BryteFlow for Oracle CDC
XL Ingest: Partitioning for very heavy datasets
BryteFlow’s Oracle CDC: Availability guaranteed and lightning fast replication – it’s faster than Oracle GoldenGate, Qlik Replicate and HVR!
Replicate data using Oracle Change Data Capture to Snowflake, Redshift, S3, SQL Server, ADLS Gen2, Azure Synapse Analytics, BigQuery, Postgres, Databricks, SingleStore, Teradata and Apache Kafka . Supports on-premise and Cloud Oracle sources (e.g. AWS RDS). Oracle CDC (Change Data Capture): 13 things to know
Oracle Change Data Capture with BryteFlow
If you need availability and high throughput, BryteFlow’s Oracle replication with Change Data Capture (CDC) could be your new best friend. BryteFlow provides the highest throughput for Oracle replication with parallel extraction and loading which is completely configurable. It can be configured to work on a remote server, so that there is zero impact on the source, especially when large volumes are involved.
Connect Oracle to Databricks and Load Data the Easy Way
No code, Real-time Oracle Replication
BryteFlow’s Oracle replication replicates data in completely automated mode from start to finish -no coding needed. Its availability is legendary- you never need to check the Oracle data replication, even with server failure or a connection outage, BryteFlow will automatically configure itself, re-connect and continue where it left off. Learn about Oracle to SQL Server Migration
Solution Highlights:
- Oracle CDC replication with zero impact on source Data Migration 101
- High performance – multi threaded configurable data extraction and loading and provides the highest throughput in the market when compared with competitors Oracle to Redshift Migration Made Easy (2 Methods)
- Zero coding – for data extraction, merging, masking or type 2 history
- Analytics ready data assets on S3, Redshift, Snowflake, Azure Synapse, ADLS Gen2, Kafka, Postgres, BigQuery, Databricks, Teradata, Oracle and SQL Server
- Automated Data Reconciliation with checksums
- Support for terabytes of Oracle data ingestion, both initial and incremental
- Data Preparation for Machine Learning on Amazon S3
- Availability and high throughput GoldenGate CDC and a better alternative
- BryteFlow provides replication support for all Oracle versions, including Oracle 12c, 19c, 21c and future releases for the long term. Oracle to Azure Cloud Migration (Know 2 Easy Methods)
Why Your DBA Will Love Oracle Autonomous Data Warehouse
Oracle to Postgres Migration (The Whys and Hows)
Oracle vs Teradata (How to Migrate in 5 Easy Steps)
Oracle to Snowflake: Everything You Need to Know
BryteFlow’s Unique
Oracle Replication Architecture
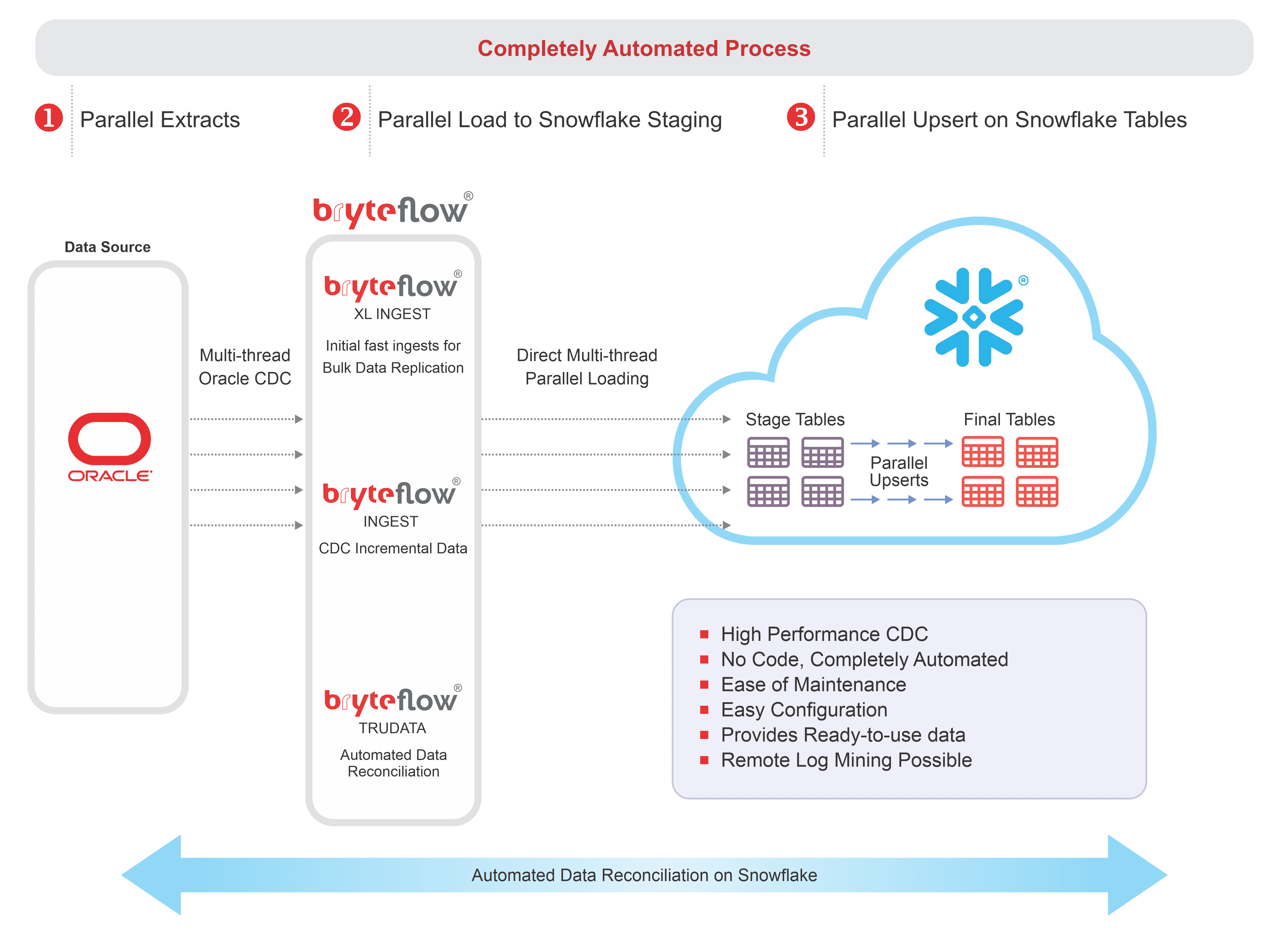
Key Features

- Zero coding – for extraction, merging, masking or type 2 history for all destinations including S3
- Enterprise-level security – deployed in your network
- High performance, parallel threaded initial or historical sync
- Highest Throughput for log based replication in the market compared to Goldengate, Qlik Replicate and HVR
- Time series your data
- Supports Oracle from version 10 including 19c
- Self-recovery from connection dropouts
- Smart catch-up features in case of down-time
- Remote server log mining option available for zero impact on source
- Transaction Log Replication
- Change Data Capture using mechanisms other than logs
Oracle Data Integration with a BryteFlow enabled automated Data Lake.
Oracle data integration with BryteFlow becomes easy because you can extract data from a full range of Oracle versions with just a few clicks. The software provides a range of data conversions out of the box including Typecasting and GUID data type conversion to ensure that your Oracle data is ready for analytical consumption. Further, BryteFlow enables configuration of custom business logic to consolidate Oracle data from multiple applications into AI and Machine Learning ready inputs when used on Amazon S3.

Oracle Replication with zero impact on source
BryteFlow eliminates the need for complex application procedures or queries to extract Oracle data. It extracts data from the Oracle application’s database level logs and does not require any additional agents or software to be installed in your Oracle environment.
Why Your DBA Will Love Oracle Autonomous Data Warehouse

Highest performance and throughput in the market
BryteFlow for Oracle delivers data at great speeds which is incomparable in the market. It uses parallel multi-threaded techniques for extraction and loading that are configurable and can scale with the amount of data, so that you can derive your insights faster.
Successful Data Ingestion (What You Need to Know)

Near real-time replication of data with CDC
With frequent incremental extractions, compression and parallel streams, BryteFlow ensures your data is constantly kept up-to-date with Oracle CDC and available to enable real-time analytics.

SQL workbench to blend data sources
An easy to use drag-and-drop workbench delivers a codeless development environment to build complex SQL jobs and dependencies across Oracle and non-Oracle data on S3.
Connect Oracle to Databricks and Load Data the Easy Way

Dashboard for monitoring
View Oracle replication dashboard and statistics so you can stay informed on the extraction process as well as reconciling differences between source and target data.

Automatic catch-up from network dropout
Pick up where you left off – automatically. In the event of a system outage or lost connectivity, BryteFlow for Oracle features an automated catch-up mode so you don’t have to check or start afresh.
Oracle to Snowflake: Everything You Need to Know

Masking & Tokenization
BryteFlow’s Oracle replication provides enterprise grade security to mask, tokenize or exclude sensitive data from the data extraction processes.
Oracle to Redshift Migration Made Easy (2 Methods)

Time-scale history for Oracle Replication
BryteFlow for Oracle provides out-of-the-box options to maintain the full history of every transaction from Oracle with options for automated data archiving. You can go back and retrieve data from any point on the timeline.
Oracle to Postgres Migration (The Whys and Hows)

Mike Hight,
Enterprise Data Architect,
Waterford
Using BryteFlow to handle CDC freed up our development resources to focus on analytics.
“As we were evaluating a major overhaul to our legacy reporting and analytics platform, we recognized that there were aspects to our process that were not really part of our core value proposition. Using BryteFlow to handle CDC freed up our development resources to focus on analytics.
Cost was an obvious concern. We are a non-profit focused on delivering educational software to as many children as possible. The ROI of using BryteFlow, contrasted with ongoing maintenance of our internal system provided significant financial support for our decision. We also evaluated other options in the marketplace but found BryteFlow to be the most cost-effective and easiest to work with during our evaluation process. In this space we found that many vendors tried very hard to justify a more expensive product by adding unnecessary bells and whistles. We went with Bryte because their product focused on their core competency and reliability.”

WATERFORD
The need to use student data in a more relevant way.
Waterford Research Institute needed to replace legacy reporting and dashboards with visualizations that were more consumable by education administrators, school principals, teachers and parents. They collected a lot of information about a student’s learning methods and progress and wanted to use this in a relevant way.
BryteFlow freed up the company’s development resources.
BryteFlow with automated CDC freed up the company’s development resources to focus on analytics and data was available in near real-time with no coding involved. Being a non-profit, they appreciated the cost-effective solution from BryteFlow to address their data management issues.
What is Oracle Change Data Capture (CDC)?
Oracle Change Data Capture is a technology for detecting all the changes to tables in an Oracle database. It captures all the inserts, updates and deletes on the tables in the Oracle database and accordingly updates the data in the destination database so data in the destination aligns with the Oracle data at source.
Why is CDC recommended for Oracle database replication to the destination?
Unlike ELT (Extract Load Transform) or ETL (Extract Transform Load), with CDC (Change Data Capture) you don’t need a time-consuming full refresh to update data. With CDC, only data that has changed is captured and ingested on the destination, saving much time and effort.
What are the challenges when doing Oracle CDC?
The challenges when doing CDC include, taking all the deltas or changes for the various tables and putting them together, so that the data is correct and readable on the destination. There can be multiple changes for a record, for example, an insert and an update or an update or a delete. They need to be processed intelligently to make sure the last record is captured correctly. Further, the processes need to be high performance as this could lead to bottlenecks.
How does BryteFlow overcome these challenges?
BryteFlow Ingest uses log based CDC and processes the changes automatically on the destination, whether it is Amazon S3, Redshift , Snowflake, Azure Synapse or SQL Server. It also maintains SCD type2 history on the destination automatically. It requires no coding and has high performance and resilience built in. It is a point and click, end-to-end solution that a business user can handle.