
This blog explores Change Data Capture (CDC) in Postgres, highlighting six primary methods to implement it: Triggers, Queries (or Timestamp column), Logical Replication, Transaction Logs, Table Differencing and our automated CDC tool Bryteflow. The blog looks at the significance of CDC in tracking and transmitting source database changes to the target, while also acknowledging the pros and cons of each method. It also shows how to set up some of the Postgres CDC methods using an IDE.
Quick Links
- Postgres CDC – why do you need it?
- About the PostgreSQL Database
- What is Change Data Capture in Postgres?
- 6 Different Methods to Implement Postgres CDC
- Bryteflow, a Tool for Real-Time, No-Code Postgres CDC
Postgres CDC – why do you need it?
PostgreSQL is a versatile and powerful relational database. It is open-source and is widely used across the world for OLTP (Online Transaction Processing) transactions including online shopping, banking, order entry, sales, service requests etc. It also handles analytics use cases. Usually, organizations will have a relational database like Postgres to deal with transactional workloads and a separate data warehouse where the data can be subjected to analytics and consolidated for reporting purposes. This means the huge volumes of data pouring into the Postgres DBs need to be delivered to the data repository along with data changes as they happen. Postgres to Oracle with BryteFlow
Modern enterprises need Postgres Change Data Capture
Connecting PostgreSQL to other data stores often involves using data pipelines that rely on time-based batch processing (think of hourly or daily batch sync), so it is a challenge to obtain data for time-critical reporting. For modern enterprises that routinely deal with huge petabytes of data, the batch processing approach can prove problematic, impact source systems and lead to errors and inaccurate results. It may fail to capture up-to-date data, causing synchronization issues that hinder accurate data-driven decision making. This is where Postgres CDC can help – to sync data between databases either continually, or at prescribed intervals. Change Data Capture (CDC) is a modern approach that can be applied in the Postgres database for achieving continuous, accurate and often real-time data sync. Postgres to SQL Server with BryteFlow
About the PostgreSQL Database
PostgreSQL is a popular open-source relational database known for its versatility and advanced features. It serves as both, a reliable transactional database and also a data warehouse for analytics. It adheres to SQL standards and offers extensibility through various tools such as pgAdmin. Its long history and strong community support make it a trusted choice for data management, reliability, data integrity, and user-friendliness across various applications. Postgres to Snowflake with BryteFlow
PostgreSQL is commonly used for the following purposes:
- PostgreSQL is used as a transactional database by large corporations and startups to support their Web applications, solutions, and products. Compare SQL Server vs Postgres
- Postgres has powerful SQL querying capabilities and can function as a cost-effective data warehouse. It is compatible with many BI tools and can be used for data analytics, data mining and business intelligence objectives. Migrating Oracle to PostgreSQL
- It also supports a geospatial database that is used for geographic information systems (GIS) and location-based services via the PostGIS extension found on PostgreSQL. Postgres to Snowflake : 2 Easy Methods of Migration
- Postgres can be run as a back-end database in the LAPP stack to power dynamic websites and web applications. LAPP stack includes Linux, Apache, PostgreSQL, and PHP (Python and Perl). Aurora Postgres and How to Setup Up Logical Replication
- The Foreign Data Wrappers and JSON of Postgres enable it to connect to other data stores (including NoSQL) and act as a federated hub for polyglot database systems. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
What is Change Data Capture in Postgres?
Change Data Capture (CDC) is a method used in Postgres databases (and others) to keep track of changes in data and its structure. It identifies, captures, and delivers the changes in data at source to target databases and applications, enabling organizations to use the changed data. In this way, Postgres CDC enables fast and efficient data transfers to data warehouses, where the information can be analyzed. Essentially, CDC in Postgres ensures that multiple databases stay updated and synced with changes in the Postgres database. Postgres CDC broadly covers these 3 steps:
- Capturing changes in data. Postgres to Snowflake : 2 Easy Methods of Migration
- Transforming the change data into a format supported by the target.
- Loading the data into the target database.
The CDC process helps identify and sync changes in data so that data stays the same and updated to the most current version across different systems, including various types of databases and data warehouses – especially useful in situations where data gets updated rapidly. CDC and how to automate it
Change Data Capture in Postgres has several benefits:
- Postgres CDC lets you make quick and informed business decisions because analytics and business insights are based on the newest, updated data. Postgres Replication Fundamentals You Need to Know
- With CDC in Postgres, transferring data over the network costs less because it only sends the latest changes, not all the data, at any given time. Data Integration on Postgres
- CDC reduces pressure on the Postgres database -if you are using the Postgres database for tasks like analytics, and tracking activities, batch processing will use more resources, impact performance and slow down systems and critical functions. With CDC in Postgres, copies of the database are created which are continuously refreshed with small volumes of changed data so there is minimal impact on the performance of the operational source system. Postgres to Oracle with BryteFlow
- Postgres CDC enhances the master data management system which gathers all the data in a centralized location. Users can pull in changed data from different sources and update the master data management system continuously, so everyone has access to the same data, thus improving data-based, business decisions. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
- CDC in Postgres can help in disaster recovery or making backups. Real-time CDC used in data replication can help create backups of key databases. Primary databases can thus be retrieved in case of system failure. Postgres to SQL Server with BryteFlow
6 Different Methods to Implement Postgres CDC
CDC is a way to track and use data that has changed in a database. PostgreSQL has built-in CDC functionality. The choice of method depends on your application’s requirements and how much impact you can tolerate on performance. Let us discuss setting up Change Data Capture (CDC) in PostgreSQL using six different methods. Aurora Postgres and How to Setup Up Logical Replication
- CDC in Postgres with Triggers
- CDC in Postgres with Queries or Timestamp Column
- CDC in Postgres with Logical Replication
- CDC in Postgres with Transactional Logs
- CDC in Postgres with Table Differencing
- CDC in Postgres with the No- Code Bryteflow Tool
1. CDC in Postgres with Triggers
Trigger-based Change Data Capture (CDC), also known as ‘Event Sourcing’, is a method used to capture changes in large databases and can be applied to PostgreSQL. It relies on its dedicated event log as the primary source of information. In this approach, triggers are an integral part of each database transaction, promptly capturing events as they happen. Think of a trigger as a set of automatic instructions for a database. It tells the database to do something automatically when a specific action happens, like when new data is added, existing data is updated, or data is deleted. These triggers can be linked to various parts of the database, like tables or views. Triggers for Postgres CDC can be set to run before or after actions like adding, updating, or deleting data. They can also be set to run for each individual change, or just once for a group of changes. Additionally, you can specify that a trigger should only run if certain conditions are met, like if specific columns are changed. Triggers can even be set up to respond to actions like clearing out (TRUNCATE) all data in a table. Postgres Replication Fundamentals You Need to Know
In PostgreSQL CDC, triggers are especially useful for tracking changes in tables. When changes occur, these triggers can record them in another table, effectively creating a log of all the changes made. To implement trigger-based Postgres CDC, you create audit triggers on the database to track all events related to INSERT, UPDATE, and DELETE actions. The advantage of this approach is that it operates at the SQL (database language) level, and developers can simply read a separate table containing all the audit logs to see what changes have occurred. Postgres to Snowflake with BryteFlow
However, it’s important for Database Administrators (DBAs) and data engineers to test how these triggers affect performance in their environment and decide if they can handle the extra work. The PostgreSQL community offers a standard trigger function that works with various versions of PostgreSQL (version 9.1 and newer) and stores all these change events in a table called ‘audit.logged_actions’.
How Trigger-based Postgres CDC Works
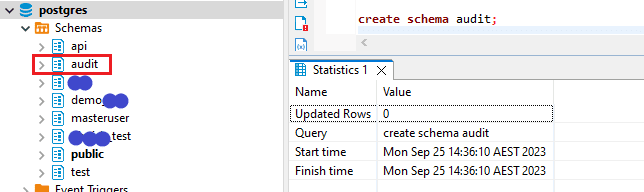
- First create an Audit schema to create the “Events History” shadow table within the IDE. A separate schema helps you to track the table easily. You can use the below query to create the Audit schema,
a. Create Schema Audit;
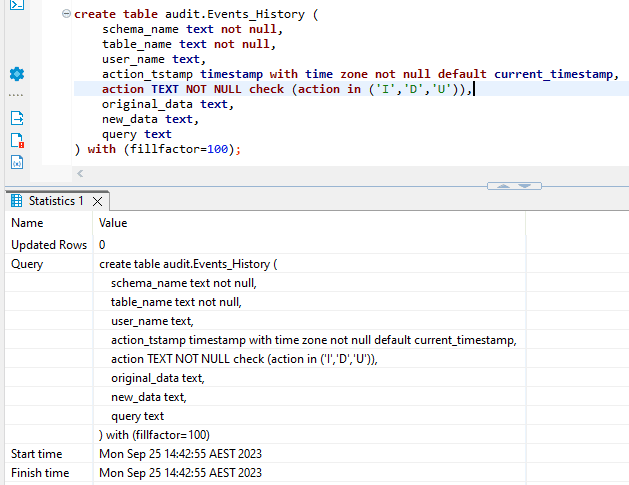
- Then create an “Events History” shadow table. You can use the below query to create the table.
create table audit.<Audit_Table_Name> (
schema_name text not null,
table_name text not null,
user_name text,
action_tstamp timestamp with time zone not null default current_timestamp,
action TEXT NOT NULL check (action in ('I','D','U')),
original_data text,
new_data text,
query text
) with (fillfactor=100);
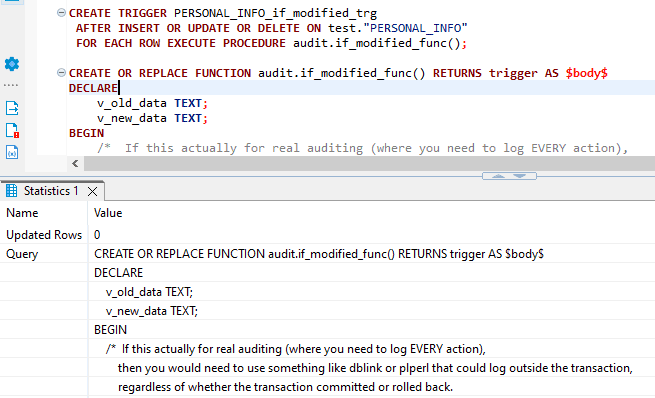
- Then, define the actual trigger function using the below Query
CREATE OR REPLACE FUNCTION audit.if_modified_func() RETURNS trigger AS $body$
DECLARE
v_old_data TEXT;
v_new_data TEXT;
BEGIN
/* If this actually for real auditing (where you need to log EVERY action),
then you would need to use something like dblink or plperl that could log outside the transaction,
regardless of whether the transaction committed or rolled back.
*/
/* This dance with casting the NEW and OLD values to a ROW is not necessary in pg 9.0+ */
if (TG_OP = 'UPDATE') then
v_old_data := ROW(OLD.*);
v_new_data := ROW(NEW.*);
insert into audit.<Audit Table name> (schema_name,table_name,user_name,action,original_data,new_data,query)
values (TG_TABLE_SCHEMA::TEXT,TG_TABLE_NAME::TEXT,session_user::TEXT,substring(TG_OP,1,1),v_old_data,v_new_data, current_query());
RETURN NEW;
elsif (TG_OP = 'DELETE') then
v_old_data := ROW(OLD.*);
insert into audit.<Audit Table name> (schema_name,table_name,user_name,action,original_data,query)
values (TG_TABLE_SCHEMA::TEXT,TG_TABLE_NAME::TEXT,session_user::TEXT,substring(TG_OP,1,1),v_old_data, current_query());
RETURN OLD;
elsif (TG_OP = 'INSERT') then
v_new_data := ROW(NEW.*);
insert into audit.<Audit Table name> (schema_name,table_name,user_name,action,new_data,query)
values (TG_TABLE_SCHEMA::TEXT,TG_TABLE_NAME::TEXT,session_user::TEXT,substring(TG_OP,1,1),v_new_data, current_query());
RETURN NEW;
else
RAISE WARNING '[AUDIT.IF_MODIFIED_FUNC] - Other action occurred: %, at %',TG_OP,now();
RETURN NULL;
end if;
EXCEPTION
WHEN data_exception THEN
RAISE WARNING '[AUDIT.IF_MODIFIED_FUNC] - UDF ERROR [DATA EXCEPTION] - SQLSTATE: %, SQLERRM: %',SQLSTATE,SQLERRM;
RETURN NULL;
WHEN unique_violation THEN
RAISE WARNING '[AUDIT.IF_MODIFIED_FUNC] - UDF ERROR [UNIQUE] - SQLSTATE: %, SQLERRM: %',SQLSTATE,SQLERRM;
RETURN NULL;
WHEN others THEN
RAISE WARNING '[AUDIT.IF_MODIFIED_FUNC] - UDF ERROR [OTHER] - SQLSTATE: %, SQLERRM: %',SQLSTATE,SQLERRM;
RETURN NULL;
END;
$body$
LANGUAGE plpgsql
SECURITY DEFINER
SET search_path = pg_catalog, audit;
- The “Events History” shadow table is housed within the database and records a chronological sequence of events that alter states.
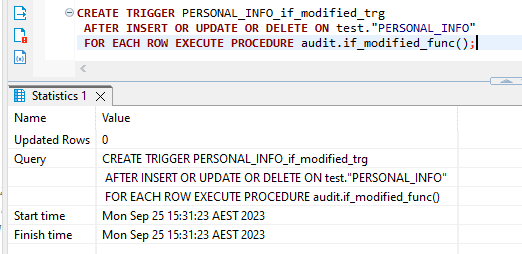
- Then create the trigger for your table using the below query,
CREATE TRIGGER <Table Name>_if_modified_trg
AFTER INSERT OR UPDATE OR DELETE ON <Schema>."<Table Name>"
FOR EACH ROW EXECUTE PROCEDURE audit.if_modified_func();
- Each time an object’s state undergoes a modification, a fresh event is added to this sequence, capturing details of the altered record.
- Three triggers are generated for every table involved in replication, and they are activated in response to specific events within a record:
- An INSERT trigger activates when a new record is added to the table.
- An UPDATE trigger activates when a record undergoes changes.
- A DELETE trigger activates when a record is removed.
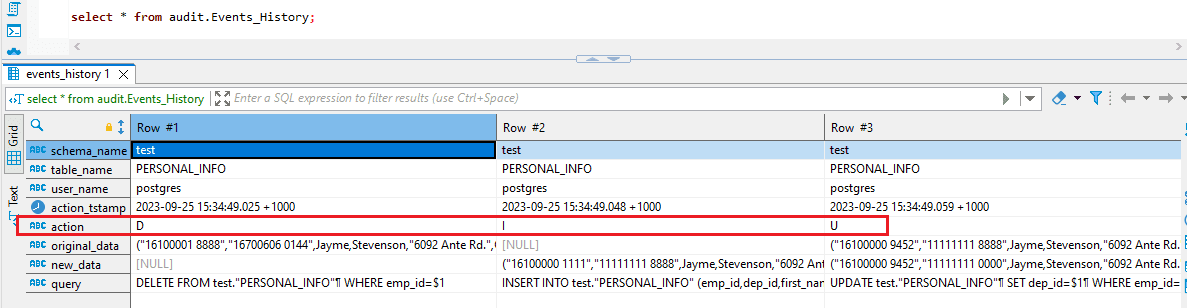
- You can use the below query to drop the trigger on the table:
- DROP TRIGGER <Trigger name> on <Schema>.”<Table Name>”;
- Ex:- DROP TRIGGER PERSONAL_INFO_if_modified_trg on test.”PERSONAL_INFO”;
- In this CDC method, changes or events are recorded only within PostgreSQL. Ultimately, you end up with a table that stores the audit log, and a developer needs to create a program to read and interpret these logs and send them to the target databases. The complexity of this process depends on the target database or data warehouse you’re sending the data to.
Let’s assess the advantages and disadvantages of utilizing Change Data Capture using triggers in PostgreSQL.
Advantages of Trigger-based Postgres CDC
- Postgres CDC using Triggers is extremely dependable and thorough.
- One significant advantage of the Trigger-based CDC approach is that, unlike transaction logs, everything happens within the SQL system.
- Shadow tables offer an unchangeable, comprehensive record of every transaction. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
- Instantly captures changes and allows for real-time processing of events.
- Triggers can detect different types of events: when new data is added, when data is updated, or when data is deleted.
- By default, the PostgreSQL Trigger function used in this method adds extra information to the events, like what caused the change, the ID of the transaction, or the name of the user involved.
- Triggers require making changes to the PostgreSQL database itself. Migrating Oracle to PostgreSQL
Disadvantages of Trigger-based Postgres CDC
- If you want to send change events to a different data storage system, you would have to create a separate process that regularly checks the table where the trigger function records the changes in the Postgres database (in this case, ‘audit.logged_actions’).
- Dealing with triggers adds more complexity in the management of your system.
- Using triggers can slow down the main Postgres database because these triggers run on the database itself and any operations executed, create an additional burden on the main database, increasing the overall time taken. To mitigate this performance impact, a common practice is to create a separate table that mirrors the main table and implement triggers on this secondary table. Synchronizing data between the master and secondary tables can be accomplished using the Postgres logical replication feature.
- On the flip side, if you want changes to be mirrored in a destination beyond the PostgreSQL instance where the trigger operates, you’ll require a separate data pipeline. This secondary pipeline will search for changes and update the target database accordingly.
- The process of establishing and overseeing triggers and multiple data replication pipelines for the target database can result in heightened operational challenges and complexity.
2. CDC in Postgres with Queries
The Query-based method in Postgres CDC involves tracking changes by querying an update timestamp column in the monitored database table that indicates the last time a row was changed. For this custom method you must have a timestamp column in your table. Database designers usually name such columns as LAST_UPDATE, DATE_MODIFIED, etc. Whenever a record is inserted or modified, the update timestamp column is updated to reflect the date and time of the change. Recurring queries are made to PostgreSQL using this timestamp column to fetch all records that have been modified since the last query, effectively capturing changes made to the data. Alternatively, scripts are also used to monitor changes in the timestamp column and record these changes in a target database. This approach is, however, effort-intensive and would demand a lot of time and work from the developer.
The provided command sample enables querying a table containing a timestamp column, allowing the retrieval of rows updated after a specific time.
SELECT * FROM (table name) WHERE (LAST_UPDATE) > (‘LAST_QUERY_TIMESTAMP’);

Query-based Change Data Capture (CDC) in PostgreSQL offers the advantage of not requiring major database modifications. It relies on a timestamp column in the table to record the last change event. However, it has limitations as it doesn’t capture DELETE events, necessitating workarounds like using a BOOLEAN column for deletion tracking. Additionally, query-based CDC places an extra load on the PostgreSQL server as it continually queries for data changes, consuming server resources. Overall, this approach is resource-intensive and demands significant developer effort and time. Compare SQL Server vs Postgres
Advantages of Query-based Postgres CDC
- It is an easy method.
- You can construct it using your own application logic.
- No external tools are necessary.
Disadvantages of Query-based Postgres CDC
- To implement query-based CDC, there must be a column (such as LAST_UPDATE) that tracks the time of the last modification for each record in the table.
- Query-based CDC in Postgres introduces extra overhead to the database.
- This Postgres CDC method necessitates usage of CPU resources for scanning tables to identify altered data and maintenance resources to ensure the consistent application of the LAST_UPDATE column across all source tables.
- Query-based CDC in Postgres is prone to errors and can lead to issues with data consistency.
- Implementing CDC in PostgreSQL based on queries can be achieved without making any alterations to the existing schema, provided that the tables include a timestamp column indicating when rows were last modified.
- Query-based CDC implementations rely on the query layer for data extraction, which imposes additional strain on the PostgreSQL database.
- The absence of a LAST_UPDATE timestamp for deleted rows means that DML operations like “DELETE” won’t be transmitted to the target database unless supplementary scripts are employed to track deletions.
3. CDC in Postgres with Transaction Logs
Modern database management systems (DBMS), such as PostgreSQL, commonly utilize transaction logs (known as WAL or Write-Ahead Log in PostgreSQL) for transaction recording and replication. Transaction Log CDC relies on the database’s transaction log as the source of truth. Transaction Log CDC is sparing of source system resources and operates independently of transactions, improving performance, as CDC operations are not directly tied to every database transaction as they occur. Transaction logs are primarily used for backup and recovery purposes but can also be employed to replicate changes to another database or data lake. Migrating Oracle to PostgreSQL
In a log-based Change Data Capture system, there is no persistent storage of the data stream. Instead, the native transaction logs (also called redo logs) store all database events, ensuring database recovery in case of failure without requiring application-level changes or scanning shadow tables. Restoring data from transaction logs in Postgres may a little complex but is achievable, offering an effective alternative to trigger-based CDC. Learn about SQL Server CDC
Advantages of Transaction Log -based CDC in Postgres
- The log-based CDC in Postgres offers the benefit of leaving the database’s performance completely unaffected, as no extra queries are necessary for each transaction. Postgres to Oracle with BryteFlow
- Postgres CDC that is log-based needs no alterations to the database tables or the application, eliminating the need for extra tables within the source database. Successful Data Ingestion (What You Need to Know)
- Log-based Postgres CDC is widely regarded as the superior method for capturing changes in data and is applicable to all scenarios, even those with exceptionally high transaction volumes. Learn about Oracle CDC
Disadvantages of Transaction Log-based CDC in Postgres
- Parsing a database’s internal logging format poses challenges since most databases lack documentation regarding their transaction log structure, and they don’t typically announce changes to it in new releases. Consequently, adapting your database log parsing logic becomes necessary with each new database release.
- Database engines often archive log files, necessitating that CDC software either read logs before they are archived or possess the capability to read archived logs.
- Implementing the additional log levels required for creating transaction logs that can be easily scanned, might introduce minor performance overhead.
- Failure scenarios can arise from the loss of connection to either the source or target, resulting in data loss, duplicated records, or requiring a restart from the initial data load.
4. CDC in Postgres with Table Differencing
Another Postgres CDC approach involves using utilities like table ‘tablediff’ to compare data between two tables to identify mismatched rows. Subsequently, scripts can be employed to apply these differences from the source table to the target table. While this method is more effective than ‘Timestamps’ CDC for handling deleted rows, it has its shortcomings.
The incremental or table differencing method involves comparing a copy of the source table with a previous version of the same table to identify any variances. To achieve this, two copies of the table need to be kept in the database. This process is conducted at regular intervals to capture disparities between the tables, delivering the most recent inserts and updates found in the new version of the table. This is achieved through the utilization of native SQL scripts, ensuring a precise representation of alterations.
You can use the below query to compare the two similar tables using MINUS operator. It returns all rows in table “Source Table” that do not exist or changed in the other table.
SELECT * FROM <schema>.<"source_table_name">
MINUS
SELECT * FROM <schema>.<"old_version_source_table_name">;
One major issue is the significant CPU resource consumption required to identify differences, and this overhead increases proportionally with the volume of data. Analytics queries against the source database or production environment can also impact application performance negatively. To mitigate these problems, some choose to periodically export the database to a staging environment for comparison. However, this approach results in escalating transfer costs as data volumes grow.
Moreover, the Table Diff method is incapable of capturing intermediate changes in data. For instance, if someone updates a field but subsequently reverts it to its original value, a simple comparison won’t capture these change events. Additionally, the diff method introduces latency in the Postgres CDC process and cannot operate in real-time.
Advantages of Table Differencing in Postgres CDC
- It offers a precise view of modified data exclusively through the use of native SQL scripts.
Disadvantages of Table Differencing in Postgres CDC
- The need for storage capacity grows due to the requirement of maintaining three copies of the data sources utilized in this Postgres CDC method: the original data, the previous snapshot, and the current snapshot.
- As a Postgres CDC method, Table Diff struggles to perform efficiently in applications characterized by high transactional workloads.
5. CDC in Postgres with Logical Replication
Postgres Logical Replication also known as Logical Decoding in PostgreSQL, captures and records all database activities using the Write-Ahead Log (WAL). This feature has been available since PostgreSQL version 9.4, enabling efficient and secure data replication between different PostgreSQL instances, even on separate physical machines. It operates by creating a log of database activities without impacting performance. To implement it, an output plugin is installed, and a subscription model with publishers and subscribers is used.
For versions older than 10, you need to manually install plugins like wal2json or decoderbufs, while version 10 and later include the default pgoutput plugin. Additionally, output plugins can transform events, such as INSERTs, UPDATEs, and DELETEs, into more user-friendly formats like JSON. However, it’s essential to note that table creation and modification steps are not captured by these events. Many managed PostgreSQL services, including AWS RDS, Google Cloud SQL, and Azure Database, support Logical Replication. The following list outlines the pros and cons of employing PostgreSQL’s Logical Replication for implementing Change Data Capture.
Advantages of Postgres Logical Replication for CDC
- Leveraging log-based CDC facilitates the real-time capture of data changes in an event-driven manner. This ensures that downstream applications consistently access the most up-to-date data from PostgreSQL.
- Log-based CDC has the capability to detect all types of change events within PostgreSQL, including INSERTs, UPDATEs, and DELETEs.
- Consuming events through Logical Replication essentially involves direct access to the file system, preserving the performance of the PostgreSQL database.
Disadvantages of Postgres Logical Replication for CDC
- One should note that Logical Replication is not available in very old versions of PostgreSQL, specifically those predating version 9.4.
- Developers are required to devise complex logic for processing these events and subsequently converting them into statements for the target database. Depending on the specific use case, this may extend project timelines. Types of CDC and the case for Automation
How Logical Replication works in Postgres
The method operates by incorporating an output plugin during setup. To activate logical replication, specific parameters must be configured in the Postgres settings.
- To begin using logical replication, the initial step is to define the following parameters within the Postgres configuration file, postgresql.conf.
-
- wal_level = logical
- By configuring the wal_level to “logical,” you enable the Write-Ahead Logging (WAL) system to capture essential data required for logical replication.
- max_replication_slots = 5
- To guarantee smooth operation, make sure that your max_replication_slots setting is either equal to or greater than the sum of PostgreSQL connectors utilizing WAL and any additional replication slots employed by your database.
- max_wal_senders = 10
- Ensure that the max_wal_senders parameter, which defines the maximum permissible concurrent connections to the WAL, is set to a value that is at least double the number of logical replication slots. For instance, if your database utilizes a total of 5 replication slots, the max_wal_senders value should be 10 or higher
- wal_level = logical
- To implement the modifications, please initiate a restart of your Postgres server.
- The next phase involves configuring logical replication by utilizing the output plugin “test_decoding”. This will guarantee that each modification to the tables generates audit events accessible through specific select statements.
- SELECT pg_create_logical_replication_slot(‘<slot_name>’, ‘<plugin>’);
- Ex:- SELECT pg_create_logical_replication_slot(bflow_replication_slot, ‘test_decoding’);
- Slot_name:- Each replication slot possesses a designated name, comprising lowercase letters, digits, and underscores.
- Plugin:- You mention the plugin here.
- To verify the slot is created successfully run the following command.
- SELECT slot_name, plugin, slot_type, database, active, restart_lsn, confirmed_flush_lsn FROM pg_replication_slots;

- Logical decoding facilitates the use of two types of select statements to retrieve these events. The following command allows you to examine these events. To access or obtain the outcomes, utilize the following commands.
- SELECT * FROM pg_logical_slot_peek_changes(‘bflow_replication_slot’, NULL, NULL);
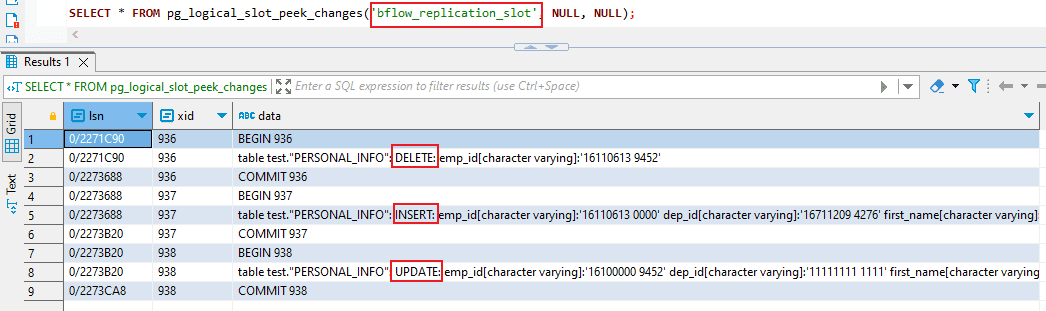
-
- SELECT * FROM pg_logical_slot_get_changes(‘bflow_replication_slot’, NULL, NULL);
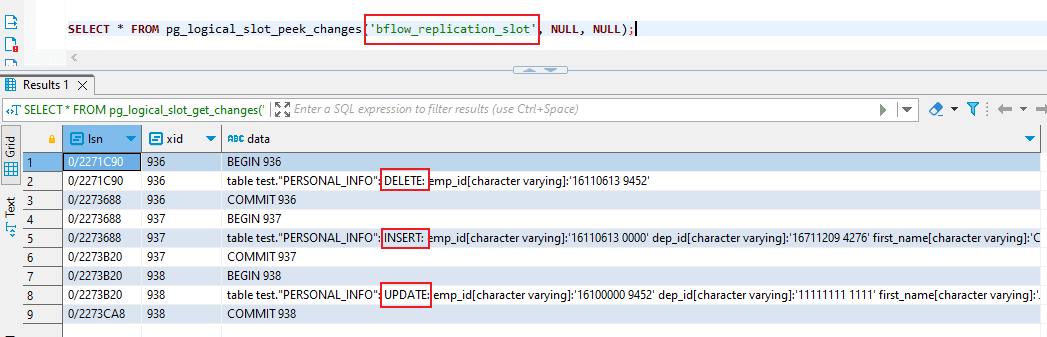
-
- The PostgreSQL command ‘peek’ allows you to inspect changes from WAL entries without actually consuming them. As a result, calling ‘peek’ multiple times will yield the same outcome each time.
- Conversely, when you use ‘get’, it provides results only on the initial call. Subsequent calls to ‘get ’will return empty result sets. In essence, this means that the results are retrieved and cleared upon the first invocation of the command, significantly enhancing our capability to develop logic for utilizing these events to generate a table replica.
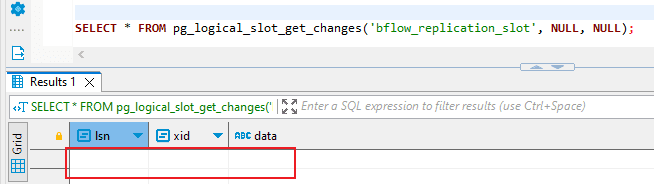
- In the subsequent phase, generate a publication that includes either all of your tables or only those that you specifically select. If you opt for specific tables, you can modify the composition of the publication by adding or removing tables at a later time.
- CREATE PUBLICATION pub FOR ALL TABLES;
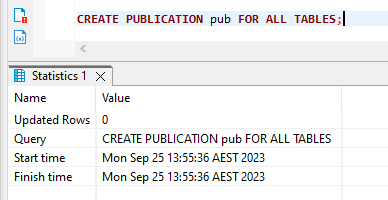
-
- Or CREATE PUBLICATION pub FOR TABLE table1, table2, table3;
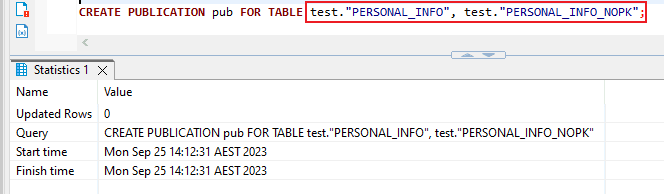
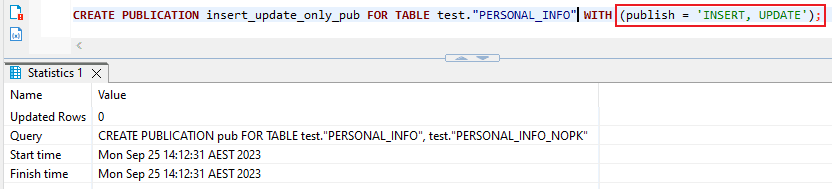
- You have the choice to decide which operations to incorporate into the publication. For instance, the publication below exclusively encompasses INSERT and UPDATE actions for table1.
- CREATE PUBLICATION insert_update_only_pub FOR TABLE table1 WITH (publish = ‘INSERT, UPDATE’);
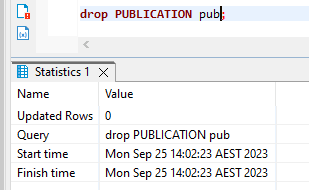
- You can use the below query to drop the “PUBLICATION pub”
- drop PUBLICATION pub;
- Verify that your chosen tables are in the publication
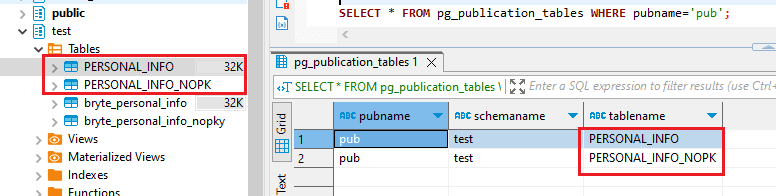
6. CDC in Postgres (Automated) with BryteFlow
We should note that though Postgres natively provides support for CDC with continuous syncing through triggers, queries, transactional logs, logical replication or through custom logic, it is incumbent on the developers to capture these events and deliver them to the target database. The logic will need to be specifically coded for different target databases according to use cases. Postgres CDC with BryteFlow
A great, cost-effective alternative is to use a fully automated tool for Postgres CDC like BryteFlow that can continuously sync and deliver data to most destinations, both on-premise, and on Cloud without the need for a single line of code. While PostgreSQL’s built-in replication tools may suffice initially, they prove challenging to scale as replication becomes more complex. This can arise from factors like increased data volume or added code complexity. BryteFlow’s Data Integration on PostgreSQL
Bryteflow, a Tool for Real-Time, No-Code Postgres CDC
BryteFlow is a no-code, real-time data replication tool that allows users to easily configure and build their data pipelines without having to write any code. BryteFlow employs automated log-based Change Data Capture (CDC) to replicate data from transactional databases (On-Prem and Cloud) like SAP, Oracle, PostgreSQL, MySQL and SQL Server to Cloud platforms like Amazon S3, Amazon Redshift, Snowflake, Azure Synapse, Azure Data Lake 2, PostgreSQL, Google BigQuery, SQL Server, Teradata, Kafka and Databricks in real-time. This enables the delivery of readily usable data at the destination.
Our data replication solution is characterized by automation, a user-friendly graphical interface, self-service capabilities, and built-in support for high volume, bulk data replication. BryteFlow Ingest can move petabytes of data within minutes, moving approx. 1,000,000 rows in just 30 seconds. BryteFlow offers a rapid deployment process, allowing you to receive your data within two weeks, in contrast to the months typically required by our competitors.
For SQL sources, BryteFlow replicates data in real-time with a range of Change Data Capture options including SQL Server Change Data Capture or SQL Server Change Tracking. It creates schema and tables automatically on the destination. BryteFlow enables ingestion from all versions of SQL Server to Postgres and supports CDC replication from multi-tenant SQL Server databases for ISVs. Learn about Oracle to Postgres Migration (The Whys and Hows)
Bryteflow’s Postgres CDC Highlights
- BryteFlow’s no-code PostgreSQL CDC replication has zero impact on source.
- High performance – parallel threaded initial sync and delta sync for large volumes.
- Zero coding – Automates schema and table creation using best practices on destination.
- Automates every process, including data extraction, merges, masking, and DDL.
- Provides data type conversions out of the box.
- Provides an option to preserve SCD type 2 history.
- Delivers analytics ready data assets on S3, Redshift, Snowflake, Azure Synapse and SQL Server
- Supports loading of terabytes of PostgreSQL data, both initial and incremental easily.
- Provides automated data reconciliation with row counts and column checksums.
- High availability and high throughput of 1,000,000 rows in 30 seconds (6x faster than GoldenGate).
- Has automated catchup from network failure, resumes automatically from point of stoppage when normal conditions are restored.
- Has a dashboard to monitor data ingestion and transform instances.
Conclusion
This article discussed various methods for continuously syncing data through Postgres Change Data Capture (CDC). It covered approaches like using triggers, queries, transactional logs, and logical replication. Additionally, it introduced BryteFlow, an agentless, no-code solution for building PostgreSQL data pipelines. The choice of CDC method depends on factors like resources, time, and experience. BryteFlow can migrate data to and from on-prem data sources, cloud-based data sources or a mix of both. If you’re interested in learning more about how BryteFlow can help you achieve and scale real-time replication with PostgreSQL, contact us for a Demo




