
This blog examines the reasons, challenges, and benefits involved in moving data from SAP HANA to Snowflake. We also present two methods of moving data from SAP HANA to Snowflake – the first, a manual one using DBeaver, and the second, a fully automated method using BryteFlow Ingest.
If you would like to move data directly from SAP applications and systems to Snowflake, do consider the BryteFlow SAP Data Lake Builder. BryteFlow can also ELT data from SAP databases if the access to the underlying database is available. BryteFlow for SAP Database Replication
Quick Links
- Why move data from SAP HANA to Snowflake?
- About SAP HANA
- About Snowflake
- Benefits of Moving Data from SAP HANA to Snowflake
- SAP HANA to Snowflake Migration Challenges
1. Practical challenges while migrating SAP HANA to Snowflake2. Technical challenges while migrating SAP HANA to Snowflake - Steps involved in moving data from SAP HANA to Snowflake
- Data-type Mappings between SAP HANA and Snowflake
- Methods to load data from SAP HANA to Snowflake
1. A Manual Method to load data from SAP HANA to Snowflake.2. An Automated Method to transfer data from SAP HANA to Snowflake using BryteFlow
- Differences between the Manual method and the Automated method
- BryteFlow Ingest and BryteFlow SAP Data Lake Builder for SAP migration
Why move data from SAP HANA to Snowflake?
Before we understand the need to move data from SAP HANA to Snowflake, let’s understand what these two platforms are all about. SAP to Snowflake (Make the Integration Easy)
About SAP HANA
SAP HANA which stands for High-performance ANalytic Appliance, is a sophisticated multi-model in-memory database that stores data in column-based tables in its main memory, instead of writing it to a disk. This lets organizations execute high speed transactions as well as advanced analytics through a single system. It allows for processing of huge amounts of data with almost zero latency, querying data instantly, and using data for business initiatives efficiently. How to Carry Out a Successful SAP Cloud Migration
SAP HANA can also be used as a platform for application development. SAP S/4 HANA which is SAP’s latest ERP, runs on the SAP HANA database. SAP ECC, the older version of SAP ERP can also be run on SAP HANA as part of the SAP Business Suite. As per SAP, support for SAP ECC will end in 2027, so SAP ECC customers will need to migrate to SAP S/4 HANA by then. SAP S/4 HANA Overview and 5 Ways to Extract S/4 ERP Data
About Snowflake
In the light of huge data volumes growing exponentially, a lot of organizations are turning to Snowflake for processing, analytics, and storage of data. Snowflake can handle and analyze large data volumes with exceptional performance and scalability. It functions as a Cloud data warehouse and can run on multiple Cloud environments including AWS, Azure and GCP. Reliable SAP CDC and Data Provisioning in SAP
Snowflake operates as a fully managed Software as a Service (SaaS) solution, providing a unified platform for various data-related functions such as data warehousing, data lakes, data engineering, data science, and application development. Its key features include storage and compute separation, elastic scalable computing, data sharing, cloning, and support for third-party tools, making it a preferred solution for data analytics and business intelligence. Snowflake enables secure data sharing across organizations and allows data to be integrated from multiple sources into a single repository. SAP to Snowflake (Make the Integration Easy)
Benefits of Moving Data from SAP HANA to Snowflake
Moving SAP HANA to Snowflake enhances accessibility
Snowflake’s architectural simplicity enables better use of SAP HANA data since it is available in a single central location. The entire team of the SAP customer can access and use the data easily and make data conform to FAIR principles (Findable, Accessible, Interoperable, Reusable). How to Carry Out a Successful SAP Cloud Migration
Moving SAP HANA to Snowflake allows for data ingestion from different sources
Snowflake is Cloud provider-agnostic and flexible. It can handle data from on-premise and Cloud SAP systems, third-party databases, and signal data. The data can be ingested in structured and semi-structured formats or even if there are changes in schema. Snowflake CDC With Streams and a Better CDC Method
Moving SAP HANA to Snowflake enables 360-degree views of the business
Centralized data in the Snowflake data warehouse allows customers to create 360-degree views of business operations including sales, products, inventory and the supply chain etc. They can even combine datasets of business partners for an overall view using the Snowflake Marketplace. Oracle to Snowflake: Everything You Need to Know
Moving SAP HANA to Snowflake means storage is automatically managed
Snowflake manages storage automatically, by way of isolated clusters addressing capacity, compression, performance and statistics, which means there is no need for you to build indexes or do maintenance chores. Here’s Why You Need Snowflake Stages
Moving SAP HANA to Snowflake means you can aggregate data from other sources
SAP Snowflake integration enables combining data from SAP HANA with data from multiple non-SAP and SAP sources. Snowflake allows concurrent data ingestion and reporting, for advanced analytics and data science use cases with practically non-existent downtime. SQL Server to Snowflake in 4 Easy Steps (No Coding)
Moving SAP HANA to Snowflake means you can separate storage and compute
As a user of Snowflake’s fully managed platform, you can attach and detach Snowflake services as required. This improves operational efficiency and reduces costs. Snowflake provides elastic compute and storage that are independently scalable. You do not need to deal with the complexities of hardware and compute allocation, it is completely managed by Snowflake. The SAP Cloud Connector and Why It’s So Amazing
For example, with heavy workloads, SAP HANA may get overloaded, display out-of-memory errors and throttle SAP BW queries, possibly needing license negotiations, whereas on Snowflake it would be business as usual. How to load terabytes of data to Snowflake fast
Moving SAP HANA to Snowflake guarantees data security
In Snowflake, data is always encrypted whether in storage or in transit. The data lands only once and views are shared across. There is only one copy of data, one security model and many elastic compute clusters equipped with their own monitors. The test, development and production environments are part of the same account. There is a single governance policy applicable, which increases security. SAP to AWS (Specifically S3)
Moving SAP HANA to Snowflake enables AI and Machine Learning
Besides SAP data you can bring third-party data and sensor data into Snowflake, for e.g. clickstream data from Facebook and X, machine-generated data from SAP with Salesforce and then model the data together by using the Snowflake Marketplace. Your team can use their preferred BI tool to access the data within their isolated compute clusters. RISE with SAP (Everything You Need to Know)
SAP HANA to Snowflake Migration Challenges
When you migrate data from SAP HANA to Snowflake, there are some challenges that may crop up. These issues could be practical as well as technical. Here is a brief rundown. How to Migrate Data from SAP Oracle to HANA
Practical challenges while migrating SAP HANA to Snowflake
Extracting SAP data directly from Tables
While you can extract data from SAP from the application layer or from querying the underlying database (if you have access), this is easier said than done. SAP has thousands of tables, most of them with 4-character abbreviations and 6-character field codes. Finding the right tables and links between them can be extremely challenging unless you are an SAP expert and familiar with SAP language. How to Carry Out a Successful SAP Cloud Migration
SAP Operational Data Provisioning framework (ODP)
The easier way to extract data is by using ODP and OData Services. ODP or Operational Data Provisioning functions using a ‘Provider’ and ‘Subscriber’ model to support data transfers between SAP systems and from SAP to non-SAP data targets. Each dataset will have more metadata than database tables and can include links between datasets. The ODP framework provides a single interface to connect with a range of data types, including SAP CDS views, SAP BW extractors (or S-API extractors), HANA Calculation views, SAP BW objects (queries, InfoProviders). Reliable SAP CDC and Data Provisioning in SAP
As communication protocols, both OData and RFCs (Remote Function Calls) can be used as channels for the SAP ABAP platform to talk with external systems. Both provide access to the ODP framework and directly to a range of SAP data sources. They can be accessed by third-party tools like BryteFlow to deliver initial and incremental data using CDC to Cloud platforms or on-premise destinations. However, in a recent development, SAP has notified SAP customers (SAP OSS Note 3255746) that use of SAP RFCs for extraction of ABAP data from sources external to SAP is banned for customers and third-party tools. Learn More
Please note that BryteFlow uses the SAP recommended mode of SAP extraction, using ODP and OData Services to extract and replicate SAP data from a wide variety of SAP data sources such as Database logs, ECC, HANA, S/4HANA , SAP BW, SAP SLT, and SAP Data Services.
Data may get corrupted while moving from SAP HANA to Snowflake
SAP data is complex, has a proprietary format, and the implementation may have customization built into it. You will need to follow established best practices and ensure data is filled in correctly using the appropriate data type and carry out trial and error testing before the SAP migration. How to create an SAP OData Service for SAP Data Extraction
Incompatibility between software modules when migrating SAP HANA to Snowflake
SAP HANA and Snowflake databases have different formats, there may also be incompatibility issues within software modules. For e.g. if a table in SAP HANA table is linked to a table or view in Snowflake, problems may surface after data migration. Once again, besides taking care to fill data in the right fields using the right data type and adequate testing, you should check for any links between tables and views if any such links are present. SAP to AWS (Specifically S3) – Know an Easy Method
ETL process bottlenecks in SAP HANA to Snowflake migration
Extracting data from SAP and transforming it for Snowflake compatibility can be challenging. SAP systems contain extensive data in diverse formats, and you need to carefully select your extraction methods. Transforming the data to meet Snowflake data warehouse requirements, including cleaning, transforming, and aggregating data, can be complex and slow down the ETL process. SAP SLT in HANA: How to use SLT Transformation Rule
SAP HANA and Snowflake have diverse data structures and schemas
SAP HANA and Snowflake often feature disparate data structures and schemas, making mapping data elements between the systems complex and time-consuming. You will need to understand the respective data models thoroughly to ensure accurate mapping and data integrity preservation during SAP Snowflake migration.
SAP HANA licensing model may prevent access to data that is technically available
You may think extracting data from the SAP HANA database would be a simple and obvious solution. Not so fast – most SAP customers have a HANA Runtime license only and cannot legally extract data from the underlying database layer without additional and expensive licensing. They can, however, extract data from the SAP application layer. This is where the BryteFlow SAP Data Lake Builder can help you- by extracting data with business logic intact from SAP applications. The SAP Cloud Connector and Why It’s So Amazing
Technical challenges while migrating SAP HANA to Snowflake
Compilation Memory Exhausted Issue on Snowflake Deployment
SAP HANA DW aggregates multi-system data into a landing area which is combined into a single view/function. For e.g. this is a common data pattern over SAP EMR systems and can be done easily since data structures are similar. However, when multiple views are used inside SQL code, the size of the code increases, due to which while deploying on Snowflake, you may face a ‘compilation memory exhausted’ issue. A quick fix would be to request Snowflake support to increase the compilation memory parameter to max limit (Default is 1 MB and max can be 4X i.e. 4 MB). SAP Extraction using ODP and SAP OData Services (2 Easy Methods)
Transactions being blocked due to parallel updates on same object
When multiple updates are carried out in parallel on the same object in Snowflake, the query will put a lock on a table or on partitions, which will block other transactions from carrying out updates on the object – which may not happen in the case of SAP HANA. A workaround might be to modify the lock wait time out value on SQL statements.You can also look at right-sizing the Snowflake warehouse for jobs, leading to better performance on update queries. CDS Views in SAP HANA and how to create one
UDFs (with query on table), cannot be used in SQL statement
User defined functions or UDFs that accept input params and calculate from master table, cannot be used in SQL statements on Snowflake. You are likely to get an error saying, “Unsupported subquery type cannot be evaluated”. You could modify the code using a quick fix, like joining the table from UDF in Query and to keep calculations only inside the function. How to Migrate Data from SAP Oracle to HANA
Date/Timestamp management can be an issue
Snowflake differs from SAP HANA in its management of Date/Timestamp format which can affect your output. You can take care of this in various ways. Read more
Schema refactoring and merging into a single schema can be challenging
You need to be careful when refactoring and merging multiple schemas into a single one or when migrating similar objects from different paths in SAP HANA to Snowflake. This will need renaming of similar objects when brought under a single schema. The name change will have to be carried out in all referenced places, and the existing and future references will have to be maintained on the migration master sheet. SAP to AWS (Specifically S3)
Renaming as per Snowflake conventions
SAP HANA objects with special characters will need to be renamed as per the standard naming conventions on Snowflake. However, it is important to remember all the changed references and they should be maintained across all places. Create a CDS View in SAP HANA
Runtime issues caused by compilation memory exhausted
If you run similar jobs concurrently on the same warehouse which are executing similar code in parallel, you could get compilation memory issues as the SQL gets compiled and estimates the execution plan, which can lead to use of maximum compilation memory at the same time. To prevent this, you could split the code depending on the number of parallel jobs you have to run concurrently. Or you could modify your job schedule so similar jobs do not run in parallel and exhaust memory. SAP OData Service for Data Extraction on SAP BW
CTE clauses can cause runtime issues like increasing time for reading partitions
CTEs or Common Table Expressions is a result set, temporarily named that can be referenced within a SELECT, INSERT, UPDATE, or DELETE statement or even be used in a View. The CTE clause can be used in a query to decrease code complexity and can be used in multiple union statements. Sometimes objects from CTE (simple CTE with single objects) if used directly in union select statements, can take a longer than expected time to scan partitions. A possible solution would be to use CTE table at all possible places in all union select statements, or not to use the CTE table at all, incorporating the direct object at all places in union select statements. It is advisable never to use a combination of CTE & direct object to prevent such situations. SAP to AWS (Specifically S3)
Steps involved in moving data from SAP HANA to Snowflake
The journey from SAP HANA to Snowflake is complex and can be broken down into steps to simplify it. Here’s how it generally goes. SAP to AWS (Specifically S3)
Step1: Consider what needs to be taken to Snowflake from SAP HANA
Among these you should think about which tables and databases you need to take across, which of your team members, roles and applications have access, which scripts and applications are engineering the current data load? Besides this, check out the frequency of data updates and the data consumption pattern. Get the details down and estimate the Snowflake support level you will need for inputs and outputs. The list will also be used as a component of the QA process. SAP S/4 HANA Overview and 5 Ways to Extract S/4 ERP Data
Step2: Low -level Design and Execution Plan for SAP HANA Snowflake migration
Your basic documentation is now done, and we can move towards formulating an execution plan. It is advisable to do the entire movement from SAP to Snowflake in phases, rather than doing it in one go. First shift the low-impact tables, databases, and applications, and then manage the complex syncing tasks. How to Carry Out a Successful SAP Cloud Migration
Based on the analysis of data (first step), divide the databases and tables as per logical phases. The first phase should involve tables that need very few changes and do not affect your business much. Plan an A-to-Z migration of full vertical slices including end to end ingestion, data migration and data consumption. Avoid hand-coding and search for tools that can automate the process and speed it up, like our very own BryteFlow. Your plan should have detailed information of the tables and columns being moved, as well as how it can affect performance. It should also have a migration timeline and a list of all user transactions that need to be captured and processed in advance. Test the migrated data before moving. Reliable SAP CDC and Data Provisioning in SAP
Step 3: Set Up your SAP HANA and Snowflake Accounts
Now that you have your execution plan, it’s time to set up your SAP HANA and Snowflake accounts to meet your needs. You can use the Snowflake UI/CLI to configure databases and warehouses, and to create users and accounts on Snowflake. Ensure the deployment settings are updated, so that they match those of the old system. RISE with SAP (Everything You Need to Know)
Step 4: Set up an SAP data extractor
The next step is to set up a mechanism to extract SAP data. SAP allows for connecting with data through APIs and ODBC/JDBC drivers. You can use a programming language of choice to write scripts to extract SAP data. Please extract data from all custom fields and save type information as type information – it will come in handy when creating tables on Snowflake. Store the data in a typed format using JSON/AVRO formats instead of CSVs. Create an SAP BW Extractor
Note: We recommend using an automated SAP ETL tool like BryteFlow for a fully automated SAP analysis, extraction setup. BryteFlow creates tables and business logic automatically on target (in this case Snowflake) and can extract data from SAP applications as well as databases (if access is available to the underlying database). SAP Extraction using ODP and SAP OData Services (2 Easy Methods)
Step 5: Create Snowflake tables
You now need to create a Snowflake table for the data that has been extracted. You will need to map SAP HANA field types to Snowflake field types. If you have a typed format as suggested in Step 4, this can be quite simple. You may also have to do some renaming of columns if they are not following Snowflake column naming conventions. Once again, we suggest using an automated SAP ETL tool like BryteFlow that does data conversions out-of-the-box and delivers ready to use data on Snowflake. How to Migrate Data from SAP Oracle to HANA
Step 6: Load data into Snowflake
Before this step, please create a backup of the SAP HANA database. Then create a staging area within Snowflake to receive your data. After exporting, add the data into the new Snowflake schema. Make data modifications if needed and export it into the Snowflake database.
Step 7: Schedule the migration from SAP HANA to Snowflake
Get a scheduler to run the migration steps at the frequency you desire. BryteFlow is one SAP ETL tool where you can schedule the migration as needed – automated mode (runs when there are changes at source) or even hourly, weekly monthly or customized as per need. The SAP Cloud Connector and Why It’s So Amazing
Step 8: Optimize the SAP HANA to Snowflake Process
Your data is now in Snowflake but going forward, is it possible to optimize the process? For one, you can try and automate the process with tools like BryteFlow. Another obvious thing to do is to load a snapshot of the data first and subsequently load only the deltas, using Change Data Capture. Also, APIs can be built for Snowflake to provide application access or for sharing tables. Snowflake CDC With Streams and a Better CDC Method
Data-type Mappings between SAP HANA and Snowflake
The table below outlines the recommended mappings of data types for Mass Ingestion Database setups, involving either an SAP HANA or SAP HANA Cloud source and a Snowflake target. Source
| SAP HANA Source Data Type | Snowflake Target Data Type |
| alphanum(precision), 1 <= p <= 127 | char(size), 1 <= size <= 127 |
| array | binary |
| bigint | integer |
| binary(size), 1 <= size <= 2000 | binary(size), 1 <= size <= 2000 |
| boolean | boolean |
| char(size), 1 <= size <= 2000 | char(size), 1 <= size <= 2000 |
| date | date |
| decimal | char(255) |
| decimal(38,38) | char(41) |
| decimal(p,s), 1 <= p <= 38, 0 <= s <= 37 | number(p,s), 1 <= p <= 38, 0 <= s <= 37 |
| double | float |
| float | float |
| integer | integer |
| nchar(size), 1 <= size <= 2000 | char(size), 4 <= size <= 8000 |
| nvarchar(size), 1 <= size <= 5000 | varchar(size), 4 <= size <= 20000 |
| real | float |
| seconddate | timestamp_ntz(0) |
| shorttext(precision), 1 <= p <= 5000 | varchar(size), 1 <= size <= 5000 |
| small decimal | char(255) |
| smallint | integer |
| st_geometry | binary |
| st_point | binary |
| time | time(0) |
| timestamp | timestamp_ntz(precision), 0 <= p <= 7 |
| tinyint | integer |
| varbinary(size), 1 <= size <= 5000 | binary(size), 1 <= size <= 5000 |
| varchar(size), 1 <= size <= 5000 | varchar(size), 1 <= size <= 5000 |
Unsupported source data types:
- alphanum (SAP HANA Cloud only)
- array
- bintext
- blob
- clob
- char (SAP HANA Cloud only)
- nclob
- st_geometry
- st_point
- Text
Methods to load data from SAP HANA to Snowflake
There are many methods available to transfer data from SAP HANA to Snowflake. We are demonstrating two methods here:
- A manual method using DBeaver to transfer data from SAP HANA to Snowflake.
- An automated method using a third-party, automated tool – BryteFlow.
1. A Manual Method to load data from SAP HANA to Snowflake.
This tutorial demonstrates a systematic approach for manually connecting and transferring data from SAP HANA to Snowflake. The process involves generating data in CSV format using DBeaver and subsequently importing it into Snowflake.
About DBeaver
DBeaver is a highly adaptable database management tool crafted for the requirements of data experts. It serves dual roles as a SQL client and an administration tool, employing JDBC for relational databases and proprietary drivers for NoSQL databases. Prominent attributes comprise code completion, syntax highlighting, and a plug-in framework, enabling customization of database-specific features. Built using Java on the Eclipse platform, DBeaver offers a free, open-source Community Edition licensed under the Apache License. It also offers an Enterprise Edition for which you need a commercial license. DBeaver can be used to transfer data in multiple formats and sources, besides being used to analyze, compare, and visualize data.
Broadly these are the main steps for manually migrating CSV data from SAP HANA to Snowflake
1.1 Extract data from SAP HANA using DBeaver and store it temporarily.
1.2 Transfer the data to Snowflake for further processing.
1.1: Export SAP HANA data to an interim storage location via DBeaver.
Employ DBeaver to move the data to a temporary storage area before importing it into Snowflake. Follow the steps provided below to start the export process:
Step 1: Open DBeaver and establish a connection to the SAP HANA Database. Expand your database schemas and locate the desired “Table” slated for migration. Select “Export Data” to initiate the migration process.
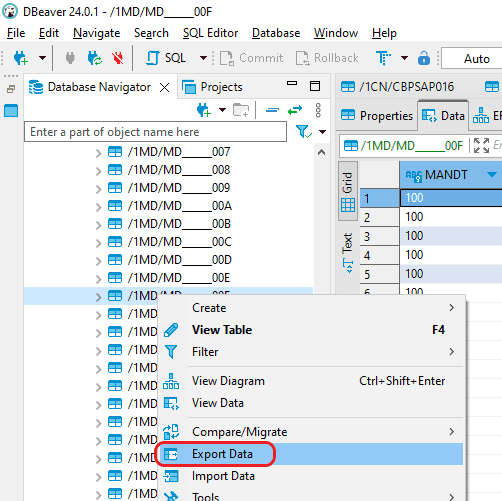
Step 2: Choose the “CSV” option in the “Export target” window, then proceed by selecting the “Next” button.
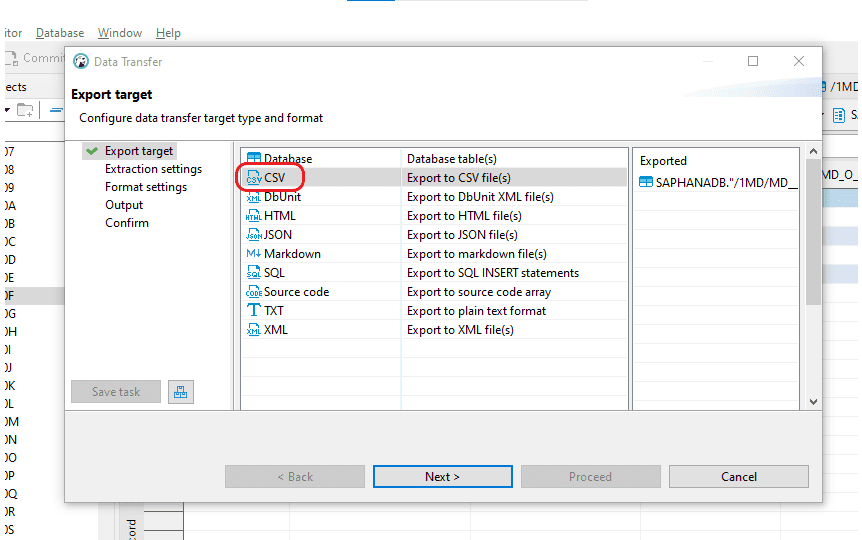
Step 3:
- In the “Extraction settings” window, maintain the current configurations and proceed by clicking “Next.”
- In the “Format settings” window, retain the current configurations and proceed by selecting “Next.”
Step 4: In the “Output” section, you can specify the location for generating the output CSV file. Keep the remaining settings unchanged and proceed by selecting “Next.”
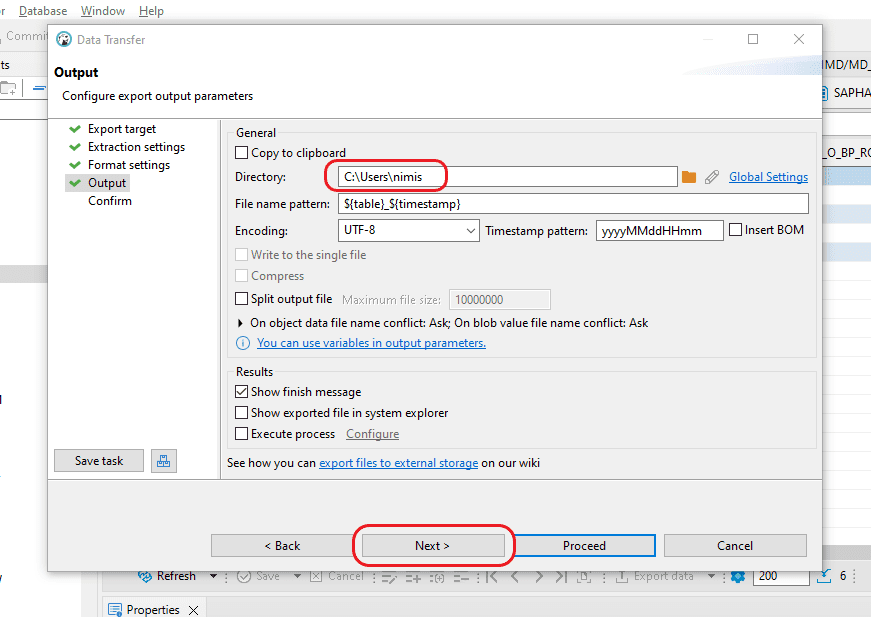
Step 5: Within the “Confirm” window, you can review details such as the “Source Container,” “Source” (including Schema and Table name), “Target location” for CSV file creation, and “File name and type.” Once you’ve verified that all information is correct, just click the “Proceed” button to generate the file.
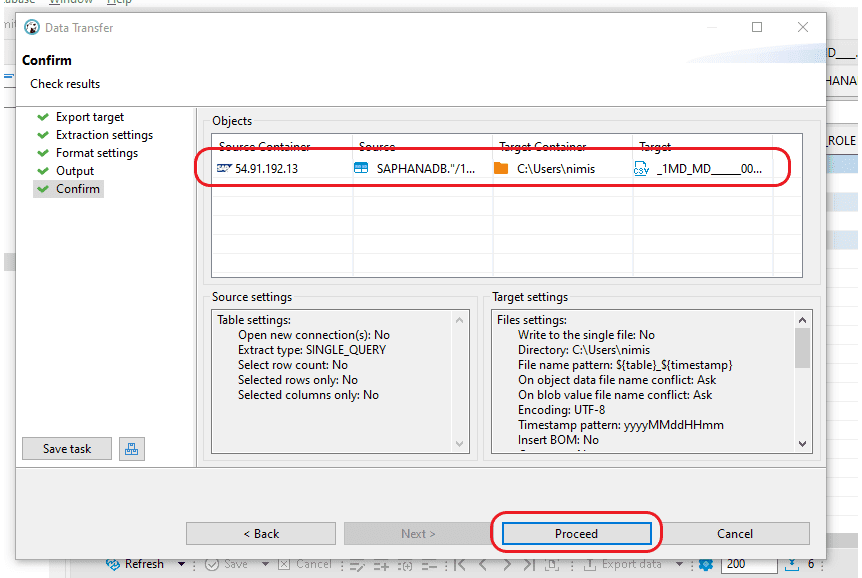
Step 6: Confirm the specified location to ensure the CSV file has been generated.

1.2 Manually upload the data into Snowflake
Step 1: Access Snowflake by logging in. Once logged in, navigate to your Database and Schema.
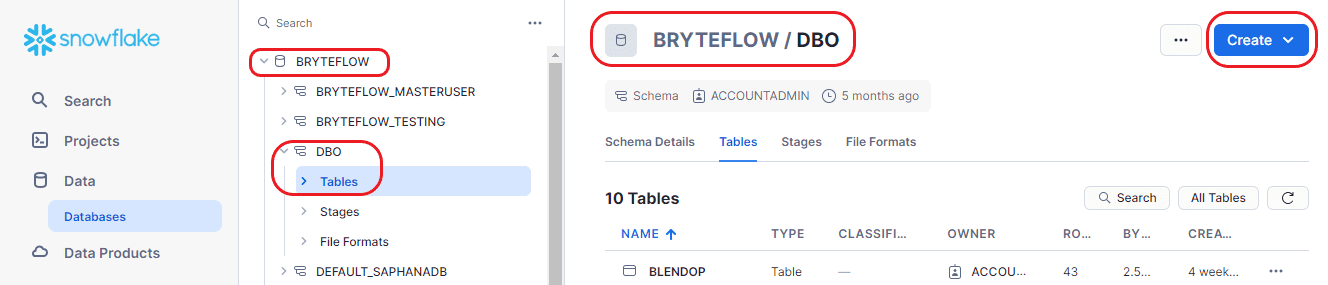
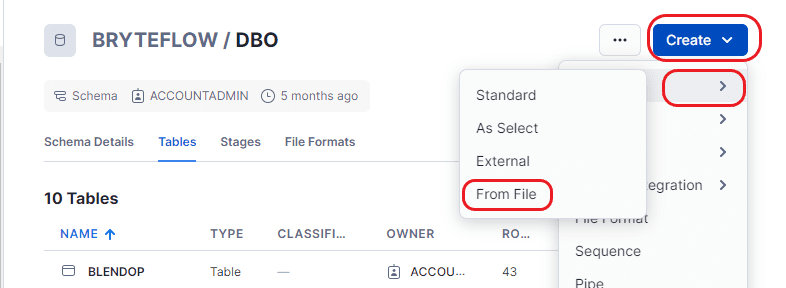
Step 2: After accessing the database, choose “Tables” from the “Create” dropdown menu, and then opt for the “From File” option to load the new table.
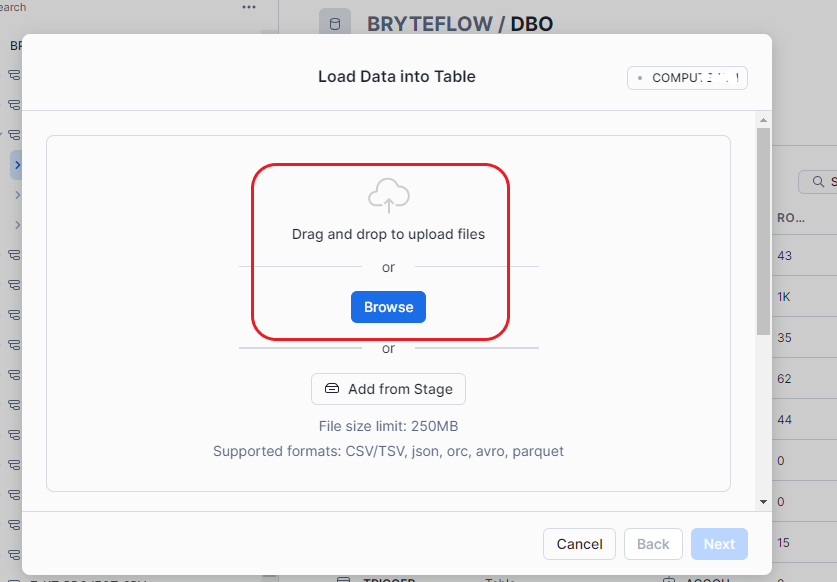
Step 3: Please upload the source file by dragging and dropping it into this area, or by browsing your files to locate and select it.
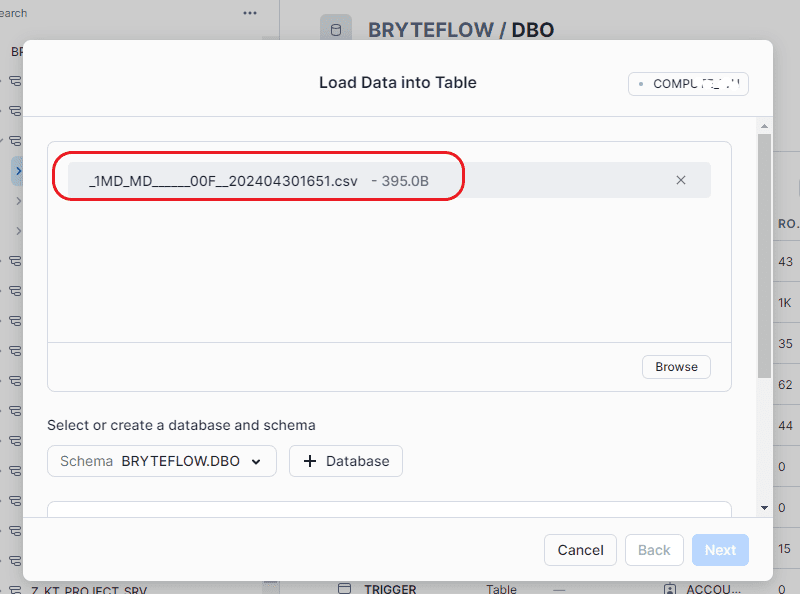
Step 4: After selecting the table, provide a name for it. Once completed, proceed by clicking on “Next.”
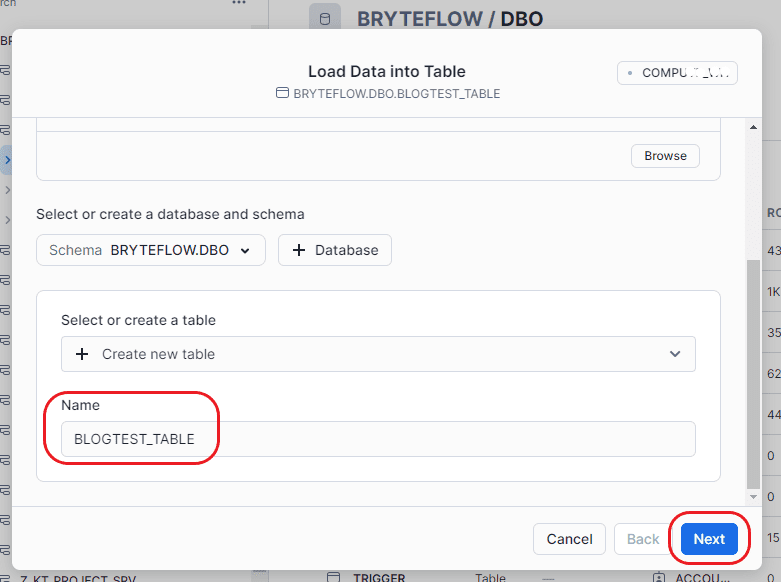
Step 5: At this juncture, you can rectify data discrepancies within the source table. The interface also alerts you to any disparities in data structure between SAP HANA and Snowflake. Additionally, you have the choice to either “Do not load any data” or “Only load valid data from file” when encountering an error.
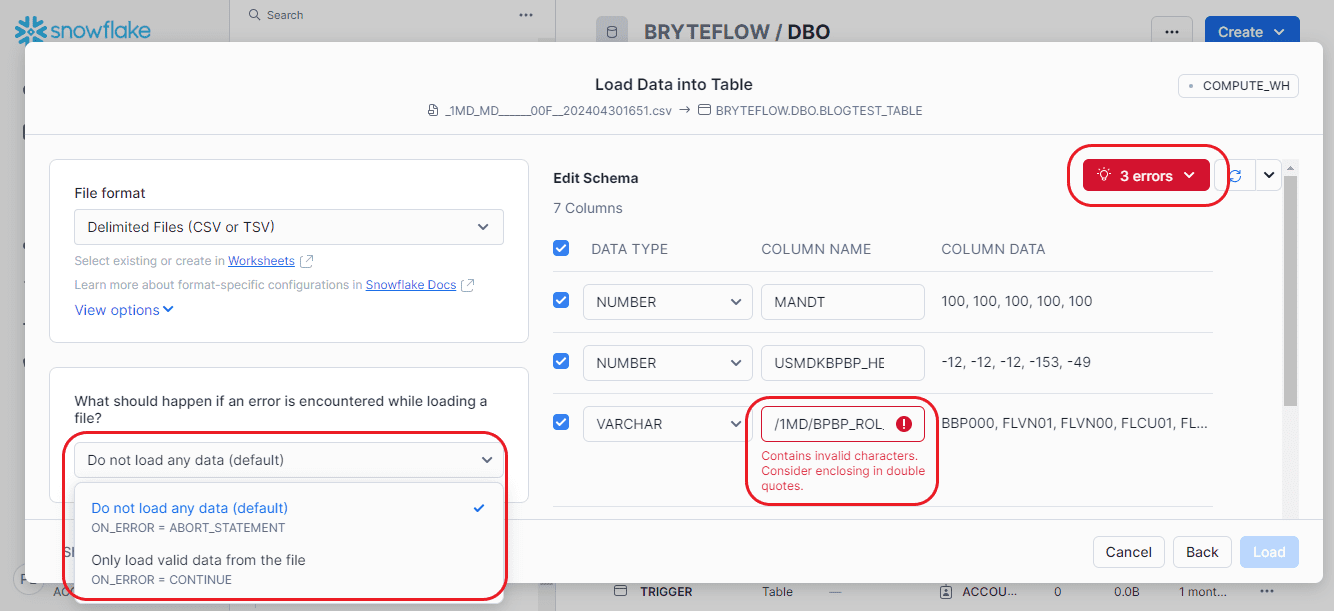
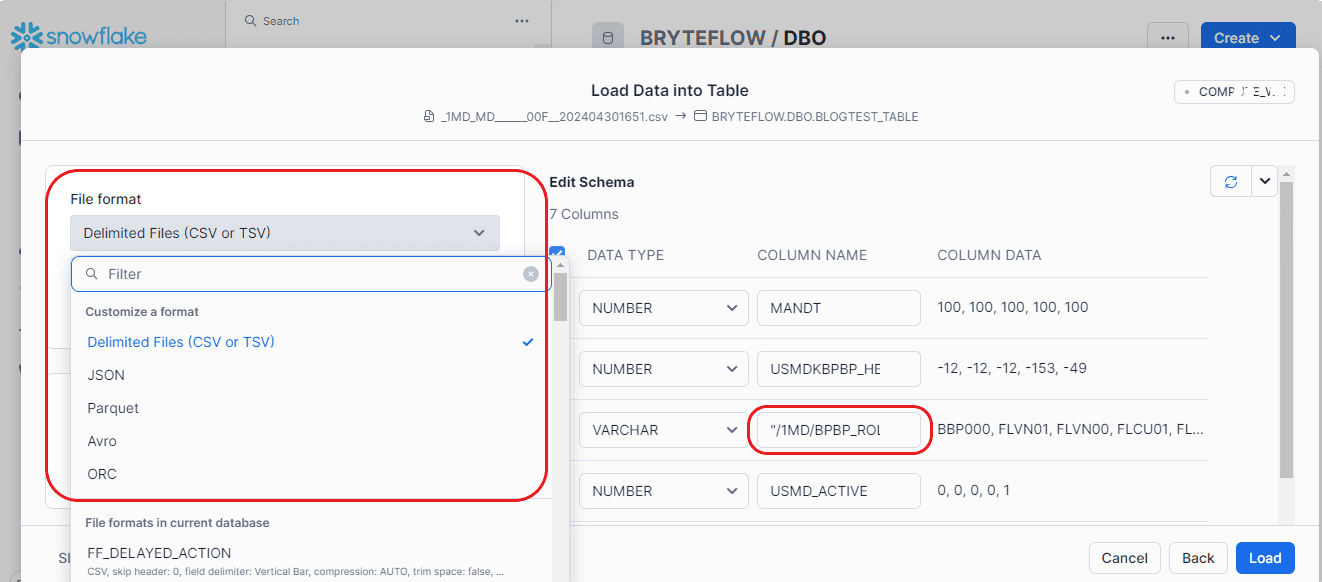
After rectifying the error, you can choose the desired format for the source file. Once done, select the “Load” option and choose the appropriate settings.
Step 6: This page displays the path of the loaded tables, along with the number of records loaded, and indicates whether the table creation was successful.
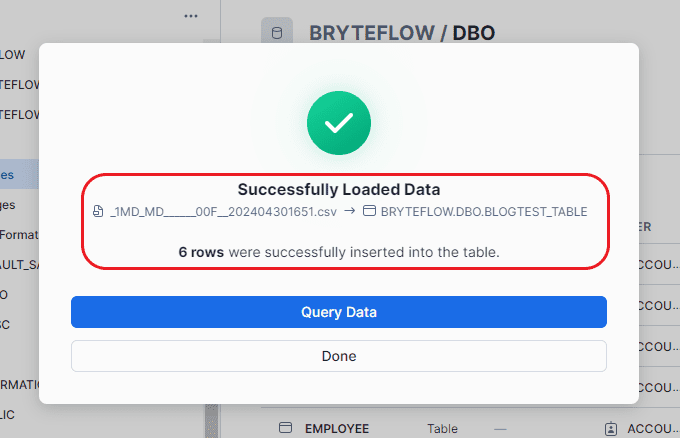
Step 7: Confirm the loaded data through table querying.
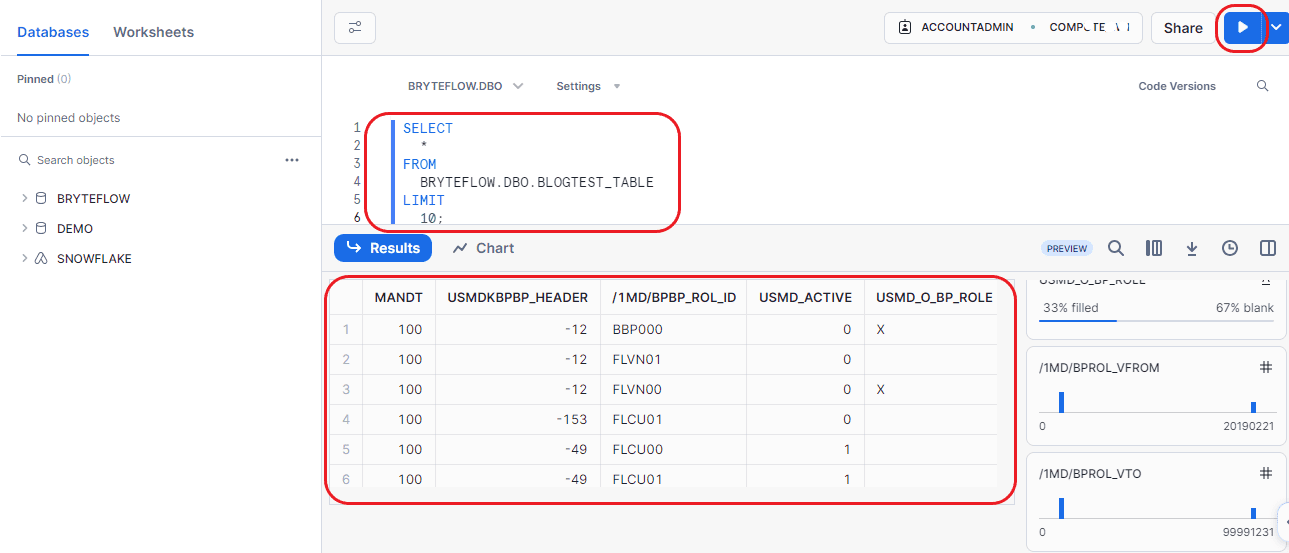
2. An Automated Method to transfer data from SAP HANA to Snowflake using BryteFlow.
BryteFlow Ingest has a user-friendly interface and an automated, streamlined process. All you need is a couple of clicks and BryteFlow Ingest handles the rest.
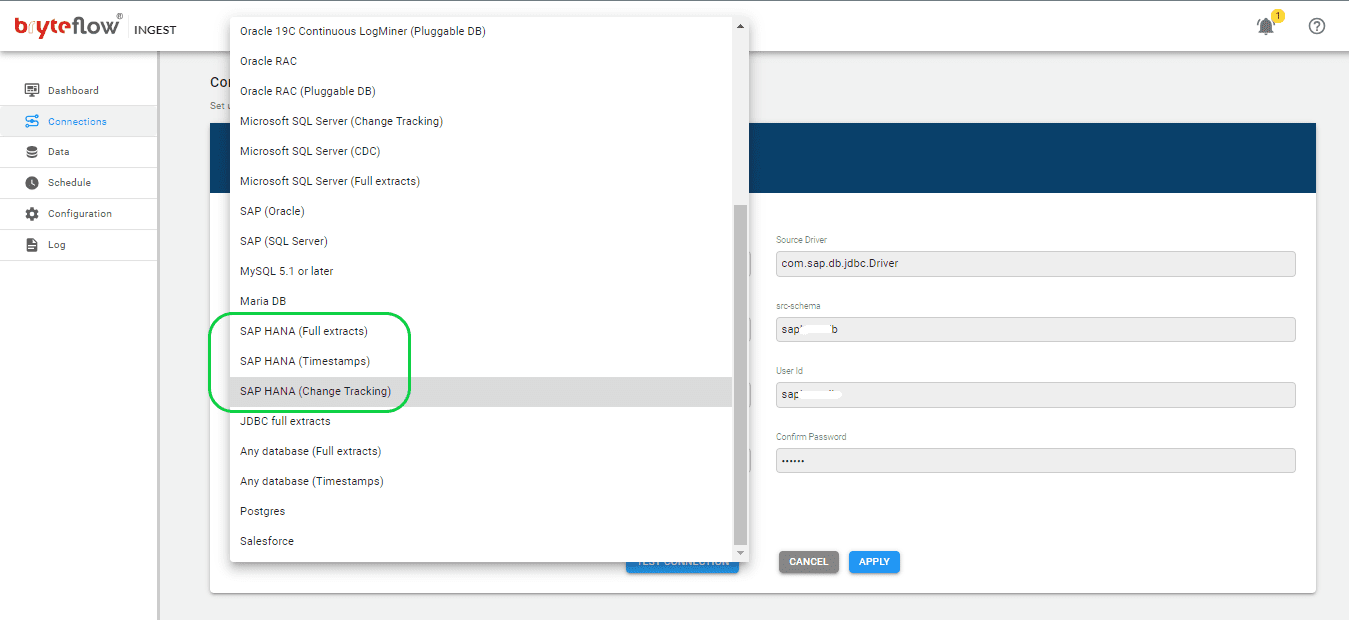
Step 1: Download and Install BryteFlow Ingest, login and Configure Source Database.
Install BryteFlow Ingest from the AWS Marketplace or Azure Marketplace, depending on your environment. After installation, login and navigate to the “Connections” tab in the left navigation panel. Choose the “Source Database” option and follow the subsequent steps to set up your source database.
- Choose “SAP HANA (Full Extracts or Timestamps or Change Tracking)” as the Database Type from the options provided.
- Complete the Source Driver details in the “Source Driver” field.
- Provide the Source URL details in the “Source URL” field.
- Enter the src-schema details into the designated “src-schema” field.
- Input the User ID used for Database connection in the User ID field.
- Enter the corresponding User password for Database connection into the Password field.
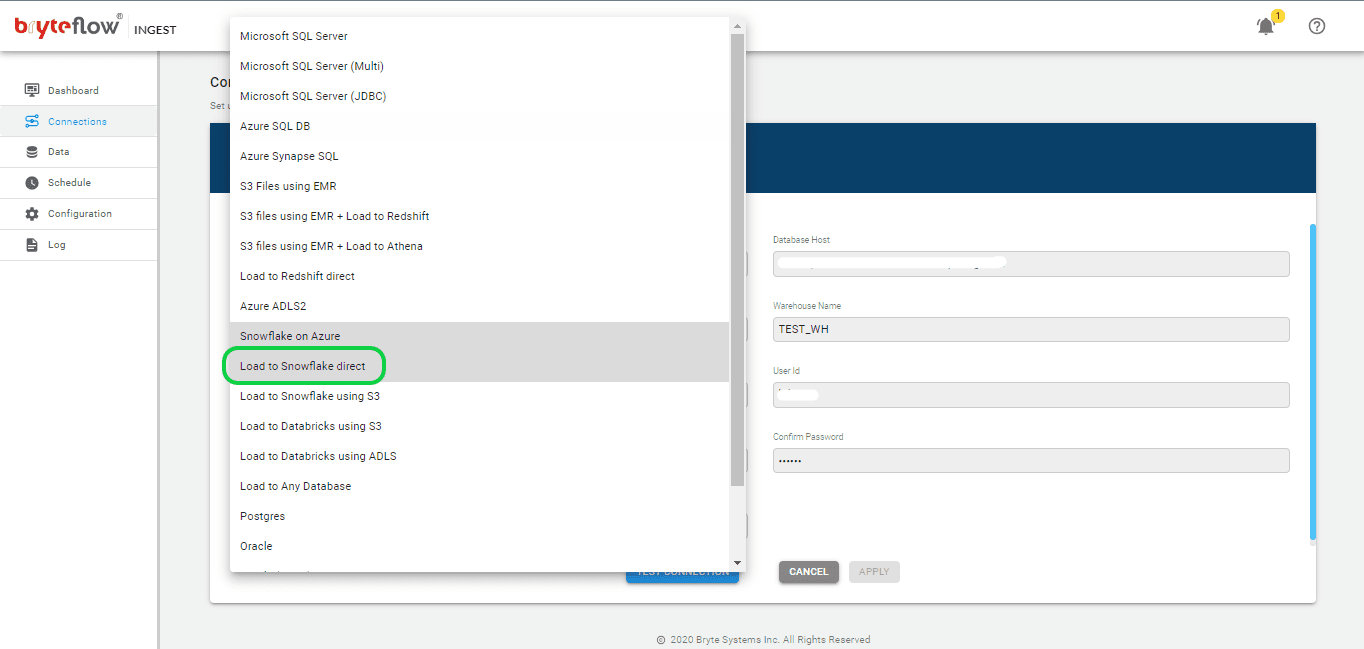
Step 2: Setup Connection Configuration for Snowflake
Select the Destination tab within the Connections screen, and feed in the following information to establish a connection with AWS Snowflake since we are loading data to Snowflake on AWS. Choose “Load to Snowflake direct” as an option to load data directly to Snowflake on AWS. Obtain and update the following details.
- Choose “Load to Snowflake direct” from the dropdown menu for Database Type.
- Input the host details for Snowflake in the Database Host section.
- Provide the account details for Snowflake as the Account Name.
- Enter the details for the Snowflake warehouse in the Warehouse Name field.
- Update the Database name in the appropriate field.
- Update the User Id in the specified area.
- Input the password in the Password field.
- Re-enter the password to confirm it in the Confirm Password field.
- Update JDBC details in the JDBC Options section.
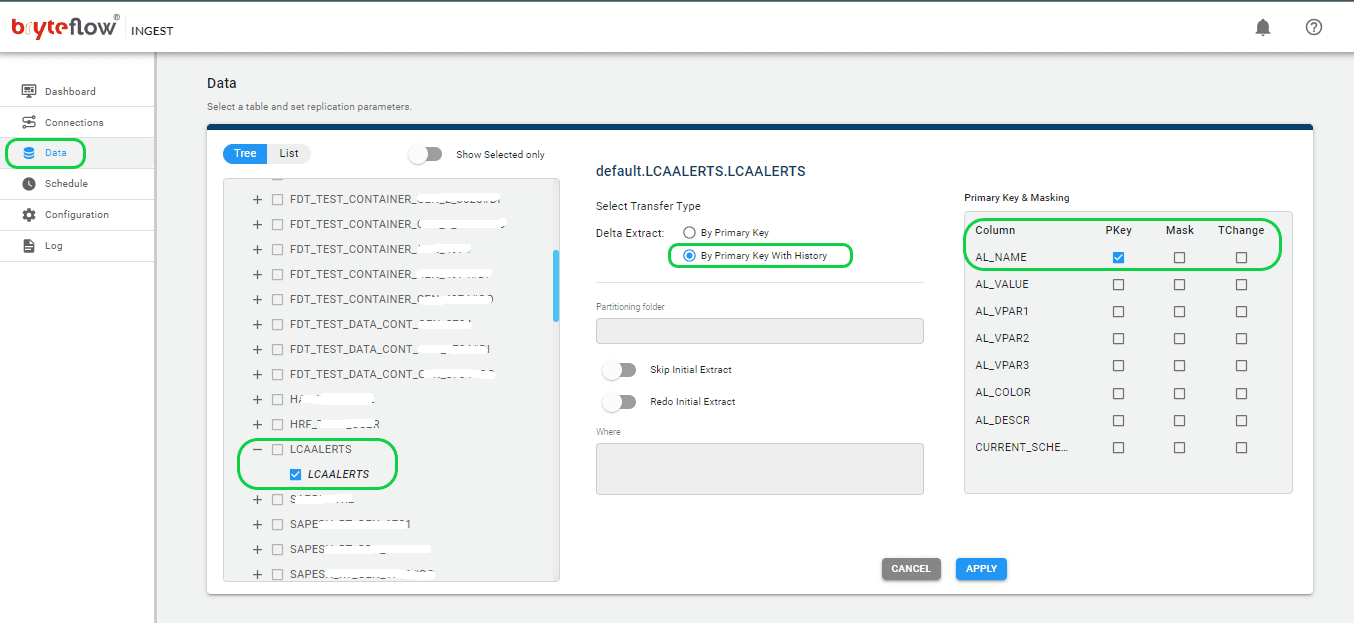
Step 3: Select the tables you want to replicate.
Select the “Data” section in the left panel to set up the source table(s) for replication. Here, you need to define the primary key and transfer method for each table. Opting for ‘By Primary Key with History’ ensures the preservation of SCD Type2 history automatically. Alternatively, selecting ‘By Primary Key’ creates a mirrored replica of the source table, excluding historical data. Additionally, you can use the “Where” feature to filter out undesired data, and Byteflow Ingest offers the capability to “mask” sensitive data within columns.
Step 4: Schedule the data replication
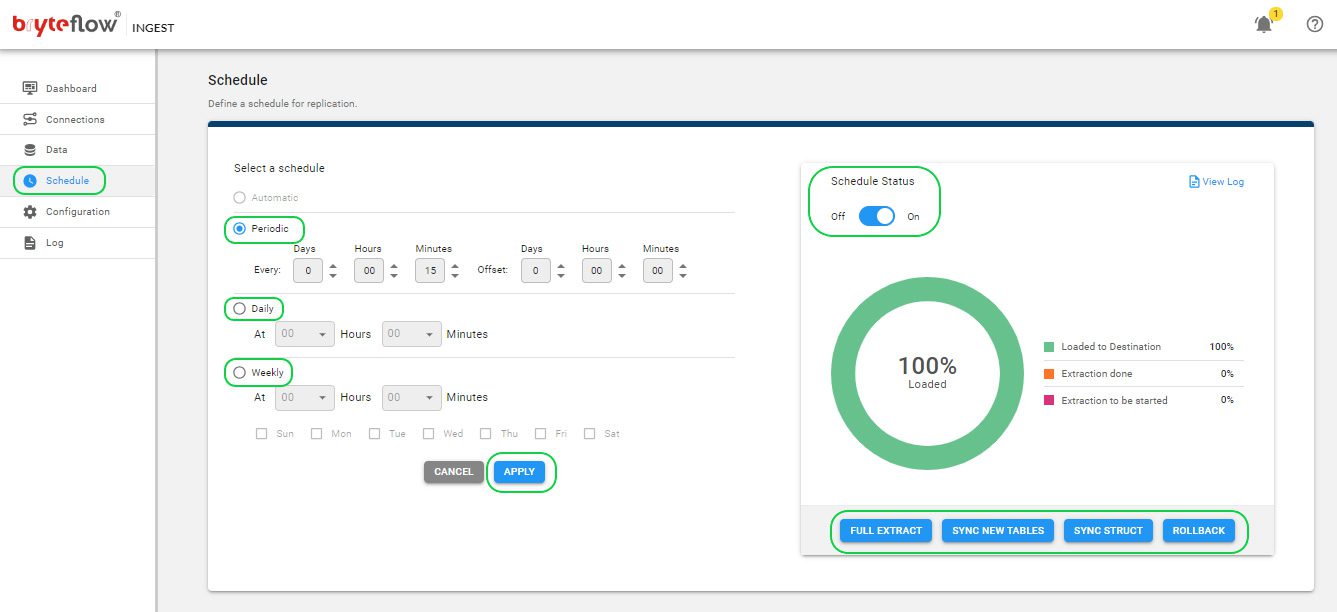
Once you’ve selected the tables, establish a schedule for data replication to ensure a smooth transfer of your data to Snowflake, in near real-time. You have the flexibility to choose between “Periodic,” “Daily,” or “Weekly” options. Opt for the “Full Extract” setting for the initial load, “Sync New Tables” to incorporate new tables after activating replication, “Sync Struct” for replicating structural modifications in existing tables, and “Rollback” to revert to a successful previous run, especially useful in case of replication interruptions due to any outages.
Monitor the progress
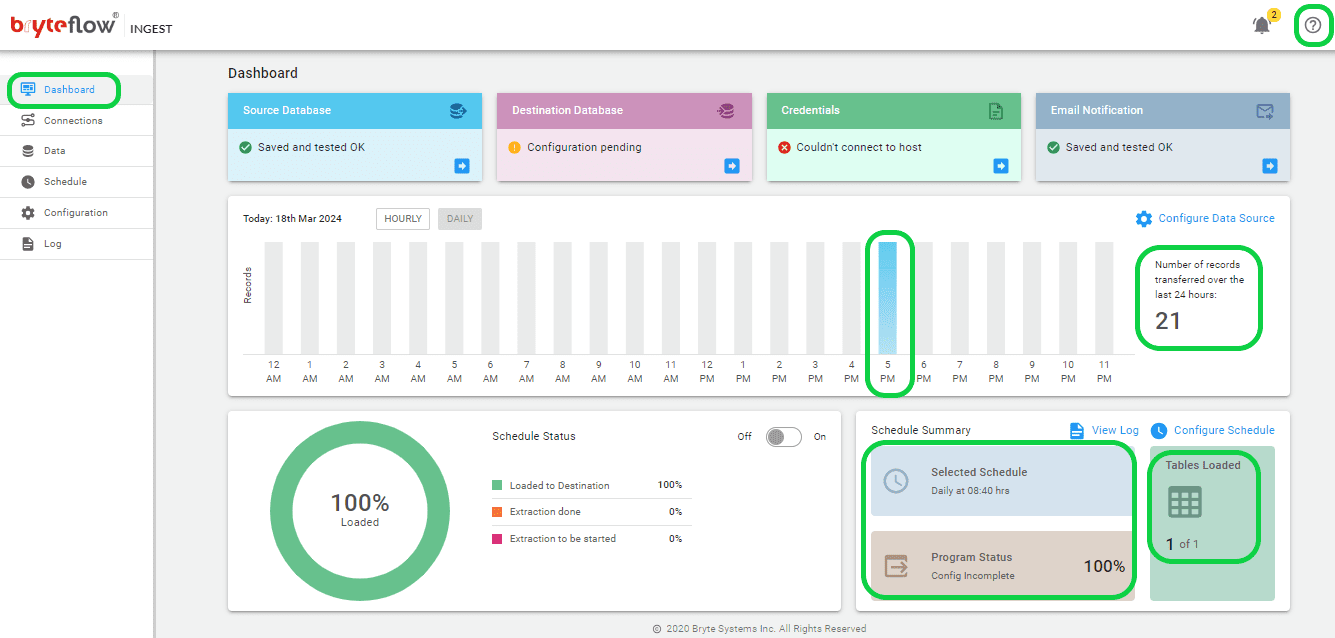
After the outlined steps are done, data replication from SAP HANA to Snowflake will commence automatically according to the scheduled time. Progress tracking is easily done via the Ingest Dashboard, offering details BryteFlow Ingest operations. This section encompasses vital features such as:
- Information on the total loaded records.
- The number of loaded tables.
- Current loading status of ingestion.
- Updates on Connection status.
- Details regarding replication frequency.
Differences between the manual method and an automated method (using BryteFlow) for delivering data from SAP HANA to Snowflake
Here is a comparison matrix that shows how using BryteFlow instead of a manual method for replication, can make the process faster, easier, and simpler, and highly reduce the efforts required from your team.
| Feature | Manual Method | BryteFlow |
| Syncing and maintaining data | Completely reliant on human effort for adding, editing, updating, and verifying the data. | The software automatically syncs data with changes at source using Change Data Capture as per schedule. |
| Coding for ELT process | A large amount of manual coding is required for a lot of processes. | Automates all processes, including data extraction, CDC, merges, data mapping, masking, schema and table creation, SCD Type2 history etc. |
| Scalability | Database size must be manually expanded for the inflow of new data. Careful manual monitoring is essential to prevent database failures resulting from insufficient space. | Can handle vast volumes of enterprise data with parallel, multi-thread loading and smart configurable partitioning, all without impacting source systems. |
| Schema Creation | Manual schema creation is needed based on the destination database. | Automatically generates schemas without the need for coding and even manages complex schema modifications. |
| Data Type Conversion | Data types must be manually converted to align with the destination database before loading. | BryteFlow seamlessly conducts data type conversions out-of-the-box. |
| Throughput | Manual processes need more time to complete. | Rapidly loads data with impressive throughput, processing approximately 1,000,000 rows in just 30 seconds. |
| Migration size | Method is suitable for smaller migrations, and probably cannot handle very large EDWs. | Ideal for very large enterprises and global business, automatically migrates petabytes of data. |
| Data Validation | Human intervention in manual data collection increases the risk of transcription errors, omissions, and misinterpretations, compromising data reliability and leading to erroneous production management decisions. | Reconciles data automatically through a seamless integration with BryteFlow TruData, using row counts and columns checksum. |
| CDC | Manual scripts are needed to extract data from logs. | Implements automated CDC for incremental SAP data replication. |
| Historical Data | Implementing options for getting historical data can be challenging. | Offers automatic availability of SCD Type2 data for easy versioning and historical data retrieval. |
| Training | Coding expertise and skilled developers will be needed for operation, some training may be required. | Simple to use, even an ordinary business user can use the software. Minimal involvement of DBA. |
| Error likelihood | A manual process is always more likely to generate errors since human effort is involved. | BryteFlow is a fully automated tool, it reduces human intervention and hence likelihood of errors. |
| Network Failure | Manually restarting the process might be required. | Provides automated catch-up and resumes from the point of stoppage when normal conditions are restored. |
| Flexibility | Each connection needs to be manually created. | Offers flexible connections for SAP, including Database logs, ECC, HANA, S/4HANA, SAP SLT, and SAP Data Services. |
| Affordability | Considering the time taken for the process and developer expertise needed, the process is very expensive. | Our plug-and-play replication software is completely automated. No coding needed, hence cost-effective. |
BryteFlow Ingest and BryteFlow SAP Data Lake Builder for SAP migration
This blog demonstrates the use of BryteFlow Ingest using trigger-based CDC to ELT data from an SAP HANA database to Snowflake. You should note we also have another tool – the BryteFlow SAP Data Lake Builder that can extract data from SAP applications and ERP systems directly, keeping business logic intact, and creating tables automatically on destination. This is especially useful if you lack access to the underlying database, extracting data from SAP applications can help avoid expensive licensing requirements. SAP Extraction using ODP and SAP OData Services
BryteFlow Ingest as well as the BryteFlow SAP Data Lake Builder can move and integrate your data with data from non-SAP sources on scalable platforms (On-premise and Cloud) like Snowflake, Redshift, S3, Azure Synapse, ADLS Gen2, Azure SQL Database, Google BigQuery, Postgres, Databricks, SingleStore or SQL Server
Conclusion
In this blog you learned about moving data from SAP HANA to Snowflake, why it is important, benefits and the steps involved in SAP HANA Snowflake migration. We also provided 2 methods for the SAP HANA Snowflake migration including a manual one using DBeaver, and a completely automated one using BryteFlow Ingest, a pre-built connector customized for SAP data integration.
Like to know more? Contact us for a Demo




