
This blog elaborates on Change Data Capture from multi-tenant databases, what multi-tenant database architecture is, its benefits and limitations. It also looks at issues with Change Data Capture from multi-tenant databases and how BryteFlow as a replication tool offers easy, automated CDC from multi-tenant databases to Cloud platforms.
Quick Links
- Do you have Enterprise Customers in your Multi-tenant Database?
- A Look at Software Multi-Tenancy
- Benefits of Multi-Tenant Database Architecture
- Limitations of Multi-Tenant Database Architecture
- Multi-Tenant Databases and Their Designs
- Change Data Capture from Multi-Tenant Databases – Some Issues
- BryteFlow as a CDC Tool for Multi-Tenant Databases
- About the BryteFlow Replication Tool
- BryteFlow Highlights for Change Data Capture
- BryteFlow for CDC from Multi-Tenant SQL Server Databases
- Brightly Case Study
Do you have Enterprise Customers in your Multi-Tenant Database?
If you are an ISV (Independent Software Vendor) or if you have multiple enterprise customers for your SaaS application, chances are you may have the data of thousands of clients in your multi-tenant database. Maybe the data keeps getting updated every minute and you need the data in real-time to run analytics on it. Who is using which product, what is the renewal rate of subscriptions, whether client invoices have been paid – you get the gist. To analyze the data, you need to get the data to your data warehouse, but first you need to ensure the data you get is real-time and fresh. Can you load the data from all the tenants in your database fast, considering there might be huge terabytes of it? Can you change data capture (CDC) incremental data in real-time, and merge it with existing data? Most of all, do you have a way to identify each client’s data easily? Don’t forget there may be security concerns too, it is sensitive information after all. But let’s start at the beginning with what constitutes a multi-tenant database. Learn about SQL Server CDC
A Look at Software Multi-Tenancy
Software multi-tenancy also known as multi-tenant software architecture is where a single instance of a software application (including database and hardware) is used by multiple customers or tenants. A tenant could be an individual user, or it could be an organization with multiple users who have access and permission to use the application. In a multi-tenant architecture, a tenant’s data is invisible and isolated from data of other tenants, to allow for privacy and to enhance data security. In other words, tenants are physically integrated but logically isolated. SaaS (Software as a Service) applications like Salesforce, Dropbox, Hubspot or other Cloud SaaS applications largely use multitenant architecture where a single instance of the application can run on one server and serve multiple tenants. Multi-tenancy software can share displays, rules, users, and database schema. Users have the option to customize rules and database schemas to a degree. Oracle CDC: 13 Things to Know
It is important to note that with SaaS software the license is not sold to a client, but instead he pays a subscription fee at periodic intervals (rents the software) making him a tenant. In return for the rental fee, the tenant can use and access your application, and have his data stored in the SaaS database. Multi-tenant data architecture is used in SaaS software, multi-tenant databases, user interfaces and applications like forums, training software, help portals etc. Multi-tenancy is generally in reference to SaaS applications, though not all SaaS software are multi-tenant and not all multi-tenant software are based on the SaaS model. Read Case Study – Delivering data from Optimov’s SQL Server Multi-tenant DB to Snowflake.
Now with your SaaS multi-tenant software, you probably also have a multi-tenant database to store details of clients. The database tenancy models are in context to how data is stored in the system. What to look for in a Real-Time Data Replication Tool
- Single-tenant Database stores data of only one client SQL Server CDC To Kafka (Unbelievably Easy New Connector)
- Multi-tenant Database stores data of multiple individual tenants with data privacy mechanisms in place.
- Hybrid Tenancy Databases include combinations of single and multi-tenant databases.
Benefits of Multi-Tenant Database Architecture
Multi-tenant Database Architecture costs less than Single Tenant Architecture
Since resources are shared between users in the multi-tenancy model, there is a lower cost per user.
Onboarding new clients is faster with Multi-tenant Database Architecture
Getting new clients on board is much faster since the environment remains the same for every customer. Scalability is thus much higher.
Multi-tenant Database Architecture allows for centralized maintenance by the provider
Updates to the multi-tenant software or the multi-tenant database will reach all customers, so maintenance can be done by the software provider and not the customers. This will lower the risk of issues caused by different software versions run by different customers. There will be consistency in performance and savings of time. Postgres CDC: 6 Easy Methods
Limitations of Multi-Tenant Database Architecture
Multi-tenant Database Architecture has vulnerabilities
The more users, the more access points, which can magnify the risk of a security breach. You must pay attention to authorization of end user access. You will need to use applications that help in managing authentication, authorization, and identities.
Multi-tenant Database Architecture can get complex
Since the application or database serves multiple customers, there is an additional degree of complexity involved in the database or code maintenance.
Multi-tenant Database Architecture needs to have robust backup
With multiple tenants, backup and restoration can be more complex. The provider needs to have robust restoration mechanisms in place.
Multi-tenant Database Architecture is restricted in terms of customization
A multi-tenant architecture has little leeway for customization and with fewer customizations, quality might get compromised.
Multi-tenant Database Architecture can produce issues that can have a global impact
A technical glitch on part of the provider can affect all users in the multi-tenant environment. Issues could be in reference to system upgrades, downtime, and other processes in the system.
Multitenant Database Architecture may need further knowledge inputs
Having multiple tenants as part of your application or database, might mean creation of additional logic for data filtering, separation of tenants, tenant identification for isolating client-wise data and maintaining security. You will probably need a team of experts on hand to take care of potential issues.
Multi-Tenant Databases and Their Designs
A multi-tenant database is a database which holds the data of multiple tenants. A multi-tenant database could be a single database with shared schema or a single database with separate schema. Multi-tenant databases are used by ISVs (multi-tenancy is used by Cloud SaaS applications like Office 365, Zendesk, Boho, Slack and other on-demand apps). Cloud providers also offer multi-tenancy. Listed below are some multi-tenant database designs.
Single Database Shared Schema
Here all the tenants are housed in one database and a tenant ID is used to reference the tenant with the rows it owns. All the tenants have a shared schema. The shared schema strategy has lower backup and hardware costs because you can serve more tenants or clients using just one database. Maintenance and support requirements are also minimized. The single database schema is easier to maintain, and a schema update needs to be rolled out only once, since it is applicable to all databases. One drawback, however, is that tenant isolation is not present, since one tenant’s data is grouped with all the others. The tenant ID is the only differentiator. SQL Server CDC To Kafka (Unbelievably Easy New Connector)
Single Database with Separate Schema
In this pattern a single database holds all the tenant data but has separate schemas for all tenants. Here there are separate tables for each tenant where each table has a tenant-specific schema. Though the tenant data can be isolated more, and schemas can be optimized, it will require a lot more maintenance as the number of tenants grows, and more database objects are created. Schema updates will also be increasingly complex since they will need to be rolled out to multiple tenants.
Multi-tenancy with Database per Client
In this multi-tenancy pattern, each tenant has its own database. Every time the system adds a new tenant, a new database is created for the tenant. This multi-tenancy pattern has the highest level of tenant isolation and can support an architecture having a shared server or several isolated servers. It is also easy to restore, relocate or delete a tenant’s data. The drawback is that there may be more servers to manage and keep secure. There will also be larger numbers of database objects to manage as the number of tenants grows. Possibly new schemas may need to be created too.
Multiple Databases, Multiple Tenants Per Database, Shared Schema
This multi-tenancy pattern is an amalgamation of ‘Single Database, Shared Schema’, and ‘Database per Tenant’. Here a group of databases would be available. Tenants would share a database and schema but would be distributed across multiple databases. If the single database, single schema is followed, some tenant isolation may be possible. Higher tenant density would lower costs and lower tenant density would enhance performance. Maintenance would be increasingly required.
Change Data Capture from Multi-Tenant Databases – Some Issues
implementing Change Data Capture on a multi-tenant database can be difficult and may not deliver satisfactory results. This is because not all databases may be enabled for multi-tenancy, and not all replication tools can deliver CDC satisfactorily from multi-tenant databases.
Today the term Change Data Capture has evolved to mean real-time CDC that uses database logs, event bus or message queues in conjunction with a CDC connector or platform. The CDC tool waits for data change events in source tables in the form of inserts, updates, or deletes, and then delivers them to the target. The CDC process keeps data on target updated in sync with the source within seconds of any change that is made. Snowflake CDC With Streams and a Better CDC Method
There are ETL and replication tools galore that claim to provide real-time Change Data Capture. Debezium is an open-source tool that provides connectors to mainstream source databases and uses Apache Kafka as an event bus. Debezium CDC requires a lot of coding effort and expertise and has scalability issues when data volumes get larger. As far as multi-tenant databases are concerned, CDC using Debezium may require multiple connectors (one for each tenant) against the same server instance, which will lead to extra load on the server.
AWS DMS is another CDC tool for the AWS environment which can provide CDC from multi-tenant databases if needed, but the going is not easy. You will need a lot of connections for the multi-tenant database and the infrastructure costs can really pile up. Also, AWS DMS has limited scalability for large data volumes. AWS DMS Limitations
Other third Party ETL tools such as Fivetran and Matillion do not provide CDC for multi-tenant databases out-of-the-box, as far as we know. A large amount of coding and tinkering may be needed to deliver multi-tenant database Change Data Capture. To sum up, these are some common issues that crop up with CDC from multi-tenant databases. Learn about Snowflake CDC
- Loading and merging large volumes of data from multi-tenant databases can be tricky when near real-time CDC replication is required. SQL Server to Snowflake in 4 Easy Steps (No Coding)
- High data volumes can cause bottlenecks and slowing down of processes and deadlocked transactions. SQL Server to Postgres – A Step-by-Step Migration Journey
- Cost of the implementation can increase if scaling up is required to handle excessive volumes, since you will need additional computing resources, memory, and disk space. What to look for in a Real-Time Data Replication Tool
- Occasionally real-time event-based CDC may need a snapshot of the entire table. If there is some downtime in the CDC pipeline, records can be missed, which means the system will have to back-fill data and the whole table will need to be re-read. This can slow down systems.
- Not many CDC tools can handle schema evolution and depending on the number of tenant databases, number of tables in each database, a large amount of coding and engineering effort may be required to keep in sync. Oracle CDC: 13 Things to Know
BryteFlow as a CDC Tool for Multi-Tenant Databases
Quite a few databases support multi-tenancy, including SQL Server, MySQL and PostgreSQL databases etc. Oracle even has an Oracle Multitenant offering as part of Oracle Database 19c. Though BryteFlow supports Oracle for multi-tenant database change data capture, it is especially useful for CDC from SQL Server databases.
The Case for Change Data Capture from Multi-tenant databases
Enterprise customers and ISVs have thousands of SQL Server DBs with the same database design and schema, from which they need to extract and aggregate data on destination for real-time analytics. This is not an easy task since not many CDC or ETL tools can capture changes from multi-tenant databases in real-time. There is almost always manual coding involved, an expensive proposition, not to mention dealing with subsequent glitches. BryteFlow however, offers CDC for multi-tenant databases out-of-the-box, and customers can easily get the changed data in near real-time from their multi-tenant database source into their single data warehouse, without any coding. Postgres CDC (6 Easy Methods to Capture Data Changes)
About the BryteFlow Replication Tool
BryteFlow Ingest is a completely no-code CDC replication tool that can load terabytes of enterprise data in real-time from multi-tenant SQL Server databases using either SQL Change Data Capture or SQL Change Tracking. From CDC options you can select from log-based CDC, or from timestamps to identify changed records. BryteFlow supports all versions and SQL Server editions, works even when Primary Keys are not available – all this with the highest performance for extraction and loading. BryteFlow creates tables and schema automatically on target, besides automating DDL. It delivers complete, ready-for-analytics data that can be queried immediately, with BI tools of your choice. BryteFlow for SQL Server
BryteFlow Ingest excels in moving large enterprise-scale data from multi-tenant SQL Server databases to Snowflake, Databricks and other Cloud data warehouse and repositories in real-time. It provides scalable, low latency replication of updates from well over thousands of customer databases (a continually growing list). It enables databases to be tagged with Tenant Identifier or Database ID from where the record originated, so it is simple to use this data. SQL Server to Databricks Migration
BryteFlow automatically merges tables across various tenants and provides configuration for identifying the source tenant per record. It handles schema evolution automatically, and scales effortlessly with low TCO. Compared to SaaS based replication tools like Matillion and Fivetran, compute costs are much lower. Other replication tools need high compute resources per tenant for this solution, and hence scaling up will involve costs that rapidly scale up as well. It is important to note that other tools do not provide the complete automation (a lot of manual coding is required) that BryteFlow provides for CDC from multi-tenant SQL Server databases. SQL Server to Snowflake in 4 Easy Steps (No Coding)
BryteFlow Highlights for Change Data Capture
BryteFlow XL Ingest supports loading of high volumes of enterprise data with parallel, multi-thread loading, partitioning and compression. This is followed by real-time CDC of incremental data by BryteFlow Ingest.
- Deltas (upserts, inserts and deletes) are merged automatically with data on destination. Oracle CDC (Change Data Capture): 13 Things to Know
- It creates the schemas and tables automatically on the target with the optimum data types and implements best practices for the target. How BryteFlow Works
- Every process is automated, including data extraction, data merges, CDC, data mapping, DDL, masking and SCD Type-2 data. Postgres CDC (6 Easy Methods to Capture Data Changes)
- It provides data type conversions out-of-the box (Parquet-snappy, ORC etc.) so data is ready-to-use on destination. Snowflake CDC with Streams
- BryteFlow has very high throughput – 1,000,000 rows in 30 seconds (6x faster than GoldenGate)
- It automates data reconciliation and checks for missing or incomplete data with BryteFlow TruData.
- BryteFlow has a point and click user-friendly UI any business user can use. What to look for in a Real-Time Data Replication Tool
- In case of network failure, an automated network catch-up feature ensures the process resumes automatically from where it left off, when normal conditions are restored.
BryteFlow for CDC from Multi-Tenant SQL Server Databases
- BryteFlow supports Change Data Capture from SQL Server multi-tenant databases in multiple ways – using log-based CDC, CDC with triggers and SQL Server Change Tracking. SQL Server CDC To Kafka (Unbelievably Easy New Connector)
- BryteFlow excels in moving large enterprise-scale data from SQL Server multi-tenant databases to Snowflake, Databricks, Azure Synapse, Redshift and other data warehouses in real-time. It enables databases to be tagged with Tenant Identifier or Database ID from where the record originated, so it is simple to use this data. Connect SQL Server to Databricks
- It delivers ready-for-analytics data in near real-time from SQL sources that can be queried immediately by BI tools. SQL Server to Snowflake in 4 Easy Steps
- BryteFlow supports SQL Server Always ON configuration.
- BryteFlow SQL Server replication works whether Primary Keys are available or not.
- BryteFlow provides scalable, low latency replication of updates from well over thousands of SQL Server customer databases to the Cloud. SQL Server to Postgres – A Step-by-Step Migration Journey
- It offers enterprise grade SQL Server replication and watertight security for on-premise and on Cloud installations or both, using a hybrid approach.
- It supports all SQL Server versions and editions.
Brightly Case Study
How BryteFlow enabled Brightly to CDC data from their SQL Server Multi-Tenant Database of over 3000 tenants to Snowflake on AWS with high throughput and low latency
The Client
Brightly is a Siemens group company that has a complete suite of user-friendly SaaS software – including CMMS, EAM, Strategic Asset Management, IoT Remote Monitoring, Sustainability and Community Engagement. Brightly stores the information of over 3000 customer tenants in 3000+ databases (every tenant has their own SQL Server DB copy) in the multi-tenant SQL Server database. The DB schema and designs are identical, the only differentiator being the tenant. The tenants constantly have new data updates that needed to be captured for Brightly to run real-time analytics on their data. Also read the Optimove Case Study
The Issue
Brightly needed to integrate data from all 3000+ databases into one DB for analytics, in near real-time on Snowflake. They had approached BryteFlow after an earlier implementation using AWS DMS had resulted in delays and failed to deliver data at the frequency they needed. They needed to onboard new customers and manage their data, as well as manage the increasing data volumes, which their earlier implementation with AWS DMS could not handle.
The Solution
BryteFlow helped Brightly set up an implementation on AWS to seamlessly extract data from over 3000 SQL Server databases into their Snowflake data warehouse. This is a highly scalable, low latency solution. BryteFlow captures incremental change data from all the SQL source databases and delivers real-time incremental changes combined into one database, with individual tenant ids to differentiate between tenants. The data from all the tenant databases is merged on Snowflake on AWS in real-time, so the Brightly team can access and analyze the data immediately with their tools of choice. The entire deployment took just a couple of weeks.
The Result
Brightly can now access all the clients’ data in real-time on Snowflake. They run analytics, reporting and can create a variety of dashboards and operational reports easily with the data.
A Glowing Testimonial
Here’s what Jan Jonak, Senior Director of Data Engineering, Brightly Software had to say, “BryteFlow software enabled us to simplify a very complex data integration problem and provide scalable, low latency replication of updates from well over 3000 customer databases (a continually growing list). This was deployed to merge data from single tenant databases on high availability SQL Server clusters, directly into the Snowflake-based Data Cloud, which enabled a variety of advanced analytics, dashboards and operational reports applications. The resulting data integration solution is a strategic enabler for our company, while being lightweight and easy to manage. We greatly appreciate BryteFlow’s collaborative approach to the implementation and how the team supported us throughout the process – from pilot to staging to production. They helped us create phases executed over time to avoid disruption to downstream application users.”
Here are some screenshots from Brightly’s journey to illustrate how easy it is to implement CDC with BryteFlow from a multi-tenant SQL database.
First you need to ensure that all prerequisites have been met and all security and firewalls have been opened between all the components.
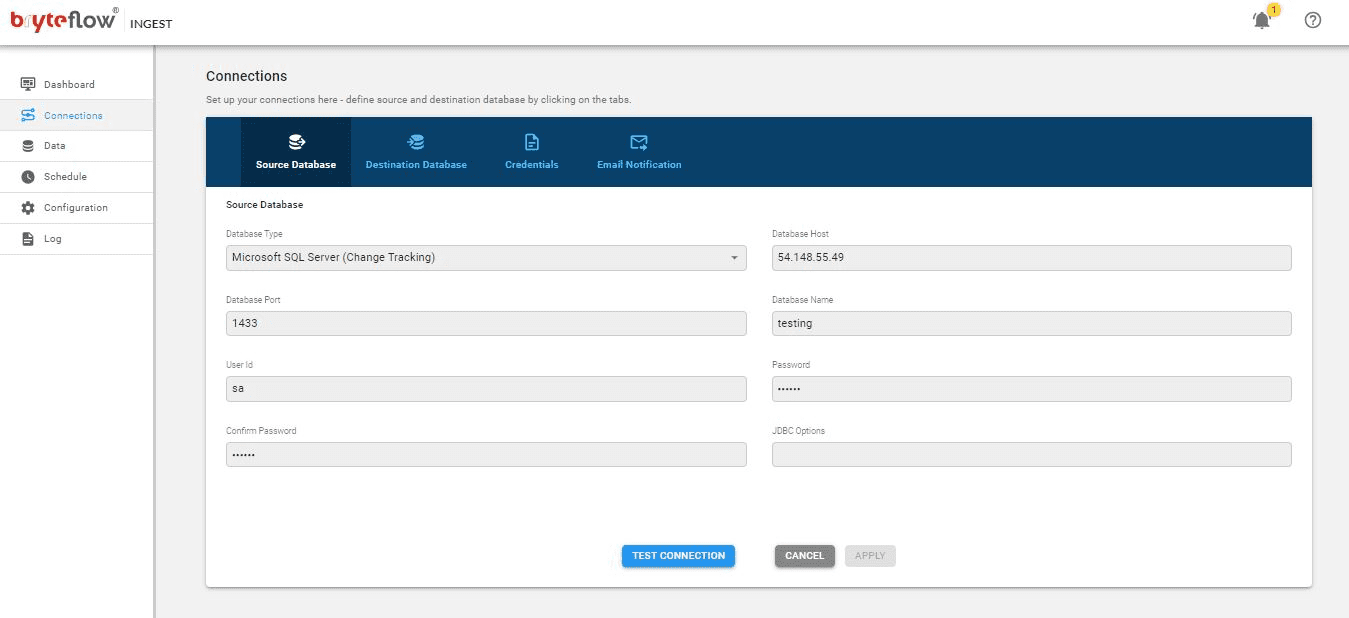
Step 1: Once the BryteFlow Ingest software is installed, select “Connections” in the left panel and select SQL Server as the “Source Database” from the options coming up. Put in the source database details and test the connection by selecting the “Test Connection” button.
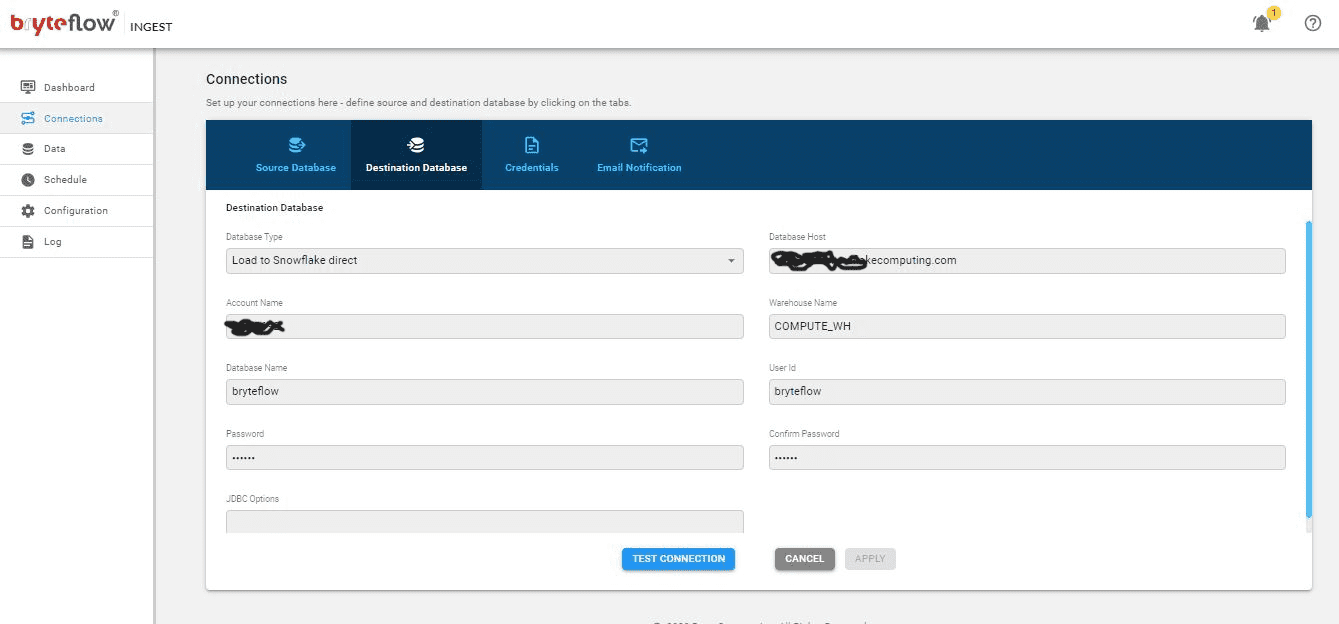
Step 2: Set up destination as Snowflake after selecting the “Destination Database” tab. Fill in the database details and test the connection by selecting the “Test Connection” button.
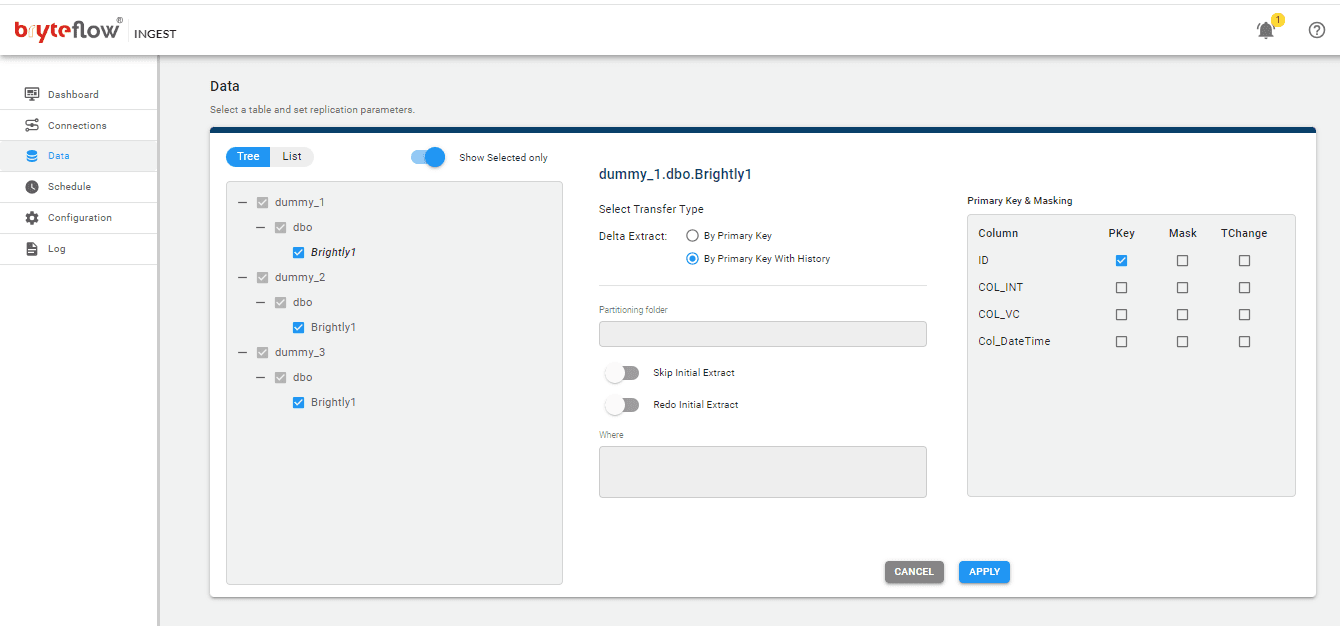
Set up the source table(s) to be replicated, select the primary key and the transfer type for each table. ‘By Primary key with History’ automatically keeps SCD Type2 history on Snowflake. ‘By Primary Key’ transfer type keeps a mirror of the source, without history. Additionally, you can filter out the unwanted data using the “Where” option and Byteflow Ingest also gives you the option to “mask” the sensitive data in the column.
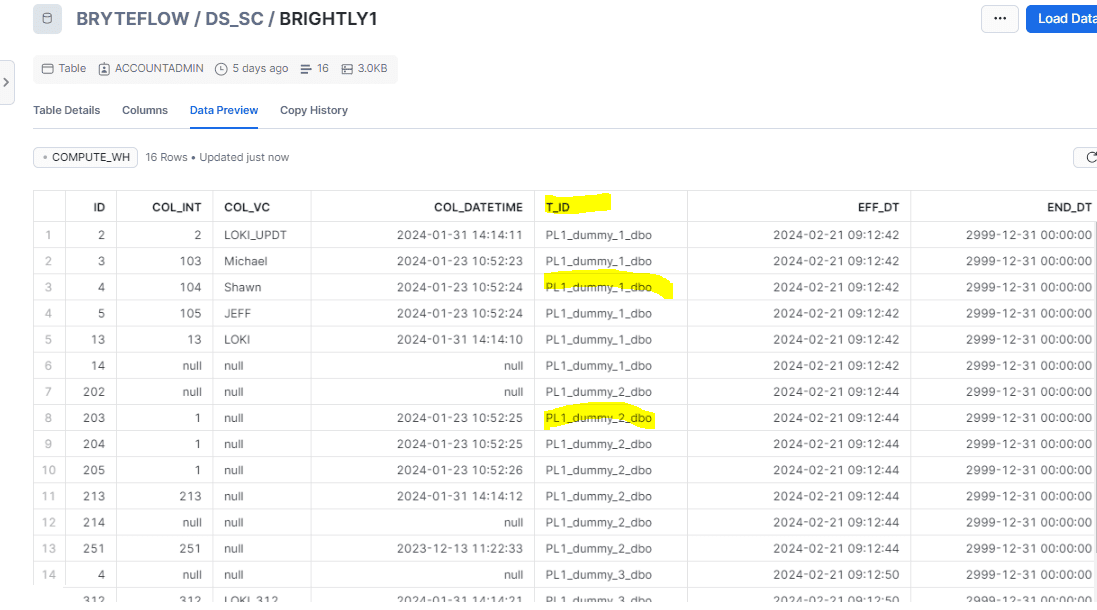
After the process of replication, there is one final consolidated table on Snowflake with the Tenant ID to reference the various DBs.
If you would like to learn about another BryteFlow implementation of Change Data Capture from a multi-tenant database, here’s the Optimove Case Study
Conclusion
In this blog we have examined the concept of multi-tenancy in databases, and how Change Data Capture from multi-tenant databases can pose issues. We have also looked at the pros and cons of multi-tenant database architecture and how BryteFlow as a CDC tool can perform CDC from multi-tenant SQL databases out-of-the-box, automatically and seamlessly.
Interested in getting a Demo of BryteFlow CDC? Contact us



