
Apache Kafka demystified
What is Kafka, how Kafka works, Kafka use cases, concepts and how to install it. This blog takes you through all the basic nuts and bolts of Apache Kafka.
Quick Links
- What is Apache Kafka?
- What is Kafka used for?
- How does Kafka work?
- Apache Zookeeper and Kafka
- Kafka Zookeeper Synergy and Apache Zookeeper Use Cases
- Installing Kafka
- Kafka Connectors
- BryteFlow as a Kafka Connector
What is Apache Kafka?
Apache Kafka is an open-source platform that ingests and processes streaming data in real-time. Streaming data is generated every second simultaneously by tens of thousands of data sources. This constant stream of records can be processed by a streaming platform like Kafka both sequentially and incrementally. Apache Kafka uses a Publish and Subscribe model to read and write streams of records. Kafka is also described as a distributed messaging software and as with other message queues, Kafka reads and writes messages asynchronously. However, unlike other messaging systems, Kafka has built-in partitioning, replication, higher throughput and is more fault-tolerant which make it ideal for high volume message processing. Kafka CDC and Oracle to Kafka CDC Methods
What is Kafka used for?
Kafka Use Cases are many and found across industries like Financial Services, Manufacturing, Retailing, Gaming, Transportation & Logistics, Telecom, Pharma, Life Sciences, Healthcare, Automotive, Insurance and more. In fact, Kafka is used wherever there is high-volume streaming data to be ingested and used for insights. Kafka use cases include data integration, event streaming, data processing, developing business applications and microservices. Kafka can be used in Cloud, Multi-cloud, Hybrid deployments. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
Kafka Use Case 1: Tracking Website Activity
Kafka can be used to track user activity by building user activity tracking pipelines with real-time publish-subscribe feeds. Pages viewed, user searches, user registrations, subscribes, comments, transactions etc. can be written to Topics and made available for processing in real-time for data warehouse analytics on platforms like Snowflake, Amazon Redshift, Amazon S3, ADLS Gen2, Azure Synapse, SQL Server etc.
Kafka Use Case 2: Operational Metrics
Kafka can be used to report on operational metrics by usage in operational data pipelines. It can collect data from distributed applications to enable alerting and reporting for operational metrics, by creating centralized data feeds of data from operations. CDC to Kafka explained
Kafka Use Case 3: Aggregating Logs
Kafka collects logs from multiple services and makes them available in standard format to multiple consumers. Kafka supports low-latency processing and many data sources, which is great for distributed data consumption. BryteFlow’s Kafka Integration
Kafka Use Case 4: Stream Processing
Unlike data warehousing systems where data is stored and then processed, you can now process data as it arrives -this is real-time data processing. The real-time processing of streams of data when done continuously, simultaneously and in a sequence of records, is Kafka stream processing. Real-time stream processing means Kafka reads data from a Topic (Source), carries out some transformation or analysis and writes the outcome to another Topic (Sink) for applications and users to consume. The high durability of Kafka is advantageous for real-time stream processing. GoldenGate CDC and a better alternative
How does Kafka Work?
Kafka is known as an event streaming platform since you can:
- Publish i.e. write streams of events and Subscribe i.e. read streams of events, involving a constant data import and export from other applications. Debezium CDC Explained and a Great Alternative CDC Tool
- Store event streams reliably for as long as you like. Zero-ETL, New Kid on the Block?
- Process event streams as they happen or later.
Kafka is highly elastic, extremely scalable, secure and has a data distributed publish-subscribe messaging system. This distributed system has servers and clients that work through a TCP Network Protocol. This TCP (Transmission Control Protocol) helps in transmitting packets of data from source to destination, between processes, applications, and servers. The protocol establishes connection before the communication happens between the two computing systems in the network. Kafka can be deployed on virtual machines, bare-metal hardware, on-premise containers and in cloud environments. Kafka Integration with BryteFlow
Kafka Architecture -the 1000 ft view
- The Brokers (Servers or Nodes) handle client requests for production, consumption and metadata and enable replication of data in the cluster. The number of Brokers can be more than one in a cluster.
- Zookeeper maintains the state of a cluster, configuration of topics, electing a leader, ACL lists, broker lists etc.
- Producer is an application that produces and delivers records to a broker.
- Consumer is the system that consumes the records from the broker. Debezium CDC Explained and a Great Alternative CDC Tool
Kafka Producers and Consumers
Kafka Producers are basically client applications that publish or write events to Kafka while Kafka Consumers are those systems that subscribe to or read and process those events. Kafka Producers and Kafka Consumers are completely decoupled and there are no dependencies between them. This is one of the reasons Apache Kafka is so highly scalable. The capability to process events exactly-once is one of the guarantees that comes with Kafka.
Kafka Topics
A Kafka Topic is essentially a category to help in organizing and managing messages. A Kafka Topic will have a unique name within the Kafka cluster. Messages are sent to and read from individual Topics. The Kafka Producers writes data to a Topic and the Kafka Consumer reads the data from a Topic. A Kafka Topic can have zero to multiple subscribers. Every Kafka Topic is partitioned and replicated across different Kafka Brokers (Kafka servers or nodes in a Kafka Cluster). This distributed placement enables client applications to read and write data to and from multiple brokers simultaneously. When a new event is written to a Kafka Topic, it is attached to a Topic partition. Events that involve the same event key such as a specific customer id or payment id will be written to the same partition always, and the Consumer of that topic -partition will always get to read the events in the same sequence as they were written. Partitions are integral to Kafka’s functioning since they enable topic parallelization and high message throughput. Debezium CDC Explained and a Great Alternative CDC Tool
Kafka Records
Records are essentially information about events that are stored on the Topic as a record. Applications can connect and transfer a record into the Topic. Data is durable and can be stored in a topic for a long time till the specified retention period is over. Records can consist of various types of information – it could be information about an event on a website like a purchase transaction, feedback on social media or some readings from a sensor-driven device. It could be an event that flags off another event. These records on a topic can be processed and reprocessed by applications that are connected to the Kafka system. Records can essentially be described as byte arrays that are capable of storing objects in any format. An individual record will have 2 mandatory attributes -the Key and the Value and 2 optional attributes -the Timestamp and the Header.
Apache Zookeeper and Kafka
Apache Zookeeper is a software that monitors and maintains order within a Kafka system and behaves as a centralized, distributed coordination service for the Kafka Cluster. It maintains data about configuration and naming and is responsible for synchronization within all the distributed systems. Apache Zookeeper tracks Kafka cluster node statuses, Kafka messages, partitions, and topics among other things. Apache Zookeeper enables multiple clients to do reads and writes concurrently, to issue updates and act as a shared registry within the system. Apache ZooKeeper is integral to the development of distributed applications. It is used by Apache Hadoop, HBase and other platforms for functions like co-ordination of nodes, configuration management, leader election etc.
Kafka Zookeeper Synergy and Apache Zookeeper Use Cases
Apache Zookeeper co-ordinates the Kafka Cluster. Kafka needs Zookeeper to be installed before it can be used in production. This is essential even if the system consists of a single broker, topic, and partition. Basically, Zookeeper has five use cases – electing a controller, cluster membership, configuration of topics, access control lists (ACLs) and monitoring quotas. These are some Apache Zookeeper Use Cases:
Apache Zookeeper elects a Kafka Controller
The Kafka Controller is the Broker or Server that maintains the leader/follower relationship among the partitions. Every Kafka cluster has only one Controller. In the event of a node shutting down, it is the Controller’s job to ensure other replicas assume responsibility as partition leaders to replace the partition leaders within the node that is shutting down.
Zookeeper Software keeps a list of Kafka Cluster Members
Apache Zookeeper functions as a registry and keeps a note of all the active brokers on a Kafka cluster.
Apache Zookeeper maintains Configuration of Topics
The Zookeeper software keeps a record of all topic configurations including a topics list, number of topic partitions for individual topics, overrides for topic configurations, preferred leader nodes and replica locations among other things.
Zookeeper Software maintains Access Control Lists or ACLs
The ACLs or Access Control Lists for all topics are also kept by the Zookeeper software. Details like read/write permissions for every topic, list of Consumer groups, group members and the latest offset individual consumer groups have got from the partition are all available.
Apache Zookeeper keeps tabs on Client Quotas
Apache Zookeeper can access the amount of data each client has permission to read or write.
Installing Kafka – some steps
Installation of Apache Kafka on a Windows OS
Prerequisites: Need to have Java installed before installing Kafka.
JRE Server Download: http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html
Kafka Installation – files required
The following files will need to be downloaded for Kafka Installation:
- ZooKeeper Download: http://zookeeper.apache.org/releases.html
- Kafka Download: http://kafka.apache.org/downloads.html
Install Apache ZooKeeper
- Download and extract Apache ZooKeeper from the link above.
- Go to the ZooKeeper config directory, Change the dataDir path from “dataDir=/tmp/zookeeper” to “:\zookeeper-3.6.3\data” in the zoo_sample.cfg file. Please note the Zookeeper folder name might differ as per the downloaded version.
- Set up System Environment Variables, add new “ZOOKEEPER_HOME = C:\zookeeper-3.6.3”.
- Edit the System Variable named Path and add ;%ZOOKEEPER_HOME%\bin;.
- From cmd run – “zkserver”. Now ZooKeeper is up and running on port default port 2181, which can be changed in the zoo_sample.cfg file.
Install Kafka
- Download and extract Apache Kafka from the link above.
- In the Kafka config directory. Change log.dir path from “log.dirs=/tmp/kafka-logs” to “C:\kafka-3.0.0\kafka-logs” in the server.properties. Please note the Kafka folder name might differ as per the downloaded version.
- In case ZooKeeper is running on a different machine, then edit these properties of server.properties
## Here we need to define the private IP of server
listeners = PLAINTEXT://172.31.33.3:9092## Here we need to define the Public IP of server}
advertised.listeners=PLAINTEXT://35.164.149.91:9092 - Add below properties in server.properties
advertised.host.name=172.31.33.3
advertised.port=9092 - Kafka runs on default port 9092 and connects to ZooKeeper’s default port, 2181.
Running a Kafka Server
Note: make sure Apache ZooKeeper is up and running before starting a Kafka server.
Otherwise, open cmd in C:\zookeeper-3.6.3\bin\windows and run Zookeeper server start batch > zookeeper-server-start.bat ../../config/zookeeper.properties
- From the Kafka installation directory C:\kafka-3.0.0\bin\windows, open cmd and run the command below.
>kafka-server-start.bat ../../config/server.properties. - Now Kafka Server is up and running, it’s time to create new Kafka Topics to store messages.
Create Kafka Topics
- Create a new Topic like my_new_topic.
- From C:\kafka-3.0.0\bin\windows open cmd and run below command:
>kafka-topics.bat –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic my_new_topic
Useful Commands for Kafka Installation
- Open a new command prompt in the location to view a list of Topics.C:\kafka-3.0.0\bin\windows>kafka-topics.bat –list –zookeeper localhost:2181
- Producer and Consumer commands for testing messages:>kafka-console-producer.bat –broker-list localhost:9092 –topic my_new_topic>kafka-console-consumer.bat –bootstrap-server localhost:9092 –topic my_new_topic (above Kafka version >2.0)
Kafka Connectors
How does one connect Kafka with external systems? Kafka Connect is the framework that connects databases, search indexes, file systems and key-value stores to Kafka with ready-to-use components called Kafka Connectors. Kafka connectors can deliver data from external systems to Kafka topics and deliver data from Kafka topics to external systems. Change Data Capture Types and CDC Automation
Kafka Connectors: Source Connectors and Sink Connectors
Kafka Source Connectors
A Kafka Source Connector aggregates data from source systems like databases, streams, or message brokers. A source connector can also collect metrics from application servers into Kafka topics for stream processing in near real-time. How to Make PostgreSQL CDC to Kafka Easy (2 Methods)
Kafka Sink Connectors
A Kafka Sink Connector exports data from Kafka topics into other systems. These could be popular databases like Oracle, SQL Server, SAP, or indexes such as Elasticsearch, batch systems like Hadoop, cloud platforms like Snowflake, Amazon S3, Redshift, Azure Synapse Databricks, Teradata, Google BigQuery, SQL Server, PostgresSQL and ADLS Gen2 etc.
BryteFlow as a Kafka Connector
BryteFlow can replicate data to Kafka automatically using log-based CDC (Change Data Capture) with very low latency and minimal impact on source. It can serve as both – a Source Connector and Sink Connector getting data into Kafka and delivering data from Kafka to external systems. BryteFlow Ingest is optimized for Kafka replication and is 6x faster than GoldenGate, delivering ready-to-use data at approx. a million rows in 30 seconds. See how BryteFlow Works
More on CDC Replication:
SQL Server CDC for real time SQL Server Replication
Oracle Change Data Capture (CDC): 13 Things to know
Kafka CDC and Oracle to Kafka CDC Methods
No Code Kafka stream processing
Using Kafka usually involves a lot of coding and development resources. With BryteFlow however, a Cloud-native replication tool, you can ingest data to Kafka from multiple sources like SAP, Oracle, SQL Server, Postgres, MySQL and IOT devices and Web applications. BryteFlow can also extract SAP data at application level with business logic intact. All this through a user-friendly graphical interface and without any coding. Debezium CDC Explained and a Great Alternative CDC Tool
Setting up BryteFlow for Kafka
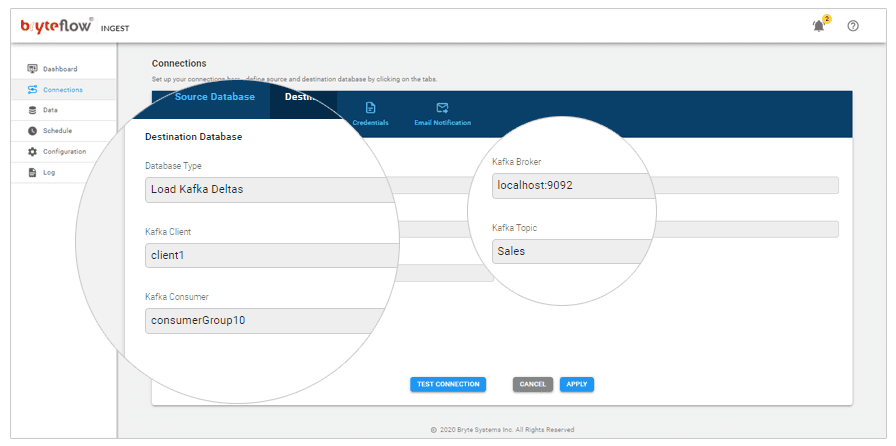
The screenshot is of BryteFlow Ingest and these are the options you need to select to set up a connection to Kafka.
Database Type: Load Kafka Deltas
Kafka Broker: Kafka Host server details
Kafka Client: Client1
Kafka Topic: Can be given direct Topic name or %s%t (Schema and table prefix)



