BryteFlow Ingest & XL Ingest for data replication
PRODUCTS
BryteFlow Blend
BryteFlow TruData
BryteFlow ControlRoom
SOLUTIONS
BryteFlow for SAP
BryteFlow for SQL Server
BryteFlow for Oracle
BryteFlow for PostgreSQL
BryteFlow for MySQL
CDC to Amazon S3
CDC to Amazon Redshift
CDC to Snowflake
CDC to Azure Synapse
CDC to ADLS Gen 2
CDC to Apache Kafka
CDC to Google BigQuery
CDC to Databricks
CDC to PostgreSQL
CDC to Teradata
CDC to SingleStore
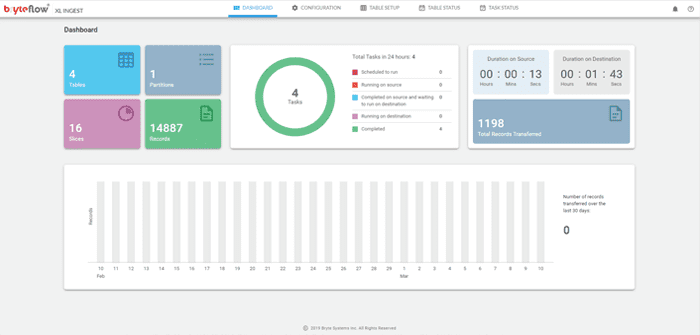
XL Ingest: Partitioning for very heavy datasets
Ingest data from multiple sources in real-time without writing a single line of code.
Getting data into a big data environment is easy when you have BryteFlow on your side. BryteFlow Ingest uses proprietary technology to help you move your data efficiently, securely, with minimal impact on your operational source systems to the destination. BryteFlow can replicate huge volumes of data from multiple sources in real-time – it has the highest throughput in the market for Oracle sources. It also helps you move your historical data or perform an initial sync of the data in the fastest way possible. BryteFlow Ingest uses an easy-to-use point and click interface to set up real-time database replication to your destination with high parallelism for the best performance. ELT to the Data Warehouse
Key Highlights:
- Replicate data and access it in almost real-time – faster time to value.
- Multi-threaded log based change data capture with high throughput.
- Multi-threaded parallel historical or initial sync with high performance.
- Easy to use point and click interface for data replication. Data Migration 101
- Save time with completely codeless and automated data ingestion.
- Automated DDL creation on the destination with best practices for performance
- Data is time-stamped, and incremental changes are merged so data is always current and reconciled. GoldenGate CDC and a better alternative
- Data replication tool provides high availability out-of-the-box.
See how BryteFlow works
Cloud Migration (Challenges, Benefits and Strategies)
Successful Data Ingestion (What You Need to Know)
BryteFlow Ingest, the data replication tool that ups performance and lowers data cost
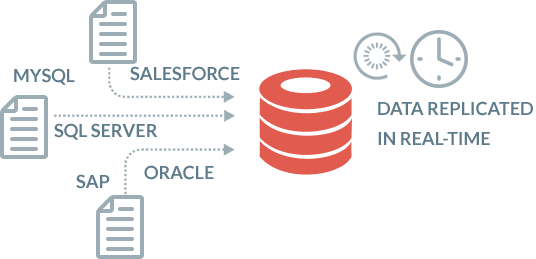
Easy, fast access to data with automated data ingestion from multiple sources.
BryteFlow Ingest replicates data in real-time from hundreds of sources. It has an easy- to-use point and click interface that you don’t need a developer to operate. You can access, merge and remodel data through the user-friendly interface. No coding. No waiting! Your data is ready to use for whatever purpose you want. Unlike other data platforms your data is verified and reconciled so you can trust its accuracy completely.
GoldenGate CDC and an easier alternative
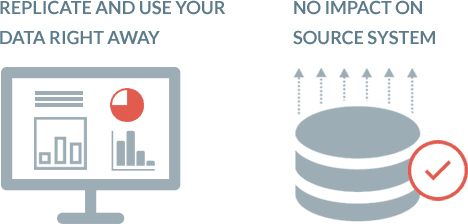
Start using your data immediately with real-time replication of your source in the data lake.
BryteFlow Ingest replicates your data in real-time at your data warehouse or data lake. It’s smart behind the scenes technology ensures you can start using your data right away and derive business value from it. To ensure important business systems are not impacted, BryteFlow Ingest uses log based change data capture (for databases) and streaming APIs (for applications) along with Zero footprint architecture.

Efficiently manage transactional data and sync changes continuously.
A world-first feature, BryteFlow Ingest is designed to efficiently manage transactional data in your data lake or data warehouse. It creates large numbers of different files for new record inserts, updates and deletes. BryteFlow’s optimized in-memory engine continuously merges new change files with existing data so your data stays always current. And this is verified and reconciled continuously at the frequency that you configure by BryteFlow TruData, our automated data reconciliation tool.

Prepares data for analytical, ML and AI consumption.
BryteFlow Ingest provides a range of data conversions out of the box including Typecasting and GUID data type conversion to ensure that your data is ready for analytical consumption. Further, BryteFlow enables configuration of custom business logic to collect data from multiple applications or modules into AI and Machine Learning ready inputs.
Successful Data Ingestion (What You Need to Know)
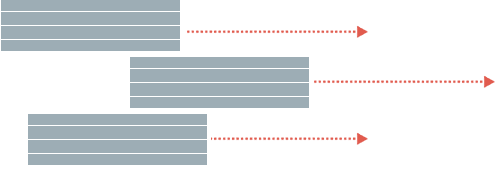
Smart Partitioning means you can run queries super-fast.
BryteFlow Ingest structures data in smart partitions so that you can run queries very fast and your system never slows down even with many other users running queries at the same time. It eliminates heavy batch processing, so your users can access current data, even from heavy loaded EDWs or Transactional Systems.
GoldenGate CDC and a better alternative
Data can be retrieved at any point in the timeline.
Since all data is saved as time series data, point in time analytics becomes easy. BryteFlow Ingest provides out-of-the-box options to maintain the full history of every transaction with options for automated data archiving. You can go back and retrieve data from any point on the timeline. This versioning feature is invaluable for historical and predictive trend analysis.
Source to Target Mapping Guide (What, Why, How)

Air tight security with encryption and masking.
BryteFlow Ingest encrypts the data at rest and in transit. It uses SSL to connect to data warehouses and databases.
How to Manage Data Quality (The Case for DQM)

Flexibility and infinite scalability.
Install BryteFlow Ingest on-premises behind your firewall, or use cloud infrastructure. Get the benefit of near-infinite scaling when required and eliminate user workload conflict by using serverless architectures and sharing nothing processing.
Cloud Migration (Challenges, Benefits and Strategies)

Automatic catch-up from network dropout.
No need to panic if your high volume data ingest operation is interrupted by a power outage or a similar situation. You can simply pick up where you left off – automatically. In the event of a system outage or lost connectivity, BryteFlow Ingest features an automated catch-up mode so you don’t have to check or start afresh.
BryteFlow XL Ingest for data replication of very large datasets
If you have large volumes of data to replicate (typically over 50 GB), we recommend an initial full ingest with BryteFlow XL Ingest. This data replication tool gets across huge datasets in minutes. It uses smart partitioning technology to partition the data and parallel sync functionality to load data in parallel threads. After the initial full ingest, BryteFlow Ingest handles subsequent data replication. Get a Free Trial

Ingests very large tables efficiently.

Reduces load on your source when ingesting very large datasets.

Smart partitioning and multi-thread parallel loading for fast data ingestion
