
This blog examines the reasons, benefits, challenges, and methods of moving data from SAP to AWS, especially with a focus on SAP to S3 migration. It looks at the SAP HANA database and at BryteFlow as a no-code, CDC tool to move data in real-time from SAP sources to AWS and S3.
Quick Links
- Why move data from SAP to AWS (and S3)?
- About the SAP HANA Database
- Benefits of moving data from SAP to AWS
- Challenges in moving from SAP to AWS
- SAP Extraction and Replication to S3 – Some Patterns
- Enabling SAP S3 Integration: The Methods
- About the BryteFlow SAP Data Lake Builder
- Highlights of the BryteFlow SAP Data Lake Builder
- Case Studies for integrating SAP Data on AWS
Why move data from SAP to AWS (and S3)?
Transferring data from SAP to AWS and specifically from SAP to S3, allows you to benefit from the added flexibility, scalability, and cost-efficiencies of the AWS Cloud. In recent years, SAP has made significant strides in enhancing its data intelligence and analytics suite to meet evolving customer needs. Notably, SAP HANA’s in-memory databases are renowned for their scalability, multi-model data management, and embedded machine learning capabilities. However, as modern enterprises increasingly adopt hybrid architectures – combining multiple ERP systems and enterprise platforms with hyperscaler Clouds via APIs – it is prudent for organizations to use centralized, intelligent Cloud storage solutions like Amazon S3 (Amazon Simple Storage Service). Data Integration on Amazon S3
Moving SAP data to S3 enables integration with data from non-SAP sources
By integrating SAP HANA data landscapes into the S3 pool along with data from other sources, enterprises can seamlessly conduct end-to-end analytics, including visualizations, decision insights, and revenue analysis. Getting SAP data to S3 will also allow for the processing of data using native AWS tools like AWS Glue, Lambda, SageMaker, Kinesis, and Redshift.
Amazon S3 provides centralized, smart storage
Businesses can leverage Amazon S3 as an efficient storage layer for their structured and unstructured SAP dataflows, while relying on SAP HANA for intelligent analytics. SAP ERP applications as a rule, generate a lot of documents via business processes like purchase orders, invoices, sales orders etc. Storing these on your main instance SAP database would impact the performance of the SAP applications. In this case too, it would be sensible to set up a content repository on S3, which is SAP-certified. How to Carry Out a Successful SAP Cloud Migration
About the SAP HANA Database
Launched by SAP in 2010, SAP HANA is a unique multi-model database. SAP HANA is an acronym for (SAP High Performance Analytic Appliance) The outstanding feature of SAP HANA is that data is stored in its memory instead of being stored on a disk. This means it can process data many times faster than disk-based systems. The columnar in-memory SAP HANA database enables companies to process huge volumes of data with very low latency and to query data instantly. It allows for execution of advanced analytics in parallel with high-speed transactions within a single system. Since SAP HANA stores data in the primary memory, it combines online analytical processing (OLAP) and online transactional processing (OLTP) to deliver blazingly fast performance, much faster than most DBMS systems. SAP’s modern ERP system SAP S/4 HANA runs on the SAP HANA database.5 Ways to extract data from SAP S/4 HANA
SAP HANA acts as an Application Server
However, SAP HANA goes beyond the definition of a database. Besides functioning as a database server, storing and presenting data requested by applications, it also offers data integration and analytics for structured and unstructured data. It plays a role as an application server, enabling companies to build smart applications using in-memory computing, real-time data, and machine learning technology. SAP HANA can be deployed on-premise, in the Cloud or even as a hybrid implementation, and these features are available across both. Thus, SAP HANA enables you to access multiple types of data from one system, simplifying IT processes and making enterprises truly agile and digital. Create CDS Views in SAP HANA
SAP HANA is versatile and can integrate data from a variety of organizational sources:
SAP HANA can aggregate data from different sources including conventional business documents like spreadsheets and contracts, user interfaces like web forms, emails, surveys, and other customer interactions, from mobile data and IoT data from sensors used in business operations, including transport, warehousing, purchase, inventory and offices. All the data can be integrated and analyzed using Machine Learning and AI to achieve deep insights for effective business decisions. Easy SAP Snowflake Integration
Benefits of moving data from SAP to AWS
SAP and AWS have valuable synergies and a long-standing relationship. AWS is a SAP-certified Cloud platform for running SAP workloads. AWS supports SAP HANA deployments with various services and infrastructure. This includes Amazon EC2 instances optimized for SAP HANA workloads, Amazon S3 (Simple Storage Service) for scalable and affordable storage, and Amazon EBS (Elastic Block Store) for high-performance storage. RISE with SAP (Everything You Need to Know)
Other AWS services for managing SAP HANA on AWS, include AWS CloudFormation, AWS Management Console, AWS SDKs and AWS CLI. You can also find security and compliance features like AWS Identity and Access Management (IAM) and AWS Key Management Service (KMS).
Here we discuss some benefits you can get by moving SAP to AWS.
Moving from SAP to AWS ensures reduction of costs
By moving SAP data to AWS Cloud, organizations can save on infrastructure management and increase ROI. Organizations save on hardware, software, implementation, and upgrade costs. It has been reported by SAP that AWS hosting can help you save 59-71% of costs over a five-year period. SAP HANA to Snowflake (2 Easy Ways)
SAP AWS Migration provides high scalability
Unlike on-premise data centers, AWS Cloud is immensely scalable. According to requirement you can scale storage, compute, databases, and servers up or down to cater to increased demand or reduce costs respectively. You do not have to buy infrastructure, only rent it, and you pay only for actual consumption. How to Carry Out a Successful SAP Cloud Migration
Migrating from SAP to AWS means you can benefit from robust infrastructure
Amazon infrastructure is widespread covering 25 regions and 80 availability zones. This means it is easy to create applications and locate them in close geographical proximity with customers and to align them with required local regulatory and compliance requirements.
You get access to AWS Tools and Services when you move from SAP to AWS
AWS has several innovative Amazon Web Services that can help accomplish a lot of objectives. For e.g. Amazon Redshift for Analytics, AWS SageMaker for Machine Learning, Amazon Cloudwatch for monitoring, Amazon S3 for affordable storage, Amazon EC2 for computing, Amazon Kinesis for processing real-time streaming data etc. You can connect to these services easily and access the services with a small bit of coding. A point to note, is that our CDC tool BryteFlow integrates seamlessly with AWS Services, and you can deploy them automatically, with just a couple of clicks. AWS ETL with BryteFlow
Moving SAP data to AWS allows it to be integrated with non-SAP data
Modern organizations have multiple data implementations with heterogenous data sources across different Clouds. Integrating all the data from SAP and non-SAP sources allows organizations to use it for advanced analytics and Machine Learning models and derive valuable business insights. Create a data lake in minutes on S3
SAP data on AWS is highly secure
Data on AWS has 5-pronged security. AWS uses data encryption, security groups, data backup, identity and access management and logging of activity to safeguard data. It is a highly secure Cloud platform with 100% encryption capability across data storage services. Services like IAM (Identity and Access Management) take care of who can access the applications and manage policies and permissions. The AWS KMS (Key Management Service) enables creation and management of cryptographic keys across applications to secure data. CloudWatch monitors operational data while CloudTrail logs user activity in the account. Amazon GuardDuty detects threats by monitoring workloads for malicious activity. Moreover, AWS has over 90 security standards and compliance certifications.
Bringing SAP data to AWS promotes easy sharing of data
SAP implementations can be complex and lead to data silos. Moving SAP data to AWS means team members can easily access the data, share, and have real-time collaboration on documents and projects, irrespective of geographical constraints. SAP HANA to Snowflake (2 Easy Ways)
Challenges in moving from SAP to AWS
Here are some of the key challenges that crop up when migrating SAP to AWS.
Moving SAP to AWS needs a deep understanding of the current data environment
SAP systems are inherently complex. They often are customized to a high degree and have various dependencies owing to extensive integration with other enterprise applications. Transitioning such systems to the AWS Cloud will need a deep understanding of the entire application landscape and how the components interact. Simplifying SAP Data Integration
SAP to AWS transitioning needs to take into account interoperability
Legacy applications like SAP often have configurations that rely on integration with other applications and databases in the organization. These may be difficult to replicate in the AWS Cloud. Overcoming interoperability challenges and ensuring smooth integration can pose issues.
Ensuring Data Security and Compliance in the SAP to AWS move
Organizations prioritize security and compliance, particularly concerning sensitive data like financial, customer, and employee information. You need to validate that AWS can provide the needed security and adherence to industry standards and regulations while implementing strong security protocols to safeguard data. S3 Security Best Practices
The SAP to AWS move needs efficient cost management
Moving SAP to AWS offers long-term cost savings, but the migration itself can incur significant expenses. It’s essential for organizations to meticulously strategize, monitor, and control cloud expenses to prevent unforeseen costs. RISE with SAP (Everything You Need to Know)
SAP to AWS Transitioning needs a careful look at Licensing and Compliance
Managing SAP application licenses for AWS Cloud can be tricky and licensing agreements need to be looked at carefully, for organizations to stay compliant. Cost considerations loom large, particularly concerning industries with stringent regulations, posing challenges for adherence in public cloud environments. Did you know you can avoid expensive SAP licensing during data extraction with the BryteFlow SAP Data Lake Builder?
Minimizing Downtime during the SAP to AWS move
Ensuring uninterrupted business operations during cloud migration is vital. It’s essential to plan for backup and disaster recovery to prevent data loss or service interruptions. Automate SAP ETL
Addressing the Skill Gap when moving SAP to AWS
Moving SAP data to AWS demands specific skillsets in both SAP and AWS technologies. Companies might have to allocate resources towards training existing staff or recruiting professionals with expertise in this area to ensure a smooth migration process.
Moving SAP to AWS may require Integration with On-Premise Systems
In many organizations, there may be a hybrid Cloud setup with certain applications residing in the cloud and others on-premise. The transition of SAP to AWS will require integration with on-premise systems, to ensure smooth data transfer between the two environments.
Applications can face performance issues in moving from SAP to AWS
SAP applications fine-tuned for on-premise settings may encounter performance issues in the AWS Cloud due to variations in network latency, storage access, and resource allocation. Proper optimization is crucial to mitigate potential performance disruptions.
SAP Extraction and Replication to S3 – Some Patterns
There are several extraction and replication patterns to get data from SAP applications and databases to S3. SAP ERP (S/4HANA, ECC, CRM etc.) and SAP BW applications are largely the sources in most cases. Creating an SAP BW Extractor
SAP Extraction at Database Level
This mode extracts SAP data at database level. There are APN partner solutions that capture data being written to SAP transaction logs in the database. The data is transformed by the third-party tools, transformed, mapped, and stored in S3. The tools can also process SAP pool and cluster tables. Our own BryteFlow can extract data from SAP databases to S3, provided there is access to the underlying database. BryteFlow for SAP
For SAP HANA databases, Python support is available and native integration with AWS Glue and AWS Lambda via SAP HANA client libraries. SAP HANA Java Database Connectivity (JDBC) drivers can also be used for extraction. JDBC or Java Database Connectivity is a Java-based application programming interface (API) which has functions that allow Java applications to access a data model in a database. The SAP HANA client includes a dedicated JDBC interface. SAP HANA to Snowflake (2 Easy Ways)
Salient points for database-level extraction:
- Minimal impact on performance to the SAP database applications since data is extracted from transaction logs by third-party tools.
- Change data capture is available out-of-the box since it relies on the presence of database change logs.
- However, licenses such as runtime licenses pose an obstacle for customers to extract data directly from the database.
- SAP application logic (typically present in the SAP ABAP layer) is not retained with this extraction pattern, so re-mapping may be required on target. If there are changes in the SAP application model, additional effort may be required to maintain the transformation on target.
SAP Extraction at Application Level
Data extraction from SAP ERP applications enables pulling of business logic from the ABAP layer (where it resides). Though the SAP HANA database does have code pushdown capabilities where application logic is pushed down to the database layer, the ABAP stack can provide a point of entry for APIs to access the business logic. Data extraction from SAP ECC
SAP Data Services, an application-level extractor can extract data from SAP applications using integration frameworks in ABAP applications and use default connectors to store the data in S3. RFC SDK (Remote Function Call) libraries enable the extractors to natively connect with SAP applications and pull data from remote function modules, queries, tables, and views. SAP Data Services (also called SAP BODS) can install ABAP code in the SAP application and push data from it instead of pulling it.
HTTP access is supported for function modules and AWS Glue or Lambda can access them using HTTP. AWS Glue or Lambda can also use the SAP-published PyRFC library for native integration using RFC SDK. You can integrate SAP IDOCs with S3 using an HTTP push pattern.
Salient points for Extraction at Application Level
- Extractions can be done with business logic intact since the extraction is done at application level. RISE with SAP (Everything You Need to Know)
- Change Data Capture is not a default feature since not all SAP function modules or frameworks support CDC.
- Using AWS native services like AWS Glue or Lambda avoids the need for using third-party tools, hence reducing the cost of the implementation. However, there may be additional coding effort involved to connect HTTP or RFC integrations with SAP applications.
- Performance might have limitations as compared to database-level extraction, because of integration at application level. The performance of the SAP application servers may be impacted as well, due to the extra load caused by pulling of data via function modules and frameworks.
SAP Extraction with the Operational Data Provisioning Framework
The Operational Data Provisioning (ODP) framework is a consolidated technology for data provisioning and consumption and allows for data replication between SAP applications and SAP and non-SAP destinations via a Provider and Subscriber model. ODP can support full data extraction as well as incremental data capture using CDC through Operational Delta Queues. 2 Easy Methods for SAP Data Extraction using ODP and SAP OData
The Operational Data Provisioning (ODP) framework for data distribution provides a consolidated technology for data provisioning and consumption. Extracting the business logic is done using SAP DataSources, SAP Core Data Services Views (CDS Views), SAP HANA Information Views, or SAP Landscape Replication Server (SAP SLT). ODP functions as a data source for OData services, allowing for REST-based integrations with external applications.
Applications such as SAP Data Services and SAP Data Hub are capable of integrating with ODP, using native Remote Function Call (RFC) libraries. Non-SAP solutions like AWS Glue or Lambda can use HTTP to integrate with the SAP OData layer to get the data. Please note: BryteFlow SAP Data Lake Builder uses the ODP framework and OData Services to extract data from SAP applications with business logic intact and without coding.
Salient points for Extraction with ODP
- Extraction with ODP is done at the application layer so it allows for business logic for the extracted data to be retained.
- Data on target retains all customizations, table relationships and package configurations, cutting down on transformation effort.
- Operational Delta Queues support CDC. If required, micro batches for full data load are also supported via OData query parameters.
SAP Extraction using SAP Landscape Transformation Replication Server (SAP SLT)
SAP Landscape Transformation Replication Server (SLT) enables data replication from SAP applications – both near real-time and batch data replication. Data extraction in real-time is enabled by creation of database triggers in the SAP application source. Some SAP targets are supported by default by SAP SLT including SAP HANA, SAP BW, SAP Data Services, SAP Data Hub, along with some non-SAP databases including Microsoft SQL Server, Oracle, Sybase ASE etc. RISE with SAP (Everything You Need to Know)
Customers who need to replicate data from SAP to hitherto unsupported targets can do customized implementations using the Replicating Data Using SAP LT Replication Server SDK. In the case of getting data from SAP applications to S3, you can use AWS Glue to extract data from SAP SLT supported target databases into S3. You can also use APAP extensions (BADIs) to replicate data to S3 using the SAP SLT Replication Server SDK. Using HANA SLT Transformation Rule
Salient points for Extraction with SAP SLT
- It supports CDC and full data extraction with trigger-based extraction. This also applies to source tables that don’t have updated date and timestamp. SAP HANA to Snowflake (2 Easy Ways)
- You will need a good amount of custom coding in ABAP to integrate with SAP-unsupported targets.
- Will attract additional licensing expenses for SAP Data Hub, SAP Data Services, or other supported databases to move data to S3.
- Custom development effort in AWS Glue will be required when replicating from an SAP-supported database to S3.
- You may need to get an SAP SLT enterprise license for replication to non-SAP-supported targets.
Learn more about AWS mechanisms for moving SAP data to S3 here
Enabling SAP S3 Integration: The Methods
There are several ways to migrate SAP workloads to AWS, each with its own considerations. Here we will discuss each of them so you can select the one that aligns best with the requirements of your specific SAP workload.
- Using an SAP OData Service and ODP to load data from SAP to S3
- Methods offered by AWS for moving SAP workloads to AWS
- AWS Partner Solution: BryteFlow for No-Code CDC from SAP to S3
Method 1: Using SAP OData Service and ODP to load the data from SAP to S3
With this approach, you need to create an API using the SAP OData Service. The OData service, which is an XML file with metadata, can be accessed by any third-party tool to load the data to AWS S3. You will need SAP Gateway availability to use the OData protocol to extract and consume SAP data via RESTful APIs. OData is an Open Data Protocol that uses HTTPS and enables secure Internet connectivity. It supports a hybrid, multi-Cloud framework and can scale with increasing data volumes. SAP Gateway provides a wide variety of options to extract SAP data without being restricted by legacy protocols like IDOC or RFC. Learn More
If your ERP is the latest SAP S/4 HANA, you will have access to many ready-to-use OData services (2000+) to use for SAP data extraction. They are built to be used largely with the SAP Fiori interface. For high-volume extractions it is advisable to use the SAP BW Extractors through ODP since they have delta, monitoring, and troubleshooting features. With SAP BW extractors you may need less transformation effort on target since they provide application context. If your ERP is ECC 6.0 EHP7/8, you would have access to limited prebuilt OData services. In this case you can use SAP BW Extractors with ODP for SAP data extraction. How to create an SAP OData Service for SAP BW Extractors
Method 2: Methods offered by AWS for moving SAP workloads to AWS
We saw the design patterns earlier to move data from SAP to S3, here are some AWS offerings that can help in moving on-premise SAP workloads to AWS. However, Amazon AppFlow and AWS Partner solutions can move data from SAP Cloud sources to AWS as well.
SAP Rapid Migration Test Program
The SAP Rapid Migration Test Program offers a swift and secure method for transferring SAP systems to AWS. It includes a variety of tools, processes, and proven methodologies to migrate SAP systems to AWS fast. Incidentally the SAP Rapid Migration Test program is also called FAST, which stands for ‘Fast AWS and SAP Transformation’. SAP has developed it in collaboration with AWS to enable customers running SAP applications (SAP ECC and SAP Business Warehouse) on any databaseto migrate to SAP HANA or SAP ASE on AWS. It also features a Cloud-based testing environment to check whether the migration was successful. Learn more
AWS Migration Hub
The AWS Migration Hub serves as a centralized platform enabling customers to monitor their migration efforts. It offers a unified perspective of all AWS migration tools and services employed in the process, facilitating the tracking of each migration task and its status.
AWS Server Migration Service (SMS)
The AWS Server Migration Service (SMS) is an agentless service that facilitates the transfer of on-premise VMware virtual machines to AWS, streamlining the migration process. It offers a suite of tools and recommended strategies designed to assist customers in moving their on-premise SAP workloads onto the AWS platform. With AWS SMS you can automate, schedule, and monitor incremental data replications of the live server allowing you to manage large-scale server migrations easily.
AWS Snowball
AWS Snowball is a solution designed to assist clients in transferring high volumes of data to AWS. It features a physical device that customers can use to move their data from SAP to AWS and is particularly advantageous for moving extensive SAP databases. With AWS Snowball you can carry out large-scale migrations without storage capacity or compute power limitations. Even in environments with low connectivity, compute workloads can be run easily, and application performance accelerated. SAP HANA to Snowflake (2 Easy Ways)
Amazon AppFlow
Amazon AppFlow is an innovative fully managed AWS service that enables you to securely move data between SaaS applications like SAP, Salesforce, ServiceNow etc. and AWS services like Amazon S3 and Redshift with a few clicks only. It has bi-directional data flows. Amazon AppFlow has the Amazon AppFlow SAP OData connector that has the capability to get, create, and update records exposed by SAP S/4HANA and SAP on-premise systems through OData APIs. This way you can connect Amazon AppFlow to OData services including the ones that pull data from SAP applications using ODP. Learn more
AWS Partner Solutions for SAP
AWS collaborates with a variety of technology partners skilled in SAP migrations to AWS, offering migration services and tools tailored to assist customers in transferring their SAP workloads to the AWS platform. BryteFlow is an AWS Advanced Technology Partner with Data and Analytics Competency, Migration Competency and Public Sector Competency. It is also an SAP Partner. How to Carry Out a Successful SAP Cloud Migration
Method 3: AWS Partner Solution: BryteFlow – No-Code CDC for SAP to S3
The screenshots illustrate how easy and automated your SAP to S3 migration is with BryteFlow. We will now demonstrate how to use BryteFlow to deliver data from SAP to S3, step by step using Change Data Capture.
Prerequisites: Please ensure that all prerequisites have been met and all security and firewalls have been opened between all the components.
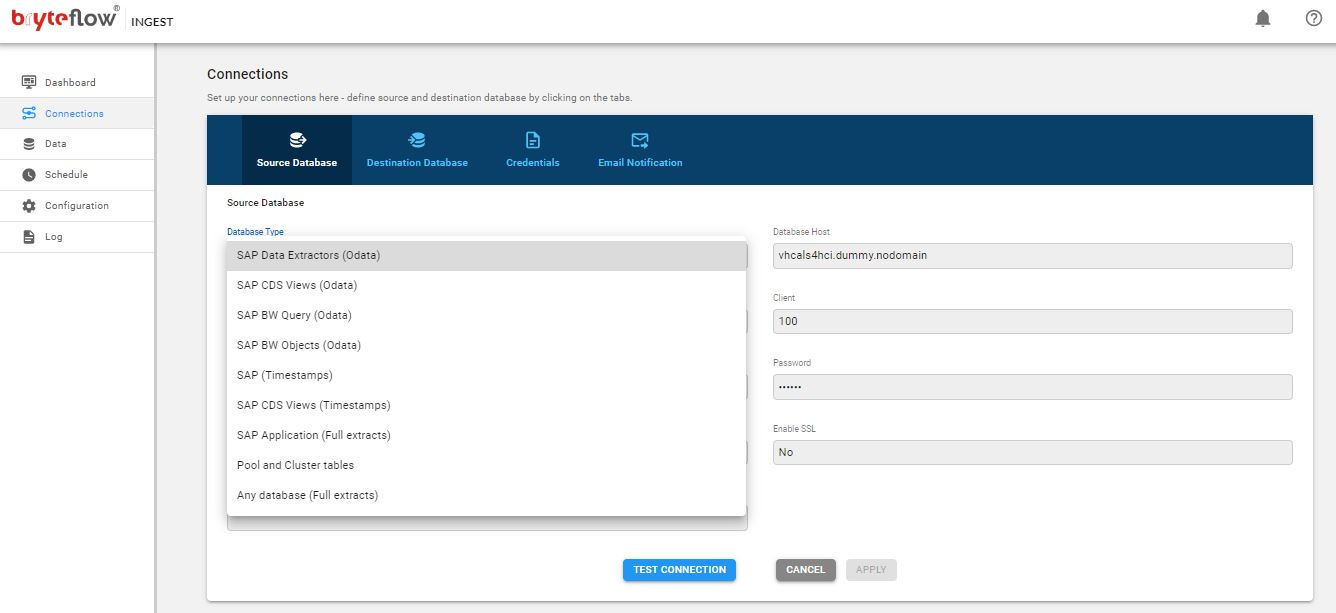
Step1: Selecting an SAP Connector and adding configuration details
The first step is to select an SAP connector for the SAP application. This screenshot shows all available connectors for BryteFlow SAP Data Lake Builder and the configuration to connect to the SAP Application host. The available connectors include SAP Data Extractors, SAP CDS Views, SAP BW Query, SAP BW Objects, SAP Application (Full Extracts), Pool and Cluster Tables, Any Database (Full Extracts), SAP (Timestamps). You can put in the configuration parameters to connect to the SAP Application host.
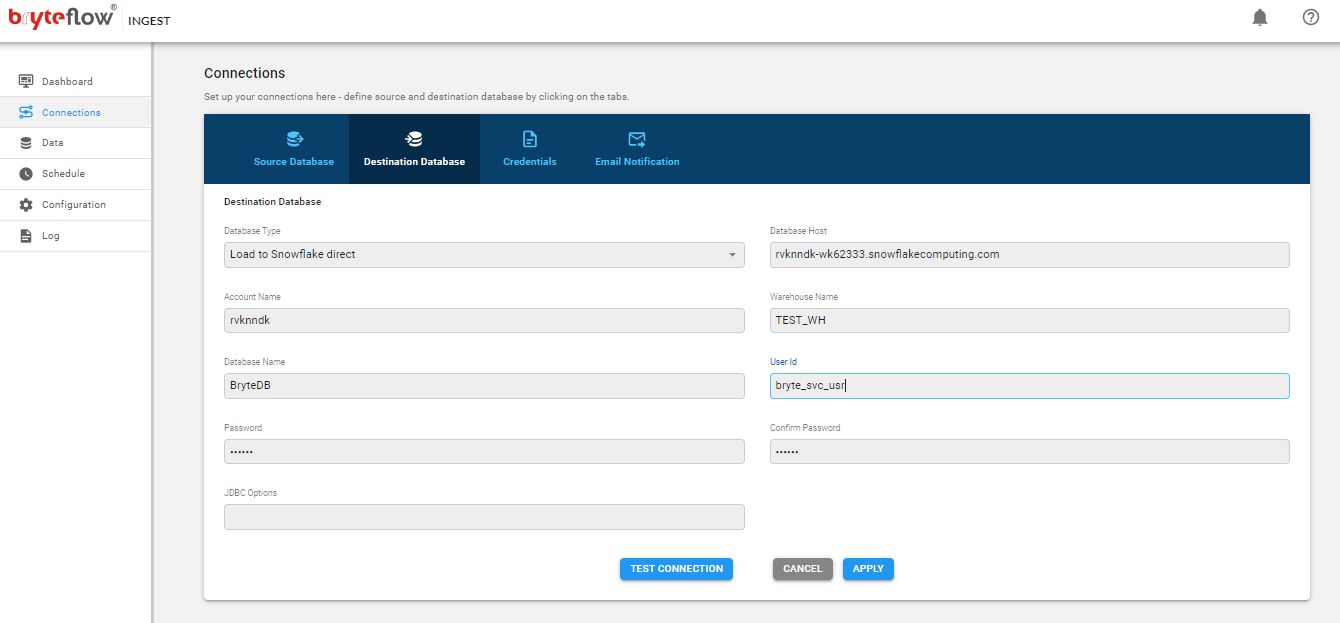
Step 2: Configuration of Amazon S3 Connector
This screenshot shows the configuration for Amazon S3 destination connector, and you need to put in the configuration details.
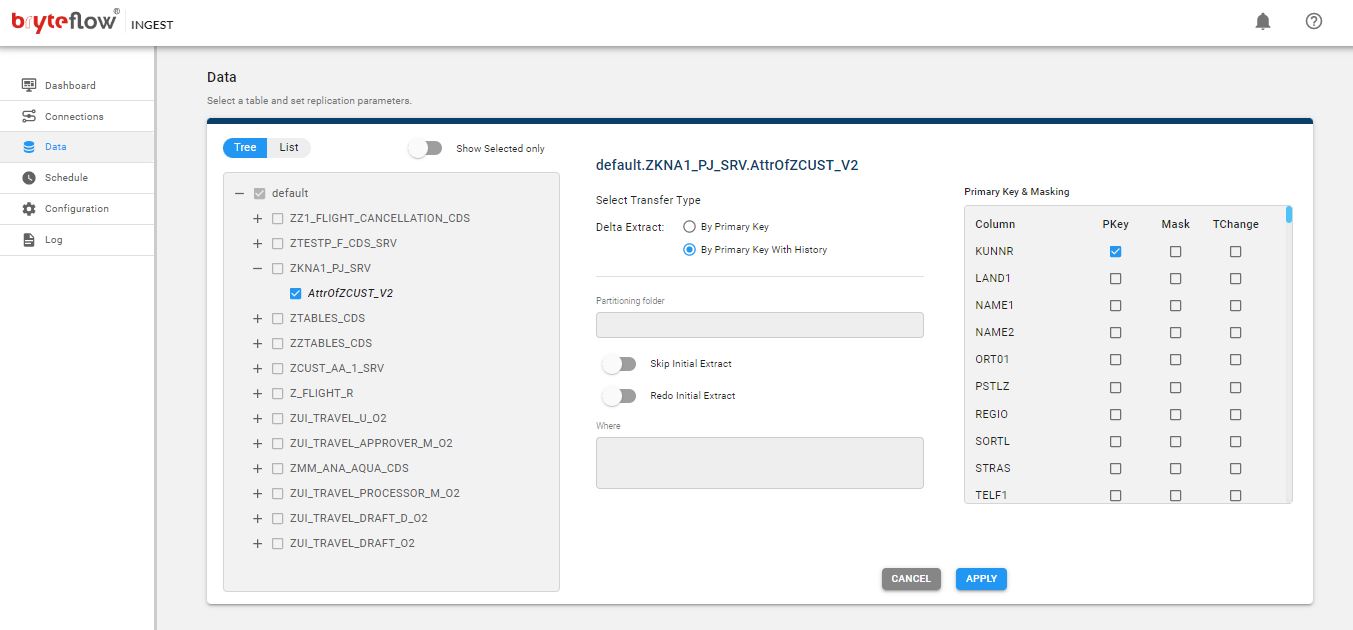
Step 3: Selecting the SAP Tables from OData Services from the SAP Application Object Catalog
This screenshot shows all available SAP OData Services from the SAP Application Object Catalog (IGWFND). You can select the tables you need to take to S3 from the SAP application and whether the delta extract will be with ‘Primary Key’ or ‘Primary Key with History’. Selecting the latter will enable you to maintain SCD Type 2 history. SAP HANA to Snowflake (2 Easy Ways)
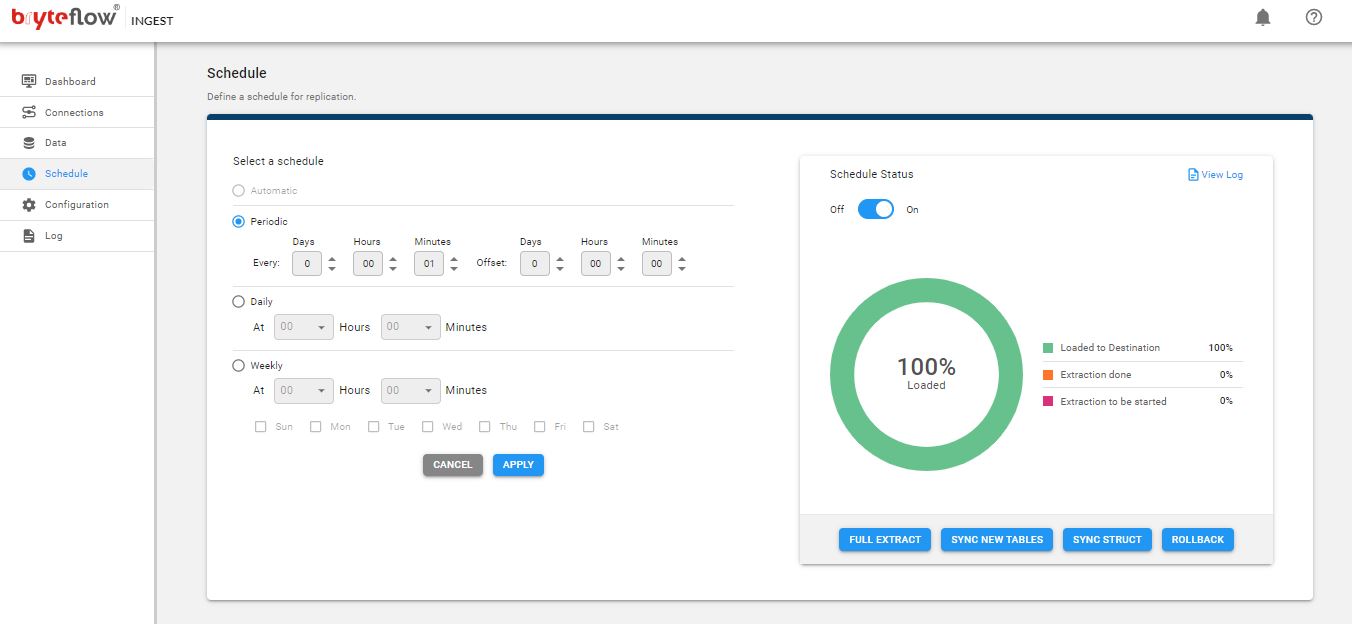
Step 4: Scheduling the Change Data Capture for SAP to S3 Pipeline
This screenshot shows schedule settings for the SAP to S3 pipeline. With the ‘Periodic’ schedule settings, you can select at what time the CDC pipeline should run and whether it should run hourly, daily or weekly. Select ‘Automatic’ if you need continuous extraction. The pipeline will run whenever there is a change at the SAP source, and it will deliver and merge the deltas with data on S3 providing Automated Upserts.
About the BryteFlow SAP Data Lake Builder
BryteFlow SAP Data Lake Builder is our no-code SAP ETL tool that seamlessly integrates with the AWS ecosystem. BryteFlow SAP Data Lake Builder extracts and replicates SAP data to on-premise and Cloud destinations on AWS, Azure and GCP such as Amazon S3, Redshift, Snowflake, Azure Synapse, ADLS Gen2, SQL Server, Databricks, PostgreSQL, Google BigQuery, and Kafka.The tool ETLs SAP data keeping business logic intact so you don’t need to recreate logic on destination.
BryteFlow SAP Data Lake Builder is ideal for moving high volume enterprise data fast, and achieves this by using parallel, multi-thread loading, smart partitioning and compression. It uses automated CDC (Change Data Capture) to deliver deltas, merging them with data automatically providing Automated Upserts. The CDC tool syncs data with source continually or as scheduled, delivering real-time, ready-to-use data with very high throughput (1,000,000 rows in 30 secs).
The BryteFlow SAP Data Lake Builder has flexible connections for SAP including: Database logs, ECC, HANA, S/4HANA , SAP SLT, and SAP Data Services. It uses the Operational Data Provisioning (ODP) framework and SAP OData Services, to replicate SAP data to AWS. 2 Easy Methods to Extract SAP Data using ODP and Odata Services
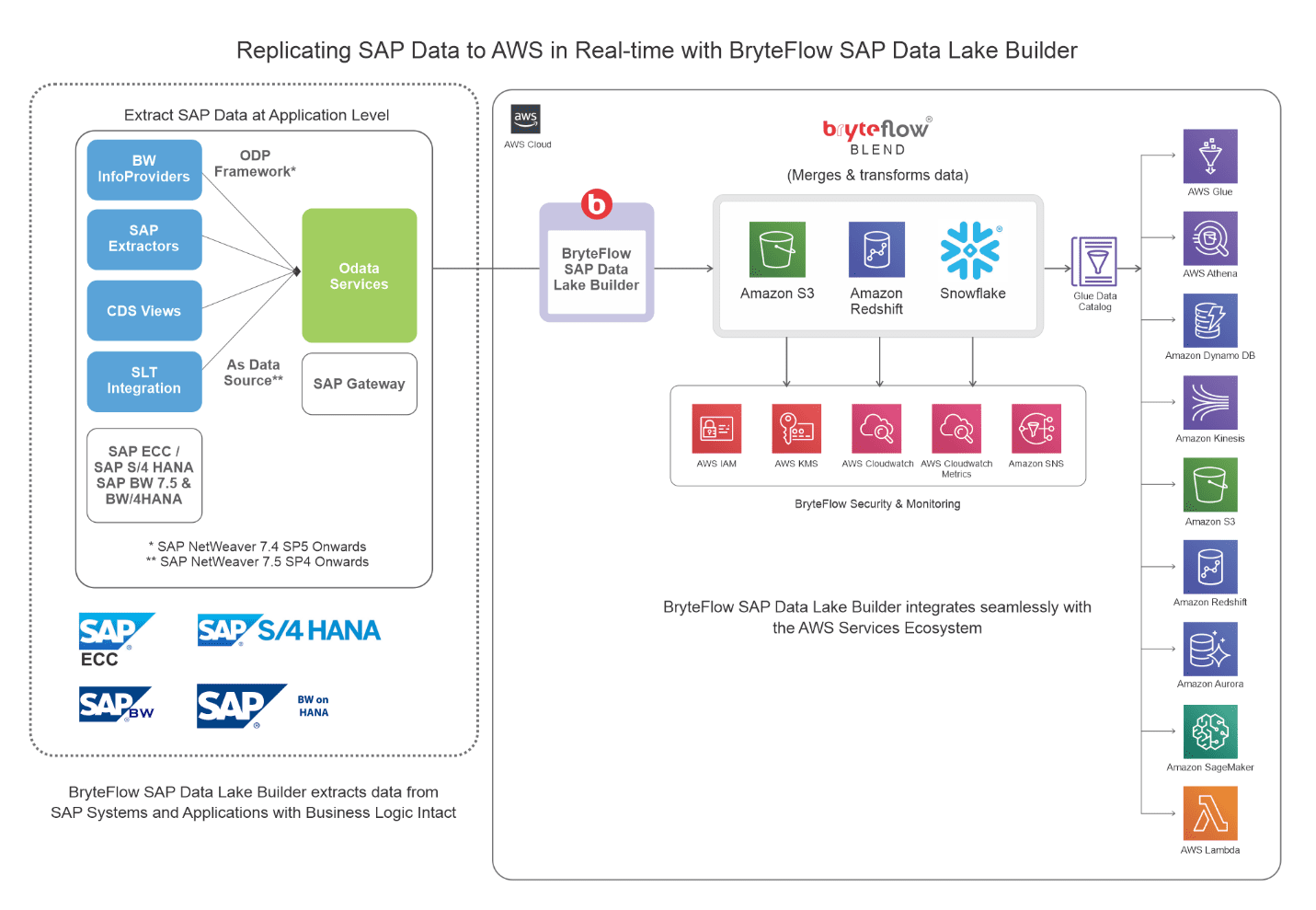
Replicating SAP data to AWS in Real-Time with BryteFlow
Highlights of the BryteFlow SAP Data Lake Builder
- Operates at the application level to connect with SAP, utilizing BW extractors, licensed SAP SLT, or SAP Core Data Services (SAP CDS) Views for data extraction and data lake construction.
- It extracts data from SAP ERP applications like SAP ECC, S4HANA, SAP BW, SAP HANA using the Operational Data Provisioning (ODP) framework and OData services, and moves data with application logic intact to AWS.
- Streamlines data extraction through ODP and OData services for initial, incremental, or delta data extraction, ensuring real-time sync using CDC. More on BryteFlow CDC
- Supports ingestion of petabytes of enterprise data with parallel, multi-thread loading, smart partitioning and compression.
- Captures inserts, updates, and deletes in real-time, integrating them seamlessly with existing data.
- Very high throughput- routinely replicates over a million rows of data in approx. 30 seconds. RISE with SAP (Everything You Need to Know)
- Eliminates the need for coding in any process, including data extraction, CDC, data mapping, schema and table creation, merging, masking and SCD Type2 history.
- Provides data type conversions out-of-the box – e.g. ORC and Parquet-snappy, so data is ready to use on destination. How to choose between Parquet, ORC and Avro for S3
- Facilitates Upsert operations on Amazon S3 effortlessly, leveraging stateless EMR clusters and comprehensive support for configurable partitioning, compression, and file types without the necessity of coding, seamlessly integrating into the AWS big data ecosystem. Create an S3 Data Lake in Minutes
- Streamlines integration with Amazon Athena and AWS Glue Data Catalog through API-level automation. How to get queries on Amazon Athena to run 5x faster
- Collaborates with BryteFlow Blend to offer data transformation capabilities across S3, Redshift, Amazon Aurora, and Snowflake.
- Automatically integrates with various AWS services including S3, EMR clusters, Amazon Athena, AWS Glue Data Catalog, and Redshift, utilizing AWS IAM, AWS KMS, CloudWatch Logs, and SNS for monitoring and security purposes.
- Ensures data security through encryption at rest and in transit, utilizing SSL connections to data warehouses and databases, masking sensitive data, and integrating with AWS KMS for encryption.
- The application is installed securely within the customer’s VPC with no outbound access, allowing the customer to control all security and data access.
- Configurable for IAM, AWS KMS, and other AWS security practices based on customer requirements.
- Facilitates querying directly on the data lake with Amazon Athena or Amazon Redshift Spectrum. Face off: AWS Athena vs Redshift Spectrum
- Provides an enterprise-grade data preparation workbench on S3 that organizes raw, enriched, or curated data into multiple S3 folders, categorizing data based on security classifications and maturity levels.
- Automates handling of data definition languages (DDLs), data mapping, and data conversion.
- Implements automated SCD Type 2 history tracking for data versioning.
- Offers end-to-end workflow monitoring through BryteFlow ControlRoom.
- Features automatic network catch-up mode to resume interrupted processes when conditions normalize.
The BryteFlow SAP Data Lake Builder offers various scenarios for delivering data to S3 and AWS
- Directly to Amazon S3 using EMR.
- To S3 first, then to Redshift using EMR.
- Directly to Redshift.
- To AWS S3 and Athena.
Case Studies for integrating SAP data on AWS
Origin Energy
Learn howThe BryteFlow software continually replicated and synced Origin Energy’s on-premise SAP data to a data lake on Amazon S3 and to a data warehouse on Amazon Redshift with minimal impact on sources. Read Case Study
Aldo Group
Learn about BryteFlow’s No-Code Plug and Play solution for the Aldo Group that loads data from SAP applications to an AWS data lake and enables seamless and codeless integration with the AWS ecosystem, opening up a wide range of use cases. Read Case Study
Mondou
How BryteFlow helped Mondou, a leading pet store franchise, to unlock large volumes of Sales and Inventory data from SAP on an AWS data lake and Snowflake to enable fast data insights. Read Case Study
We have discussed various modes to move data from SAP to S3 and extended the purview to include modalities for SAP to AWS replication as well. We also looked at the commonly used design patterns to extract data from SAP to AWS and the tools and frameworks used, including the ODP framework and OData services. Finally, we presented you with an easy, no-code and secure way to move your data from SAP applications to S3 and AWS with BryteFlow, and benefit from its seamless integration with AWS services.




