
This blog examines the Databricks Lakehouse and the Delta Lake and how they are adding value to data. Find out the benefits of Databricks migration, methods of ingestion to Databricks and how BryteFlow can make your Databricks migration even easier and no-code. When you need data access to be simple and unified, to implement use cases like Analytics, BI, and Machine Learning models on one platform, when you need the huge compute power of Apache Spark under the hood to process data at scale, and when you need easy collaboration on projects with ready availability of open-source tools, Databricks is the way to go. BryteFlow’s Data Integration on Databricks
Quick Links
- What is the Databricks Lakehouse?
- What is the Databricks Delta Lake?
- How Delta Lake enhances Reliability
- Databricks Migration, why it is Worth Your While
- Databricks Benefits: A Closer Look at the Advantages
- Databricks Data Ingestion Methods
- Databricks Data Ingestion on AWS, Azure and GCP with BryteFlow
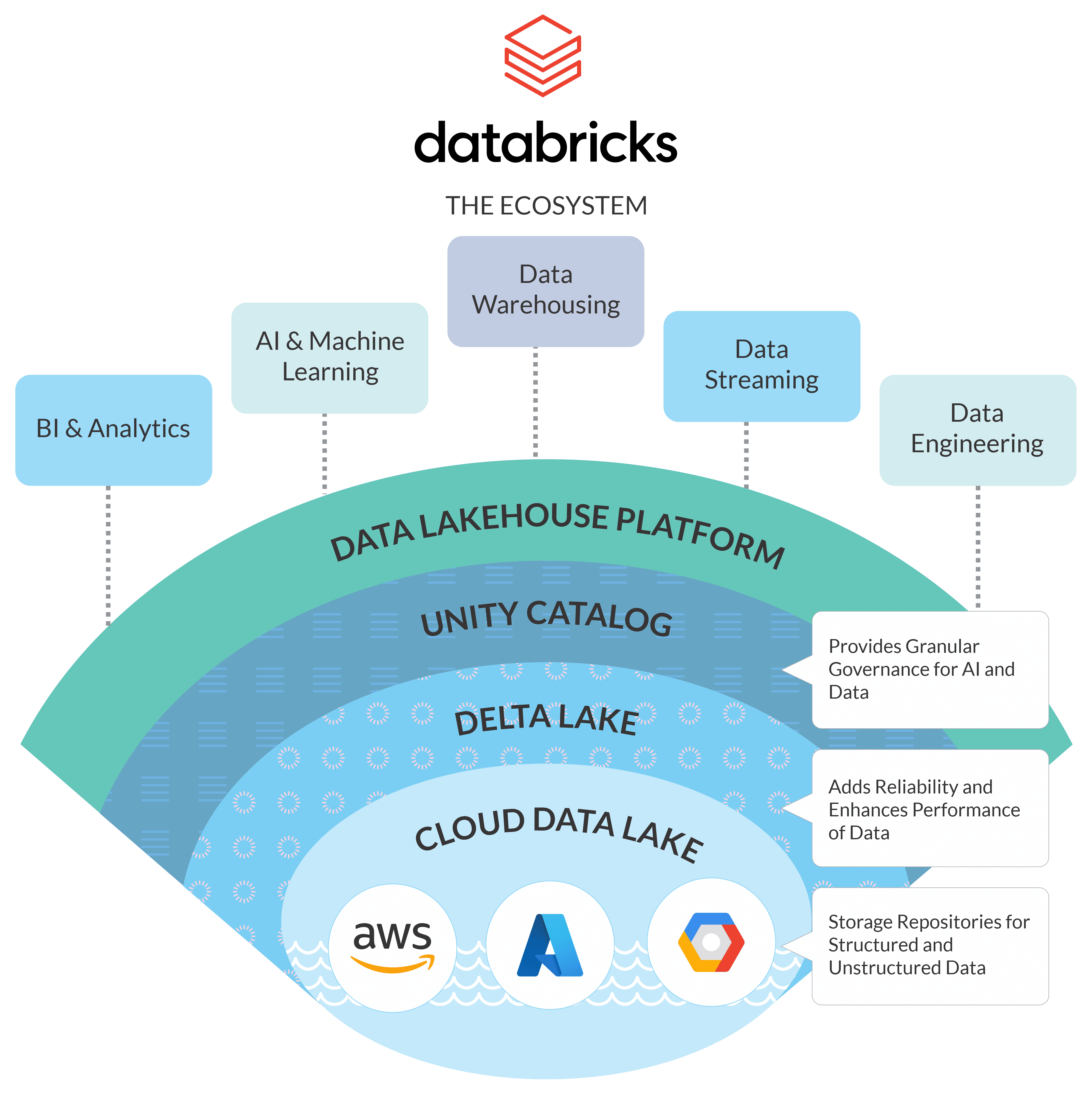
What is the Databricks Lakehouse?
Databricks is getting a lot of good press lately. And why not? The Databricks Lakehouse Platform is a flexible, versatile Cloud platform that integrates with your account in the Cloud for storage and security and deploys and manages the Cloud infrastructure for you. It is a single platform that can handle diverse data needs including data science, machine learning, and analytics, as well as data engineering, reporting, and business intelligence (BI). Data Integration on Databricks
The Databricks Lakehouse Platform is a unified analytics platform represented by a single group of tools that can build, share, deploy and maintain very large volumes of enterprise grade data with unlimited scalability to boot. Think of the Databricks Lakehouse as a combination of a Data Lake and Data Warehouse. Because a single system can handle both, affordable data storage (like a data lake) and analytical capabilities (like a data warehouse), the Databricks Lakehouse makes data easier and simpler to access and use. It also enables easy collaboration within teams. Databricks vs Snowflake: 18 differences you should know
The Databricks Lakehouse can be installed on your current Cloud- whether you use Google Cloud, Microsoft Azure, Amazon Web Services (AWS), or a combination of these Cloud providers. As a managed data and analytics platform, the Databricks Lakehouse is fast, scalable, and cost-effective. An interesting aside – Databricks was created by the same team that created Apache Spark, the powerful, fast, open-source analytics engine, and Databricks runs on top of Spark for analytical processing. Databricks also has Delta Lake, its own open-source data storage format. Delta Lake is built upon the open-source Apache Parquet storage format and maintains a “transaction log”, listing all the operations performed on the data. Data Lakehouse on S3 without Delta Lake
Databricks Lakehouse allows you to do a lot of useful data-related tasks:
- You can extract all your data into a single space
- Manage data in batches and real-time streaming of data
- Carry out data transformation and organize data
- Access and use data for AI and machine learning
- Collaborate and share data with team members
- Generate business reports for insights
- Can be used on multiple Cloud platforms like AWS, Azure and GCP.
What is the Databricks Delta Lake?
Data Lakes on your Cloud platforms are basic data repositories. They are flexible but are not very robust and have few guarantees. However, with Delta Lake the data residing in your Cloud data lake (like Amazon S3, Azure Data Lake Gen2 etc.), can be subjected to analytics as if it was in a data warehouse. Databricks Delta Lake is the optimized storage layer in the Data Lakehouse Platform that serves as a base for storing data and tables. Delta Lake is open-source and provides reliability to the data lake. It enables scalable metadata management, ACID (Atomicity Consistency Isolation Durability) transactions via a file-based transaction log for Parquet data files. Delta Lake is built on Parquet and is completely compatible with Spark APIs. It can be used on top of any data lake effectively and cheaply since it is open-source software. The Delta Lake enables close integration with Structured Streaming and enables you to use a single data copy for both batch and streaming processes thereby delivering fast, high volume incremental processing. Parquet, ORC or Avro?
All tables on Databricks are saved by default in the Delta Lake format unless specified differently. The Delta Lake protocol was originally developed by Databricks, and it is still evolving, thanks to active contribution from the community. The Databricks Lakehouse Platform has many products and optimizations built on Apache Spark and Delta Lake guarantees. Databricks vs Snowflake: 18 differences you should know
How Delta Lake enhances Reliability
Delta Lake offers ACID transactions
The ACID transactions ensure there is no inconsistent data thanks to serializable isolation levels, like those provided by an RDBMS. This means that if there are multiple users reading and writing to the same table concurrently, their transactions will be isolated and not affect the others. Each request will be serialized as if they were occurring one after the other, though they would be happening simultaneously.
Delta Lake enforces Schema
Delta Lake checks automatically whether the data frame schema being written is compatible with the table schema. Prior to writing from a data frame to a table, Delta Lake verifies whether the columns in the table exist in the data frame, whether the data types of the columns match, and that column names are the same, including the case.
Delta Lake provides Data Versioning
Versioning information is contained in every Delta Lake table transaction log. This ensures Delta Lake evolution and minimum reader and writer version are tracked separately. Backward compatibility is guaranteed by Delta Lake. A higher version of the Delta Lake reader would always able to read data produced by a lower version.
Delta Lake enables time travel of data
Delta Lake has automated versioning of data of every operation done to a Delta Lake table or directory. This allows for rollbacks and pinpointing changes in data. Time travel is possible using either a version number or time stamp.
Databricks Migration, why it is Worth Your While
If you had to sum up the reason for Databricks migration in 2 words, it is ‘Do More’. Migrating to Databricks enables you to do more on so many levels. Unlike traditional enterprise data warehouses that support mostly historical reporting, cannot manage unstructured and semi-structured data, and ML and AI powered innovative data science use cases, Databricks can easily handle all those things. It is a completely unified platform that allows you to simplify data systems and combine different types of data from diverse sources. It provides end-to-end workflows for Data Science use cases and Machine Learning models. Data Migration 101 (Process, Strategies, Tools)
It is also much cheaper to scale, has no vendor lock-ins, and data formats are not proprietary. Databricks has built-in keyword bindings for all the data formats natively supported by Apache Spark, like Parquet, ORC, JSON, CSV, Avro, Text etc. Delta Lake however is the default protocol.
Databricks Benefits: A Closer Look at the Advantages
Databricks accelerates ETL, ELT and data access
Databricks enables users to directly access and query data in the Delta Lake, thereby avoiding tedious ETL and ELT processes. It provides an easy-to-use interface and provides limitless scalability with the capability to simply spin up more compute resources if needed. It democratizes the data, ensuring everyone on the team can access the data. Databricks is affordable and agile. About Automated ETL Pipelines
Data Science use cases with Databricks
Databricks is built on top of Apache Spark and as such can be used to build Spark-based streaming and machine learning applications. Databricks provides a unified, collaborative environment with interactive notebooks that can be used to create dashboards and interactive reports. This enables visualizing results in real-time, training and tuning of machine learning models and processing of data using Spark libraries. Developers can co-ordinate and write code together in common languages like Python, R, Scala and SQL and share it effectively with commenting, co-authoring, automatic versioning, Git integrations and role-based access. SQL Server to Databricks (Easy Migration Method)
Databricks provides multi-Cloud support
Databricks can be installed on top of your current Cloud easily so you can use Databricks on AWS (Amazon Web Services), Databricks on Azure or Databricks on GCP (Google Cloud Platform). You can even deploy it on a multi-cloud combination if needed. Cloud interoperability is being developed for resiliency and managing risks. The multi-Cloud option is especially useful for organizations involved in mergers and acquisitions so they can integrate their individual technology implementations easily and fast.
Databricks has an ‘Open’ philosophy and no proprietary data formats
Unlike other platforms that restrict users with vendor lock-in and proprietary data formats, Databricks encourages innovation with its widespread community of developers and support for common data formats. Databricks Lakehouse is built on Open standards and has an Open-source foundation (Spark). Delta Lake too is open-source, and it can be used to enable a data warehousing compute layer atop a traditional data lake.
Expert Support for Databricks
Databricks has SQL support and is supported by talented engineers who work on Apache Spark. The community is active in answering questions and troubleshooting issues. There are support subscription plans available or if you don’t want to avail of those, there is the Databricks Help Center.
Databricks offers multi-user support
Databricks is highly evolved, and you can access data directly or use traditional ETL / ELT to query data. It supports multiple users, offers superior data management, sharing of clusters, job scheduling and solid security. In a Databricks Lakehouse, ACID transactions provide consistency so multiple users using SQL, can read or write data reliably at the same time.
Databricks simplifies management of Apache Spark
Apache Spark at the core of Databricks, delivers a single framework to build data pipelines. Teams can build and deploy advanced analytics applications with self-service Spark clusters that are highly available and optimized. This means you can get a zero-management Databricks Cloud platform centered around Apache Spark and focus on innovation rather than managing infrastructure.
You get an interactive unified platform that provides an interactive workspace for visualization and exploration, auto-managed Spark clusters, production pipeline scheduler and a platform to run Spark-based applications. You also get recovery and monitoring tools with Databricks automatically to recover failed clusters, without any human intervention. You will also have access to the latest Spark features on Databricks since Spark is open-source, and access to Spark libraries to get applications up and running.
Databricks can be used to handle multiple data tasks and cater to various types of users
You can use Databricks to create applications ranging from BI to ML. With Databricks you can process, clean, share, store, model and analyze your data, all on one unified platform. Users with different data profiles – data scientists, business analysts, data engineers can all benefit from Databricks’ easy to deploy engineering workflows, machine learning models and dashboards for business analytics to accelerate insights and innovation for the organization.
There are multiple user interfaces on the Databricks workspace for essential data management that include these tools:
- Interactive Notebooks
- SQL Editor and Dashboards
- Compute Management
- Workflows Scheduler and Manager
- Data Ingestion and Governance
- Data Discovery, Annotation, and Exploration
- ML Model Serving
- Machine Learning (ML) Experiment Tracking
- Feature Store
- Source Control with Git
Besides the Workspace UI, you can interact with Databricks programmatically with these tools:
- REST API
- CLI
- Terraform
Databricks supports both – Streaming and Batch Processing
Apache Spark powers the Databricks Lakehouse to support both streaming and batch data processing, data of which is stored via the Delta Lake on your Cloud data lake. Get a Lakehouse on S3 without Delta Lake
Databricks is easy to use and lends itself well to use cases like Analytics, AI, and ML
The Databricks Lakehouse platform is extremely versatile and enables end-to-end workflows for data engineering, machine learning models and dashboards for analytics. You can spin up clusters automatically for more compute and Spark under the hood, makes for extremely fast processing of very large datasets. Databricks vs Snowflake: 18 differences you should know
Databricks has an impressive eco-system that aids innovation and fast processing
Databricks has an impressive eco-system built upon Apache Spark and easy integration with open-source Spark applications. It manages open-source integrations updates in the Databricks Runtime releases. The listed technologies are open-source projects created by the Databricks team: Delta Sharing, MLflow, Apache Spark and Structured Streaming, and Redash. Databricks also manages proprietary tools that can be used to integrate and enhance the open-source technologies for improving performance like: Workflows, Unity Catalog, Delta Live Tables, Databricks SQL, and Photon.
Data Science and Analytics on Databricks – Use what you already know
The Databricks Unified Analytics Platform provides teams the opportunity to manage all analytical processes including ETL, models training and deployment by using familiar tools, languages, and skills. They can share code via interactive notebooks and maintain revision history and GitHub integration. Teams can also automate tasks for data pipelines like jobs scheduling, monitoring, and debugging. Databricks also allows you the freedom to use your preferred tools and what you’re familiar with. SQL, Python, Scala, Java, and R can be used as coding languages and most data professionals have these common skills.
Databricks Platform is much more affordable than traditional data warehouses
Databricks uses SQL and there is no extra licensing required for Databricks usage and its allied applications, most of which are open-source. Databricks can be used on top of Azure, AWS, and GCP Cloud platforms. It has no proprietary data formats and no vendor lock-in. It processes massive amounts of data using the Cloud platform’s data lake for storage, and processing data via the Delta Lake. Your data can be queried in the data lake itself hence the very fitting term – the Databricks Lakehouse. You also save time and costs by not having to move your data to a separate data warehouse making for much faster time to insight. SQL Server to Databricks (Easy Migration Method)
Databricks Data Ingestion Methods
Databricks data ingestion can be done using a variety of mechanisms. Here we examine a variety of ways to load data to Delta Lake.
Delta Live Tables for Data Pipelines to Databricks
Delta Live Tables (DLT) is a structure for creating trustworthy, easily maintained, and testable pipelines for batch and data streaming to the Data Lakehouse. You need to define the transformations you need, and Delta Live Tables will manage task co-ordination, monitoring, data quality, cluster management, handling errors etc. This helps in delivering high quality data, simplifying ETL pipeline development, automated data testing and complete visibility for recovery and monitoring of data. You can use the Databricks Auto Loader in Delta Live Table pipelines without needing to provide a schema or checkpoint location since Delta Live Tables handle these settings automatically. As an extension of Apache Spark’s Structured Streaming functionality, Delta Live Tables enable you to implement a data processing pipeline with minimal declarative Python or SQL coding.
Delta Live Tables enable:
- Autoscaling of compute infrastructure which is cost-effective
- Quality checks of data as per set expectations
- Automated handling of schema evolution
- Monitoring data through event log metrics
Databricks Auto Loader to move data to Databricks
Databricks Auto Loader is an extremely useful mechanism for incremental processing of data files as they land into cloud storage. The best part – it does not need any additional setup. Auto Loader provides cloudFiles, which is a Structured Streaming source for processing files. Once it is pointed to an input directory path on cloud storage, cloudFiles processes fresh files automatically as they arrive. It can also process existing files in the directory if required. Both Python and SQL are supported by Auto Loader in Delta Live Tables. Auto Loader has the capability to process files by the billion for migration or backfilling tables. It has powerful scaling capabilities and can scale to ingest millions of files per hour in near real-time.
Auto Loader can load data files from AWS S3 (s3://), Azure Data Lake Storage Gen2 (ADLS Gen2, abfss://), Google Cloud Storage (GCS, gs://), Azure Blob Storage (wasbs://), ADLS Gen1 (adl://), and Databricks File System (DBFS, dbfs:/). Auto Loader can ingest JSON, CSV, PARQUET, AVRO, ORC, TEXT, and BINARYFILE file formats. Parquet, ORC or Avro for S3?
COPY INTO Statement for loading data to Databricks
You can load data from a file location into a Delta table with the COPY INTO SQL command. COPY INTO is a re-triable and idempotent operation which means files in the source location that have already been loaded are skipped. You get the ability to use temporary credentials while doing this operation, thereby supporting secure access. This is the syntax. Source
COPY INTO target_table
FROM { source |
( SELECT expression_list FROM source ) }
[ WITH (
[ CREDENTIAL { credential_name |
(temporary_credential_options) } ]
[ ENCRYPTION (encryption_options) ])
]
FILEFORMAT = data_source
[ VALIDATE [ ALL | num_rows ROWS ] ]
[ FILES = ( file_name [, ...] ) | PATTERN = glob_pattern ]
[ FORMAT_OPTIONS ( { data_source_reader_option = value } [, ...] ) ]
[ COPY_OPTIONS ( { copy_option = value } [, ...] ) ]
Databricks Add Data UI enables loading of data to Databricks from multiple sources
You can load data from a range of sources to the Databricks Lakehouse using the Add Data UI. The UI can be accessed by selecting ‘New’ from the Dashboard then selecting ‘Data’. Using the Add Data UI, you can load data in a variety of ways:
Upload Data: To upload CSV or TSV files into Delta Lake tables, select the ‘Upload Data’ option. You can import small CSV or TSV files from your local system to create a Delta table. This works for smaller volumes of data since the Upload Data UI can upload only 10 files at a time, with the total size of files being under 100 MB. It does not support compressed file formats like zip and tar and the files uploaded must have either a “.csv” or “.tsv” extension.
Databricks File System (DBFS): You can use the Databricks File System (DBFS) to implement legacy DBFS file uploads. DBFS is an abstract framework that lies on top of scalable object storage. It maps filesystem calls (like UNIX) to native cloud storage APIs. DBFS is available on Databricks clusters and is a distributed file system that is mounted on a Databricks workspace.
Other icons: Accessing other icons opens sample notebooks that allow users to set up connections to multiple data sources.
Parquet or Iceberg Data Conversion to Delta Lake Format
The CONVERT TO DELTA SQL command does a one-time conversion to convert Parquet and Iceberg tables to Delta Lake tables. The Databricks Unity Catalog supports the CONVERT TO DELTA SQL command. This enables you to set up existing Parquet data files from your Cloud platforms as external tables in Unity Catalog and then convert them to Delta Lake to use all the powerful features of the Databricks Lakehouse.
Loading Data to Databricks with Third-party Partners
The Databricks Partner Connect program provides integrations with third-party vendors to enable processes like data ingestion, data preparation and transformation, business intelligence (BI), and machine learning (ML). Third-party partner integrations managed by independent software vendors can help you connect easily with enterprise data platforms. You can set up the connections through the Add Data UI. Most third-party data ingestion solutions are low-code or no-code like our very own BryteFlow.
Databricks Data Ingestion on AWS, Azure and GCP with BryteFlow
BryteFlow Ingest acts as a third-party Databricks data ingestion tool and extracts and ingests data from multiple sources to your Databricks Lakehouse in real-time, in completely automated mode (read no coding). BryteFlow Ingest delivers data from sources like SAP, Oracle, SQL Server, Postgres and MySQL to the Databricks platform on Azure, AWS and GCP in real-time using log-based automated CDC. You get time-versioned, ready to use data for Analytics, BI, and Machine Learning on destination. How BryteFlow Works
You can connect BryteFlow Ingest to various sources in just a couple of clicks. BryteFlow offers low latency and very high throughput of 1,000,000 rows in 30 seconds. It ingests petabytes of data with parallel, multi-threaded loading and automated partitioning for the initial full refresh of data followed by ingestion of incremental deltas using log-based CDC. With BryteFlow, every process is automated including data extraction, CDC, DDL, schema and table creation, masking and SCD Type2. It’s easy to set up and you can start getting delivery of data in just 2 weeks. BryteFlow’s Data Integration on Databricks
BryteFlow’s ELT To Databricks Highlights
- Delivers real-time data from transactional databases like SAP, Oracle, SQL Server, Postgres and MySQL to Databricks on AWS, Azure and GCP.
- Ingests data to the Databricks Lakehouse using automated log-based CDC (Change Data Capture) to deliver deltas in real-time and sync data with source. About Automated CDC
- BryteFlow’s Databricks ELT process is completely automated and has best practices built in. Databricks vs Snowflake: 18 differences you should know
- The initial full load to the Databricks Lakehouse is fast with parallel, multi-threaded loading and partitioning orchestrated by BryteFlow XL Ingest. SQL Server to Databricks (Easy Migration Method)
- BryteFlow delivers ready-to-use data to the Databricks Delta Lake with automated data conversion and compression (Parquet-snappy).
- BryteFlow provides very fast loading to Databricks – approx. 1,000,000 rows in 30 seconds. BryteFlow is at least 6x faster than Oracle GoldenGate and you can also compare it with Matillion and Fivetran.
- For ingestion of SAP application data to Databricks we recommend the BryteFlow SAP Data Lake Builder. It can ELT data directly from SAP applications to the Databricks Lakehouse with business logic intact – no coding needed.


