
This blog explores the mechanisms of SQL Server Change Data Capture to Kafka, while highlighting the strength of both platforms. It talks about Debezium as a CDC tool and its limitations, and how BryteFlow is an easier and more effective Kafka CDC Connector than Debezium. It also demonstrates a step-by-step method for SQL Server CDC to Kafka using BryteFlow.
Quick Links
- What is Microsoft SQL Server?
- What is Apache Kafka?
- About Kafka Connect
- Connecting SQL Server to Kafka
- Debezium for SQL Server CDC to Kafka
- Limitations of Debezium CDC
- BryteFlow as a SQL Server Kafka Connector (Debezium Alternative)
- SQL Server CDC to Kafka Step by Step with BryteFlow
- BryteFlow Connector for SQL Server Kafka CDC: Highlights
What is Microsoft SQL Server?
Microsoft SQL Server is a widely used Relational Database Management System (RDBMS) developed by Microsoft. It follows the Relational Model architecture where data is organized into interconnected tables made up of rows and columns. A SQL Server database thus comprises of a group of tables that stores structured data in sets. A SQL Server table has a collection of rows, which are called records or tuples, and columns, which are also known as attributes. Each column holds a specific type of information such as dates, currency amounts, names, and figures. SQL Server CDC for Real-Time Replication
Each database can have multiple schemas. A database schema is a model that lays out the organization of data within the relational SQL database and includes elements like table names, fields, data types and how these entities are related. Each schema will contain database objects like tables, views, and stored procedures. Other objects like certificates and asymmetric keys are contained within the database but are not part of a schema. SQL Server databases are stored in the file system in files.
SQL Server to Postgres – A Step-by-Step Migration Journey
SQL Server supports various applications including transaction processing, business intelligence, and analytics in corporate IT setups. It ranks among the top three RDBMS technologies globally, alongside Oracle Database and IBM’s DB2. Built upon SQL, it incorporates Microsoft’s proprietary language extension called Transact-SQL (T-SQL). SQL Server is available for deployment both on-premise, and in the Cloud. SQL Server to Snowflake in 4 Easy Steps (No Coding)
What is Apache Kafka?
Apache Kafka is an open-source distributed event streaming platform which is optimized for ingesting and transforming real-time streaming data. Originally developed at LinkedIn to address internal data flow challenges, Kafka has evolved into a robust solution for managing massive message streams with low latency and high throughput. It offers secure, scalable, and elastic capabilities, making it a popular choice for companies seeking reliable event streaming solutions. Kafka is known for building high-performance data pipelines across various sectors like banking, retail, insurance, healthcare, IoT, media, and telecom. Kafka CDC Explained and Oracle to Kafka CDC Methods
Kafka is versatile and can be used to enable streaming analytics, data integration, and database migrations. 80% of Fortune 500 companies use Apache Kafka as a message broker, owing to its ability to process huge volumes of data and events. An event could be an action, change or occurrence that is recognized and stored by applications, including website clicks, payments, newsletter subscriptions, feedback, and posts on social media etc. How To Make PostgreSQL CDC to Kafka Easy (2 Methods)
Kafka provides users with three primary capabilities, including:
- Facilitating the publication and subscription to streams of records.
- Efficiently storing streams of records in chronological order of generation.
- Supporting real-time processing of record streams through Kafka connectors for importing and exporting data from various sources. What is Apache Kafka and Installing Kafka (Step-by-Step)
Apache Kafka has five fundamental Java APIs:
- Kafka Producer API: Producers publish a stream of events to a single Kafka topic or more. The Producer API allows developers to create Producers that write data to Kafka topics.
- Kafka Consumer API: Consumers subscribe to a single Kafka topic or more to process the stream of events produced to them. The Consumer API allows developers to create Consumers for reading data from Kafka topics.
- Kafka Connector API: This interface allows for the building and running of reusable data import and export connectors that produce or consume event streams to and from external systems and applications within a Kafka integration. For e.g. a SQL Server connector will capture all changes that happen to tables in the SQL DB. It is worth noting that the Kafka community has many ready-to-use connectors, so you don’t need to make your own. Data integration on Kafka with BryteFlow
- Kafka Streams API: The Kafka Streams API can be used to run applications and microservices that carry out stream processing in Kafka. It reads input from one or more topics to generate output to one or more topics, changing the input streams to output streams.
- Kafka Admin Client API: The Admin Client API is a Kafka API that allows developers to manage Kafka clusters using a program. Using a set of operations, developers can create, modify, delete, and describe Kafka resources such as topics, brokers, and Access Control Lists and automate tasks such as creation and deletion of Topics. This helps to make Kafka administration a part of larger workflows and systems. Kafka CDC Explained
About Kafka Connect
The Kafka Connect API, a constituent of Kafka along with the Kafka Streams API and Apache Kafka, serves as a layer on top of the core Apache Kafka platform. The Kafka Connect framework connects Kafka with external systems like databases, search indexes, and file systems, facilitating the streaming of large volumes of data. It offers readily deployable modules known as Kafka Connectors, which help to import data from external systems into Kafka topics and export data from Kafka topics to external systems. You can use pre-built connector implementations to connect with common data sources and sinks or create your own connectors. Installing Apache Kafka
This Kafka Connect framework automates much of the process, sparing users from the complexities of coding new source implementations, including troubleshooting, logging, and iterative adjustments. By using Kafka Connect, users benefit from built-in data preparation functionalities and the ability to perform minor data transformations easily. How To Make PostgreSQL CDC to Kafka Easy (2 Methods)
Kafka Connectors
Kafka Connectors are essential for integrating Kafka with external sources such as databases, search applications, and file systems. An extensive library of hundreds of connectors is available for diverse integration needs. Integration on Kafka with BryteFlow
Kafka Source Connectors
Kafka source connectors are specialized connectors that aggregate data from external systems into Kafka. These sources encompass data streams, databases, message brokers, and even application servers, enabling low-latency stream processing and metric collection for further analysis. Oracle CDC to Kafka
Kafka Sink Connectors
On the other hand, Kafka sink connectors transport data from Kafka topics to various external systems, including Elasticsearch, Hadoop, and different databases. Many sink connectors are available, customized for popular systems and platforms like JDBC, Amazon S3, Amazon Redshift, PostgreSQL, and Google BigQuery, among others.
Connecting SQL Server to Kafka
You may need to take across data from SQL Server to Kafka in real-time for any number of purposes. In the age of exponential data growth, organizations need to analyze and extract insights from huge volumes of information. Apache Kafka can handle this deluge efficiently, offering a distributed system to seamlessly manage streams of data. Kafka ensures data accuracy and precision by collecting and storing information in real-time as an immutable commit log. One of the popular methods to bring across SQL Server data to Kafka is with Debezium, an open-source platform. Debezium CDC explained and a great alternative
Debezium for SQL Server CDC to Kafka
Debezium is the default CDC platform of many organizations trying to CDC data to Kafka. But what exactly does Debezium do? First off, it is an open-source platform to perform Change Data Capture and consists of a large group of CDC connectors designed for Apache Kafka Connect. Each connector is tailored to extract changes from diverse databases, using their in-built CDC capabilities. It captures database changes at row level and delivers them as a Kafka output stream. This enables processing of records by downstream applications or for the records to be sent to storage for database replication.
Limitations of Debezium CDC
Though Debezium supports a wide array of databases (it has connectors for SQL Server, PostgreSQL, Oracle, MongoDB, MySQL, Db2 and Cassandra), has lightweight architecture, low latency streaming and high flexibility, it does have certain limitations. More on Debezium CDC
Debezium CDC only takes data to Kafka not to the target database
ETL of data is meant to extract data from business systems and into data warehouses like Amazon Redshift, Snowflake, Azure Synapse etc. where it can be analyzed. However, Debezium streams events only to Kafka, from there your team of data engineers and developers will need to ensure the data reaches the target database in the correct format and is accurate and complete. This will require extra effort in the form of data mapping and managing tables on target, verifying data, managing schema and incremental updates. This could make the implementation expensive, with a lot of additional overheads.
Note: Although Apache Kafka has been a part of traditional Debezium CDC setups, with the advent of Debezium Server, it can connect directly with alternative message processing platforms such as Google Pub/Sub, AWS Kinesis etc. Debezium Server is a standalone Java application built on the Qurkus framework. The server is set up to deploy one of the Debezium source connectors for capturing database changes. These change events can be transformed into various formats, such as JSON or Apache Avro, before being dispatched to a range of messaging infrastructures, including but not limited to Amazon Kinesis, Redis, Google Cloud Pub/Sub, or Apache Pulsar.
Engineering support will be needed for Debezium CDC
Debezium has built-in capabilities for managing changes in schema and late events, however extra work will be needed to deal with issues such as downtime in the source database. Issues could include management of schema changes, exactly-once semantics, dealing with spikes in traffic etc. Availability, reliability, and fault tolerance will need to be taken care of, and engineering support will be needed on a regular basis.
Debezium CDC relies on Kafka and throws up related tasks
Debezium needs Kafka to deliver changes from source. For organizations that don’t use Kafka, implementing it can be an onerous task. Management and monitoring of a Kafka cluster can be time consuming and apart from that, fine tuning will be required for things like topic partitioning, replication, and data retention policies. Kafka capacity and throughput will need active management to prevent degradation, especially as data volumes grow. Other tasks like upgrades, security patching, and failure recovery will also require engineering skills and effort. How to install Kafka
Debezium being open-source has inherent challenges
Debezium is open-source, which means engineering teams will have to manually upgrade infrastructure and keep current with new releases. Every upgrade will also require testing to ensure optimal performance. Container images and orchestration configurations will also need to be updated over large, distributed deployments. Also delays in creating patches can degrade performance and pose security risks.
Debezium cannot get historical data for CDC without manual intervention
Manual effort will be needed in the case of a new Consumer to get real-time and historical change events unless data is stored in a Kafka log (expensive proposition) or a compacted Topic.
Zero data loss may not be possible with CDC of large tables in Debezium
Debezium CDC does not handle very large tables well. If any component fails, data integrity and zero data loss may be compromised. Once again, the development team will have to take up the onus of integrity maintenance.
A large number of specific proficiencies and skills will be needed for Debezium CDC
Proficiency in Kafka, Kafka Connect, and ZooKeeper is essential for data teams working on Change Data Capture (CDC) pipelines using Debezium, not to mention mastery in Java for the implementation.
Debezium CDC requires manual handling of complex schema changes and migrations
Substantial custom logic needs to be developed within Kafka processing to manage schema evolution effectively. Some source databases do provide support for schema evolution to a degree, but complex schema evolution will need to be manually handled.
Scalability issues with certain Debezium connectors for CDC
Issues such as out-of-memory exceptions might occur when employing plugins like wal2json to convert write-ahead log outputs to JSON in Postgres database, for example.
Debezium CDC Connectors may have restrictions
Certain connectors have limitations concerning specific data types. For example, Debezium’s Oracle connector faces constraints in handling BLOB data types.
Debezium CDC snapshotting makes tables unavailable while the process is going on
Snapshotting tables may not be possible when allowing incoming events, which can lead to prolonged unavailability of tables, especially with large datasets.
Debezium CDC connectors can handle only one task
Multiple connectors are available to organizations, however each is limited to one task per connector (i.e., “tasks.max”: “1”).
Debezium CDC does not offer Active Directory authentication
Currently there is no support for Active Directory authentication.
Debezium CDC can have Event Overflow
When millions of change events are created rapidly, then accumulation in data pipelines and data loss can cause event overflow, causing bottlenecks.
BryteFlow as a SQL Server Kafka Connector (Debezium Alternative)
As you can see working with Debezium incorporates a fair degree of manual effort, needs expertise in certain technology skillsets and a high degree of involvement of your development teams. It may also require inclusion of Kafka in your stack which will need active management. That’s why BryteFlow may prove a better CDC option than Debezium. In fact, out of all the possible methods of getting SQL Server data to Kafka, you will find using BryteFlow is the easiest and the fastest.
SQL Server Change Data Capture to Kafka keeps data constantly synced with changes in the SQL DB. This can be done in different ways including setting up BryteFlow as a SQL Server Kafka Connector to CDC SQL data to Kafka, or by using a Debezium SQL Server Connector (external link). BryteFlow is a completely no-code CDC tool that functions as a third-party Kafka connector to get your data from SQL Server to Kafka, and unlike Debezium, it needs minimal involvement from your data engineers. It has an intuitive point and click interface that any business user can use easily.
Debezium may find it challenging to deal with very large datasets, but BryteFlow can deliver huge volumes of enterprise data in real-time, with low latency and extremely high throughput (approx.1,000,000 rows in 30 seconds). BryteFlow delivers the initial full refresh and incremental data capture with fast parallel, multi-thread loading, and smart configurable partitioning. It also offers data conversions out-of-the-box e.g. Parquet-snappy, ORC so data delivered is ready to use on target. It is fast to deploy and you can start receiving data in just a couple of weeks. How BryteFlow Works
SQL Server CDC to Kafka Step by Step with BryteFlow
BryteFlow as a CDC tool minimizes impact on your source systems while delivering all changes from the SQL Server database to Kafka in real-time. In order to establish the SQL Server to Kafka CDC connector within BryteFlow Ingest, you need to simply configure the source endpoint, set up the destination endpoint, select the desired tables for replication, specify a replication schedule, and watch your data rolling in. For defining MSSQL DB as the source, please adhere to the prerequisites outlined here
(external link)
Step 1: Download and Install BryteFlow Ingest, followed by Login and Configure Source Database
You can acquire the software either directly from the BryteFlow team or by download it from the AWS Marketplace (external link) BryteFlow is also available on Azure Marketplace (external link). After obtaining it, proceed with the installation. Upon installation completion, log in and access the “Connections” tab located in the left panel. Select the “Source Database” option, then follow the provided steps to configure your source database.
- Select Microsoft SQL Server (CDC) as the Database Type from the available choices. BryteFlow also offers support for Microsoft SQL Server (Change Tracking) and Microsoft SQL Server (Full Extracts), allowing you to choose based on your requirements.
- Fill in the Database Host field with the MSSQL Host Details.
- Specify the Port Details in the Database Port field.
- Enter the Database Details in the Database Name field.
- Input the User name used for Database connection into the User Id field.
- Provide the User password associated with the User Id for Database connection in the Password field.
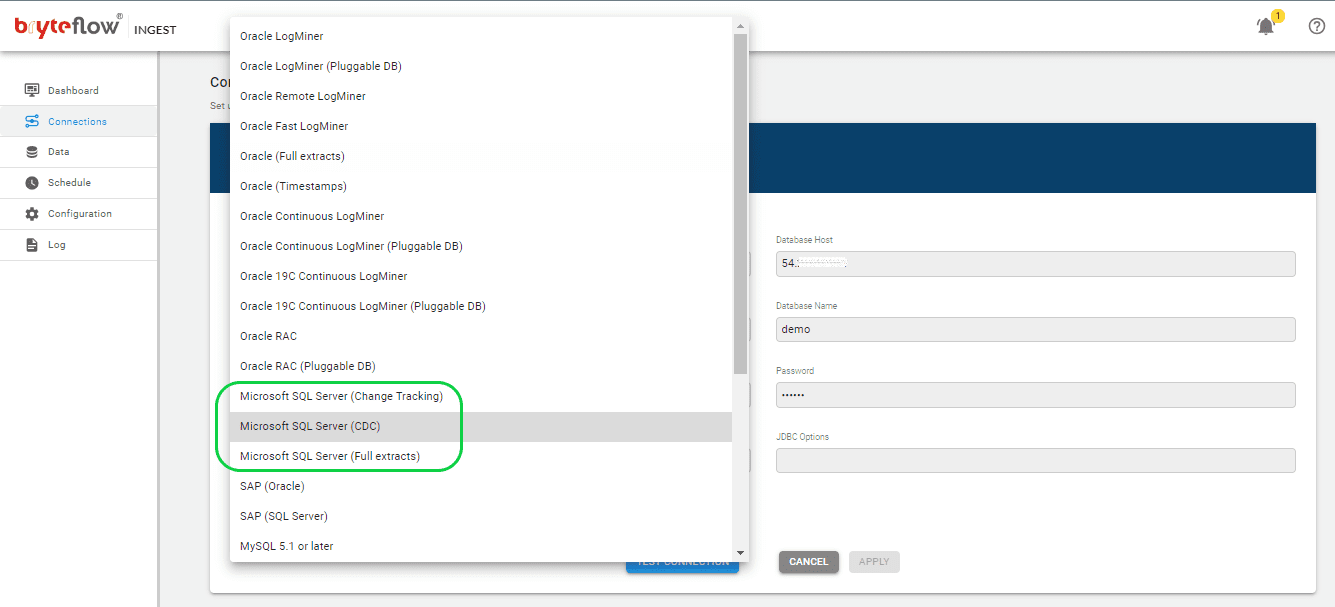
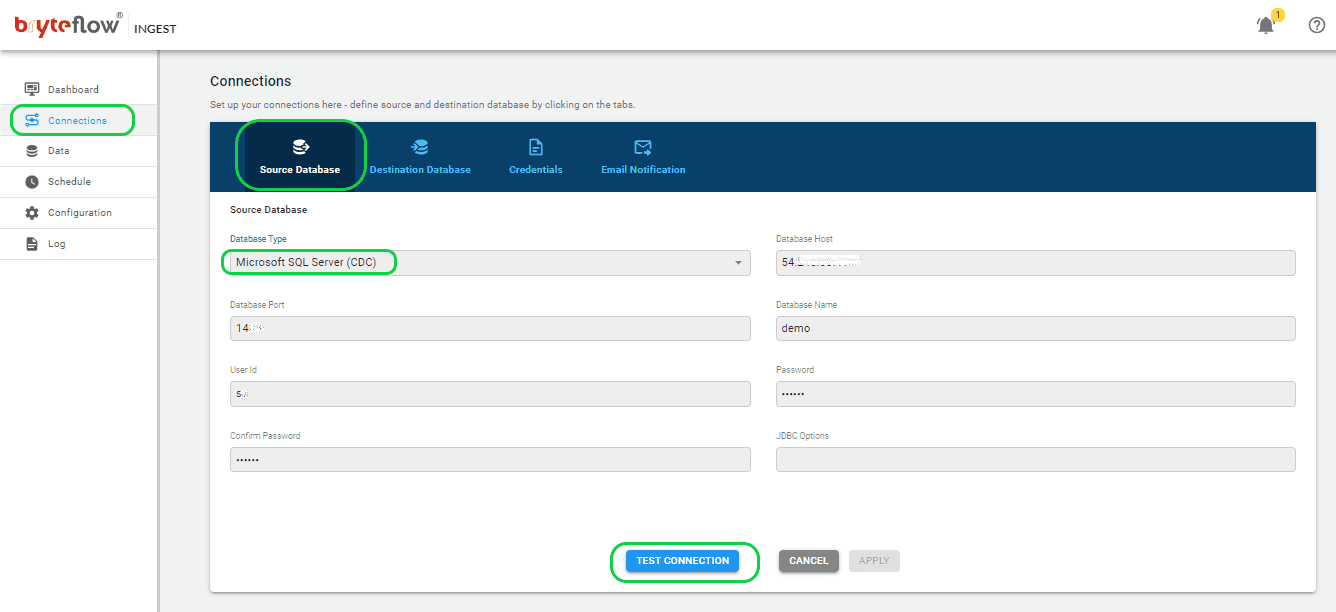
After inputting the necessary details, verify the application’s connection by clicking on ‘Test Connection’. A successful connection test is required to initiate the replication process.
Step 2: Configure Destination Database
Select the “Destination Database” within the “Connections” menu and proceed with the following instructions to establish a connection to your Kafka destination database. BryteFlow supports Kafka Message Keys and Partitioning, where each JSON message contains a ‘key’ and messages can be partitioned for parallel consumption. By default, BryteFlow Ingest places messages into Kafka Topic in JSON format, with a minimum message size of 4096 bytes.
- Select “Load to Kafka Deltas” from the dropdown menu under Database Type.
- Provide the Kafka Broker information in the designated “Kafka Broker” section.
- Enter the Kafka Client details within the “Kafka Client” section.
- Specify the Kafka Topic particulars in the dedicated “Kafka Topic” area.
- Complete the information for your Kafka Consumer in the designated field.
- Update the SSL configuration by toggling the “Enable SSL” option.
- Include the SSL Truststore path details in the appropriate section labeled “SSL Truststore Path.”
- Enter your password in the designated “Truststore Password” field.
- Add Keystore details under the corresponding “Keystore” section.
- Input your password in the designated “Keystore Password” field.
- Provide your password again in the “Key Password” field.
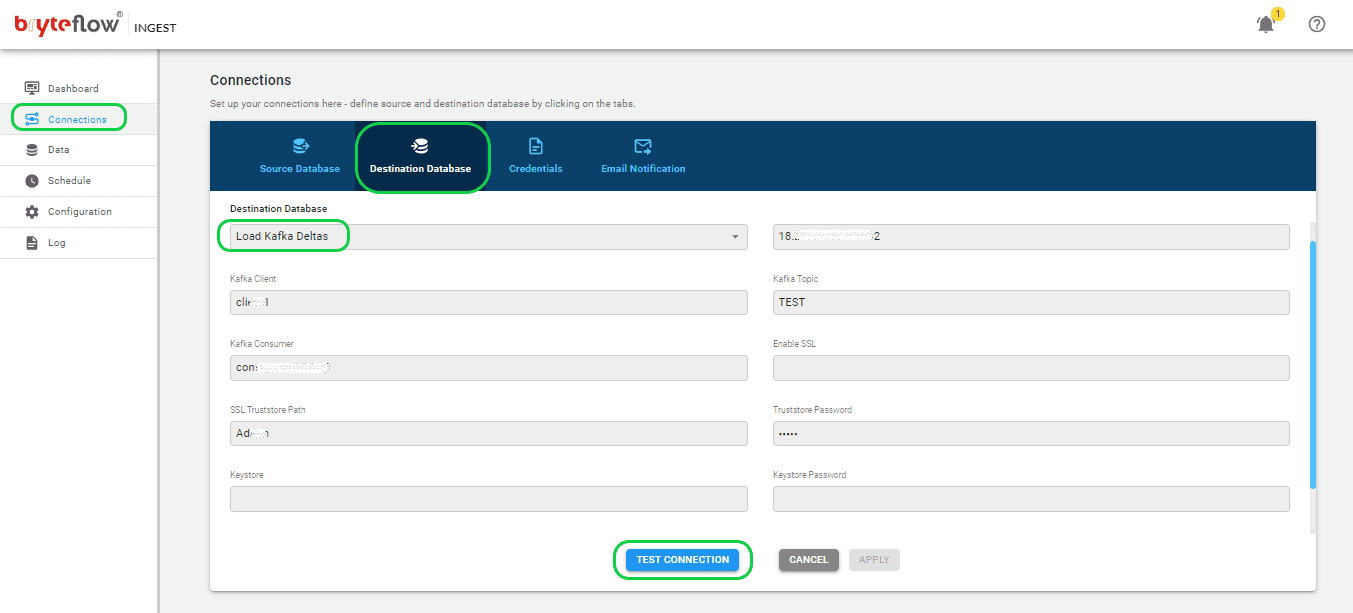
Step 3: Identify the tables you want to replicate
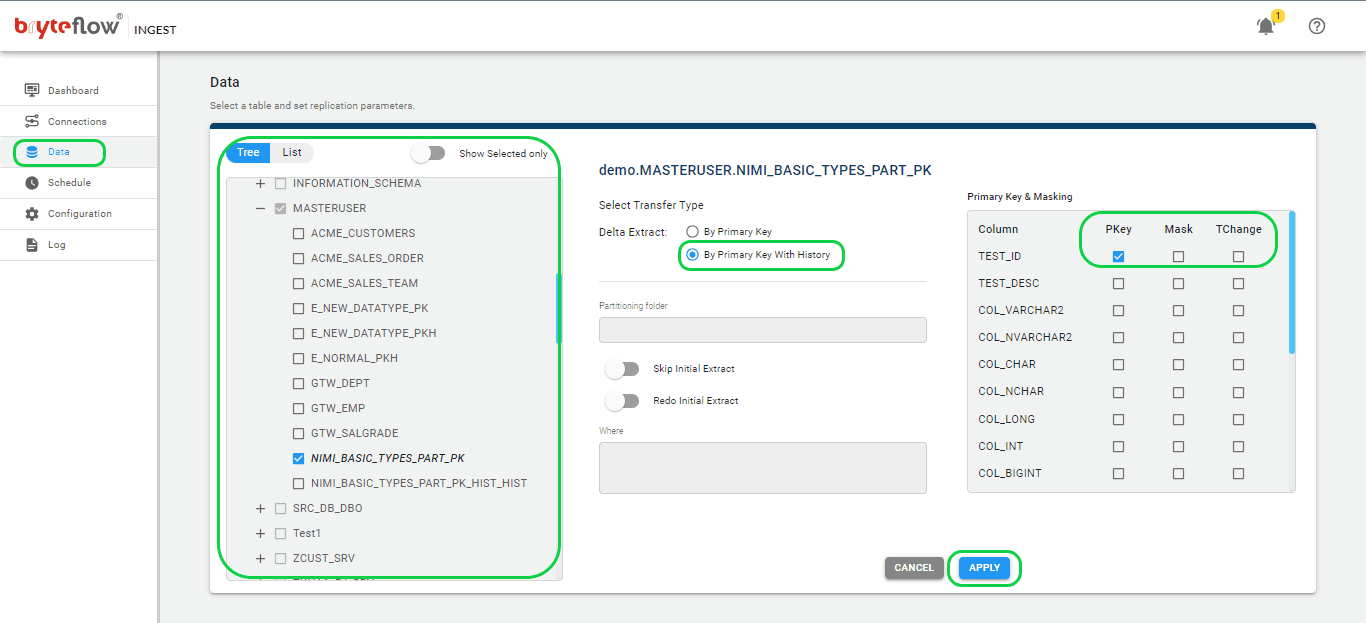
To choose the table(s) for transfer to the Kafka destination database, follow these steps.
- Select the “Data” tab and expand the database to configure the source table(s) for replication.
- Locate and select the desired table that you wish to synchronize.
- Tick the checkbox beside the table name and proceed by clicking on the table.
- Within the pane on the right-hand side, designate the transfer type for the table, choosing between “By Primary Key” or “By Primary Key with History.” The former replicates the table exactly as it is to the destination, while the latter records changes as time series data with Slowly Changing Dimension type 2 history, providing a point-in-time perspective.
- Identify the Primary Key column by selecting its checkbox next to the column name.
- Optionally, mask a column by selecting its checkbox to exclude it from the transfer to the destination.
- Specify data type conversions for columns requiring changes by selecting the ‘TChange’ checkbox against those columns.
- Confirm and save the configuration details by clicking the ‘Apply’ button.
Step 4: Schedule the replication
Select the Schedule tab in the left panel to go to the Schedule page. Configure a recurring schedule for the pipeline by setting the interval in the ‘Schedule’ tab. This can range from intervals as short as a second to daily extractions at specific times, determined by selecting the desired hour and minute from the drop-down menu.
Choose from options such as “Periodic,” “Daily,” and “Weekly.” Select “Full Extract” for the initial load, “Sync New Tables” to integrate new tables post-replication activation, “Sync Struct” to replicate structural changes in existing tables, and “Rollback” to revert to a previously successful run, particularly helpful in the event of replication interruptions due to outages. For instance, opt to replicate every 15 minutes post the full extract, ensuring that new data is loaded every 15 minutes. Initiate the replication process by clicking on “Full Extract” for the initial load.
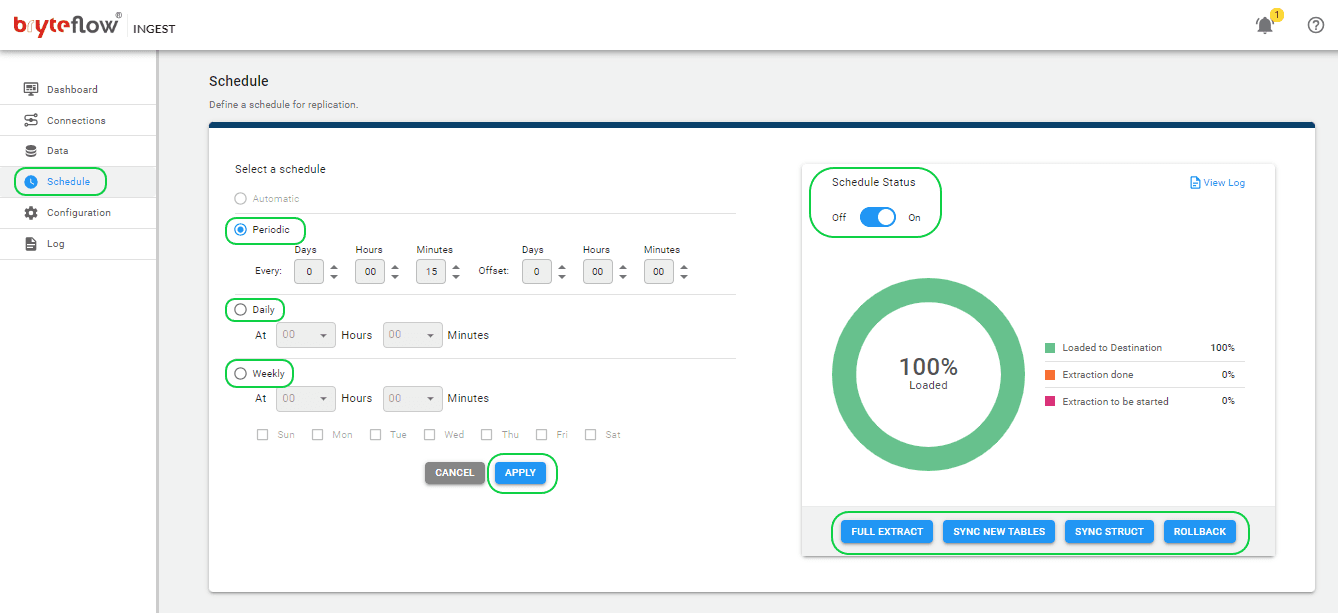
Step 4: Monitor your replication
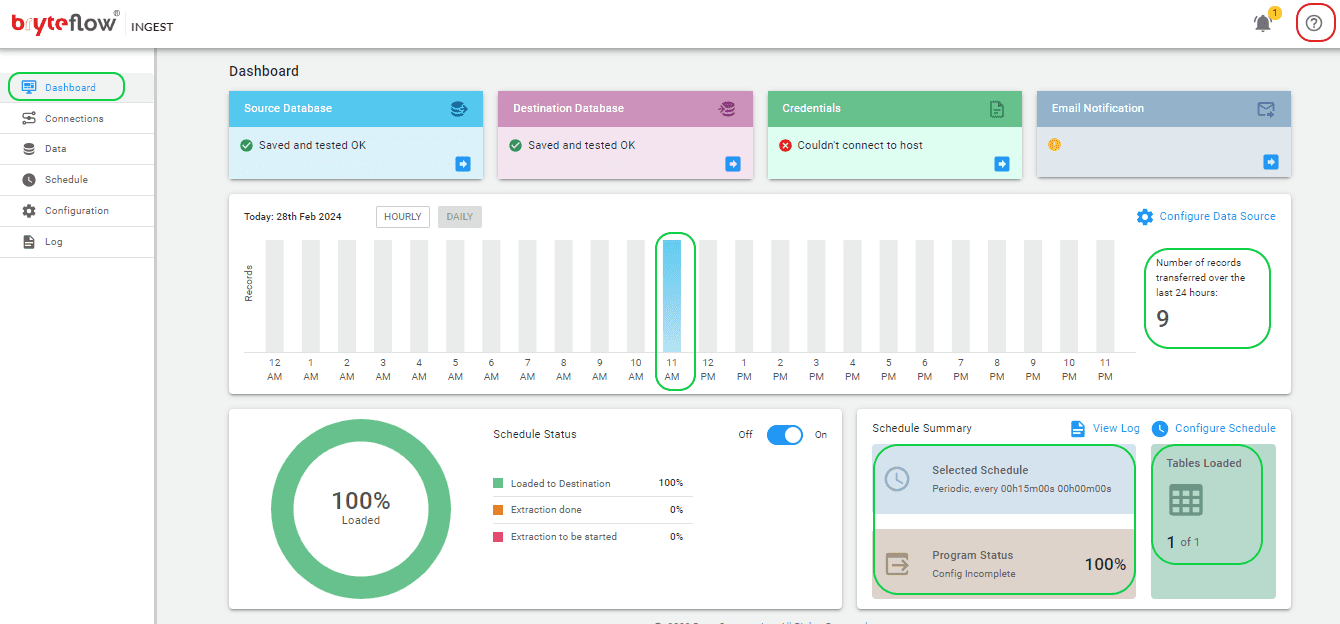
Keeping track of all these tasks is easy using the intuitive BryteFlow Ingest dashboard. This dashboard offers in-depth visibility into BryteFlow Ingest operations, presenting details such as the total number of records and tables loaded, real-time updates on ongoing loading processes, replication frequency, and connection statuses. Additionally, getting assistance is easy with the “HELP” option located in the top right corner (highlighted in red) on the dashboard.
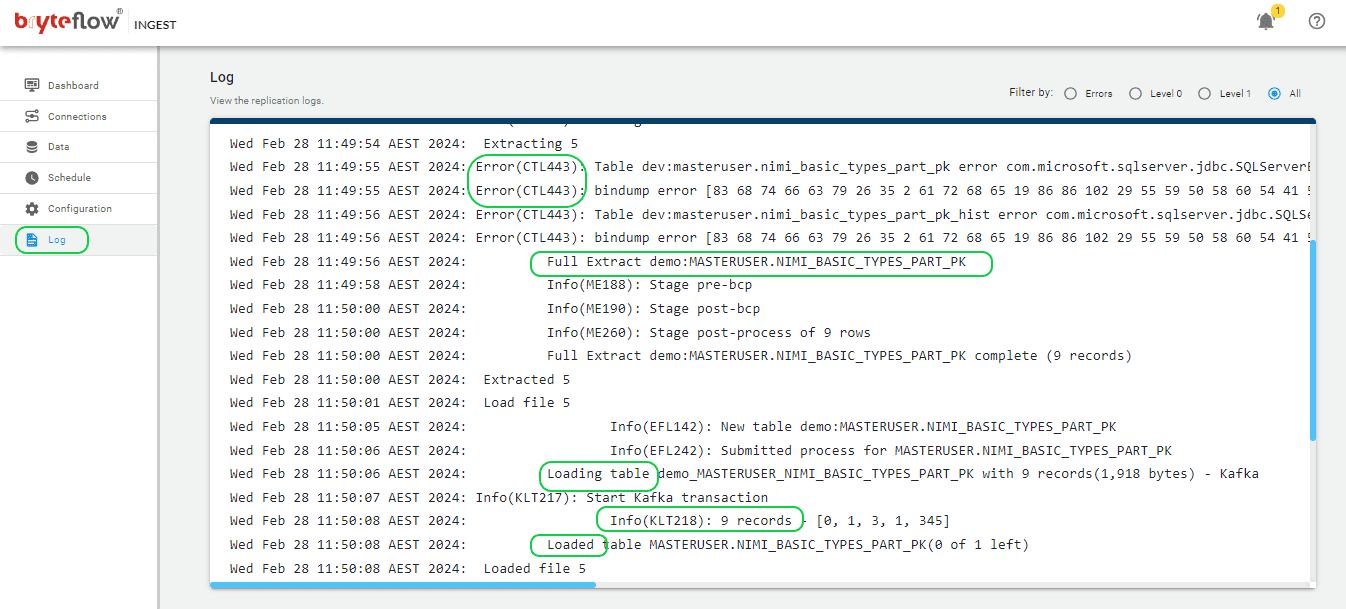
- Additionally, you can track the advancement via the log, providing real-time updates on the replication process, including extraction or loading statuses, the number of records loaded, and any encountered errors.
Step 4: Verify the loaded data in Kafka
To verify the data in Kafka, follow the below steps,
- Access Kafka Magic by logging in.
- Navigate to the “Kafka Cluster” section and choose your cluster from the dropdown menu.
- Next, select your desired topic from the options listed under the “Topic” dropdown.
- Finally, initiate the search process by clicking on the “Run Search” button.
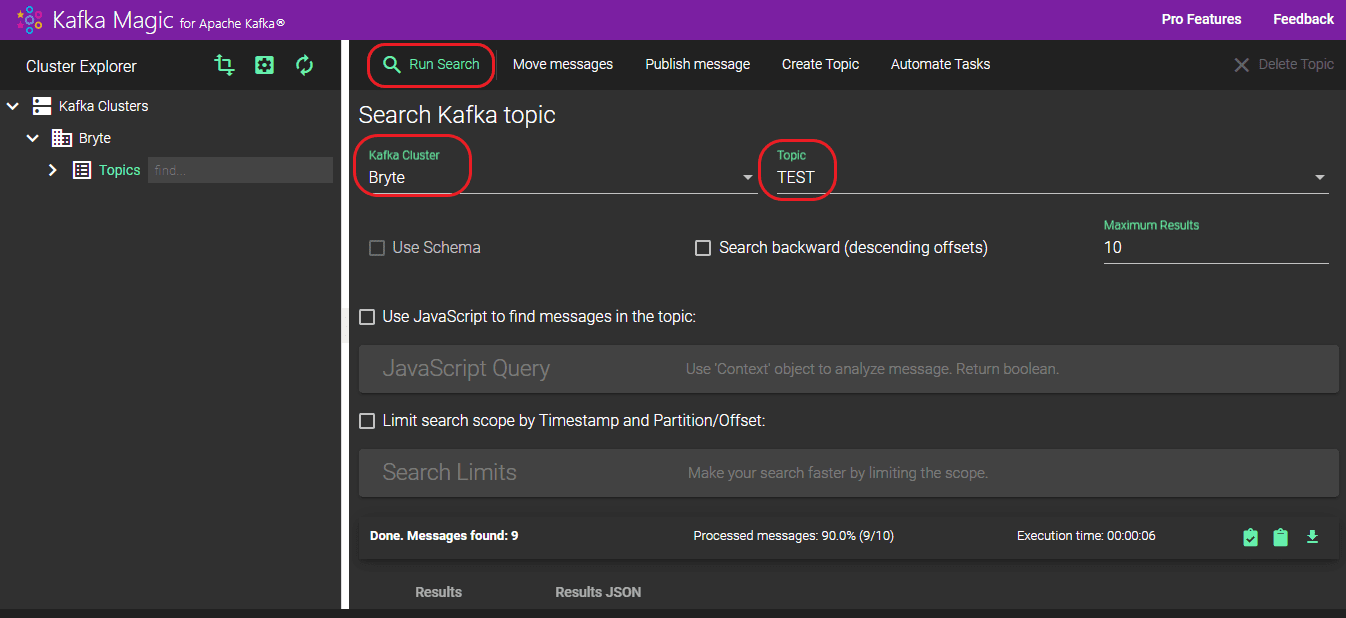
- The records loaded can be viewed under the “Results” section. A total of 9 records were loaded, with all 9 successfully transferred to the “TEST” topic.
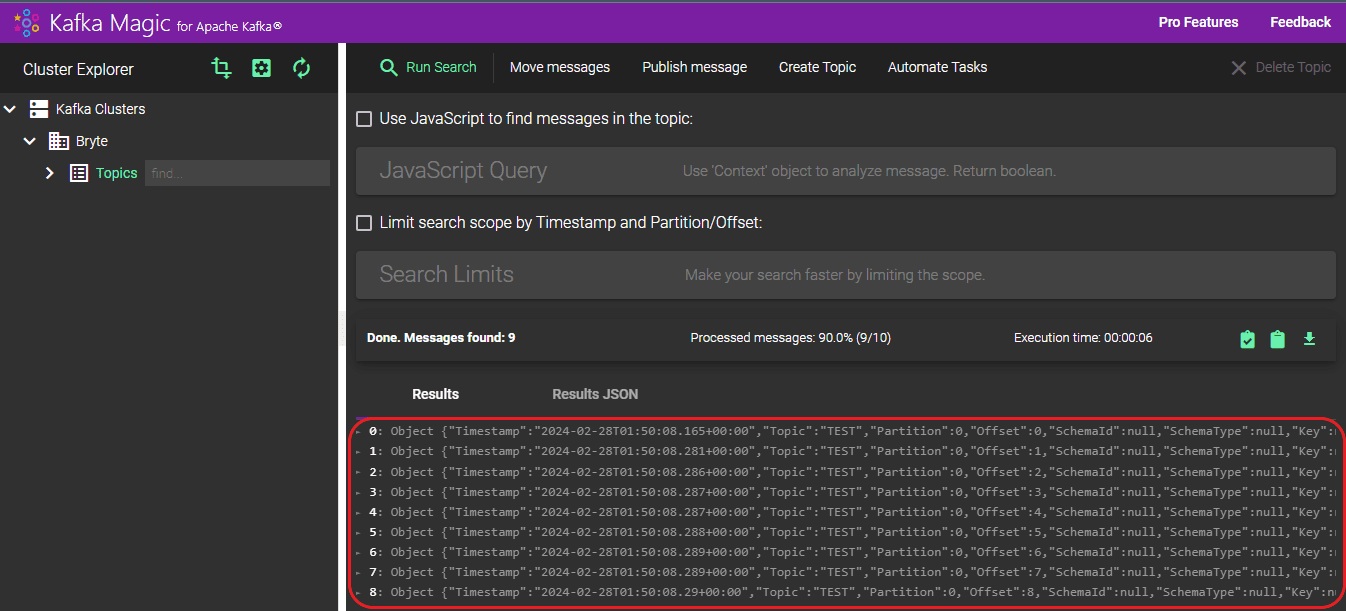
- You can also view the details of the loaded data in JSON format by selecting “RESULTS JSON”.

BryteFlow Connector for SQL Server Kafka CDC: Highlights
- After BryteFlow’s initial one-time load into Kafka Topics, incremental changes within the SQL Server database are delivered to Kafka in real-time, with high throughput and minimal latency by using either SQL Server CDC or SQL Server CT.
- BryteFlow’s CDC replication to Kafka is very fast and real-time, ideal for heavy datasets, and uses parallel multi-thread loading, smart partitioning and compression.
- BryteFlow specializes in real-time CDC replication from transactional databases like Oracle, SAP, SQL Server and PostgreSQL to Kafka.
- Every process is automated with BryteFlow, including data extraction, merging, data mapping, masking, schema and table creation, DDL and SCD Type 2 history. How BryteFlow Works
- BryteFlow delivers ready-to-use data in JSON format to Kafka.
- BryteFlow extends support for replication from all versions and editions of SQL Server.
- BryteFlow automatically populates the Schema Registry without any coding, making the overall process much faster. Since Kafka moves data only in byte format, the Schema Registry has to provide the schema to producers and consumers by storing a schema copy in its cache.
- For SQL Server, BryteFlow can CDC data from multi-tenant databases which is a boon for ISVs.
- A user-friendly point-and-click interface enables automated data flows, so there is no coding for any process.
- BryteFlow ensures high availability with an automated network catch-up feature, resuming replication automatically from the point it halted, after normal conditions are restored.
Conclusion
In summary, we have seen the strengths of SQL Server and Apache Kafka, Debezium as a SQL Server Kafka CDC tool and its limitations, and how to get SQL Server data to Kafka using Change Data Capture with BryteFlow. If you would like to see BryteFlow in action, do contact us for a demo.



