
Executives and business leaders often ask about S3 security for their Amazon S3 Data Lakes. Data is a valuable corporate asset and needs to be protected. In this blog post we look at S3 security best practices and how you can implement them using individual AWS services and BryteFlow to provide watertight S3 security, so that your data remains secure in the S3 data lake. BryteFlow’s S3 Data Lake Implementation
Quick Links
What is Amazon S3?
S3 Storage and Security
S3 Security and Access Management using S3 Bucket Policies
S3 Security Best Practices – 13 Tips You Should Follow
- S3 Security Tip 1: Apply S3 Block Public Access
- S3 Security Tip 2: Use Amazon S3 Object Lock
- S3 Security Tip 3: Ensure data resides in your Virtual Private Cloud or VPC
- S3 Security Tip 4: Use S3 Encryption – Server-Side Encryption or SSE to encrypt data
- S3 Security Tip 5: Use AWS Key Management Service or KMS
- S3 Security Tip 6: Use Data Masking and Tokenization
- S3 Security Tip 7: User Access Control with AWS Identity and Access Management (IAM) Permissions
- S3 Security Tip 8: Use AWS Lake Formation for fine grained control access
- S3 Security Tip 9: Audit S3 Access frequently
- S3 Security Tip 10: Use AWS CloudTrail to monitor actions and requests
- S3 Security Tip 11: Use AWS Trusted Advisor
- S3 Security Tip 12: Use the BryteFlow Replication Tool to automate S3 Security Best Practices
What is Amazon S3?
Amazon S3 (Amazon Simple Storage Service) is an AWS service that lets a user access and store data online through a basic web-based interface. S3 is extremely powerful, enabling users to move and store data across different classes of object storage, adding metadata to objects and running analytical queries on data in S3. However, with great power comes great responsibility, (apologies to Spiderman!) and Amazon S3 takes its responsibility for maintaining data security very seriously. 6 reasons to automate your Data Pipeline
Despite S3 security, data breaches and leaks do happen. Here we list out some S3 security features that are available and S3 security best practices you can take advantage of, to keep your data secure in your S3 data lake. Create an S3 Data Lake with BryteFlow (S3 Tutorial – 4 Part Video)
S3 Storage and Security
Before discussing S3 security you need to understand how S3 storage works. On S3 data is stored as Objects within S3 Buckets. Any kind of file can be an object including text files, images, videos etc. When adding files there is an option to add metadata and to define access to the file by setting permissions. Each bucket can have defined access stating who can control, create, delete, and list objects, view access logs for the bucket and objects within and to select the geographical region where S3 will store the bucket. Amazon S3 Data Lake Solution
S3 Security and Access Management using S3 Bucket Policies
AWS Identity and Access Management (IAM) is an AWS service that helps manage access to your data on S3. By default, only the person creating the S3 bucket has access to its contents. You can grant additional permissions to users by instituting an IAM policy.
According to S3 best practices you should define roles to provide specific access to a set of resources. You can create Access Control Lists (ACLs) to make objects accessible to authorized users. Use S3 Bucket Policies to define permissions for all objects within an individual bucket and Query String Authentication to provide limited-time access to users with temporary URLs. Amazon S3 also supports Audit Logs to display requests made to access data and to see which users are accessing what data.
S3 Security Best Practices – 13 Tips You Should Follow
S3 Security Tip 1: Apply S3 Block Public Access
Every S3 bucket, existing and future in your account should have S3 Block Public Access applied. This will ensure there is no public access to any object. S3 Block Public Access can negate S3 permissions that enable public access, allowing the account administrator to set up a centralized control for consistent safety configuration.
S3 Security Tip 2: Use Amazon S3 Object Lock
The Amazon S3 Object Lock prevents object version deletion. You can specify a retention period for this. This is important for regulatory compliance and acts as an extra layer of data protection. Workloads can be migrated from write-once-read-many (WORM) systems into S3, and you can set S3 Object Lock at object and bucket levels to block object version deletions.
S3 Security Tip 3: Ensure data resides in your Virtual Private Cloud or VPC
A Virtual Private Cloud (VPC) is a virtual network dedicated to your AWS account. Hosted virtualization isolates your data from that of other companies – both in transit and in the cloud provider’s network -helping to create a more secure environment. Consider having a VPC endpoint for S3. This is a logical entity within your VPC that will allow you to connect only to S3. This enables you to control access to buckets from specific VPCs or VPC endpoints keeping data safe from the dangers of the open Internet. This enables control over requests, users and groups allowed through a particular VPC endpoint.
S3 Security Tip 4: Use S3 Encryption – Server-Side Encryption or SSE to encrypt data
Use Server-Side Encryption or SSE to encrypt your data when you store data on Amazon S3. Amazon S3 server-side encryption uses the strongest block ciphers in existence, 256-bit Advanced Encryption Standard (AES-256), to encrypt your data. Amazon S3 has 3 different server-side encryption options to manage the encryption keys but only one type of server-side encryption can be applied to an object at any given time.
Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3)
As per Amazon S3-Managed Keys (SSE-S3) protocol, each object encryption has a unique key. As an additional safeguard, Amazon S3 encrypts the key with a master key that it regularly rotates.
Server-Side Encryption with Customer Master Keys (CMKs) Stored in AWS Key Management Service (SSE-KMS)
Customer Master Keys (CMK) encryption is quite like (SSE-S3) but has a few more advantages and additional charges. Separate permissions allow you to get a CMK to prevent unauthorized access of your objects in Amazon S3. It displays an audit trail showing who used the CMK and when. You can also make and manage customer-managed CMKs or use AWS-managed CMKs specific to you and your region.
Server-Side Encryption with Customer-Provided Keys (SSE-C)
In the Server-Side Encryption with Customer-Provided Keys (SSE-C), Amazon S3 manages the encryptions while you, the customer provides and manages the encryption keys. S3 encrypts the data as it writes to disk and decrypts the data on access.
S3 Security Tip 5: Use AWS Key Management Service or KMS
AWS Key Management Service (AWS KMS) is a managed AWS service that makes it easy for you to create and control the encryption keys used to encrypt your data when you transfer and store it. The customer master keys that you create in AWS KMS are protected by hardware security modules (HSMs). With BryteFlow, enabling KMS, is as easy as just providing your KMS Key, BryteFlow automates the rest of the process.
S3 Security Tip 6: Use Data Masking and Tokenization
When it comes to storage of sensitive data on S3, you can use tokenization to hide sensitive data. Tokenization will substitute the actual data with characters generated randomly in the same format so unauthorized users cannot get to the data. The relational values of the original data to token data is stored on a token server. When the actual values are needed, the Token system will look up and serve the original values from the Token server. Tokenization is used in customer service databases, payment processing, storing credit card information etc.
Masking is similar but you cannot retrieve the original data. Masking can also be used to control sensitive data access based on permissions. This is Dynamic Data Masking that enables authorized users to access unmasked data but displays masked data to users who do not have access permissions for the sensitive data.
BryteFlow provides Data masking and tokenization out-of-the-box on S3. Certain data like financial data or credit card data may be very sensitive and hence masking or tokenizing it is essential. BryteFlow has easy options for data masking, providing check boxes against data elements, to mask them. Set up an S3 Data Lake in Minutes with BryteFlow (Video Tutorial)
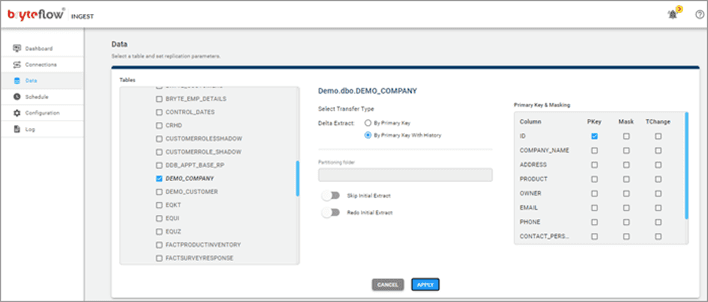 BryteFlow Ingest offers Data Masking options through selection of checkboxes
BryteFlow Ingest offers Data Masking options through selection of checkboxes
S3 Security Tip 7: User Access Control with AWS Identity and Access Management (IAM) Permissions
You can manage secure access to your Amazon S3 resources using access policy options. By default, all Amazon S3 resources—buckets, objects, and related sub-resources, are private: only the resource owner, an AWS account that created them, can access the resources. The resource owner can then grant access permissions to others by writing an access policy. User policies are managed with the AWS Identity and Access Management (IAM) service which enables you to control permissions and manage access to objects in an S3 bucket. IAM enables you to create IAM users, groups and roles and then associate access policies with them to grant access to objects on S3.
BryteFlow Ingest keeps the ready-to-use raw data and transformed data using BryteFlow Blend in separate buckets, making it easy to give access as required. Only a select group, should have access to raw data and this can be managed very easily through AWS IAM permissions.
S3 Security Tip 8: Use AWS Lake Formation for fine grained control access
AWS Lake Formation is an AWS service which had been released in 2019 with general availability in certain regions. AWS Lake Formation can help you set up a secure data lake easily. It plugs into AWS Big Data services like AWS Identity and Access Management (IAM)and AWS Key Management Service (KMS), Amazon S3, Redshift and Athena seamlessly. Learn about querying on S3- Amazon Athena vs Redshift Spectrum
AWS Lake Formation takes the effort out of security management by providing a single place to centrally define security, governance, and auditing policies versus doing these tasks per service, and then enforcing those policies for users across analytics applications. AWS Lake Formation provides superior access control: With S3, you can only control access to a single object or a file, however with AWS Lake Formation, you can get fine grain control by columns in an object or file.
BryteFlow provides an automated solution for building and maintaining a data lake and interfaces with Glue Data Catalog and AWS Lake Formation, making it easy to set up security across the AWS eco-system. Check out AWS Glue as an option for AWS ETL
S3 Security Tip 9: Audit S3 Access frequently
IAM policies for S3 can be further complemented with Metadata solutions using a combination of tools like AWS Lambda, Elasticsearch and Kibana. This enables clients to have real time visibility and alerts across Amazon S3 data search and access activity. For example, a client can have visibility across the list of users that failed authentication using a filter on the agentname, agentid and ruledescription fields.
S3 Security Tip 10: Use AWS CloudTrail to monitor actions and requests
You can view a record of actions taken in S3 by users, roles, and services. AWS CloudTrail collects this information so you can get details of the request made, including who made the request, IP of the requester, when it was made etc. CloudTrail is enabled by default when you create an AWS account and to create an ongoing record of actions and events, you can create a Trail in the CloudTrail Console, which will enable CloudTrail to log data events.
S3 Security Tip 11: Use AWS Trusted Advisor
AWS Trusted Advisor makes inspections of your AWS account and advises you on the actions to take in case there are security concerns. It checks the following in S3: Amazon S3 bucket logging configuration, S3 buckets with open access, S3 buckets without versioning enabled.
S3 Security Tip 12: Use the BryteFlow Replication Tool to automate S3 Security Best Practices
BryteFlow Ingest replicates data in real-time to S3 automatically using log-based Change Data Capture, without you needing to write a single line of code. Upserts on S3 are automated – inserts and updates are merged with data in S3 automatically, so you get ready-to-use data. There is no coding to be done for any process including data extraction, masking or SCD Type 2 history. The Amazon S3 data lake is automated from end-to-end and includes all best practices for S3 security, S3 partitioning and compression. See how BryteFlow works
BryteFlow automates S3 best practices to achieve high throughput and low latency. Bulk inserts with BryteFlow XL Ingest are easy and fast with multi-threaded parallel loading, smart partitioning, and compression. BryteFlow TruData provides automated data reconciliation, checking data completeness with row counts and columns checksum. BryteFlow Blend provides automated transformation on S3, enabling you to transform and merge any data, including IoT and sensor data on Amazon S3 in real-time, to prepare data models for Machine Learning, Analytics and AI. Get a Free Trial of BryteFlow



