
Why use ELT in the Data Warehouse and how are ETL and ELT different in their data warehousing operations? The blog answers this and compares ETL and ELT feature by feature. It also introduces you to BryteFlow, our automated ELT tool.
Quick Links
- Why big data analytics needs ETL or ELT in the Data Warehouse
- About ETL and ELT Processes
- ETL and ELT: Know the differences
- ETL and ELT: Feature-by-Feature Comparison Chart
- BryteFlow, ELT Tool for the Data Warehouse and Data Lake
Why big data analytics needs ETL or ELT in the DataWarehouse
Organizations are increasingly collecting data from multiple sources. Data from legacy databases, IoT data, data from social media channels, ecommerce transactions, emails, ERP and CRM data, website data and the list goes on. All this data needs to be integrated by way of ETL or ELT in data warehouses or other data repositories. The transformed data can be analyzed to deliver rich insights from analytics, or to enable machine learning that can fuel growth for organizations. Organizations can aggregate these massive volumes of data in data warehouses via ETL and ELT processes. Data Migration 101 (Process, Strategies and Tools)
About ETL and ELT Processes
What is ELT (Extract Load Transform)?
ELT or Extract Load Transform is a process critical to the world of data integration and analytics. ELT refers to the process of extracting data from multiple sources, loading it to a target data warehouse and then using the resources of the data warehouse to power the transformation to make the data ready for consumption. When you ELT data you are taking advantage of a streamlined ELT pipeline that can handle the tasks of extraction, loading and transformation to the data warehouse in real-time and in an automated manner. ETL / ELT in Snowflake
The ELT pipeline handles the tasks of data cleansing, enrichment, and data transformation within the data warehouse. This allows organizations to concentrate on achieving actionable business insights from their data rather wasting time in figuring out how to get the data to the data warehouse, the coding it may entail, and fixing incipient performance issues. ELT is becoming increasingly popular due to the adoption of the Cloud and cloud data warehouses like Amazon Redshift, Snowflake, Google BigQuery, Teradata, Azure Synapse, that have immense scalability, compute power and unlimited storage to support huge volumes of raw data and complex transformations. The ELT process also delivers data to data lakes such as Amazon S3, Databricks, and Azure Data Lake. Cloud Migration (Challenges, Benefits and Strategies)
What is ETL (Extract Transform Load)?
ETL or Extract Transform Load process refers to the 3 distinct steps: Extract – extracting and integrating data from different sources, Transform – holding and transforming it in a storage / staging area and Load – loading the transformed data to a data warehouse or data lake for further use. Data migrations and cloud data integrations require ETL to bring data across. ETL is an older process that came into being in the 70s while ELT came into being somewhere in the 2000s. ETL delivers data to on-prem and cloud data warehouses and is suitable for delivering structured data from SQL relational databases like SAP, Oracle and SQL Server. ETL SAP Data with the Bryteflow SAP Data Lake Builder
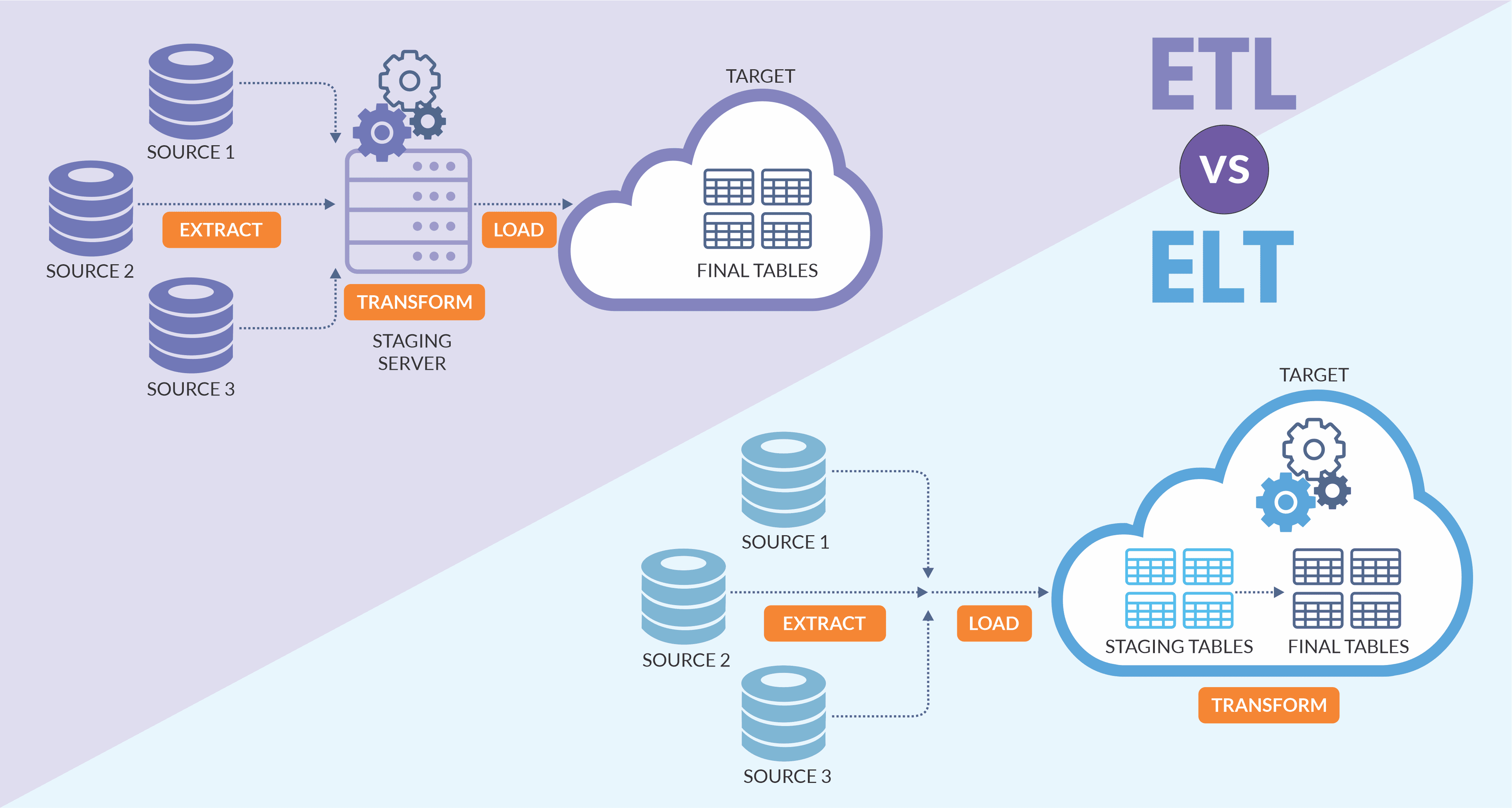
ETL and ELT: Know the differences
ETL and ELT: They differ in the order of how Extract, Load and Transform operations are performed
ETL and ELT basically differ in the sequence that Extract Transform Load operations are performed. The ETL process extracts and aggregates data from sources and stores it in a staging area, performs transformations on it and then loads transformed data to the data warehouse or data repository. In the case of the ELT process, the raw data from multiple sources is extracted and loaded to the data warehouse where it is transformed (when needed) using the compute resources of the data warehouse. GoldenGate CDC and a better alternative
ETL and ELT: ELT can handle more data types and higher volumes that ETL
ETL is applied to structured data and smaller datasets generally, while ELT can handle very high volumes of structured and unstructured data. Since ELT can store raw data, not much thought needs to be given to data extraction and storage upfront. ELT is ideal for big data volumes since data can be extracted and loaded into the data warehouse directly from source. However, the ETL process needs a lot more thought at the start since the data to be transformed needs to conform to the schema of the target database. The schema is the way the database has been constructed and incudes fields, table names, data types and how they relate to each other. Data subjected to ETL is usually structured data from SQL-based legacy databases and on-premise systems while data for ELT can be structured, semi-structured and unstructured (data from PDFs, images, videos, ppts, social media etc.). For ETL you also need to identify at the outset the data that needs to be extracted, and potential keys to integrate the data from various sources, since it is unlikely all of the data will need to be queried for a particular purpose. SQL Server to Databricks (Easy Migration Method)
ETL and ELT: ELT is faster, more scalable, and efficient and data can be queried endlessly
In an ETL process, data ingestion takes more time since the data must be stored and transformed on a different server before loading to the data warehouse or repository. With ELT, raw data is extracted and loaded directly to the data warehouse. Transformation is done as and when required in the data warehouse itself, so loading and transformation can happen in tandem. The raw data can be queried and re-queried in an ELT process in contrast to ETL where datasets cannot be queried endlessly. Raw data retained through ELT can be used as a valuable resource for different business intelligence queries. ELT is more scalable (can ingest very high volumes of data), flexible (can be queried repeatedly) and efficient (faster process, can handle structured and unstructured data). Oracle vs Teradata (Migrate in 5 Easy Steps)
ETL and ELT: Overall ELT may cost less than ETL
Since ETL requires a separate secondary server for transformation, maintenance and server costs can add up. ELT needs fewer systems and so the maintenance costs are reduced. Compute time required for ELT is less since transformations are isolated from extract and load operations and can be carried out selectively later. How to reduce costs in Snowflake by 30%
ETL and ELT: ELT supports ingestion to Data Lakes and Machine Learning use cases
ELT can deliver large amounts of raw data and lends itself well to storage of data in data lakes unlike ETL which is delivered to data warehouses. ELT’s compatibility with data lakes enables data to be used for machine learning and data science use cases. Of course, it can handle relational data too. GoldenGate CDC and a better alternative
ETL and ELT: Data in an ETL process reduces risk of compliance violations
Organizations with sensitive data or with compliance regulations like GDPR, HIPAA, or CCPA need to mask, remove, or encrypt certain data fields. For e.g. masking the first few digits of social security numbers. The ETL process transforms the data before loading it to the data warehouse and thus is more compliant of security policies. ELT however uploads the sensitive data which can show up in logs where the System Admins might have access to it. This could be a violation of the EU’s GDPR compliance standards. Database Replication Made Easy – 6 Powerful Tools
ETL and ELT: Feature-by-Feature Comparison Chart
| Feature | ETL | ELT |
| Order of operation | Data extracted from source, loaded to a secondary staging server for transformation and then loaded to the data warehouse | Data extracted from source, directly loaded to the data warehouse and transformed there when needed. |
| Data Lake compatibility | ETL is not suitable for data lakes, and data lakehouses. | The ELT process is ideal to deliver data to data lakes, and data lakehouses. |
| Privacy and Compliance concerns | Transformation is done before loading, so ETL is suitable for compliance with HIPAA, GDPR, and CCPA standards. This enables sensitive data to be removed / masked before loading to the data warehouse. | Direct loading of data needs to have more data security measures in place. ELT has a higher risk of non-compliance and exposing sensitive data since entire dataset is loaded to the data warehouse. |
| Data volumes | ETL is suitable for use with smaller, relational data sets needing complex transformations that have been pre-selected as per analytical goals. | ELT can handle large and small data volumes and can process structured and unstructured data. Ideal for very large data sets that need fast analytics. |
| Speed | ETL takes more time since data needs to be transformed before loading into the data warehouse. | ELT is faster since data is loaded directly into the data warehouse and then transformed when required. Loading and transformation can happen in parallel. |
| Maintenance & Costs | A secondary processing server is required for staging and transformation which adds to hardware and maintenance costs. | Data being loaded directly to the data warehouse uses fewer systems, leading to lower maintenance costs. |
| Maturity of Processes | ETL has been around since the 70s. Over the years its protocols and processes have been well documented and defined. | ELT is much newer and been around since the 2000s. Best practices are still evolving and there is less documentation. |
| Requerying data | Data is transformed before loading and raw data is not available for requeries. | Since raw data is loaded directly into the data warehouse, it can be queried and requeried any number of times. |
| Hardware | An on-premises, conventional ETL process may need costly hardware. However modern cloud based ETL solutions will not require hardware. | Since the ELT process uses cloud-based systems, extra hardware is not required. |
| Raw Data Storage | The ETL process does not store raw data in the data warehouse. It stores only the transformed data required for analytics. | The ELT process stores all the raw data in the data warehouse that can be transformed selectively when needed |
| Use Cases | ETL uses structured, relational data and is suitable for analytics and BI purposes. | ELT can process structured, semi-structured and unstructured data. Since large volumes of raw data are available, it can be used for Machine Learning, AI as well as Analytics purposes. |
BryteFlow, ELT Tool for Data Warehouses and Data Lakes
As an ELT tool, BryteFlow carries out completely automated ELT to Snowflake (on AWS, Azure and GCP), Amazon Redshift, Amazon S3, Amazon Aurora and Postgres integration (on AWS and Azure) from multiple sources like SAP, Oracle, SQL Server, Postgres, MySQL etc. BryteFlow’s no-code real-time ELT process features data extraction and ingestion done by BryteFlow Ingest using log-based CDC to sync data with source. BryteFlow enables ELT of large volumes of enterprise data. High volume ingestion for the initial full refresh is very fast due to parallel multi-thread loading, partitioning and compression. Incremental data is loaded with log-based, automated Change Data Capture.
Data transformation is carried out by BryteFlow Blend, our data transformation tool. BryteFlow Blend merges, joins and transforms data in your data warehouse or data repository and provides ready-to-use data in real-time for Analytics, AI, and ML. BryteFlow Blend prepares data with simple SQL and has an intuitive drag-and-drop interface for complete end-to-end workflows. BryteFlow is a completely automated self-service ELT tool that can be used by business users easily and requires minimal or no involvement from DBAs. Cloud Migration Challenges
BryteFlow ELT Tool Highlights
- The ELT tool uses automated CDC (Change Data Capture) to sync data with source. Kafka CDC and Oracle to Kafka CDC Methods
- BryteFlow Ingest delivers high speed data extraction and ingestion for ETL (1,000,000 rows in 30 secs) in near real-time. About Data Ingestion
- Support for fast loading of data -initial full refresh with parallel, multi-threaded loading and compression. How to load terabytes of data to Snowflake fast
- Completely automated ELT pipeline, no coding for any process including creation of schema, SCD Type2 and masking. Database Replication Made Easy – 6 Powerful Tools
- Visual drag-and-drop UI for ELT workflows. Oracle vs Teradata (Migrate in 5 Easy Steps)
- Transformed data is ready to use immediately for Analytics or Data Science purposes. How to Manage Data Quality
- Start to finish monitoring of ELT workflows with relevant dashboards. SQL Server to Databricks (Easy Migration Method)
- Automated data reconciliation of data with comparison of row counts and columns checksum with BryteFlow TruData.
Check out Snowflake ELT / ETL and AWS ETL with BryteFlow Zero-ETL, New Kid on the Block?




