
This blog examines why and how you should connect and migrate data from SQL Server to Databricks. We examine the SQL Server vs Databricks premise, and the methods that could be employed to move data from SQL Server to Databricks. We illustrate a manual method in detail using SQL Server Management Studio and the Databricks Add Data UI to connect SQL Server to Databricks and load data. We also present how BryteFlow can provide a completely automated SQL Server Databricks migration.
Quick Links
- What is Databricks?
- What is Microsoft SQL Server?
- SQL Server to Databricks – Why Migrate?
- Databricks vs SQL Server: Reasons to Migrate to Databricks
- How to connect and load data from SQL Server to Databricks
- Using Databricks Native Tools to load data from SQL Server
- Manually connect and migrate SQL Server to Databricks
- Third-party Partners to load data to Databricks from SQL Server
- BryteFlow as a SQL Server to Databricks Migration Tool – Highlights
Have you ever thought of a data platform where you didn’t need to transfer data for querying to your data warehouse but could conveniently do it in your data lake itself? An immensely scalable environment where you could run machine learning models, perform advanced analytics, query data with BI tools, and generate reports, all in one place? Databricks Lakehouse is the unified analytics platform that is the answer to your prayers. Learn about Databricks Integration with BryteFlow
What is Databricks?
Databricks is a unified cloud-based platform that lends itself to a variety of data goals, including data science, machine learning, and analytics, as well as data engineering, reporting, and business intelligence (BI). Because a single system can handle both, affordable data storage as expected of a data lake, and analytical capabilities as expected of a data warehouse, the Databricks Lakehouse is a much-in-demand platform that makes data access simpler, faster, and more affordable. Databricks Lakehouse and Delta Lake, the Dynamic Duo
Databricks is extremely scalable and cost-effective. It can be installed on top of your existing cloud-whether that cloud is Google Cloud, Microsoft Azure, Amazon Web Services (AWS), or a multi-cloud combination of these cloud providers. It provides a collaborative and interactive workspace for users. Databricks is built on Apache Spark, the most active and powerful open-source information handling engine, and it is interesting to note that Databricks was developed by the same team that developed Spark. Databricks is known for its flexibility and supports multiple programming languages like Python, R, SQL, and Scala, making it available for different use cases. Databricks is very appropriate for big data environments helping organizations derive speedy insights, build innovative applications, and make effective data-driven decisions. Data Integration on Databricks
What is Microsoft SQL Server?
Microsoft SQL Server is an RDBMS (Relational Database Management System) developed and owned by Microsoft. It stores, manages and retrieves data when requested by other applications, either running on the same computer or on another computer in a network (On-premise or Cloud). SQL Server can be used for a wide range of applications, including analytics, business intelligence, and transaction processing. SQL Server has many editions, each designed to handle distinct workloads and requirements. These include:
SQL Server Enterprise Edition: Used for large scale enterprise data and mission-critical applications. The Easy Way to CDC from Multi-Tenant Databases
It is highly secure and can be used for Advanced Analytics, Machine Learning, etc. About SQL Server CDC
SQL Server Standard Edition: It is appropriate for mid-size applications and data marts. It can handle reporting and analytics on a basic level. SQL Server to Snowflake in 4 easy steps
SQL Server Web Edition: It is an affordable option for Web hosting and delivers scalability, low cost, and management features for web properties. SQL Server CDC To Kafka (Unbelievably Easy New Connector)
SQL Server Developer Edition: It is used to build, test, and demo and meant for a non-production environment. SQL Server vs Postgres – A Step-by-Step Migration Journey
SQL Server Express Edition: It is free to use and intended for small scale applications.
SQL Server is a database server built upon SQL (Structured Query Language). However, T-SQL (Transact-SQL) is SQL Server’s own implementation of the language and is Microsoft’s proprietary language with its own programming constructs. Additional capabilities include variable declaration, exception handling, stored procedure, and more. BryteFlow for SQL Server Replication
In 2016, after 20 years of working solely on Windows, SQL Server 2017 was made available to run on Linux as well as Windows. Data Integration on SQL Server
SQL Server to Databricks – Why Migrate?
Though SQL Server is an awesome RDBMS and used throughout the world, there are some reasons why you might want to migrate from SQL Server to Databricks. If your organization is large and has some innovative applications on the anvil that need machine learning models, involving huge datasets, or perhaps need advanced analytics based on data from multi-cloud implementations, then Databricks is a great option. Maybe you need to access your data fast, are working on a budget, or have large teams that need to work collaboratively and concurrently on the data – in all these cases too, Databricks can be a logical choice. Learn about SQL Server CDC
Databricks offers built-in libraries and APIs for data exploration, data engineering, and machine learning, enabling teams to derive valuable insights from their data. By migrating from your enterprise data warehouse or legacy data lake to the Databricks Lakehouse, you can simplify your data platform, innovate more quickly, and cut costs. All your data, analytics, and AI workloads can now be run on a modern, unified platform that is secured by a common governance approach and built on open standards. Data Integration on Databricks
Databricks vs SQL Server: Reasons to Migrate to Databricks
Databricks offers support for AI and Machine Learning Applications
Databricks ML is built on an open Lakehouse foundation with Delta Lake which allows machine learning teams to access and use data at scale. Databricks ML helps in data processing and team collaboration providing a complete lifecycle for Machine Learning that covers generative AI and large language models. Production pipelines are easy to set up and can be built without much engineering support. Open-source technologies like MLflow and Apache Spark, which are collaborative, self-service tools, can be used to accelerate the development of AI, ML, and real-time analytics capabilities. Databricks and Delta Lake – A Dynamic Duo
Databricks offers High Performance and Scalability
The foundation of Databricks is Apache Spark, a powerful distributed computing framework. Spark distributes data processing across multiple systems which allows Databricks to process very large datasets very fast, delivering performance as well as scalability for big data analytics and machine learning. Databricks can generate huge computing power to crunch through large volumes of data and thus scores over SQL Server, since the latter cannot process large volumes of data for analytics as fast. Databricks vs Snowflake: 18 differences you should know
Databricks supports Advanced Analytics and Agile Data Science Applications
Databricks provides native support for big data processing, making it well-suited for organizations dealing with massive datasets. As a unified analytics platform, it integrates seamlessly with various data sources and tools, allowing for multiple objectives like advanced analytics, machine learning, and data science workflows. Data Integration on Databricks
Databricks supports multi-user environments
Your team can use Databricks, an integrated workspace with a multi-user environment, to create new Spark-based machine learning and streaming applications. You can also create dashboards and interactive reports in an interactive notebook environment. This lets everyone view results in real time, train and tune machine learning models, and use any of Spark’s libraries to process data with ease. Cloud Migration Challenges
Databricks encourages collaboration and has a user-friendly workspace
Databricks Lakehouse makes data stores accessible to everyone in the company, providing your teams with a user-friendly interface so they can directly query the data without having to go through cumbersome ETL or ELT or Data Warehouse/Data Lake processes. It provides a unified environment for development, sharing and execution of data pipelines, models, and analytics tasks. Resources too, can be easily scaled up for querying increasing data volumes. Connect Oracle to Databricks and Load Data the Easy Way
Databricks has a Cloud-native and Serverless Architecture and is a Multi-Cloud Platform
Databricks is serverless and is created for the Cloud. You don’t need to manage and maintain any infrastructure. Databricks provides auto-scaling capabilities and allocates resources based on workload demands. Databricks is available on top of your existing cloud, whether that is Amazon Web Services (AWS), Microsoft Azure, Google Cloud, or even a multi-cloud combination of these. The multi-Cloud option is a boon for organizations involved in mergers and acquisitions, enabling them to integrate their individual technology implementations fast and without hassle. Compare Databricks vs Snowflake
Databricks is built on Zero Management Apache Spark
Databricks is built on open-source Apache Spark, your teams can spin up self-service Spark clusters that are highly available and optimized for performance. This makes it possible for anyone, even those with no DevOps experience, to build and deploy advanced analytics applications. Your team will always have access to the most recent Spark features with Databricks, allowing them access to the latest open-source innovation and to concentrate on the core objectives rather than infrastructure management. Additionally, Databricks provides monitoring and recovery tools that automatically and without user intervention, recover failed clusters. Get a Data Lakehouse on S3 without Delta Lake
No Lock-in and no proprietary data formats with Databricks
Databricks is open-source and has no vendor lock-in and proprietary data formats. SQL, Python, Scala, Java, and R can be used as coding languages which most data professionals are familiar with, and it uses data formats like Parquet, ORC, JSON, CSV, Avro, Text and Binary apart from Delta Lake and Delta Sharing, which means there are no obstacles in accessing and working with data. Choosing between Parquet, ORC and Avro
Databricks has Unique Ecosystem Integration and Architecture
Databricks integrates seamlessly with cloud storage platforms, data lakes, and streaming applications. It stores and processes massive amounts of data using the Cloud platform’s data lake for storage, and processes data via the Delta Lake layer. Delta Lake too, is open-source, and can be used to enable a data warehousing compute layer on top of a conventional data lake. You don’t need to load the data to a cloud data warehouse (as in the case of SQL Server) for processing, making for faster time to insight. Databricks and Delta Lake – A Dynamic Duo
Databricks is designed for high throughput and fast processing
Databricks has the Apache Spark engine under its hood to process data at scale, lightning fast. More recently it has added Photon, another engine that enables Databricks to cover the full data processing spectrum from start to end. In contrast, databases like SQL Server are designed to be responsive and to provide low latency, but on smaller volumes of data. Databricks vs Snowflake: 18 differences you should know
Open and Secure Data Sharing with Databricks
Delta Sharing in Databricks is the first open protocol in the industry for secure data sharing. You can easily share data without needing to copy it to another system, regardless of where the data is stored. You can visualize, query, enrich, and manage shared data from your preferred tools thanks to integrations with leading platforms and tools. You can use Delta Sharing and directly connect to shared data using Pandas, Apache Spark, Rust, Tableau, or other such systems with the open protocol. You can manage and audit shared data across organizations from a central location through native integration with the Unity Catalog. This enables you to confidently share data assets with partners and suppliers to improve business operations, while meeting security and compliance requirements. With Delta Sharing you can use cloud storage systems like Amazon S3, ADLS, and GCS to share terabyte-scale data reliably and securely.
Superior Data Governance with on Databricks with Delta Lake
Databricks Delta Lake reduces risk by providing data governance with fine-grained access controls, a feature that is typically unavailable in data lakes. Through audit logging, you can update data in your data lake quickly and accurately to meet GDPR regulations and maintain better data governance. The Unity Catalog, the first multi-cloud data catalog for the Databricks Lakehouse, incorporates these capabilities natively on Databricks and further enhances them.
Databricks is a cost-efficient, affordable solution
SQL Server can prove expensive, especially for licensing for larger deployments, while Databricks offers flexible pricing models, including pay-as-you-go options. You can reduce costs by taking advantage of the Databricks serverless architecture, easy scalability as per actual usage, and benefit from cloud provider pricing models.
Databricks provides flexibility in handling of data
Databricks is very flexible in terms of the data it can handle, structured, unstructured, and streaming. Unstructured data includes text, images, video, and audio. It can also handle different types of workloads including analytics, ML, BI data science use cases etc. SQL Server handles mostly structured data. Databricks supports both – direct access to data and conventional ETL to speed up the time to insight.
SQL Server Drawbacks
Apart from the multiple advantages of Databricks, there are some inherent drawbacks of SQL Server which may motivate users to move to Databricks. SQL Server CDC To Kafka (Unbelievably Easy New Connector)
The SQL user interface is not easy to work with
SQL has a user interface that makes things appear more complicated than they actually are. The interface can prove intimidating to users.
Performance tuning in SQL Server can be complicated
Users without specialized knowledge may find query optimization and performance tuning challenging. for very large data sets. BryteFlow for SQL Server Replication
SQL Server can have high licensing costs
Though free versions of the SQL Server software are available for educational or development purposes, there is a licensing fee for commercial use. SQL Server licensing is evolving constantly and can be difficult to get your head around.
SQL Server needs high security
SQL Server databases are under threat very often since the database does have vulnerabilities, regardless of version. Also, the databases have a lot of sensitive data that make them prime targets for security breaches.
SQL Server users get limited control over data
Users of SQL are not given total control over databases due to some business rules that are not apparent.
SQL Server source control support may be lacking
There is no native source control support in SQL Server. You need to use third-party tools to keep track of changes made to database objects.
How to connect and load data from SQL Server to Databricks
Here we look at 3 ways you can connect Databricks to SQL Server and load data into a Delta Lake-backed Databricks Lakehouse. Data that is migrated to Databricks lands into the Delta Lake layer. Databricks vs Snowflake: 18 differences you should know
What is Delta Lake?
The Databricks Lakehouse Platform’s foundation for storing tables and data is Delta Lake, the optimized storage layer that sits on top of a data lake. Delta Lake is open-source software and adds a file-based transaction log to Parquet data files for ACID transactions and scalable metadata handling. Delta Lake is fully integrated with Structured Streaming and Apache Spark APIs. This makes it simple to use a single copy of the data for both batch and streaming operations and provides incremental processing of data at scale. Delta Lake supports batch data processing, unified streaming, ACID transactions, and scalable metadata. Databricks and Delta Lake – A Dynamic Duo
Data Type Mapping for moving data from SQL Server to Databricks
Databricks does not support all data types. As a result, it is necessary to manually adjust the MSSQL data types to their equivalent Databricks data types in order to connect and load data from SQL Server to Databricks.
Data type support and mapping for SQL Server sources in Databricks.
| SQL Server source type | Databricks | |
| bigint | 64-bit integer | bigint |
| binary | Fixed-length binary data | binary |
| binary(s) | Fixed-length binary data | binary |
| bit | 1, 0 or NULL | not supported |
| char | Fixed-size string data | string |
| char(s) | Fixed-size string data and scale | string |
| date | Date (year, month and day) | date |
| datetime | date that is combined with a time of day with fractional seconds that is based on a 24-hour clock. | timestamp |
| datetime2 | Date and time with fraction (milliseconds) | timestamp |
| datetimeoffset | Date that is combined with a time of a day based on a 24-hour clock like datetime2, and adds time zone awareness based on UTC (Universal Time Coordinate or Greenwich Mean Time). | timestamp |
| decimal | Fixed-point number | decimal(38) |
| decimal(p,s) | Fixed-point number with precision and scale | decimal(p,s) if p<=38, s<=37
string if p>38 or s>37 |
| decimal(p) | Fixed-point number with precision | decimal(p,0) if p<=38
string if p>38 |
| float | Floating-point number | float |
| float(p) | Floating-point number with precision up to a maximum of 64 | float |
| image | Variable-length binary data, ⇐ 2G | binary |
| int | 32-bit integer | bigint |
| money | 64-bit currency amount | not supported |
| nchar(s) | Fixed-size string data with scale | string |
| ntext | Variable-length Unicode UCS-2 data, ⇐ 2G | string |
| numeric | Fixed-point number | decimal(38) |
| numeric(p,s) | Fixed-point precision and scale number | decimal(p,s) if p<=38, s<=37
string if p>38 or s>37 |
| numeric(p) | Fixed-point precision number | decimal(p,0) if p<=38
string if p>38 |
| nvarchar(s) | Variable-size string data with scale | string |
| real | Single-precision floating-point number | float |
| smalldatetime | a date that is combined with a time of day. The time is based on a 24-hour day, with seconds always zero (:00) and without fractional seconds. | timestamp |
| smallint | 16-bit integer | bigint |
| smallmoney | 32-bit currency amount | not supported |
| text | Variable-length character data, ⇐ 2G | string |
| time | Time (hour, minute, second and fraction) | timestamp |
| tinyint | 8-bit unsigned integer, 0 to 255 | bigint |
| varbinary | Variable-length binary data | binary |
| varbinary(s) | Variable-length binary data with scale | binary |
| varchar(s) | Variable-length character string | string |
| xml | XML data | string |
Methods of SQL data conversion and import into Databricks Delta Lake
There are several methods to load data into your Databricks Lakehouse. One option is to manually migrate data from MSSQL to Databricks. Alternatively, you can use a third-party automated tool like BryteFlow to migrate the data. Here we outline the different methods you can use to move SQL Server data to Databricks. SQL Server to Databricks with BryteFlow
- Using Databricks Native Tools to load data
- Manually migrating data with SSMS and Databricks Add Data UI.
- Loading data with third-party partners like BryteFlow
Using Databricks Native Tools to load data from SQL Server
Delta Live Tables
Delta Live Tables help in building data pipelines that can be maintained, tested and are reliable. It is a declarative framework by which you can define the transformations needed to be done on the data and Delta Live Tables will manage the clusters, orchestrate tasks, and monitor them. It also helps in quality control and error management. Data can be uploaded from any data source supported by Apache Spark on Databricks with Delta Live Tables. Delta Live Tables Datasets are of 3 types: Streaming Tables, Materialized Views, and Views.
Auto Loader can be used in Delta Live Tables pipelines. There is no need to provide a schema or checkpoint location because Delta Live Tables handles these settings for your pipelines automatically. Delta Live Tables is an extension of the Apache Spark Structured Streaming functionality that lets you deploy a production-quality data pipeline with just a few lines of declarative Python or SQL. Delta Live Tables help in:
- Cost-saving autoscaling of compute infrastructure
- Expectations-based data quality checks
- Handling schema evolution automatically
- Monitoring via event log metrics
COPY INTO Statement
The COPY INTO is a SparkSQL statement that enables loading of data from a file location into a Delta Table. This is a re-triable and idempotent operation – files in the source location that have already been loaded are skipped. COPY INTO simplifies data movement and reduces the code to be written. It is a compact statement that enables complex data loading methods. COPY INTO supports secure access in multiple ways, including the ability to use temporary credentials.
Learn More
Auto Loader
Auto Loader is a Databricks feature that without any additional setup, can process new data files incrementally as they arrive in Cloud storage. It enables rapid ingestion of data from Azure Data Lake Gen2, Amazon S3 and Google Cloud Storage. Auto Loader has the capability to load data files from Databricks File System (DBFS, dbfs:/), AWS S3 (s3://), Azure Data Lake Storage Gen2 (ADLS Gen2, abfss://), Google Cloud Storage (GCS, gs://), Azure Blob Storage (wasbs://), and ADLS Gen1 (adl://).
Auto Loader provides a Structured Streaming source called cloudFiles. Provided there is an input directory path on the cloud file storage, new files are automatically processed by the cloudFiles source as they land, with the option of also processing existing files in that directory. JSON, CSV, PARQUET, AVRO, ORC, TEXT, and BINARY FILE formats are all supported by Auto Loader. Databricks Auto Loader uses Structured Streaming and checkpoints to process files when they land in the specified directory. Auto Loader has the capability to process millions of files and supports both – near real-time ingestion and batch processing. In Delta Live Tables, Auto Loader supports both, Python and SQL.
Learn More
Conversion of Parquet or Iceberg data to Delta Lake and Databricks Clone functionality
Parquet and Iceberg tables stored in external locations managed by Unity Catalog can be converted to Delta Lake tables once with the CONVERT TO DELTA SQL command, for querying on the Databricks Lakehouse. Existing Parquet files can be configured as external tables in Unity Catalog and converted to Delta Lake to benefit from all the features of the Databricks Lakehouse.
For incremental conversion of data, the Databricks clone functionality can be used. It combines Delta table cloning and conversion of tables to Delta Lake format. Databricks Clone can be used to ingest Parquet or Iceberg data in the following circumstances:
- While performing migration from Parquet and Iceberg to Delta Lake but source tables are needed to be in use afterwards.
- An ingest-only sync is required between target and source that gets the updates, deletes, and inserts.
- An ACID-compliant source data snapshot needs to be created for machine learning, batch ETL or reporting.
Manually connect SQL Server to Databricks to load data
Here we will show you a manual method to connect and transfer data from MSSQL to Databricks by generating data in CSV files using SQL Server Management Studio and loading them in Databricks through the Add Data UI. However, there may be errors due to differences in data type compatibility between the two databases. BryteFlow for SQL Server Replication
What is MSSQL Server Management Studio?
SQL Server Management Studio (SSMS) is a single platform that can handle various aspects of SQL infrastructure. You can access, configure, administer, and manage all elements associated with SQL Servers. It has a diverse range of graphical tools and script editors that provide developers and database administrators a comprehensive utility to interact with SQL Server. Here we will use MSSQL Server Management Studio to export data in CSV file format for importing it into Databricks using the Databricks Add Data UI.
What is Add Data UI in Databricks?
The Databricks user interface (UI) provides a visual platform for accessing various functionalities, including workspace folders, their contents, data objects, and computational resources. The Add Data UI enables you to effortlessly import data into Databricks from diverse sources. Through the Add Data UI you can upload CSV, TSV, or JSON files to either create a new managed Delta Lake table or overwrite an existing one.
It is possible to upload data to the staging area without creating a connection to compute resources, but it is imperative to choose an active compute resource to preview and configure your table. You can preview upto 50 rows from your data when configuring options for the uploaded table. The data files for managed tables in Databricks are stored in the locations specified for the associated schema configuration. You must have the correct permissions to create a table within a schema. You can create managed Delta tables in the Unity Catalog or in the Hive Metastore.
Limitations of Databricks Add Data UI (Upload)
- It supports only CSV, TSV, or JSON files.
- Only 10 files can be uploaded at a time with Upload UI.
- The total file size of the uploads must not be more than 100 megabytes.
- The file must be a CSV, TSV, or JSON and have the extension “.csv”, “. tsv”, or “. json”.
- Zip, Tar and other compressed files are not supported.
These are the main steps in manual Migration of CSV data from SQL Server to Databricks
1.1 Export MS SQL data into intermediate storage using SQL Server Management Studio.
1.2 Load data into Databricks through the Add Data UI.
1.3 Update the table details and convert the data types into Databricks Delta Lake format.
1.1 Export MS SQL data into intermediate storage – using SQL Server Management Studio.
We can use the SQL Server Management Studio to copy the data into an intermediate storage before loading into Databricks. Follow the steps mentioned below to export the data:
Step 1: Open MS SQL Server Management Studio. Then connect to the MS SQL Server. Go to the database that needs to be migrated. Right click on the database > Tasks > Export data.
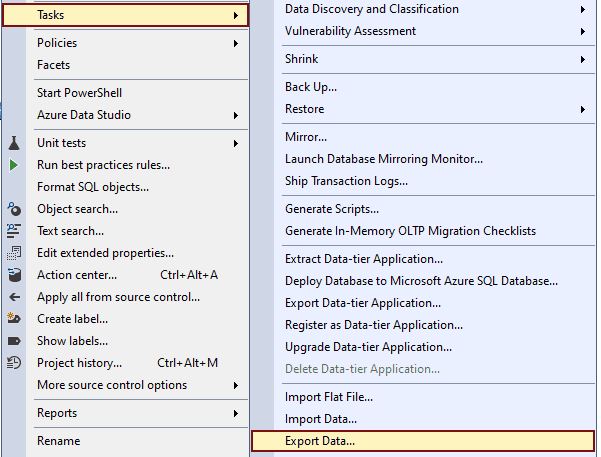
Step 2: In the “Choose a Data Source” window. Select “SQL Server Native Client” from the Data source drop-down list. Then choose “Windows Authentication”, and your Database from which the data will be exported. Once that’s done, click the “Next” button.
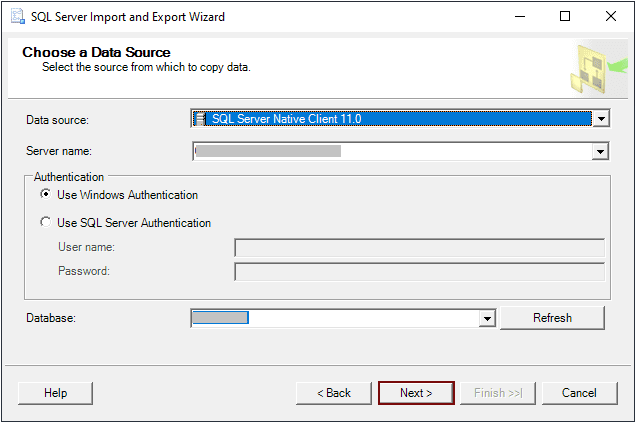
Step 3: From the “Choose a Destination” window, you have three options to export data – CSV, Excel or Flat File. Here we choose “Destination as CSV”.
Destination as CSV – CSV files are the simplest files for storing and transferring large amounts of data. Select “Flat File” from the Destination drop-down list. In the “File Name” text box, give the path and file name of the CSV file or select the file by browsing. Then give the file extension as “.CSV”. Select the format. Once done, click the “Next” button.
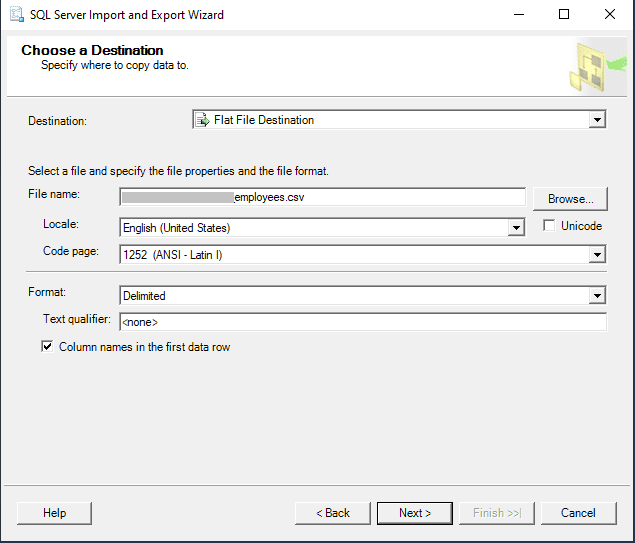
Step 4: In the “Specify Table Copy or Query” window, choose the “Copy data from one or more tables or views” option.
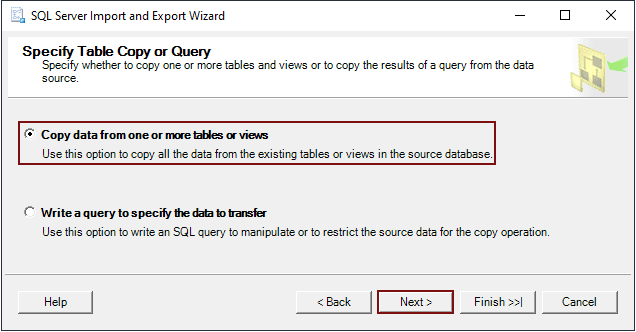
Step 5: The next window is the “Configure Flat File Destination” for CSV files. In this window, you have the option to select one or multiple tables or views for exporting data. After making your selections, you will need to specify the characters that will be used as delimiters for the destination file, both for rows and columns. The “Preview” button in this window allows you to preview the data that will be exported.
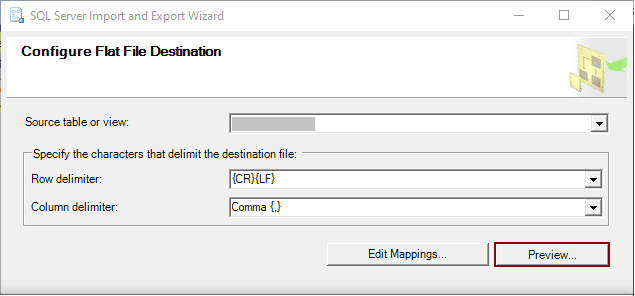
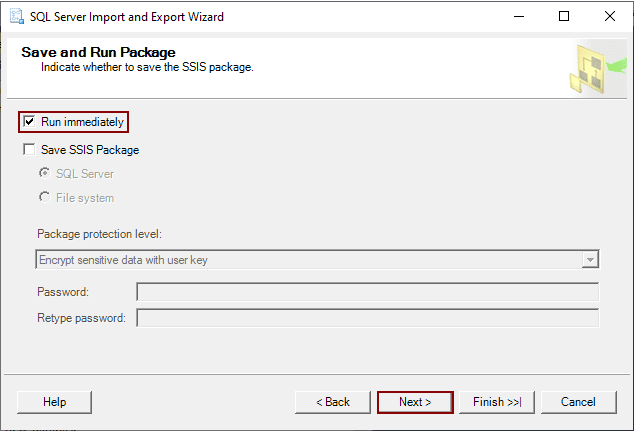
Step 6: In the “Save and Run Package” window, you have the option to decide what happens to the data in the SQL Server database. You can choose to export it to a CSV file right away by selecting the “Run immediately” option, or you can save the copied data as an SSIS package by selecting the “Save SSIS Package” checkbox. Once you’ve made your choice, you can either click the “Finish” button or proceed to the review step by clicking the “Next” button.
Step 7: The “Complete the Wizard” window, is the last step in which decisions that were made in the wizard can be verified. Once everything is confirmed, click the “Finish” button to complete the process. Following that, a final step will appear, displaying progress and status details regarding the export of SQL Server data.
1.2 Load data into the Databricks through Add Data UI
Step 1: Open Databricks.
Make sure the cluster is up and running. Then go to the “New” tab and click on “Data” tab.
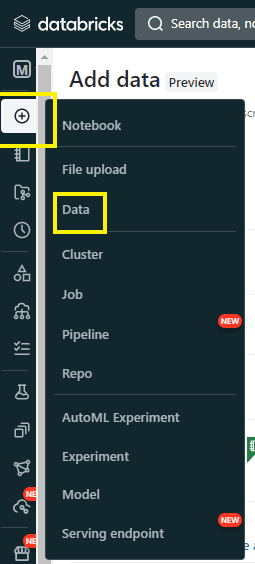
Step 2: Once the Data tab is open, it opens the “Add Data” window. Select “Upload Data” option.
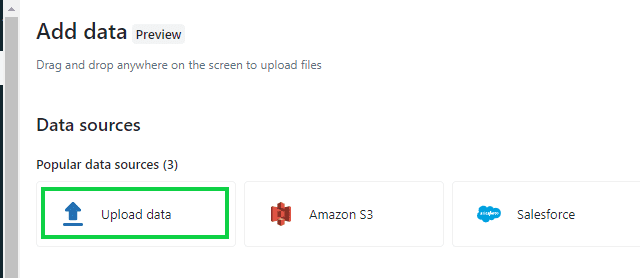
Step 3: Then, with the “Upload Data” window open. Drag your file onto the “Upload Data” window or browse and select the file. You have the option to select more than one file.
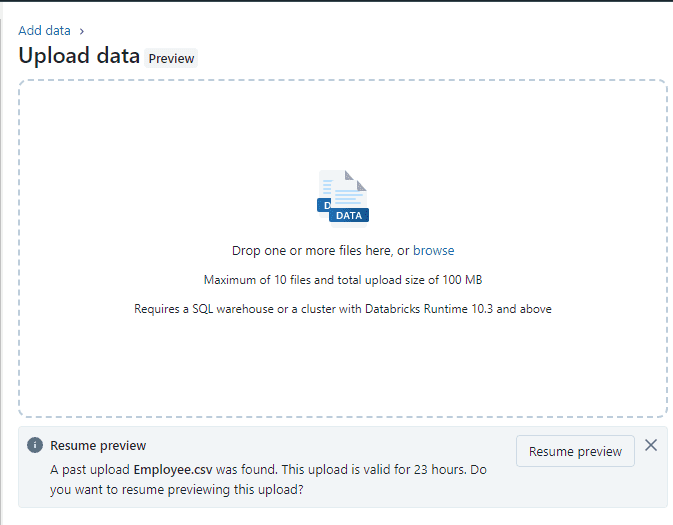
Step 4: When you have selected the file or dropped the file into the upload window, the UI will automatically upload the file and show the preview of the file. It looks like this:
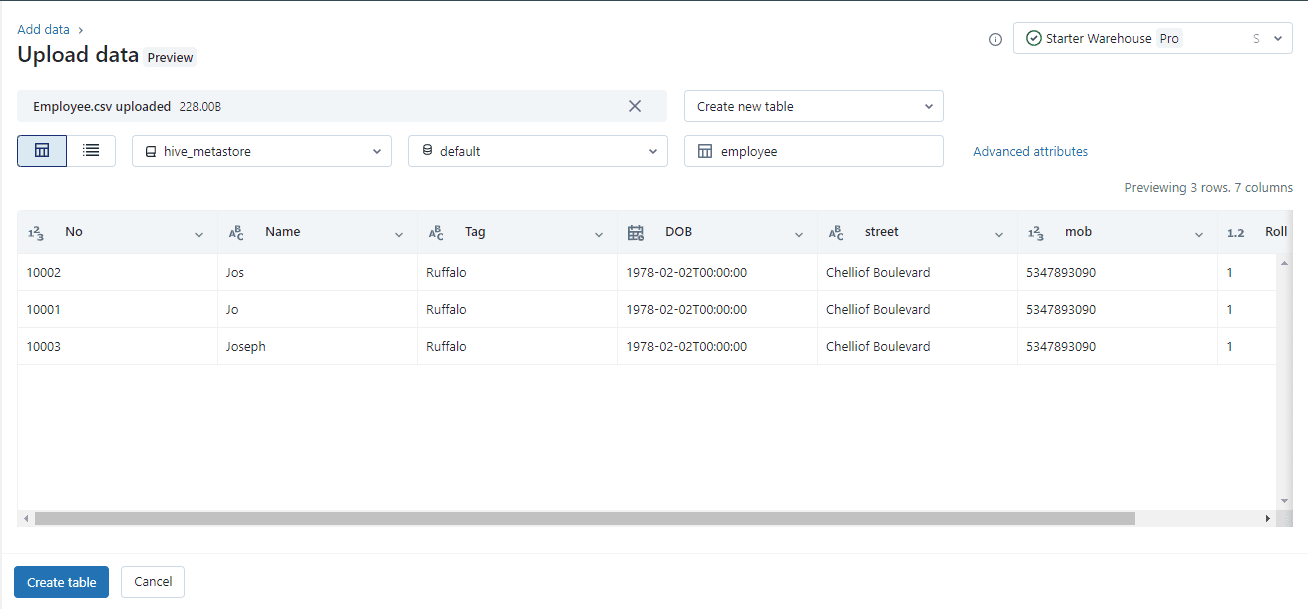
1.3: Update the table details and convert the data types into Databricks Delta Lake format.
Once the file is uploaded by the UI, it shows the preview of the file. Here, we can do all the edits and data type conversions before creating the table.
Step 1: We can see the preview in ‘Vertical’ as well.
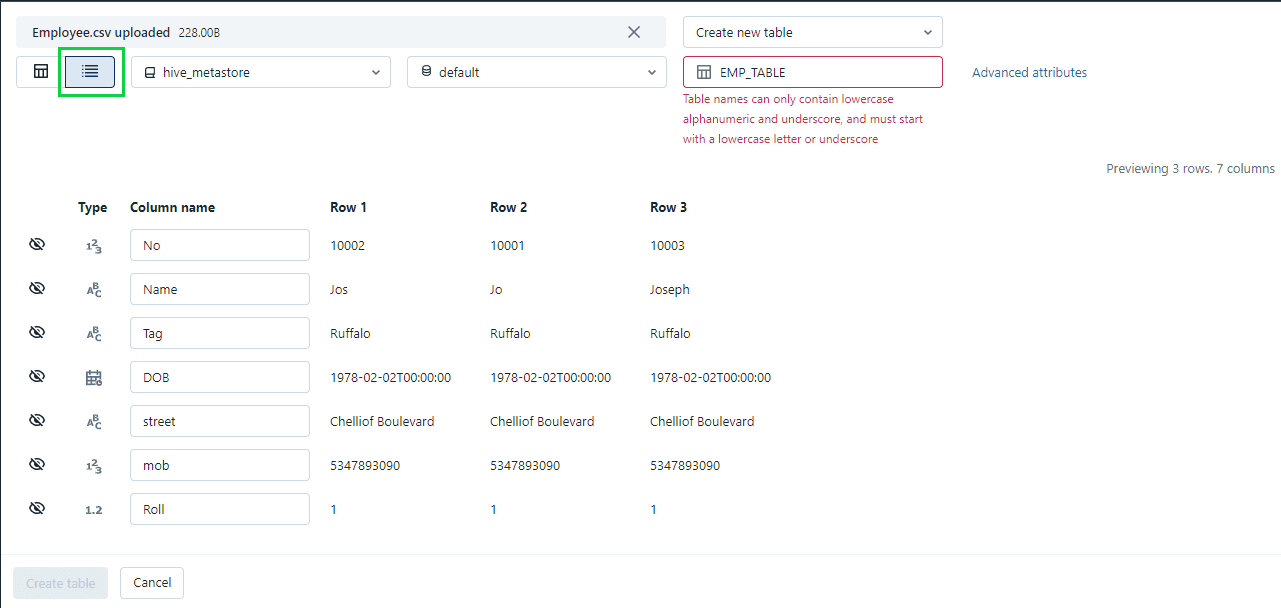
Step 2: In this window we can edit:
- The details of the table such as ‘Name of the Table, Name of the Columns and select different schema’.
- Different schema can be selected by clicking on the down arrow next to the “Default Schema”.
- Table names can only contain lowercase alphanumeric and underscore, and must start with a lowercase letter or underscore.
- Column names do not support commas, backslashes, or unicode characters (such as emojis). To edit the column name, click the input box at the top of the column.
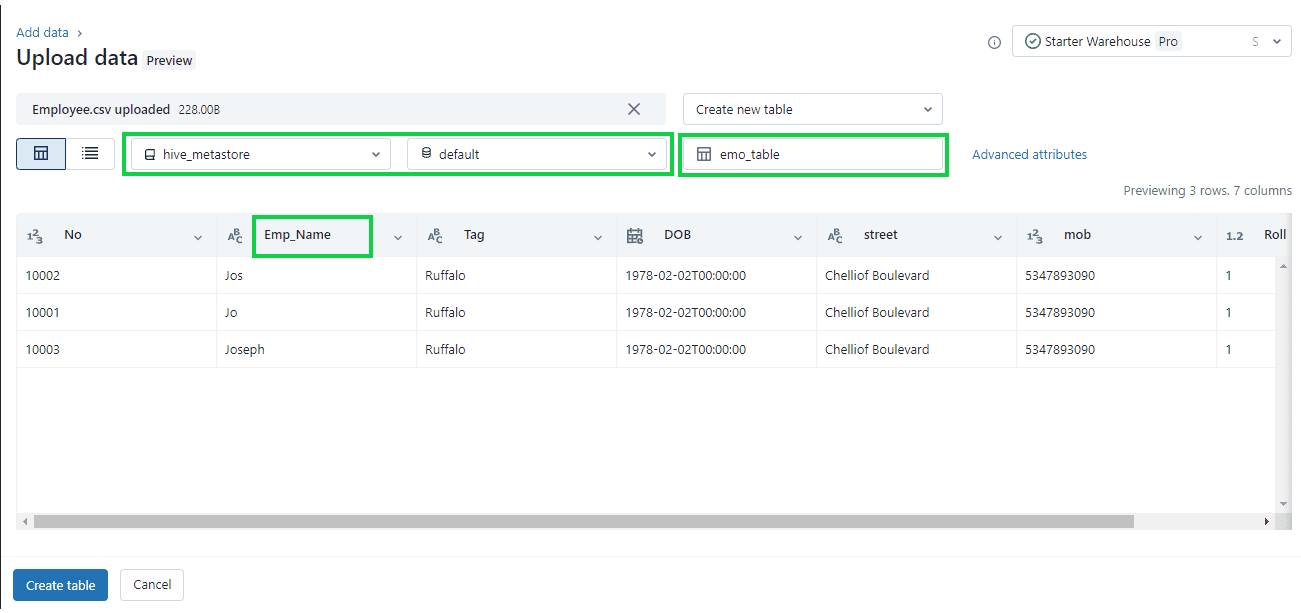
Step 3: The “Data Types”.
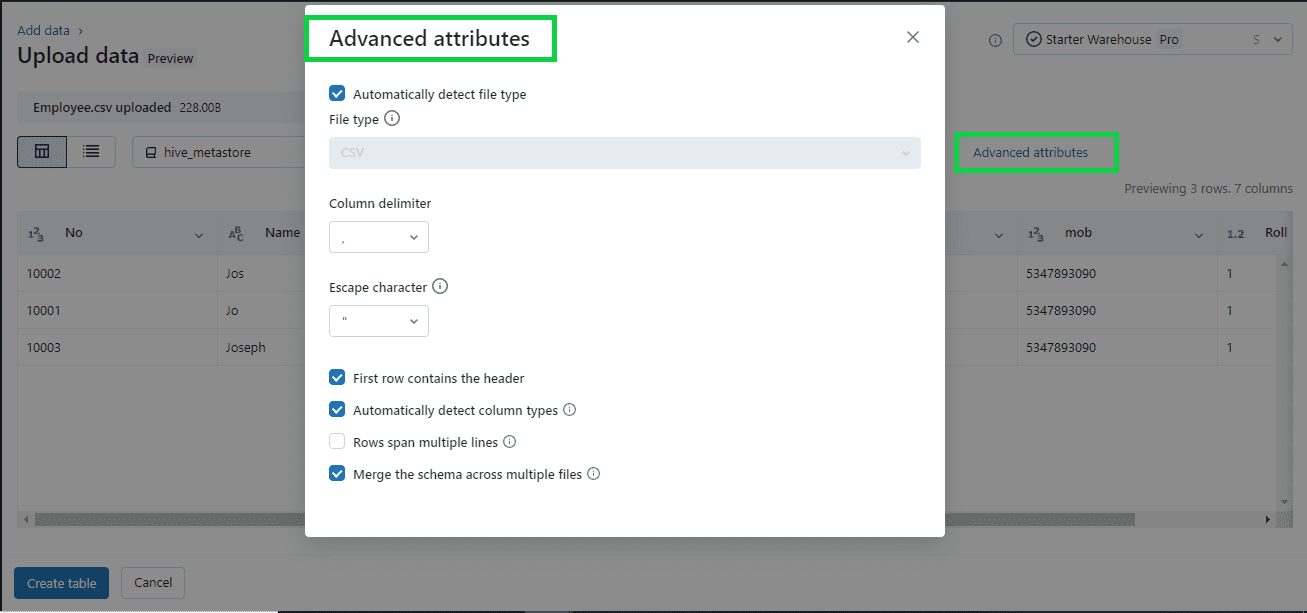
Format options depend on the file format you upload. Common format options appear in the header bar and are inferred by default for CSV and JSON files. You can interpret all columns as STRING type by disabling “Advanced attributes > Automatically detect column types”.
For CSV, the following options are available:
- First row contains the header (enabled by default): This choice determines if the CSV/TSV file includes a header.
- Column delimiter: The column separator character must be a single character and cannot be a backslash. By default, CSV files use a comma as the separator.
- Automatically detect column types (enabled by default): The file content is automatically analyzed to detect column types. You have the option to modify the types in the preview table. When this setting is disabled, all column types are assumed to be strings.
- Rows span multiple lines (disabled by default): This option helps to identify each row in a file and span into multiple lines, rather than load all rows as a single row into a file.
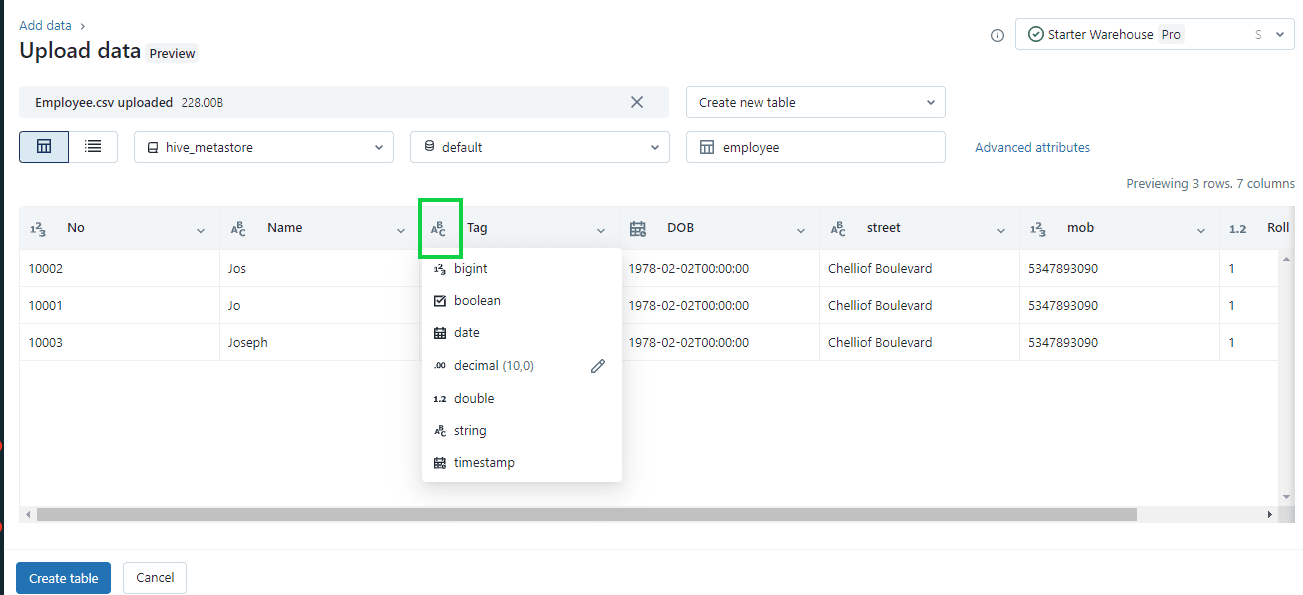
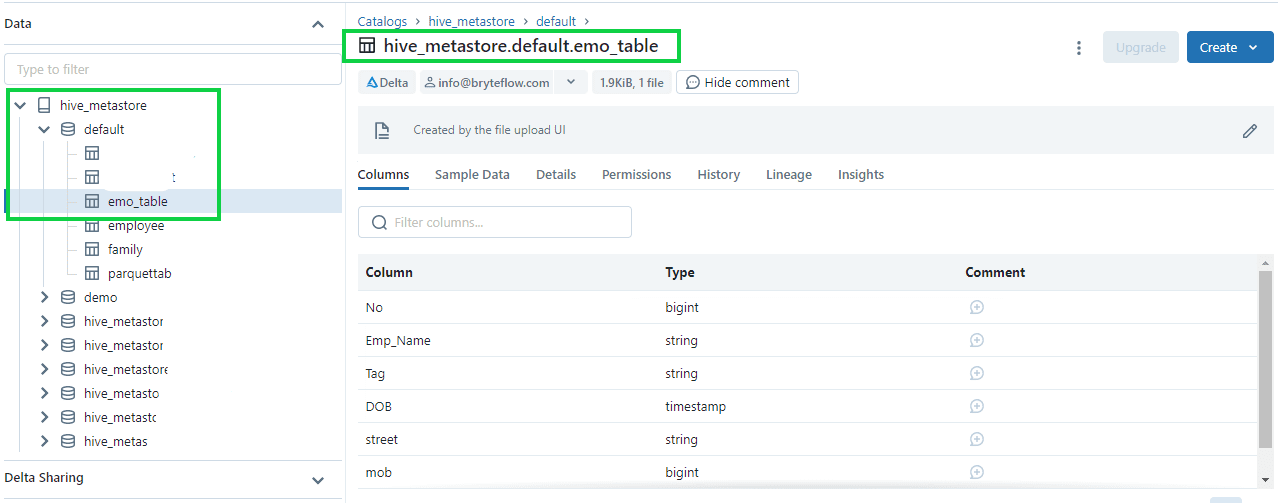
Step 4: Once editing is completed, click on “Create Table” option on the bottom left to create the table. The table creates as per conditions and edits we have provided.
Third-party Partners to load data to Databricks from SQL Server
There are a lot of data migration tools that can migrate your data from SQL Server to Databricks. What you need is a tool that is no-code, has high throughput and low latency and whose performance is optimized for Databricks best practices. Our very own BryteFlow is one such tool that can automatically connect Databricks to SQL Server and deliver completely automated SQL Server to Databricks migration.
Why use BryteFlow to connect SQL Server to Databricks?
If you are looking to load SQL Server data to Databricks on AWS, Azure or GCP, BryteFlow can make the journey completely automated and real-time. BryteFlow replicates SQL Server data to Databricks, syncing changes at source using a variety of CDC options, including SQL Server Change Data Capture and SQL Server Change Tracking. It loads the first full refresh with multi-threaded parallel loading, automated partitioning, and compression, and delivers deltas with automated Change Data Capture, merging updates, inserts and deletes automatically on target. BryteFlow transforms and delivers ready-to-use data to the Databricks Delta Lake for Machine Learning and Analytics.
BryteFlow as a SQL Server to Databricks Migration Tool – Highlights
- No-code tool – BryteFlow Ingest automates data extraction, schema creation, DDL, SCD Type2, masking and other processes, provides real-time data.
- Get ready to use data at the destination whether S3, Redshift, Snowflake, Azure Synapse, ADLS Gen2, Databricks, PostgresSQL, Kafka or SQL Server.
- Low latency, high throughput, moves petabytes of data in minutes- 1,000,000 rows in 30 seconds. Matillion and Fivetran Alternative for SQL to Snowflake Migration
- BryteFlow supports SQL Server Always ON configuration. SQL Server to Postgres Migration
- BryteFlow SQL Server replication works whether Primary Keys are available or not.
- Point-and-click easy to use user interface, self-service, spares your DBA’s time.
- Databricks replication best practices (AWS & Azure) are built in.
- BryteFlow enables out-of-the-box data conversions and provides analytics-ready data.
- BryteFlow supports on-premise and cloud hosted SQL Server sources. (e.g. AWS RDS, Azure SQL DB, Cloud SQL etc.) and can be installed on-premise or on the Cloud.
- BryteFlow automates CDC from multi-tenant SQL databases. It enables data from multi-tenant SQL databases to be defined and tagged with the Tenant Identifier or Database ID from where the record originated to make data usage simple. The Easy Way to CDC from Multi-Tenant Databases
- BryteFlow offer multiple CDC replication options such as SQL Server Change Data Capture, SQL Server Change Tracking, Timestamps and Log Shipping.
- BryteFlow’s SQL CDC replication has zero impact on source.
- BryteFlow supports all SQL Server Editions and Versions.
- BryteFlow has high availability with automatic network catchup in case of network failure or power outage.
Contact us for a Demo of BryteFlow or get a Free POC.



