
This blog takes a look at SAP BODS, what it is, its advantages and disadvantages, SAP BODS architecture and how the BryteFlow SAP Data Lake Builder can prove a worthy alternative to SAP BODS, also known as SAP Data Services. Learn about BryteFlow for SAP
Quick Links
- What is SAP BODS?
- A short history of SAP BODS
- SAP BODS Architecture and Components
- Advantages and Disadvantages of SAP BODS
- BryteFlow as an alternative to SAP BODS
- BryteFlow SAP Data Lake Builder Highlights
What is SAP BODS?
SAP Business Object Data Services or SAP BODS as it is better known, is an SAP ETL tool that can extract data from different sources, cleanse and transform the data as per requirements, and then move the data to the target destination which could be an SAP application, data mart, data warehouse, flat file, or any operational database. SAP BODS can move and process data in real-time or in batches. It is an all-in-one versatile tool that can process data at enterprise-scale and take care of multiple functions like data integration, data quality, data profiling, and data processing. SAP BODS has a graphical user interface (GUI) to help developers build and implement complex data integration workflows easily without coding. SAP BODS is also known as SAP Data Services or even SAP BO Data Services. How to Carry Out a Successful SAP Cloud Migration
Please Note: SAP OSS Note 3255746 has notified SAP customers that use of SAP RFCs for extraction of ABAP data from sources external to SAP (On premise and Cloud) is banned for customers and third-party tools. Learn More
A short history of SAP BODS
The first stage in the evolution of SAP BODS were two ETL software created by Acta Technology Inc. called Data Integration (DI) tool and the Data Management or Data Quality (DQ) tool. These were renamed later as Business Objects Data Integration (BODI) tool and Business Objects Data Quality (BODQ) tool when Acta Inc. was acquired in 2002 by Business Objects, a French company. Later the Business Objects company was acquired by SAP in 2007 and the two products were merged to form a single product called SAP Business Objects Data Services (BODS).
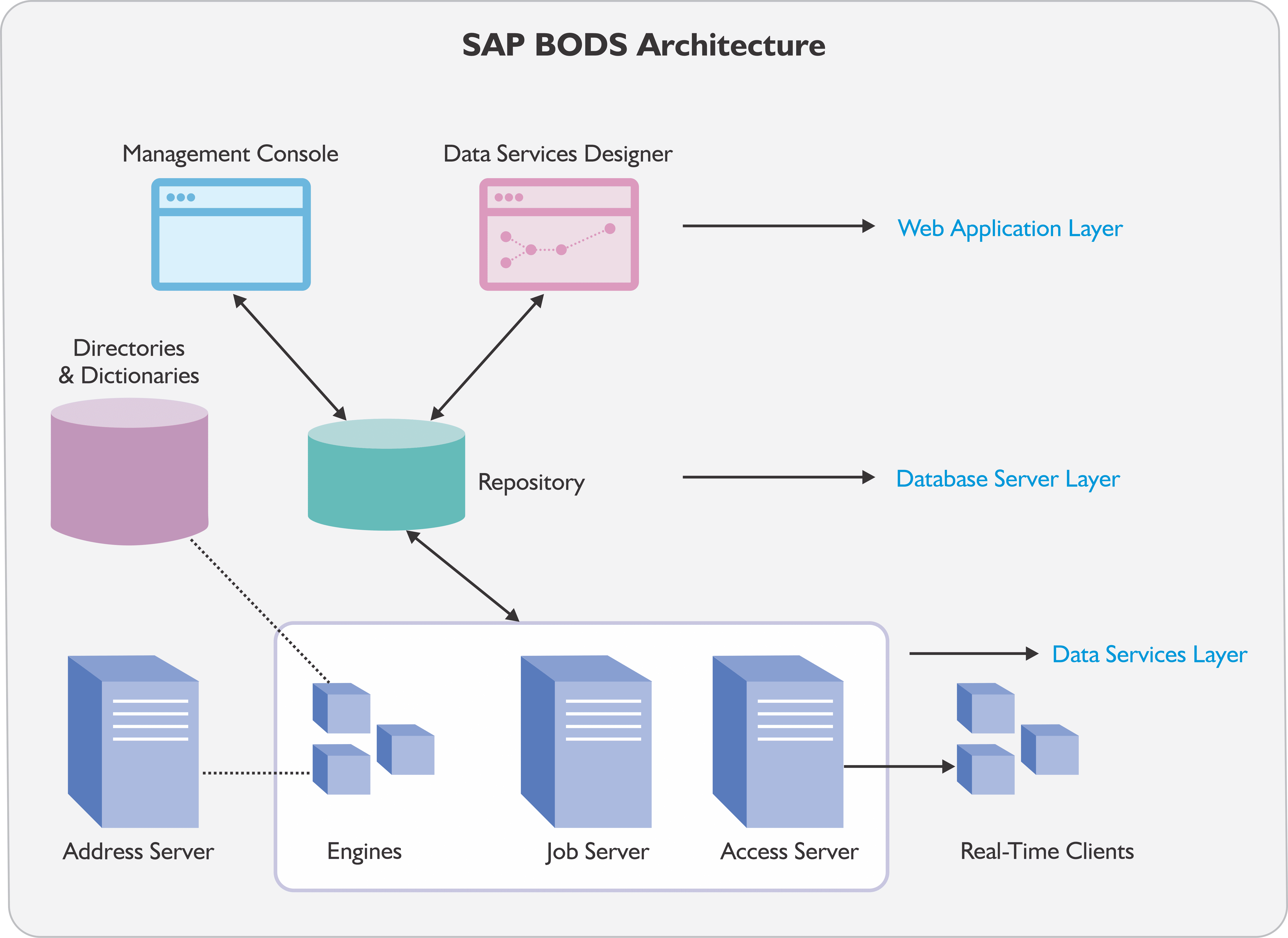
SAP BODS Architecture and Components
SAP BODS connects to a wide range of data sources and target systems, including databases, files, web services, SAP systems, and more. It has pre-built connectors and adapters to allow for data extraction and loading from different systems. The SAP BODS architecture delivers a reliable, scalable, and secure platform to integrate and transform multi-source data to provide useful, actionable insights. This is an overview of the SAP BODS architecture, its components and how they interact with each other. Create a CDS View in SAP HANA
Management Console
The SAP Data Services Management Console is a web-based application where users can execute jobs, schedule jobs, get auto technical documentation and some reports etc. It has features such as Impact and Linear Analysis, Auto Documentation, Operational Dashboard, Administration, Data Validation and Data Quality Data Reports. The Administrator section is the most used and handles job monitoring, execution, and scheduling. Every environment (e.g. DEV, QA, Production) has its own management console. Create an SAP OData Service for SAP Data Extraction
Data Services Designer
The Data Services Designer tool has a user-friendly GUI to enable you to outline transformations, data mapping and control business logic. It can help manage repository metadata and enables building of applications comprising of data and workflows. 5 Ways to extract data from SAP S4 HANA
Job Server
The SAP Data Services Job Server uses multi-threading, query optimization, parallel processing, in-memory caching, and in-memory data transformations to deliver data with high throughput and scalability. The Job Server has engines, and enables integration of data from different sources, helps in data transformation and manages data extractions and transactions from ERP applications and other sources. The Data Integration Job Server tool allows movement of data in real-time or in batches. The Job Server tool can also be executed from the Designer console and will retrieve the job information for you from the relevant BODS SAP storage repository and execute the job on the engines. A repository can be linked to more than one engine depending on the number of jobs being run and the need for performance. SAP Extraction using ODP and SAP OData Services (2 Easy Methods)
Engines
After the BODS jobs are run, the Job Server starts up the engines for data processing. The engines of the Job Server use in-memory data transformation and parallel processing to deliver quality, high connectivity, and scalability in processing. The engines are of 3 types:
- Data Integration Engine
This BODS engine handles the basic ETL process including data extraction, transformation and loading of data as per defined workflows. It reads and extracts data at source, applies transformations, and loads data to the destination. The SAP Cloud Connector and Why It’s So Amazing
- Data Quality Engine
The Data Quality Engine is responsible for data cleansing, data profiling and data enrichment. It offers functionality for data validation, detection of duplicates, address cleansing and standardization of data. SAP ECC and Data Extraction from an LO Data Source
- Text Data Processing Engine
The Text Data Processing Engine carries out text data processing for text extraction, text categorization and sentiment analysis. It allows unstructured text data to be integrated into data integration workflows. SAP HANA to Snowflake (2 Easy Ways)
Access Server
Access Server is like the Job Server but differs in the sense that it is used for real-time jobs. It provides a real time XML request-reply message that gathers the message request and delivers it to a real-time service to provide a message reply in a particular period. The Access Server reads the query and sends it to the next available real-time service, passing it through multiple computing resources. Using SAP SLT Transformation Rule in HANA
Address Server
Address Server helps in validating and correcting address data in the data that is being processed. The Address Server must be started before data flows containing Global Address Cleanse or Global Suggestion List Transform are run with EMEA engine enabled. How to Migrate Data from SAP Oracle to HANA
Repository
The repository is a database that stores user-defined and predefined system objects, such as source and target metadata and transformation rules. This helps in creating repositories on open client / server platforms and for sharing metadata with other enterprise software. There are two types of repositories -Local which is used by the Designer and Job Server, and Central which is used for object sharing and version control. Every local repository is connected to a single or multiple job servers which are executing your job. How to create an SAP OData Service for SAP Data Extraction on SAP BW
Objects
If you have wondered what the Objects in BODS are, it refers to all the entities used in the Data Services Designer. Everything used in the BODS Designer is an Object ranging from projects, jobs, system functions and metadata. They are stored in the local object library and are hierarchical in pattern. Every Object will have properties that define it, including Name, Date Created etc. They also have Options that control how the object is operated. SAP Extraction using ODP and SAP OData Services
Objects are of 2 types- Reusable and Single Use
Reusable Objects in SAP BODS
A Reusable Object can be used multiple times once it is defined and saved in the local repository. This can be done by creating Calls to the definition. The Object Library contains object definitions and when you drag and drop an object from the library, a fresh reference is created for the object. Only one definition exists for each reusable object and if you change that definition, the definition will be changed at all the places where the object is included. RISE with SAP (Everything You Need to Know)
Single Use Objects in SAP BODS
The objects that are created specifically for a job or data flow are single use e.g. a particular transformation created for a data ETL process. Automating the ETL Pipeline
Here are some objects used in SAP BODS
Project
The Project is an object with the topmost level in the hierarchy of the Designer screen. Projects enable you to manage the other objects you create. Only one project can be opened at a time in the window. The SAP Cloud Connector and Why It’s So Amazing
Job
A Job refers to the smallest piece of work that you can schedule and execute independently.
Script
This refers to part of the code or subset of lines in the procedure. It can execute functions and give values to variables which can be distributed to other steps in the flow.
Workflows
A Workflow comprises of several data flows that make up the flow of work for a complete job. Workflow is a procedure that is optional. These are some of the tasks a workflow does:
- Calling data flows.
- Calling a different workflow.
- Defining the sequence of steps in which a job should be executed.
- Passing dataflow parameters to and fro.
- Specifying how errors must be handled during execution.
- Defining conditions for executing different project parts.
Data Flow
The process by which data from source is transformed into data on the target is a Data Flow. It is a Reusable Object and always called from a Job or a Workflow. It enables you to:
- Identify the source data you need to query.
- Define the data transformations to be carried out.
- Identify the table on target where you need to load the data.
Other commonly encountered terms in the SAP BODS environment
Datastore
A Datastore is an interface or connection that links the source database or application and SAP Data Services. It also enables the import of metadata regarding the data source. These are some of the databases and applications supported by SAP Data Services. It supports:
- Databases: ODBC, Oracle, DB2, MySQL, Microsoft SQL Server, HP Neoview, Informix, Sybase ASE, Sybase IQ, SAP HANA, Netezza, Data Federator, Teradata. SAP HANA to Snowflake (2 Easy Ways)
- Oracle Applications How to Migrate Data from SAP Oracle to HANA
- JD Edwards: JD Edwards ERP applications JDE One World, JDE World
- Siebel: Siebel CRM application
- PeopleSoft
- SAP Applications
- SAP BW: SAP BW as Source and Target
- Adapters: Custom Java- based Adapters to access application metadata and application data
- Web Service: The web services datastore works by sending a request and waits until a reply is received from a web services server.
Central Management Console (CMC)
This tool handles essential tasks like registration of repositories, user management etc. and is a web-based administration tool.
Data Integrator Web Administrator (DI Web Admin)
This tool helps to manage repositories within SAP BODS. DI Web Admin contains services such as Central Repository, Meta Repository, Web Services and Job Services. The SAP Cloud Connector and Why It’s So Amazing
Advantages and Disadvantages of SAP BODS
Advantages of SAP BODS as an SAP ETL tool
- SAP BODS delivers high scalability whether there are a hundred customers or ten thousand. It supports parallel processing, distributed data integration, and load balancing, which allows for efficient processing of enterprise-scale data. SAP to AWS (Specifically S3) – Know as Easy Method
- Being an SAP product, BODS has seamless integration with SAP systems, such as SAP Business Suite, SAP BW (Business Warehouse), and SAP HANA, which enables organizations to optimize existing SAP investments. SAP SLT Transformation Rule in HANA
- SAP BODS has a drag-and-drop interface which data engineers or analysts can start using without much being required in terms of coding skills.
- Within SAP BODS there are system-provided objects and functions which can be easily dragged and dropped which saves time while doing data transformations etc. How to Carry Out a Successful SAP Cloud Migration
- SAP BODS is flexible and enables multiple ways for ingestion to SAP, such as BAPIs, IDOCS, and Batch input.
- Various data transformations can be implemented within SAP BODS using Data Integrator language and SAP BODS also enables building of customized functions through its capability to perform complex data transformations. Replication with SAP SLT using ODP Scenario
- Jobs can be scheduled and monitored easily with SAP BODS. Repetitive, mundane tasks can be minimized using variables. Variables are convenient since they allow for certain factors to be changed like processing environment, task-related steps etc. without needing to recreate the entire job. SAP ECC and Data Extraction from an LO Data Source
- SAP BODS also has built-in features for data harmonization, profiling, cleansing and data quality. This ensures accuracy, consistency, and completeness of data. SAP HANA to Snowflake (2 Easy Ways)
- SAP BODS has a central repository that provides superior metadata management. It enables users to maintain and document metadata related to data sources, transformations, and other objects. This enhances collaborative effort and maintains consistency over multiple projects.
Disadvantages of SAP BODS as an SAP ETL tool
- SAP BODS is a commercial product and needs to be licensed for use. Maintenance, support, and upgrades may also attract extra charges, so overall it could prove expensive to use. RISE with SAP (Everything You Need to Know)
- SAP BODS has limited real-time data capabilities and getting real-time data with change data capture may prove challenging. BODS was designed for batch processing and may not be optimal for situations that need real-time data processing. SAP Replication with SLT and ODP
- When you create a real-time job in Data Services Designer, they are not executed with triggers like batch jobs. The Administrator executes them as real-time services that wait for messages from the Access Server. Once the Access Server receives the message and passes it to real-time services, they can process the message and return the result. They continue processing the messages until they get a command to stop executing. SAP HANA to Snowflake (2 Easy Ways)
- SAP BODS is a complex tool and requires technical expertise in data integration, SQL, and ETL processes to design workflows efficiently. In other words, a skilled development team will be required to use SAP BODS. BryteFlow for SAP Replication
- The debugging functionality of SAP BODS is not very sophisticated, which means development can become challenging as compared to other coding platforms.
- SAP BODS may need a sizable number of dedicated servers and hardware resources particularly when dealing with huge data volumes. Hardware infrastructure and performance optimization are key factors that must be taken into account when considering BODS.
- It might prove challenging to integrate data from non-SAP systems with SAP BODS. Additional customization and development efforts may be needed for smooth connectivity and data integration. How to Migrate Data from SAP Oracle to HANA
BryteFlow as an alternative to SAP BODS
Though SAP BODS is a great SAP ETL tool, you can make your task even easier by using BryteFlow. Our BryteFlow SAP Data Lake Builder tool automatically extracts data from SAP systems and applications with business logic intact, so you don’t need to recreate it on the destination. It also delivers ready-to-use data which can be consumed immediately – no coding required whatsoever! BryteFlow merges deltas using real-time, automated Change Data Capture to keep data continually updated on on-premise and cloud targets like Snowflake, Redshift, Amazon S3, Google BigQuery, Databricks, PostgreSQL, Azure Synapse, ADLS Gen2, Apache Kafka, Azure SQL DB and SQL Server.
BryteFlow SAP Data Lake Builder Highlights
Here are a few features of the BryteFlow tool that can make your SAP ETL tasks much easier.
Extracts data with business logic intact
The BryteFlow SAP Data Lake Builder connects to SAP at the application level. It gets data exposed via SAP BW ODP Extractors or CDS Views as OData Services to build the SAP Data Lake or Data Warehouse. It replicates data from SAP ERP systems like ECC, HANA, S/4HANA and SAP Data Services. SAP application logic including aggregations, joins and tables is carried over and does not have to be rebuilt, saving effort and time. It can also connect at the database level and perform log based Change Data Capture to extract and build the SAP Data Lake or SAP Data Warehouse. A combination of the 2 approaches can also be used. The SAP Cloud Connector and Why It’s So Amazing
A No-Code Tool for SAP ETL
Using SAP BODS may require some scripting, but BryteFlow is completely automated with no coding for any process including data extraction, SCD Type2, schema creation, data mapping, table creation, DDL etc. BryteFlow automates inserts, updates and deletes, merging them with existing data, to keep your SAP Data Lake or SAP Data Warehouse continually synced with source in real-time. No coding or a third-party tool like Apache Hudi is required. SAP to AWS (Specifically S3) – Know as Easy Method
Fast multi-threaded parallel loading and smart partitioning
BryteFlow ingests data with parallel, multi-threaded loading and partitioning, with just a few clicks. This makes data extraction very rapid and enables faster querying of data. The user-friendly interface provides easy automated configuration of data for partitioning, file types and compression. How to Migrate Data from SAP Oracle to HANA
Provides Time -series data with Automated SCD Type 2 History
BryteFlow enables automated SCD Type2 history for accessing time-series data. It maintains the full history of every transaction with options for automated data archiving, so you can retrieve data from any point on the timeline. How to Carry Out a Successful SAP Cloud Migration
Delivers data directly to Snowflake without staging
If you are using Snowflake as a destination, BryteFlow does not need a landing platform and lands the data directly to Snowflake’s internal stage using the best practices. The process is much faster without intermediate stops. SAP to Snowflake (Make the Integration Easy)
User-friendly interface
BryteFlow has an intuitive, user-friendly interface. Once configured, you just need to define the SAP source and destination with a couple of clicks, select the tables you need to take across, set a schedule for replication and start receiving data almost instantly. SAP HANA to Snowflake (2 Easy Ways)
ETL SAP data in one go, with a robust automated data pipeline
Processing data with BryteFlow SAP Data Lake Builder is just a one phase process and does not require 2-3 distinct operations as is the case with most SAP integration tools like BODS. Data migration that has multiple hops increases latency, risk of pipeline breakage and data getting stuck.
Completely secure SAP ETL
With BryteFlow SAP Data Lake Builder, you do not have to define and manage security on Azure Blob, Amazon S3 or Google Cloud Storage since staging is not needed. BryteFlow configuration and installation happens within your VPC, the data stays within your data environment and is subject to your security controls.
Data from non-SAP Systems and Applications
BryteFlow also replicates data automatically from other transactional databases like Oracle, SQL Server, Postgres, MySQL and Teradata to the Cloud and on-premise destinations by way of BryteFlow Ingest, in case you should need it. View How BryteFlow Works
Contact us for a Demo of BryteFlow SAP Data Lake Builder or get a Free POC




