BryteFlow for PostgreSQL CDC
PostgreSQL Data Migrations
PostgreSQL to Snowflake
PostgreSQL to Oracle
PostgreSQL to SQL Server
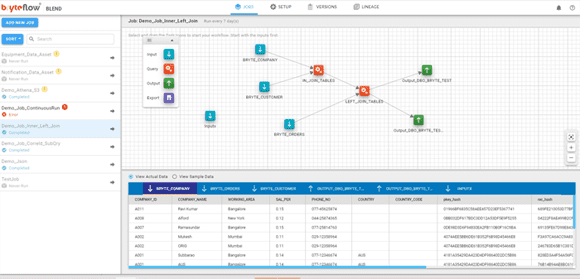
BryteFlow Blend, our data transformation tool
PostgreSQL Replication: Guaranteed availability, super-fast replication across platforms and NO coding
Get PostgreSQL Replication across multiple platforms using Change Data Capture (CDC). Easy to set up, completely automated and extremely fast, our PostgreSQL replication does not need Admin access or access to logs. With BryteFlow’s log-based CDC technology you can continuously load and merge changes in data to the destination with no slowing down of source systems.
Postgres CDC (6 Easy Methods to Capture Data Changes)
Solution Highlights:
- PostgreSQL replication with Change Data Capture has zero impact on source
- High performance – parallel threaded initial sync and delta sync for bulk PostgreSQL migration Postgres to Snowflake : 2 Easy Methods of Migration
- Zero coding – Automated table creation using best practices on destination with data upserted or kept with SCD type 2 history How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
- Analytics ready data assets on S3, Redshift, Snowflake, Azure Synapse and SQL Server data lakes ELT in Data Warehouse
- Support for terabytes of PostgreSQL data, both initial and incremental Postgres Replication Fundamentals
- Automated Data reconciliation with column checksums
- Data Preparation for Machine Learning on Amazon S3 About Aurora Postgres Replication
- High Availability and Throughput Debezium CDC Explained
View PostgreSQL to Snowflake Replication
Oracle to Postgres Migration (The Whys and Hows)Postgres CDC (6 Easy Methods to Capture Data Changes)
SQL Server vs Postgres – A Step-by-Step Migration Journey
Key Features

- S3 file merges
- Enterprise-level security
- High Throughput
- Time series your data
- Supports all versions of PostgreSQL
- Self-recovery from connection dropouts
- Smart catch-up features in case of down-time
- Parallel log mining for PostgreSQL
- Transaction Log Replication
- Change Data Capture
Unlock your PostgreSQL Data with a BryteFlow enabled Data Lake.
With BryteFlow, you can extract data from a full range of PostgreSQL Modules with just a few clicks. The software provides a range of data conversions out of the box including Typecasting and GUID data type conversion to ensure that your PostgreSQL data is ready for analytical consumption. Further, BryteFlow enables configuration of custom business logic to consolidate PostgreSQL data from multiple applications or modules into AI and Machine Learning ready inputs. Automating your Data Pipeline

Zero impact on PostgreSQL source
BryteFlow eliminates the need for complex application procedures or queries to extract PostgreSQL data. It extracts data from the PostgreSQL application’s database level logs and does not require any additional agents or software to be installed in your PostgreSQL environment.
CDC to PostgreSQL

Remodels data to make it consumable
BryteFlow for PostgreSQL can replicate complex data and data modules by remodeling the data into analytical data formats. You can even use the data outside of a PostgreSQL environment.
Postgres CDC (6 Easy Methods to Capture Data Changes)

Near real-time replication of data
With frequent incremental extractions, compression and parallel streams, BryteFlow ensures your data is constantly kept up-to-date and available to enable real-time analytics. Postgres to Snowflake : 2 Easy Methods of Migration

SQL workbench to blend data sources
An easy to use drag-and-drop workbench delivers a codeless development environment to build complex SQL jobs and dependencies across PostgreSQL and non-PostgreSQL data.
Oracle to Postgres Migration (The Whys and Hows)

Dashboard for monitoring
BryteFlow for PostgreSQL displays various dashboards and statistics so you can stay informed on the extraction process as well as reconciling differences between source and target data.
How to Make PostgreSQL CDC to Kafka Easy (2 Methods)

Automatic catch-up from network dropout
Pick up where you left off – automatically. In the event of a system outage or lost connectivity, BryteFlow for PostgreSQL features an automated catch-up mode so you don’t have to check or start afresh.
Debezium CDC Explained and a Great Alternative CDC Tool

Masking & Tokenization
BryteFlow for PostgreSQL provides enterprise grade security to mask, tokenize or exclude sensitive data from the data extraction processes.
SQL Server vs Postgres – A Step-by-Step Migration Journey

Time-scale history
BryteFlow for PostgreSQL provides out-of-the-box options to maintain the full history of every transaction from PostgreSQL with options for automated data archiving. You can go back and retrieve data from any point on the timeline.
Aurora Postgres and How to Setup Up Logical Replication

Ronnel Magdaluyo
Business Engagement Manager
Bingo Industries
With BryteFlow we get to work with the most current data almost immediately.
“Using Bryteflow on Amazon S3 has been a real game changer for us. We have been able to achieve a Data Warehouse and an Analytics solution in a short amount of time. With Bryteflow we get to work with the most current data almost immediately. Our data extraction and transformation development time has been shortened. Unlike other tools that takes a considerable amount of time to develop an end to end process, we have achieved this at great speeds. The tool in itself is incredibly easy to use – took me just half a day to learn the core functionalities! And best of all – with Amazon S3, our data storage cost is insignificant, so we actually store everything!”
BINGO INDUSTRIES
Enabling run-time reports to be generated on the fly by business users
Bingo Industries is an Australian fully integrated recycling and resource management company that provides solutions across the entire waste management supply chain. They faced a number of challenges like slow performing reports, deadlocks during batch runs, data that did not lend itself to adhoc reporting and long development times for new reports.
BryteFlow helped Bingo Industries create a Data Warehouse and Analytics solution fast
This gave Bingo Industries access to their most current data almost immediately. The solution provided near real-time data ingestion and the capability to build data models on S3 with BryteFlow Blend. Reports are available within 1 hour latency and data is readily available for run-time reports to be generated on the fly by business users directly. Data extraction and transformation development time has also been shortened.