
SQL Server Change Data Capture (CDC) for real-time SQL Server Replication
This blog deals with SQL Server CDC, what it is, SQL CDC pros and cons, how to enable SQL Server CDC step by step, tips to improve SQL Server CDC performance, and why you should consider automated SQL Server CDC from BryteFlow.
Quick Links:
- What is SQL Server CDC?
- SQL CDC is an integral part of SQL Server replication
- How to enable CDC in SQL Server – step by step
- SQL Server Change Data Capture: Pros and Cons
- SQL Server CDC Performance: Tips to make it better
- SQL Server CDC with BryteFlow: No Code and Automated
- SQL Server CDC from Multi-Tenant Databases to the Cloud Data Warehouse
- SQL Server CDC Kafka – Our New Offering
What is SQL Server CDC?
SQL Server Change Data Capture or CDC is a way to capture all changes made to a Microsoft SQL Server database. Any inserts, updates or deletes made to any of the tables made in a specified time window are captured. Changes to the table structures are also captured, making this information available for SQL Server replication purposes. CDC (change data capture) reads the transaction logs to find data changes and records the changes in a separate table or database. This has a small overhead on server resources, it has no impact on the tables themselves. There are no locks, reads, or anything to block or slow down transactions unlike SQL Server Change tracking. Learn how to get SQL Server to Snowflake in 4 Easy Steps
SQL CDC is an integral part of SQL Server replication
When data needs to be transferred or replicated to data lakes or data warehouses whether to S3, Redshift, Azure Synapse, SQL Server, Databricks, PostgresSQL, BigQuery or Snowflake from a SQL Server database, the SQL CDC functionality is especially useful as it helps in replicating incremental data efficiently, so that the data lake/ warehouse is always up to date and is a centralized place for data access from different SQL Server repositories. SQL Server vs Postgres – A Step-by-Step Migration Journey
SQL Server is a relational database management system developed by Microsoft. Its primary function is to store and retrieve data efficiently and is generally used by applications for data storage and retrieval. SQL Server versions 2008 onwards support Change Data Capture or CDC.
Learn about migration from Oracle to SQL Server
SQL Server Change Data Capture or CDC- points to note:
- You need sysadmin privileges to turn this functionality on. Data Migration 101
- Web, Express and Standard editions of SQL Server do not support this functionality SQL Server to Databricks (Easy Migration Method)
- You need to enable CDC at database level AND at the table level for all tables that need to be tracked Debezium CDC Explained
- You need to start the SQL Server Agent. Change Data Capture Types and CDC Automation
These steps are explained in depth below:
How to enable CDC in SQL Server – step by step
To enable Change Data Capture (CDC)
1. At DB level:
Use <databasename>;
EXEC sys.sp_cdc_enable_db;
For Example:
Use Adventureworks2019;
EXEC sys.sp_cdc_enable_db;
To enable SQL Change Data Capture on a Table in SQL Server
2. At table level:
USE <databasename>
GO
EXEC sys.sp_cdc_enable_table
@source_schema = ‘<schema_name>’,
@source_name = ‘<table_name>’,
@role_name = null,
@supports_net_changes = 0;
For Example:
USE Adventureworks2019
GO
EXEC sys.sp_cdc_enable_table
@source_schema = ‘dbo’,
@source_name = ‘DimCustomer’,
@role_name = null,
@supports_net_changes = 0;
How to check if CDC is enabled on a table in SQL Server
1. Check if CDC has been enabled at database level
USE master
GO
select name, is_cdc_enabled
from sys.databases
where name = ‘<databasename>’
GO
For example:
USE Adventureworks2019
GO
select name, is_cdc_enabled
from sys.databases where name = ‘Adventureworks2019’
GO
Results:
| name | is_cdc_enabled |
| Adventureworks2019 | 1 |
If is_cdc_enabled is 0 then CDC is not enabled for the database
If is_cdc_enabled is 1 then CDC is already enabled for the database name
2. Check if CDC is enabled at the table level
USE databasename
GO
select name,type,type_desc,is_tracked_by_cdc
from sys.tables
where name = ‘<table_name>’
GO
For example:
USE Adventureworks2019
GO
select name,type,type_desc,is_tracked_by_cdc
from sys.tables
where name = ‘DimCustomer’
GO
Results:
| name | type | type_desc | is_tracked_by_cdc |
| DimCustomer | U | USER_TABLE | 1 |
If is_tracked_by_cdc = 1 then CDC is enabled for the table
If is_tracked_by_cdc = 0 then CDC is not enabled for the table
3. Check if the SQL Server Agent has been started
Use Microsoft configuration Manager to turn on the SQL Server Agent.
The SQL Server Agent should be running.
1. To start this process on your SQL Server, launch SQL Server Configuration Manager.
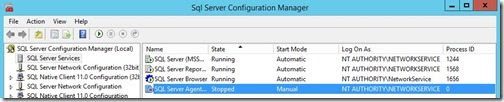
2. Right-click the SQL Server Agentservice and click Properties.
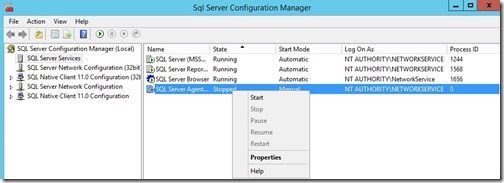
3. On the Properties Window, select an appropriate account. Here we are using the Local System account as an example. Then click on the Service tab.
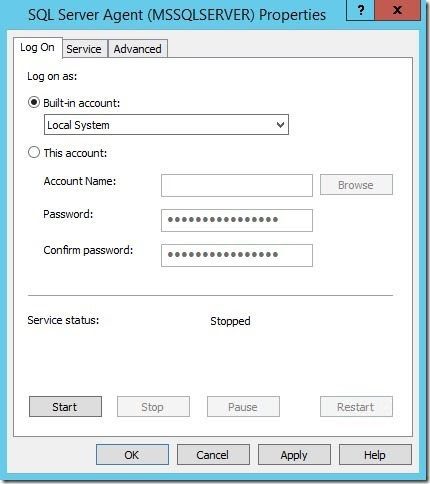
4. Change the Start Mode to Automatic and then click OK to close the window.
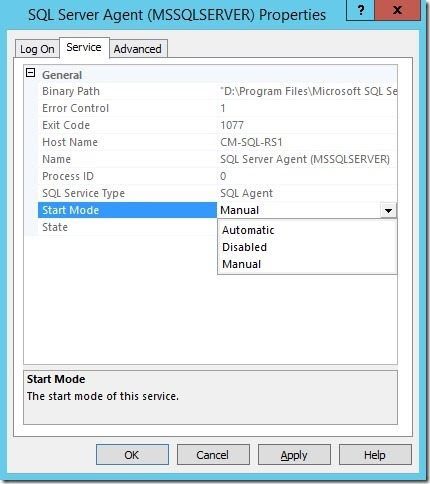
5. Right-click the SQL Server Agentservice and click Start.
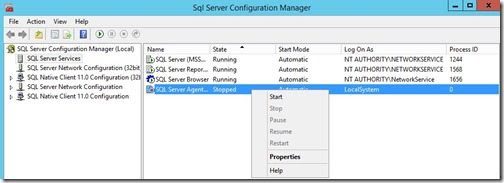
6. With that last step completed, the SQL Server Agentservice is ready to be used.
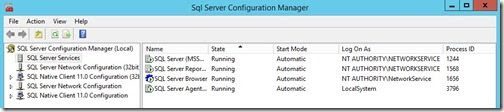
SQL Server Change Data Capture: Pros and Cons
Challenges of SQL Server CDC
- A limitation that we see with the SQL Server Change Data Capture functionality is that it uses I/O and has a small overhead on server resources; however, it has no impact on the tables themselves. There are no locks, reads, or anything to block or slow down transactions. There are several other mechanisms that support real-time data replication from SQL Server. When the underlying tables have large volumes of DML activity, SQL Server CDC may not be the optimum solution. An Alternative to Matillion and Fivetran for SQL Server to Snowflake Migration
- It is harder to set up than other mechanisms and may need some on-going intervention by the DBAs for transaction logs for transactional replication. 6 reasons to automate your data pipeline
- Also CDC functionality is not supported by Web, Express and Standard editions of SQL Server Postgres CDC (6 Easy Methods to Capture Data Changes)
Benefits of SQL Server CDC
- The benefit with SQL Server Change Data Capture is that most replication mechanisms from SQL Server require the tables to have a primary key. CDC will support tables without a primary key and this is the use case it is most useful for, as incremental data and real-time replication can be achieved without primary keys on the tables to be replicated. SQL Server to Snowflake in 4 Easy Steps
- The CDC mechanism can be used for Always On Availability Groups on SQL Server as CDC data is replicated to the replicas. The Easy Way to CDC from Multi-Tenant Databases
SQL Server Change Data Capture Limitations (Challenges with custom coding)
- Though the native SQL Server CDC functionality helps to capture changes, there is significant coding to be done, to capture these changes and use them for SQL replication to a Data Warehouse or Data Lake. SQL Server to Snowflake in 4 Easy Steps
- Not only does reliability and robustness need to be catered for but on-going maintenance, data issues and handling new tables and data types becomes an on-going issue for enterprises. SQL Server vs Postgres – A Step-by-Step Migration Journey
- The alerting and monitoring solution needs to be hand coded as well, and when you look at the different components required to get this working, a hand coded solution does not offer quick time to value and can be expensive to develop and maintain. SQL Server to Databricks (Easy Migration Method)
SQL Server CDC Performance: Tips to make it better
The SQL Server Change Data Capture process is an effective way to capture and deliver changes from a set of tables. You can adopt these fine-tuning tips to increase SQL Server CDC performance by tweaking allowable latency, workload characteristics, and system I/O usage.
Using Scan Job Parameters to improve SQL Server CDC performance
sp_cdc_enable_table – select only columns you need with @captured_column_list parameter
Tweaking and tuning the scan job parameters, sys.sp_cdc_enable_table parameters can improve change data capture performance while processing remarkably. Limit the columns needed for SQL CDC to only the columns you actually need to monitor. You can specify @captured_column_list parameter in sys.sp_cdc_enable_table. Think about the data components you really are interested in and whose changes you need to capture while enabling CDC on a table, then specify only those columns to vastly improve SQL CDC performance. The fewer the columns the better your CDC performance. SQL Server to Databricks (Easy Migration Method)
Set the @supports_net_changes parameter
Another factor that weighs on SQL CDC performance is the @supports_net_changes parameter in sys.sp_cdc_enable_table. When the @supports_net_changes is set to 1, an extra non-clustered index will be created on the change table, creating a net changes query function. The maintenance of this index can lower SQL change data capture performance. If support for net changes is not required, set @supports_net_changes to 0.
Increase Maxscans and/or maxtrans for lower latency
When workload cannot be matched by CDC using default parameters, or latency reaches too high a level, try increasing maxscans and/or maxtrans by a factor of 10 or you can cut down the polling interval to 1 and see if that works. Increase maxtrans further if latency is still high but track query performance, workload, and latency for change tables carefully. In cases where SQL Server CDC can keep up with workload, latency should not be much higher than the polling interval. Successful Data Ingestion (What You Need to Know)
When implementing a SQL Server CDC solution, workload characteristics must be given due attention. Points to ponder are INSERT/DELETE vs. UPDATE and about how the DML operation will affect one row per transaction or multiple rows.
INSERT/DELETE vs. UPDATE – how many rows does the DML operation create per transaction?
For e.g., one INSERT creates one row in the change table during SQL Server CDC, but one UPDATE will insert two rows in the change table. If a row is inserted into a table and immediately updated to fill missing fields possibly through an INSERT trigger, three rows will be created and need to be written to the change table instead of one row for each insert. It is best to avoid using Change Data Capture to capture deltas for tables that have large updates often and avoid situations where a row has to be updated immediately after an insert.
Tip: Did you know BryteFlow’s SQL Server Change Data Capture process is completely automated (no coding of any sort) and Upserts too are automated? This means when change data in inserted into the table, it merges automatically with existing data, additional rows will not be created, and no third-party tool is required. You can also opt for SQL Server Change Tracking by BryteFlow to capture changes on tables that have large updates often, it is very sparing of resources.
Run Cleanup job efficiently to remove delete entries
Less stored procedure parameter sp_MScdc_cleanup_job is run to begin the cleanup job of removing the delete entries. The stored procedure extracts the configured retention and threshold values for the cleanup job from msdb.dbo.cdc_jobs. The configurable threshold value represents the highest number of delete entries that can be deleted through a single statement. For large thresholds, there may be a lock escalation that increases application response time and latency of the CDC job, it is therefore advisable to start cleanup during non-peak hours or when there is no active workload. Change Data Capture Types, Advantages and Automating CDC
Monitor transaction log files storage
Another factor that can affect SQL Server Change Data Capture is the transaction log I/O subsystem. Log file I/O increases a lot when CDC is enabled in a database and the log records remain active till the CDC processes them. This can give rise to increasing latency since the log space cannot be reused till the CDC processing is done. In high latency environments, the log disk can grow and become full, and CDC cannot process further transactions since CDC writes to changes tables when they are logged operations. The solution is to add another log file on a separate disk.
Tip: BryteFlow’s CDC is extremely low impact and BryteFlow supports both SQL Server CDC and SQL Server Change Tracking. The SQL Server Change Tracking mechanism is even more light-weight than CDC and is ideal for large databases that are frequently updated.
Differentiate between the application data and the change data
As a rule, having the change table on the same file group as the application table should not matter, but the case of heavily loaded I/O subsystems, placing change tables in a file group on different physical disks can enhance SQL Server CDC performance.
In order to maintain the small size of the PRIMARY file group and to have a differentiation between application data and the change data, it is recommended you specify @filegroup_name in sys.sp_cdc_enable_table as a different file group from PRIMARY.
Keep the table cdc.lsn_time_mapping on a separate file group
Apart from change tables, the table cdc.lsn_time_mapping can also become quite large as a result of many I/O operations. It is created in the default file group every time sys.sp_cdc_enable_db is run on a database. Before you execute sys.sp_cdc_enable_db, ensure that change data capture metadata and especially cdc.lsn_time_mapping are kept on a file group other than PRIMARY. The default file group can be changed back after you create the SQL change data capture metadata tables.
Tip: BryteFlow SQL Server CDC provides automated metadata, no coding needed. Successful Data Ingestion (What You Need to Know)
SQL Server CDC with BryteFlow: No Code and Automated
- BryteFlow is a GUI based tool that helps to capture the changes from SQL Server with CDC and several other mechanisms like SQL Server Change Tracking
- It is a no-code way of transferring your data to various data warehouses and data lakes. SQL Server vs Postgres – A Step-by-Step Migration Journey
- It creates the schemas automatically on the target with the optimum data types and implements best practices for the target. Source to Target Mapping Guide (What, Why, How)
- Data replicated to the target can be held automatically with SCD type 2 history if configured. SQL Server CDC to Databricks
- Automated, sophisticated data reconciliation – this is another enterprise grade feature not ordinarily offered in the market.
- BryteFlow supports SQL Server Always ON configuration. SQL Server to Databricks (Easy Migration Method)
- BryteFlow SQL Server replication works whether Primary Keys are available or not. SQL Server CDC To Kafka (Unbelievably Easy New Connector)
- BryteFlow offers enterprise grade SQL Server replication and watertight security for on-premise installations, on the cloud or using a hybrid approach. Successful Data Ingestion (What You Need to Know)
SQL Server CDC from Multi-Tenant Databases to the Cloud Data Warehouse
Loading and merging large volumes of data from multi-tenant SQL Server databases can be challenging, especially when near real-time replication for Analytics is required. There is significant coding to be done to handle the number of databases, number of tables in each database and to deal with the schema evolution not being in sync across all the various tenants. An Alternative to Matillion and Fivetran for SQL Server to Snowflake Migration
Further high volumes of data can cause bottlenecks and slowdowns (especially when a large amount of data gets loaded) or even deadlocked transactions. Cost of computing resources, memory and disk also become a challenge and add to the overall cost and complexity of the solution significantly. SQL Server CDC To Kafka (Unbelievably Easy New Connector)
However, you don’t need to spend time on making your code more efficient to resolve these issues. BryteFlow can automate CDC from multi-tenant SQL databases easily. BryteFlow provides a massively scalable, secure, no-code solution that loads terabytes of data in near real-time, from multi-tenant SQL Server implementations using Change Data Capture (CDC) or Change Tracking. It merges and delivers complete, ready-for-analytics data that can be queried immediately with BI tools of choice. It enables data from multi-tenant SQL databases to be defined and tagged with the Tenant Identifier or Database ID from where the record originated, so using this data becomes simple. BryteFlow for SQL Server Replication
SQL Server CDC Kafka – Our New Offering
BryteFlow now delivers data from SQL Server to Kafka using CDC. There is a first full one-time load into Topics after which changes in the SQL database are delivered in real-time using Change Data Capture with high throughput and low latency. BryteFlow as a SQL Server Kafka connector provides automated partitioning and compression for a faster, more efficient process and configurable parallel extraction and loading. Data is delivered in JSON format to Kafka and BryteFlow populates the schema registry automatically. It supports SQL Server CDC to Kafka from all SQL Server versions and editions. The simple point-and-click interface is user-friendly and there is NO coding for any process.
Conclusion
In contrast to the coding-intensive approach, you get easy, real-time SQL Server replication with CDC using BryteFlow. Just point and click to set up. Replicate large volumes of data easily with parallel threaded initial sync and partitioning followed by delta sync. Tables are created automatically with data upserted or with SCD Type 2 history. You get multiple CDC options appropriate for the SQL Server version or edition you are using (all versions/editions supported). Get ready to use data at the destination whether S3, Redshift, Snowflake, Azure Synapse, ADLS Gen2, Databricks, PostgresSQL, Kafka or SQL Server.


