BryteFlow for AWS Data Integration
Replication to Amazon S3
Data integration on Amazon Redshift
What is Amazon Redshift?
Amazon Redshift is essentially the AWS data warehouse in the cloud that can handle huge petabyte volumes of data. Big data is growing exponentially and on-premise data warehouses cannot scale up easily to meet the demand of increased storage and analytics, the way a cloud data warehouse like AWS Redshift can. BryteFlow for AWS ETL
The fastest way to move your data is with BryteFlow’s log-based Change Data Capture to Redshift
Secrets of Fast Bulk Loading of Data to Cloud Data Warehouses
Check out BryteFlow’s data integration on AWS Redshift. Get in touch with us for a FREE Trial.
Aurora Postgres and How to Setup Up Logical Replication
BryteFlow’s Technical Architecture
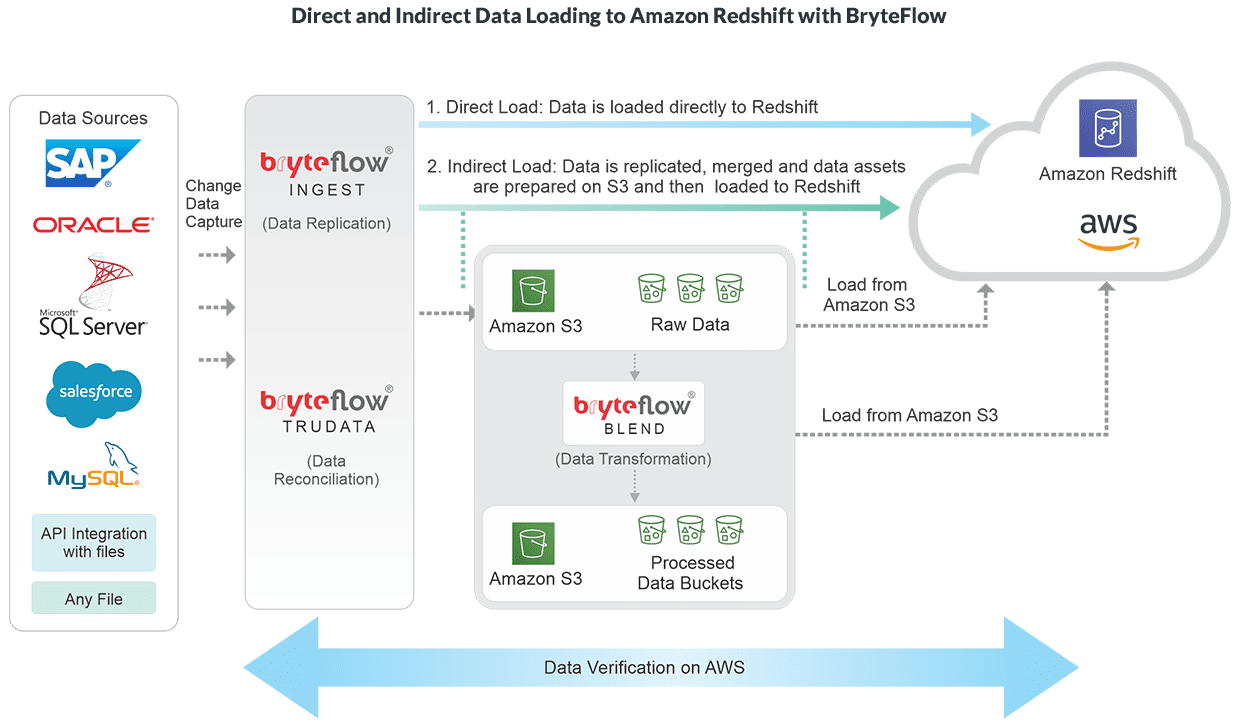
How BryteFlow works with the Amazon Redshift Data Warehouse
BryteFlow meshes tightly with AWS services to provide fast data integration, in real-time. Here’s what you can do with BryteFlow on Redshift. Get a Free Trial of BryteFlow



Change Data Capture your data to Redshift with history of every transaction
BryteFlow continually replicates data to Redshift in real-time, with history intact, through log based Change Data Capture. BryteFlow Ingest leverages the columnar Redshift database by capturing only the deltas (changes in data) to Redshift keeping data in the Redshift database synced with data at source. ELT in Data Warehouse
Data is ready to use – Get data to dashboard in minutes
BryteFlow Ingest on Redshift provides a range of data conversions out of the box including Typecasting and GUID data type conversion to ensure that your data is ready for analytical consumption or for Machine Learning purposes.
Build a Data Lakehouse on Amazon S3
Transfer data with speed and performance
BryteFlow Ingest uses fast log-based CDC to replicate your data to Amazon Redshift. Data is transferred to the Redshift database at high speeds in manageable chunks using compression and smart partitioning. BryteFlow for AWS ETL
Automated DDL and performance tuning in Redshift
BryteFlow helps you tune performance on AWS Redshift by automating DDL (Data Definition Language) which is a subset of SQL.
BryteFlow offers flexibility for data preparation
You have the choice of transforming and retaining data on AWS S3 and pushing it selectively to Redshift – for multiple use cases including Analytics and Machine Learning. Or replicating and transforming data directly on AWS Redshift itself.
Data Integration on Amazon S3 Data Lake
Make Redshift performance faster by preparing data on the AWS S3 data lake
BryteFlow frees up the resources of the Redshift database by preparing your data on Amazon S3 and only pushes the data you need for querying onto Redshift, hence freeing up Redshift resources. BryteFlow eliminates this data-load process from the Amazon Redshift cluster. This has an immediate and direct positive impact on concurrency. Create an S3 Data Lake in Minutes
Save on storage and boost Redshift cluster performance
You can choose to save all your data on Amazon S3 where typically storage costs are much lower. In Redshift you need to only pay for the resources you actually use for the compute – this can translate to a large savings on data costs. This also enhances the performance of the Redshift cluster.
Aurora Postgres and How to Setup Up Logical Replication
Automated Data Reconciliation on Redshift
You are assured of getting high quality, reconciled data always with BryteFlow TruData, our data reconciliation tool. BryteFlow TruData continually reconciles data in your Redshift database with data at source. It can automatically serve up flexible comparisons and match datasets of source and destination.
Ingest large volumes of data automatically with BryteFlow XL Ingest
If you have huge petabytes of data to replicate to your Redshift data warehouse, BryteFlow XL Ingest can do it automatically at high speed in a few clicks. BryteFlow XL Ingest has been specially created to cater for the replication of large data sets with tables over 50 GB. Learn the Secrets to Fast Bulk Loading of Data
Dashboard to monitor data latency and status of data ingestion on Redshift
Stay on top of your data ingestion to Redshift with the BryteFlow ControlRoom. It gives you the specifics of your data including latency, operation start time, operation end time, volume of data ingested and data remaining.
Data transformation with data from any database, incremental files or APIs
BryteFlow Blend our data transformation tool enables you to merge and transform data from virtually any source including any database, any flat file or any API for querying on Redshift.
Data migration from Teradata and Netezza to the Redshift data warehouse
BryteFlow can migrate your data from data warehouses like Teradata and Netezza to Amazon Redshift with ease in case you need to shift your data.
Data pipeline and 6 reasons to automate it
Get built-in resiliency
BryteFlow has an automatic network catch-up mode. It just resumes where it left off in case of power outages or system shutdowns when normal conditions are restored.
Query data external to Redshift with Redshift Spectrum
BryteFlow enables you to query external exabytes of data residing in Amazon S3 through Redshift without actually needing to load the data onto Redshift. This is done through Redshift Spectrum, a feature of Amazon Redshift. Redshift Spectrum is serverless and you can enjoy the advantages of open data formats and cheap storage. Also, if you are processing huge data volumes you can scale up power on Redshift Spectrum easily by harnessing thousands of nodes.
Amazon Athena vs Redshift Spectrum for queries
Why use AWS Redshift as your
Cloud Data Warehouse?
Amazon Redshift, the cloud data warehouse has some great built-in advantages:

High speed data querying
Amazon Redshift offers exceptional performance, in fact it is known for its speed in processing large data sets. This is largely due to its architecture that uses Massively Parallel Processing (MPP) design and columnar data storage. Also, it analyzes all your data using standard SQL which is simple and cost-effective.
An affordable data warehouse
As far as cloud data warehouses go, Redshift is an affordable data warehouse. It is also a fully managed service so you don’t need to set up expensive hardware and also save on maintenance. By using BryteFlow you can save on costs further by storing data on the Amazon S3 data lake and only pushing data to Redshift for querying.
A scalable, elastic data management solution
Do you need to make new purchases of hardware and software every time your data volumes go up or want to use your data in a new way? With Redshift you can easily scale computing power up for extended capacity and better performance.
Data security is a concern you need not have
Security on AWS Redshift is comprehensive. BryteFlow teams up with Redshift to implement best in class security with access and credentials managed through Identity and Access Management (IAM) accounts. For companies using Private Cloud, access is available through a Virtual Private Cloud. Data encryption adds another level of security to your data.