Databricks Connections
SQL Server Databricks CDC in real-time with BryteFlow
SQL Server Databricks Automated ETL Pipeline
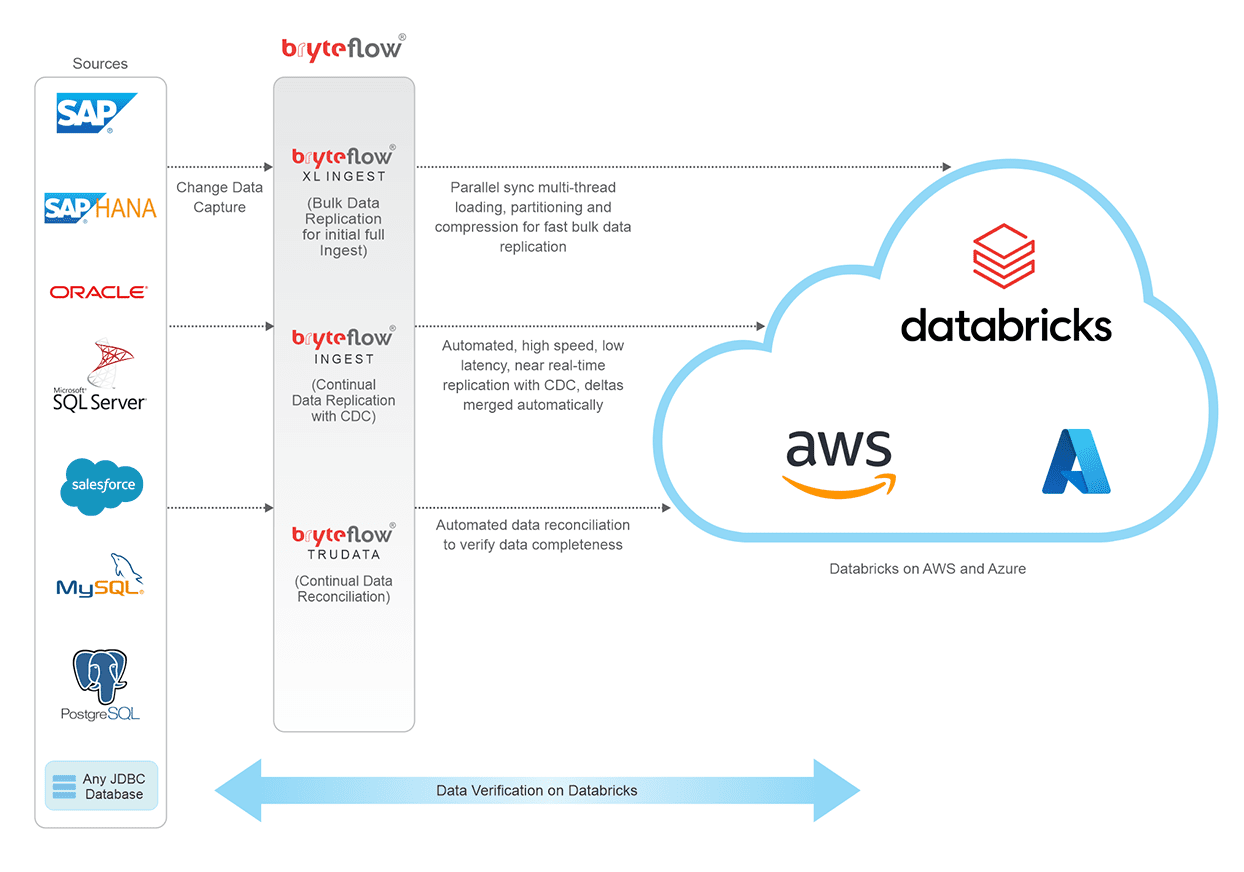
Need to load SQL Server data to Databricks on AWS or Azure for Machine Learning or Analytics? BryteFlow helps you implement SQL Server Databricks integration with an automated ETL pipeline (no coding) in real-time. It carries out SQL Server Databricks Replication using CDC or Change Tracking to sync data with changes at source. It loads the first full refresh with multi-threaded parallel loading, automated partioning and compression, and delivers deltas with automated Change Data Capture. It provides time-versioned data along with SCD Type2 history. BryteFlow transforms and provides ready-to-use data in the Databricks Lakehouse for Machine Learning and Analytics. SQL Server to Databricks (Easy Migration Method)
SQL Server Databricks CDC Options with BryteFlow
- Using SQL Server Change Tracking for Real-time replication
- Using SQL Server Change Data Capture for Real-time replication
- Using timestamps to identify changed records
- Log shipping for real-time SQL Server Change Data Capture
How BryteFlow makes the Databricks SQL Server Connect easier
- BryteFlow replicates data in real-time to the destination with zero impact, using SQL Server Change Data Capture or SQL Server Change Tracking or a combination of both.
- Parallel multi-threaded loading and automated partitioning and compression for first full refresh.
- Support for high volumes of SQL Server to Databricks ingestion, both initial and incremental.
- Databricks replication best practices (AWS & Azure) built-in. SQL Server vs PostgresSQL
- Automated Process for SQL Server to Databricks ETL. Databricks Lakehouse and Delta Lake (A Dynamic Duo!)
- Point-and-click user friendly interface makes it easy to migrate data from SQL Server to Databricks
- Availability, very low latency and high throughput – approx. 1,000,000 rows in 30 seconds
- BryteFlow supports real-time data replication from all versions of SQL Server. More on SQL Server CDC
- BryteFlow supports on-premise and cloud hosted SQL Server sources. (eg AWS RDS, Azure SQL DB, Cloud SQL etc.) and can be installed on-premise or on the cloud. SQL Server Data Integration
- BryteFlow enables out-of-the-box data conversions and provides ready-for-use data in Databricks. Databricks Lakehouse and Delta Lake (A Dynamic Duo!)
Suggested Reading:
SQL Server Change Data Capture (CDC) for real-time SQL Server Replication
SQL Server Change Tracking for real-time SQL Server Replication
BryteFlow for SQL Server Replication
No-Code SQL Server Databricks ETL with CDC

SQL Server to Databricks replication has very high throughput and loads very large datasets with ease
Load huge volumes of SQL Server data to Databricks with BryteFlow. BryteFlow XL Ingest manages the initial refresh of large SQL Server datasets to Databricks at super-fast speeds of approx. 1,000,000 rows in 30 seconds. BryteFlow uses parallel multi-threaded loading, automated partitioning and compression to rapidly load data.
Databricks Lakehouse and Delta Lake (A Dynamic Duo!)

How much time will your Database Administrators need to spend on managing the replication?
Using BryteFlow saves your DBA’s time. He or she will not need to manage backups and dependencies until the changes have been processed or configure full backups etc. which can add to the Total Cost of Ownership (TCO) of the solution. They won’t need to assign sysadmin privileges to users either.
With BryteFlow, it is “set and forget”. There is no involvement from the DBAs required on a continual basis, hence the TCO is much lower. Further, you do not need sysadmin privileges for the replication user.
BryteFlow for SQL Server

SQL Server to Databricks migration is completely automated
With BryteFlow’s automated ETL pipeline to connect SQL Server with Databricks, there is no coding involved in any process. With BryteFlow you get full automation. BryteFlow is a self-service ETL tool, with a user-friendly point-and – click interface that any business user can use easily.
SQL Server to Databricks (Easy Migration Method)

SQL Server ingestion to Databricks is monitored for data completeness from beginning to end
BryteFlow provides end-to-end monitoring of data and makes it a point to track your data. For e.g. if you are replicating SQL Server data to Databricks at 3pm on Monday Sep. 5, 2022, all the changes at source till that point will be replicated to the Databricks database, latest change last so the data will be replicated with all inserts, deletes and updates present at source.
Connect Oracle to Databricks and Load Data the Easy Way

Databricks Data maintains Referential Integrity
With BryteFlow you can maintain the referential integrity of your data when replicating data from SQL Server to Databricks. This means that when there are changes in the SQL Server source and when those changes are replicated to the destination (Databricks AWS & Databricks Azure) you will know exactly what changed- the date, the time and the values that changed at the columnar level.
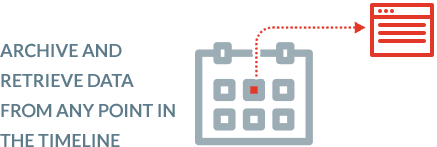
Archive data while preserving SCD Type 2 history
BryteFlow provides time-stamped data and the versioning feature allows you to access data from any point on the timeline. This versioning feature is integral to historical and predictive trend analysis.
About BryteFlow Ingest

Automatic catch-up from network dropout
BryteFlow has built-in resiliency. In case of a power outage or network failure you will not need to start the SQL Server to Databricks replication process over again. You can simply pick up where you left off – automatically.
Connect Oracle to Databricks and Load Data the Easy Way
About Microsoft SQL Server
Microsoft SQL Server is a software that is a relational database management system owned by Microsoft. It’s primary objective is to store data and then retrieve it when other applications request it. It supports a huge range of applications including transaction processing, analytics and business intelligence. The SQL Server is a database server that implements SQL (Structured Query Language) and there are many versions of SQL Server, engineered for different workloads and demands.
About Databricks
Databricks is a unified, cloud-based platform that handles multiple data objectives ranging from data science, machine learning and analytics to data engineering , reporting and BI. The Databricks Lakehouse simplifies data access since a single system can handle both- affordable data storage (like a data lake) and analytical capabilities (like a data warehouse). Databricks can be implemented on Cloud platforms like AWS and Azure and is immensely scalable and fast. It also enables collaboration between users.