
If you have chosen Snowflake to be your cloud data lake or your data warehouse, how do you get your data to Snowflake fast, especially when you have large amounts of data involved? An Alternative to Matillion and Fivetran for SQL Server to Snowflake Migration
A word about Snowflake
Snowflake is a zero-maintenance, fully managed, cloud-based data warehouse that is well known for its ease of use and infinite scalability. Snowflake has a cloud architecture that separates storage and compute and supports different cloud environments. Being a fully managed data warehouse, you do not need to actively manage your clusters. The compute, storage and cloud services layers are integrated but scale independently which makes it a perfect platform for varying workloads. Learn how to cut costs on Snowflake by 30%
A columnar database based on SQL
Snowflake has a columnar database engine that is based on SQL. Easy as it is to use, it can be challenging to get large amounts of data loaded to Snowflake as a one-time activity or as an on-going activity. Especially when the data latency from different disparate sources to Snowflake needs to be low. One thing to keep in mind is that Snowflake being a columnar database, it is preferable to avoid inserting data into Snowflake row by row – it can be excruciatingly slow. How to load SQL Server to Snowflake in 4 easy steps
Loading data with staged file storage
To help with fast loading of bulk data, Snowflake has a Staging feature. Snowflake can store data internally or externally i.e. within its own environment or on other cloud storage environments. These storage locations whether external or internal are called stages and the uploading of files to these locations is called staging. Databricks vs Snowflake: 18 differences you should know
Though an AWS S3 bucket or Azure Blob storage is the most common external staging location, data can also be staged on the internal Snowflake stage. The internal stage is managed by Snowflake, so one advantage using this stage is that you do not actually need an AWS or Azure account or need to manage AWS or Azure security to load to Snowflake. It leverages the Snowflake security implicitly. Flows optimized for Snowflake can be used to extract data from any supported source, transform it and load to Snowflake directly. 6 reasons to automate your Data Pipeline
A Snowflake flow is comprised of these operations:
- Extraction of the data from source Transform data with BryteFlow’s ETL in Snowflake
- Creation of Avro, XML, ORC, CSV, JSON, or Parquet Our Blog explains the differences between Avro, ORC and Parquet file formats.
- Compression of files using the gzip algorithm. SQL Server to Snowflake in 4 Easy Steps
- Copying of files to the Snowflake stage, either S3, Azure Blob or internal stage. Compare Databricks vs Snowflake
- Checking to confirm the destination Snowflake table is in place, if not, creating the table from source metadata.
- Using the Snowflake “COPY” command to load data in bulk.
- Clean-up of remaining files if required. Data Migration 101 (Process, Strategies and Tools)
What to keep in minding when loading huge amounts of data to Snowflake
Preparing Data files
Prepare the files as below:
- General File sizing: For maximum parallel loads of data we suggest you create compressed data files approx. 10MB to 100 MB.
- Smaller files can be aggregated to cut processing time. Also faster loading can be achieved by splitting large files into smaller files. You can then distribute the load across Snowflake servers for higher speed. Databricks vs Snowflake: 18 differences you should know
- It is better to use COPY INTO rather than INSERT since the former uses more efficient bulk loading mechanisms. Postgres to Snowflake : 2 Easy Methods of Migration
Data Load Planning
For large data sets, loading and querying operations can be dedicated to separate Snowflake clusters to optimize both operations. The standard virtual warehouse is adequate for loading data as this is not resource-intensive. You can decide the warehouse size based on the speed at which you want to load the data. Note: splitting large data files is always recommended for fast loading. ELT in Data Warehouse
Loading large tables
It is recommended that if you are doing a bulk load (e.g. for an initial migration) it is ideal to load day-by-day, or in the order you want to your data to be sorted, for querying. So, for dates, for example fire a “COPY” command for each day. This is so that we automatically cluster the data under the covers to help with queries. If the table is large, you could use a clustering key. A clustering key is a subset of columns in a table (or expressions on a table) that are explicitly designated to co-locate the data in the table in the same micro-partitions. This should be used with care and only for large multi-terabyte tables. An Alternative to Matillion and Fivetran for SQL Server to Snowflake Migration
Staging Data
Snowflake, Azure and S3 support stage references with paths. You can use paths to stage and partition regular datasets. Partitions created with details like location, application, with the date of writing data, can be used to cut down time in future data loading. With a single command you can simply copy any part of the partitioned data into Snowflake. Data can be copied to Snowflake by the hour, day, month, or year when the table was initially populated. This helps you run concurrent COPY statements that match a subset of files and take advantage of Snowflake’s parallel loading operations for faster loading. Here’s Why You Need Snowflake Stages (Internal & External)
Terabyte data load comparison based on different file formats.
Data loading time is also affected by the file formats you use. Snowflake conducted an experiment recently to test loading speed of different file formats like CSV, Parquet and ORC. The source table contained 28.8 billion rows representing 4.7 TB of uncompressed data, roughly 164 bytes per row and Snowflake compressed this down to 1.3 TB internally. Source
Then they loaded the table in different source formats:
- CSV files gzipped
- Date-partitioned Parquet files (snappy compressed)
- Date-partitioned ORC files (snappy compressed)
Load Performance
The data was loaded using a Snowflake 2X-large cluster. This is the performance recorded:
Source Format |
Target Layout |
Load Time (sec) |
TB/Hr (uncompressed) |
| CSV (Gzipped) | Structured | 1104 | 15.4 |
| ORC (Snappy comp) | Semi-structured | 3845 | 4.4 |
| ORC (Snappy comp) | Structured | 2820 | 6.0 |
| Parquet (Snappy comp) | Semi-structured | 3518 | 4.8 |
| Parquet (Snappy comp) | Structured | 3095 | 5.4 |
A few points stand out immediately:
Loading speed from Gzipped CSV worked out to 15 TB/hour and was several times faster than loading from ORC and Parquet files. ORC and Parquet files delivered at 5-6 TB / hour so don’t bother creating ORC or Parquet files from CSV in the expectation that they will load faster.
It was found that loading data into a fully structured, columnarized schema is ~10 – 20% faster than loading it to a VARIANT.
Load speed was also found to be inversely proportional to the size of the warehouse when the same data was loaded to warehouses of different sizes – the larger the warehouse, the faster the loading. For e.g. the 3X-large warehouse (twice the scale of 2X-large) loaded data at twice the speed of 2X-large. How to choose between Parquet, ORC and AVRO for S3, Redshift and Snowflake?
Warehouse |
Loading speed |
| 3X-large | ~28 TB/Hour |
| 2X-large | ~14 TB/Hour |
| X-large | ~7 TB/Hour |
| large | ~3.5 TB/hr |
You will spend approx. the same amount of Snowflake credits to load a given data set regardless of the cluster size you use, as long as you suspend the warehouse after loading to avoid idle time.
Other factors that affect the loading rate of your data files:
Location of your S3 buckets
For the experiment, both the Snowflake deployment and S3 buckets were located in us-west-2.
Number and types of columns
A larger number of columns may require more time to load in relation to the number of bytes in the files.
Gzip Compression efficiency
More uncompressed bytes in data read from S3 will probably increase your loading time.
It is recommended to use enough load files to keep all loading threads busy in all cases. For e.g. a 2x-large has 256 threads and the Snowflake team used ~2000 load files to cover the five years of history.
What to look for in a data ingestion tool
It is now time to look at how to move the data to Snowflake automatically with the best practices mentioned above. The following are the characteristics you should look for in the tool:
- The tool should be secure, easy to use and set up, with end-to-end automation. Postgres to Snowflake : 2 Easy Methods of Migration
- It should be extremely fast and capable of loading data at terabyte scale. Snowflake CDC With Streams and a Better CDC Method
- It should have seamless integration with other components like data lakes and data warehouses and related solutions.
Enter BryteFlow Ingest and BryteFlow XL Ingest
BryteFlow Ingest
BryteFlow Ingest replicates data continually, delivering all the changes happening at source in real-time with log-based Change Data Capture. The replication process has minimal impact on source systems. BryteFlow Ingest needs no coding and completely automates the data replication process including creating the tables on Snowflake with an easy point and click interface and all the best practices mentioned above. It is fast to set up and deploy (get started in a single day) and is capable of loading huge datasets to Snowflake in minutes. It does parallel loading to Snowflake and keeps the data latency down. Your data can also be verified for completeness by our data reconciliation tool BryteFlow TruData so you will know if there is data missing. Snowflake CDC With Streams and a Better CDC Method
You can configure the data replication to use an internal Snowflake stage or an external stage.
BryteFlow XL Ingest
As the name suggests, this tool was created expressly to load extremely large datasets fast. XL Ingest delivers terabytes of data at high speed without slowing down of source systems. Data can be loaded in parallel to Snowflake, using multiple threads, which means you can load large datasets that much faster. This can cut down days of loading time to mere minutes. Data Migration 101 (Process, Strategies and Tools)
How to load data to Snowflake from a sample database using BryteFlow Ingest
Please ensure that all pre-requisites have been met and all security and firewalls have been opened between all the components.
Set up the connection details on the Connections screen. Assume the source is SQL Server and set up the source connection details. The source could be on the cloud or on-premises.
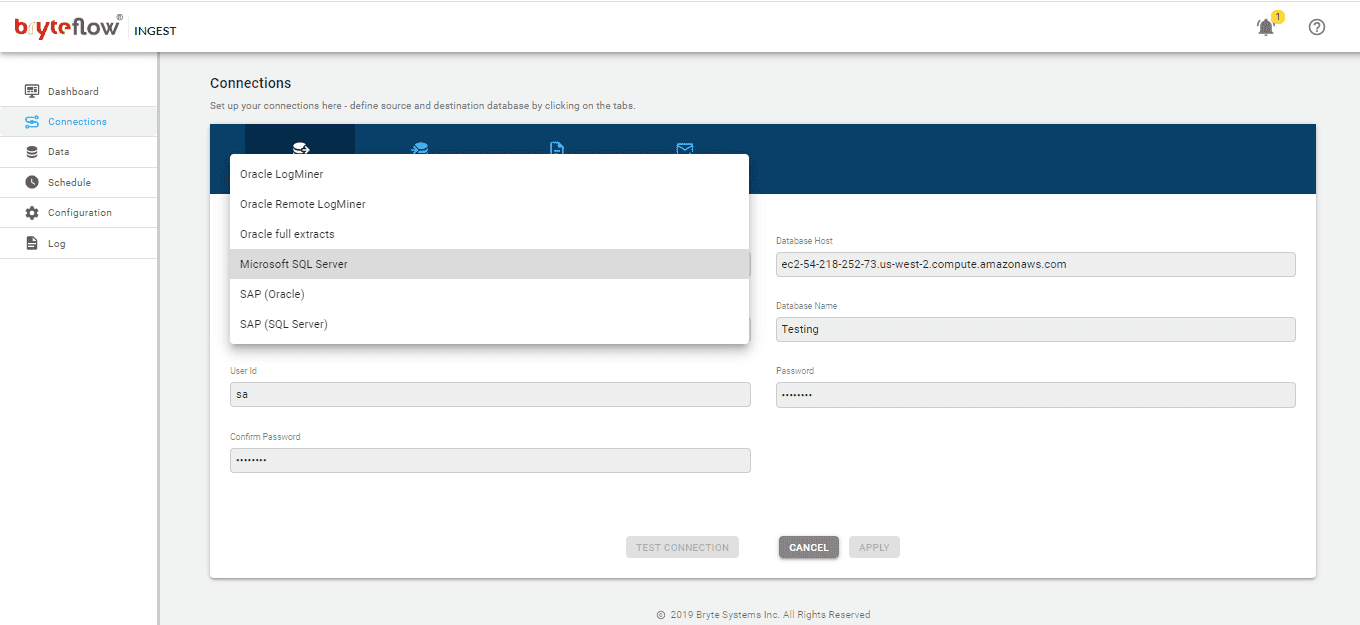
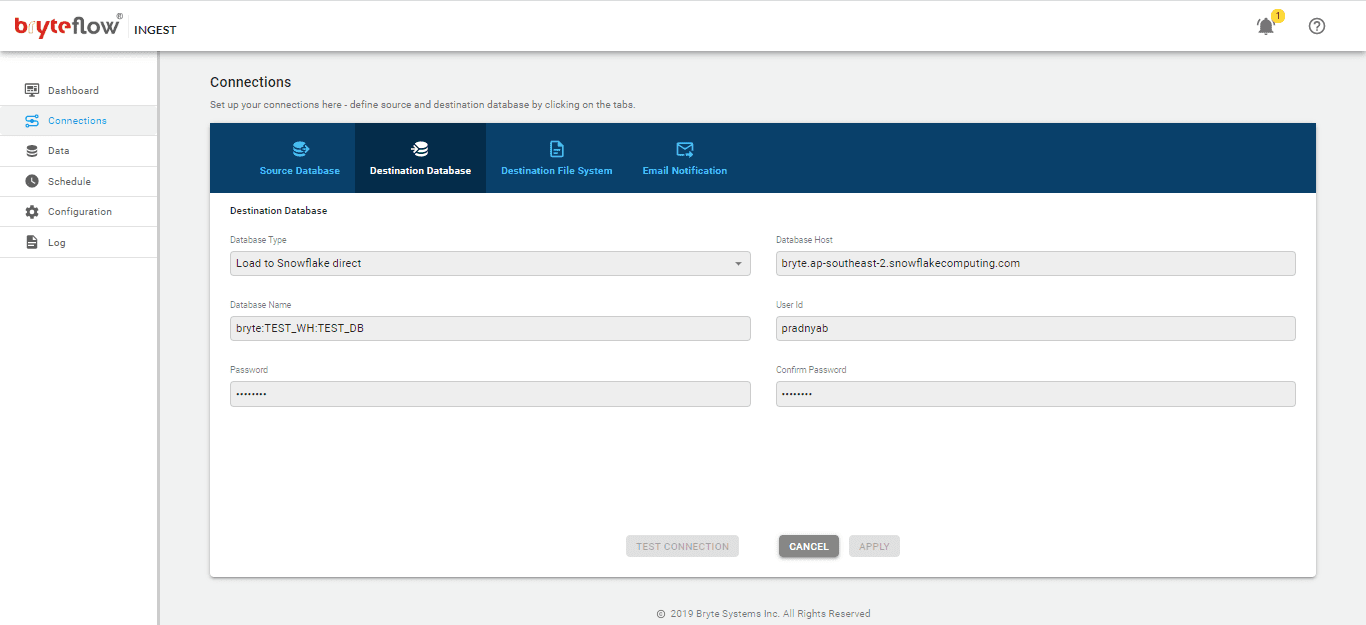
Set up the destination as Snowflake. Note: this is a Snowflake direct load with using Snowflake’s internal stage. Here are the different options for loading to Snowflake – Snowflake loading options
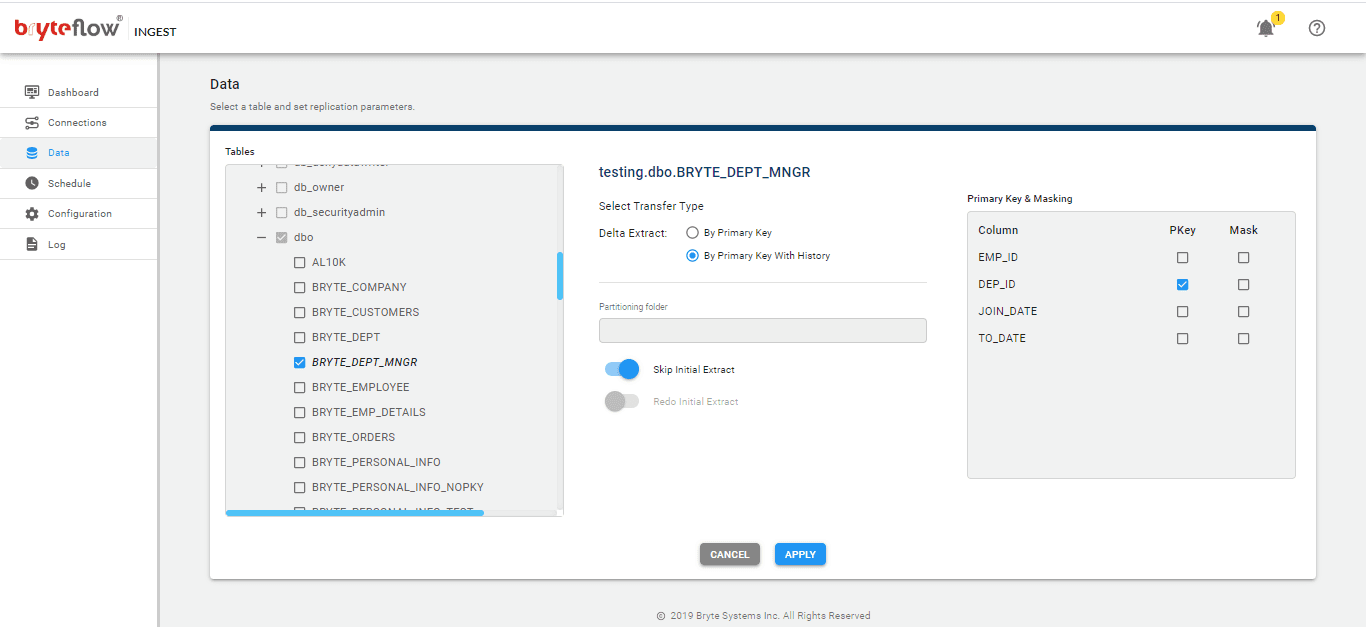
On the Data screen set up the table(s) to be replicated, select the primary key and the transfer type. The ‘Primary key with history’ option automatically keeps SCD Type2 history on Snowflake. The ‘By Primary key’ option keeps a mirror of the source without history. ‘By Primary key with history’ options keeps a history of each change automatically.
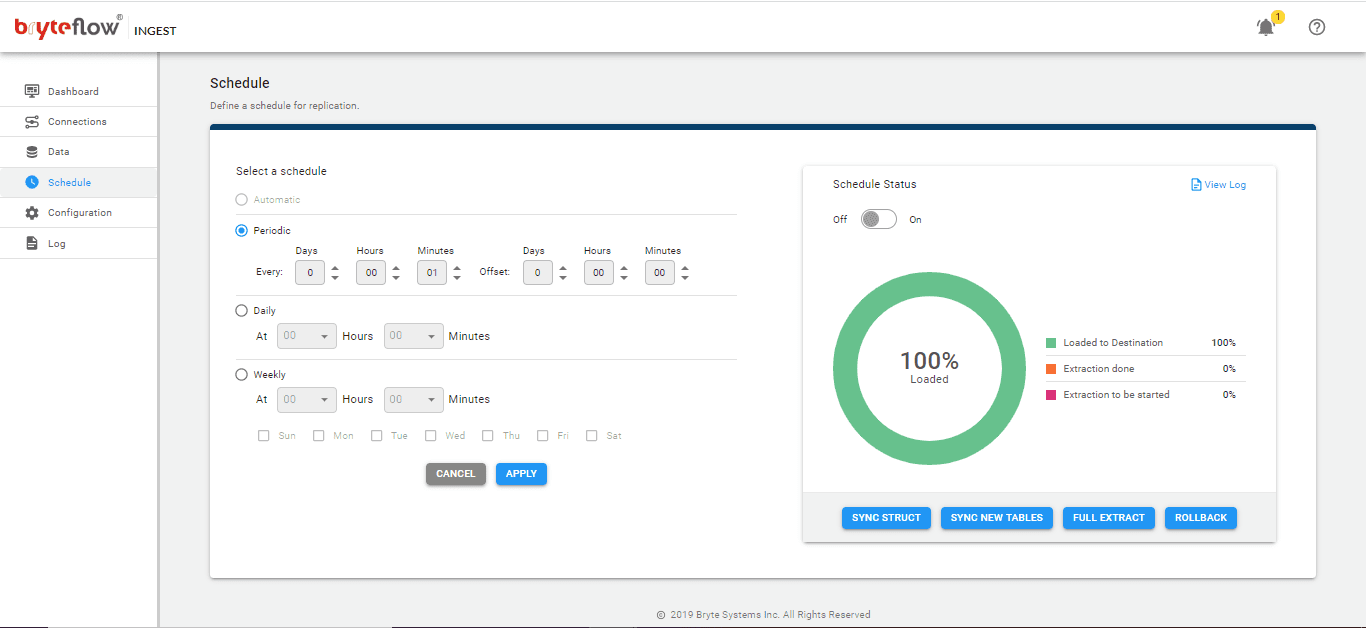
On the Schedule screen schedule your data replication time – periodic (specify the frequency here), daily or weekly. Sit back and watch your data flowing to Snowflake in near real-time.
Initial sync for really large tables
When you have really huge tables to replicate, it is enormously helpful to use BryteFlow XL Ingest for the initial sync. XL Ingest uses smart partitioning technology and parallel loading to deliver data very fast.
Follow these simple steps:
Your tables can be any size, as XL Ingest handles terabytes of data efficiently. On the Table Setup screen configure the large table to be brought across. Select the columns you need and use table partitioning – auto or manual.
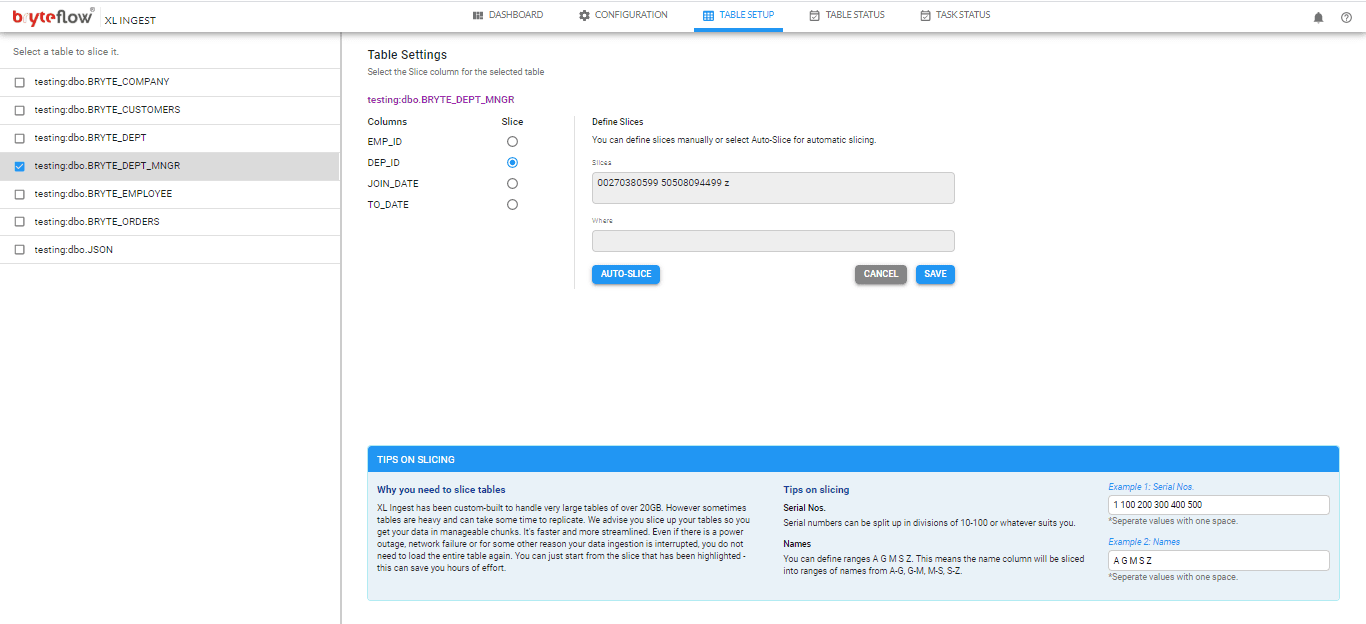
As the table is brought across, you can monitor the loading status on the Task Status screen. After completion the table is replicated on Snowflake and is ready to use with SCD Type2 history (if so configured).
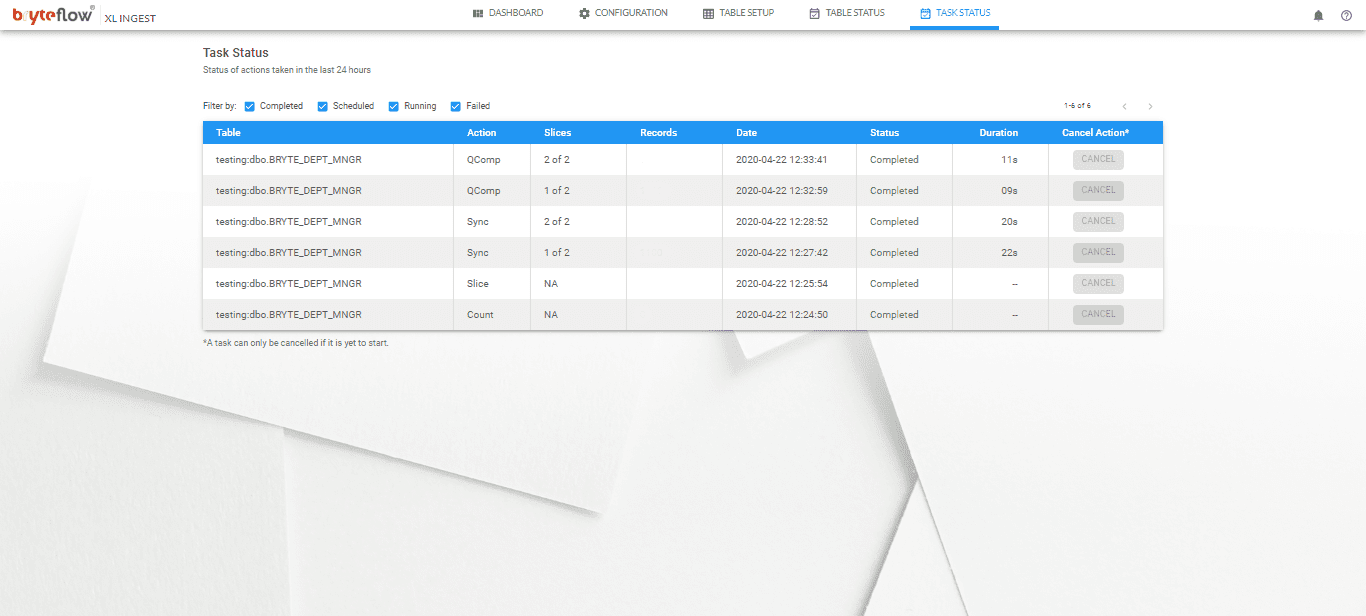
To experience BryteFlow with Snowflake, start with our supported free trial. To find out more about BryteFlow’s powerful automated data migration, check out https://bryteflow.com/bryteflow-ingest-xl-ingest/
Our supported free trial means we will help you get started with screen sharing, consultation and any online support you might need. Get a FREE Trial now.



