Google BigQuery Connections
Load data to BigQuery in Real-time without Coding
Google BigQuery Integration is real-time and automated with BryteFlow
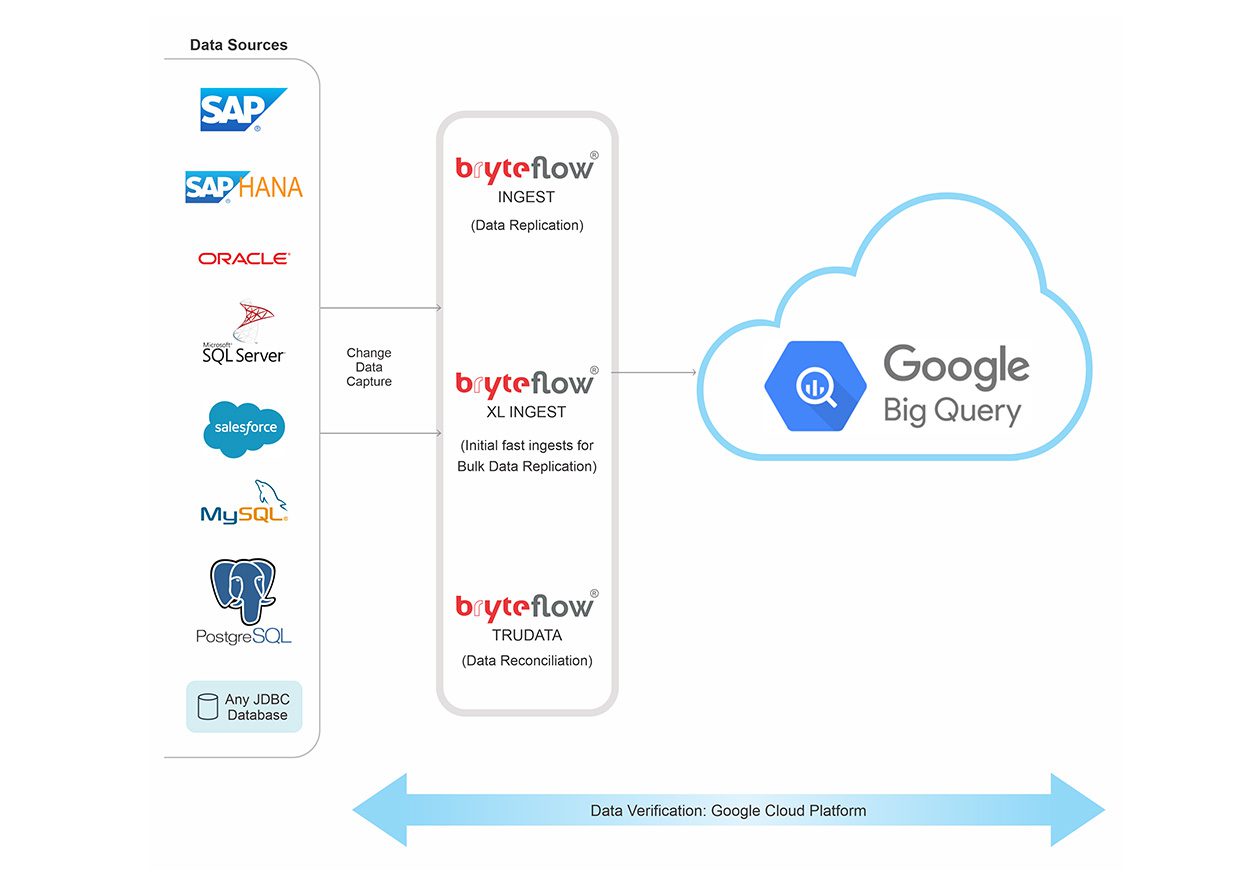
Load data to BigQuery from multiple sources like Oracle, SAP and SQL Server in real-time automatically. BryteFlow moves your data to BigQuery using log-based CDC (Change Data Capture) and syncs data continuousy with changes at source including inserts, updates and deletes. BryteFlow replication supports moving of large data volumes to BigQuery in minutes with multi-threaded parallel loading and automated partitioning and compression for the initial full refresh, followed by incremental loading using CDC to BigQuery. There is no coding for any process including SCD Type2, masking, DDL etc. and data is ready to use on Google BigQuery for Analytics, Machine Learning etc. 6 reasons to automate your data pipeline
BigQuery Integration and Migration Highlights
- BryteFlow’s BigQuery CDC has no impact on source systems Successful Data Ingestion (What You Need to Know)
- Multi-threaded configurable data extraction and loading to BigQuery for high performance
- BigQuery loading best practices baked into the replication tool Data Migration 101 (Process, Strategies and Tools)
- BigQuery migration with zero coding for processes including extraction, merging, masking or type 2 history
- Automated Data Reconciliation with row counts and columns checksum
- Support for petabytes of BigQuery data ingestion both initial and incremental
- Replication to BigQuery in minutes with high throughput – approx. 1,000,000 rows in 30 seconds
- High availability and resilience with Automated Catchup
Suggested Reading:
SAP to Big Query
Oracle to BigQuery
SQL Server to BigQuery
Loading Data to BigQuery?
Reasons to use BryteFlow
BryteFlow works with BigQuery to provide automated, fast data integration, in real-time.
Here’s what you can do with BryteFlow on your Google BigQuery Data Warehouse. Get a Free Trial of BryteFlow





Change Data Capture your data to Google BigQuery with history of every transaction
BryteFlow uses log-based CDC to move data to BigQuery in real-time, with history intact. BryteFlow Ingest leverages the columnar BigQuery database by capturing only the deltas, syncing data in the BigQuery data warehouse continuously with source. Change Data Capture Types and Advantages of CDC
Data is ready to use on BigQuery for Analytics or Data Science purposes
BryteFlow Ingest on BigQuery provides a range of automated data conversions out-of-the-box including Typecasting and GUID data type conversion to ensure that your data is ready for analytical consumption or for Machine Learning purposes.
Load data to BigQuery at top speed and high throughput
BryteFlow Ingest uses fast log-based CDC to replicate your data to the BigQuery data warehouse. Data is loaded to BigQuery in manageable chunks using automated compression and smart partitioning at an approx. speed of 1,000,000 rows in 30 seconds. ELT in Data Warehouse
Automated DDL and performance tuning with best Google BigQuery best practices baked in
BryteFlow helps you tune performance on Google BigQuery by automating DDL (Data Definition Language) which is a subset of SQL. Other processes like masking, extraction, SCD Type2 history too are completely automated.
Load data to BigQuery and automatically reconcile it
You are assured of getting high quality, reconciled data always with BryteFlow TruData, our data reconciliation tool. BryteFlow TruData continually reconciles data in the BigQuery data warehouse with source. It can automatically serve up flexible comparisons and match datasets of source and destination.
Initial full refreshes to BigQuery are fast with BryteFlow XL Ingest
If you have huge petabytes of data to load to BigQuery, BryteFlow XL Ingest is recommended for the initial full ingest in case of very large datasets. It uses smart partitioning, compression and parallel sync with multi-threaded loading to transfer bulk data fast. Data Migration 101 (Process, Strategies and Tools)
Dashboard to monitor data ingestion and data transformation instances on the BigQuery warehouse
Stay on top of your data ingestion statuses with the BryteFlow ControlRoom. It displays the status of BryteFlow replication instances, displaying latency, operation start time, operation end time, volume of data ingested, transformation jobs etc.
Get built-in resiliency for BigQuery CDC Replication
BryteFlow has an automatic network catch-up mode. It just resumes where it left off in case of power outages or system shutdowns when normal conditions are restored, so the BigQuery CDC process continues without a hitch.
Google BigQuery Advantages




What is Google BigQuery?
BigQuery is a scalable, serverless enterprise data warehouse owned by Google. It helps organizations store, manage and query their data at scale. BigQuery is immensely powerful and can process massive datasets in minutes.
Machine Learning is built into BigQuery
BigQuery’s processing power comes from the Google infrastructure and it’s capability to handle huge datasets make it ideal for Machine Learning. BigQuery has a feature called BigQuery ML built into the system that enables users to create, run and test Machine Learning Models using standard SQL queries.
Storage and Compute are separated on BigQuery
BigQuery’s serverless architecture separates storage and compute and enables independent scaling of both on demand. This provides flexibility and cost optimization since expensive compute resources don’t need to be run all the time but only when required by users.
BigQuery supports faster Analytics with connectors to ETL and BI tools
BigQuery enables organizations to set up data warehouses very fast with built-in connectors to popular ETL tools. BigQuery also has native support for BI platforms like Looker and Tableau, so organizations that already use these tools can start creating dashboards and reports right away.
BigQuery has no infrastructure management hassles
Users do not need to manage any infrastructure at their end. Updates are delivered automatically. Maintenance, patching and feature upgrades are all handled by Google, freeing up users to concentrate on more valuable tasks.
Strong Security and Governance
BigQuery has a service level agreement (SLA) guarantee for 99.9% uptime. BigQuery as a cloud-based data warehouse service has very strong governance and security measures in place including data integrity protection, built-in disaster recovery with automatic data replication, and high availability in case of unforeseen downtime and intentional or unintentional breach of data. All this at no extra charge.
BigQuery has infinite scalability
Since BigQuery is cloud-based and has a serverless architecture, it is almost infinitely scalable, enabling users to scale up processing power for analytics automatically if required. This feature allows users to discover and concentrate on important insights rather than being restricted by compute bottlenecks.
Process external data through BigQuery without duplicating it
Big Query’s logical warehousing feature enables users to process external data sources through BigQuery. This can be done in the cloud storage of BigQuery without needing to duplicate the data . Transactional databases and spreadsheets can also be processed by BigQuery in Drive.