 19c, 21c and future releases for the long term.



