
In this blog we discuss Postgres Data replication, its advantages, Postgres replication types and models with their advantages and limitations. We also demo a completely automated step-by-step Postgres replication method, using a third-party CDC replication tool – our very own BryteFlow. Postgres CDC (6 Easy Methods)
Quick Links
- What is Postgres DB?
- What Is Database Replication and why is it needed?
- How does PostgreSQL Replication work?
- Advantages of PostgreSQL Replication
- PostgreSQL Database Replication Models
- PostgreSQL Replication Modes
- Different Types of Postgres Database Replication
- PostgreSQL Logical Replication
- PostgeSQL Streaming Replication or Physical Replication
- Postgres Logical Replication vs Streaming Replication: A Comparison
- PostgreSQL Replication with BryteFlow, a Third-Party Tool
What is Postgres DB?
PostgreSQL or Postgres as it is popularly known, is a free, open-source Object-Relational Database Management System (ORDBMS) that is known for its versatility, adaptability, and extensibility. The Postgres DB is an ACID (Atomicity, Consistency, Isolation, Durability) compliant database, which makes it suitable for reliable database transactions. Postgres DB can be used as a reliable transactional database and as a data warehouse for analytics, and is also very popular in the AI, ML and data science community. The Postgres DB has a host of innovative features that enable the platform to manage, store and analyze huge volumes of data – both structured and unstructured. Postgres DB seamlessly integrates standard SQL for relational data queries with JSON for non-relational data handling. Data Integration on Postgres
Postgres can be run on a number of platforms – On-premise and Cloud
Many of the Fortune 500 companies as well as others run their Web applications, solutions, and products on PostgreSQL. It also helps that Postgres can be run across various operating systems including Linux, macOS, Windows, BSD, and Solaris. It can also be used on Docker containers or Kubernetes. Postgres DB can be implemented on Cloud platforms such as AWS, Azure, and GCP. Postgres to Snowflake : 2 Easy Methods of Migration
Postgres is remarkably extensible and supports development of complex database applications
PostgreSQL truly stands out due to its remarkable extensibility. It allows Postgres extensions or modules to be added to the Postgres DB to extend its functionality. Some commonly used Postgres extensions include pgAdmin for database administration, PostGIS for geographical data, and PL/Python for writing database functions in Python. Extensions are mostly community-driven and open-source and help developers to customize their applications for specific requirements. Extensions enable the addition of features, data types, operators, and functions that are not available in the core Postgres system. Information about these is stored in System Catalogs. This is where Postgres differs from other RDBMS, in that it stores so much information in the catalogs, not just tables and columns, but also information about data types, functions, access methods etc. Postgres Replication with BryteFlow
Postgres structure and the support of an active developer community
PostgreSQL is not a distributed database but a single-node relational one. All data is served from one node, without it being distributed over multiple nodes or automatic sharding. PostgreSQL organizes data conventionally in tables and adheres to a monolithic architecture, in which integrated components collaborate seamlessly. Its open-source core is built upon C programming and is supported by a vibrant developer community that contributes to a stream of ongoing enhancements. SQL Server to Postgres – A Step-by-Step Migration Journey
What is Database Replication and why is it needed?
Database replication is the method by which the same data is stored in multiple locations, to make data more available, accessible and to enhance system reliability and resilience. Data replication has several uses such as:
Data Replication for Disaster Recovery and Backups
The replicated data serves as an accurate backup should some natural disaster, hardware failure or data breach occur.
Data Replication for faster data access
For large organizations present in a lot of locations, it makes sense to have a replica closer to the location in the interests of lower latency, faster access and balancing the load across the network. Database Replication Made Easy – 6 Powerful Tools
Data Replication for optimizing server performance
When data replicas are distributed across several servers, users can access data faster. Also, with all read operations being carried out on replicas, the processing power of the primary server is freed up for compute-intensive write operations. How to Select the Right Data Replication Software
Data Replication for Data Analytics and Data Science
Organizations that need to analyze their data need to replicate their data from multiple sources into data warehouses and Cloud platforms to be integrated and subjected to business intelligence (BI) tools for analytics, or to be used to create ML models for AI, ML, and data science objectives. Postgres to Snowflake : 2 Easy Methods of Migration
How does PostgreSQL Replication work?
Postgres database replication involves the copying of data from a Primary server to multiple servers called Replicas. The Primary server also called a Master server, allows read and write operations while the Replica servers also called Replicas, serve read-only transactions only. Postgres provides two methods of replication – Streaming (Physical) replication and Logical replication.
In PostgreSQL replication, transactional consistency is maintained by applying changes in the same order as they occur on the primary server. This replication model ensures that all writes are directed to the primary node, which then broadcasts the changes to the replicas or secondary nodes.
A database replica is essentially a copy of your database, that can be used for various purposes such as read replicas, hot standbys, or for testing and performance analysis. Replication involves designating one node as primary and others as replicas, with Write Ahead Logs (WAL) that record all changes to ensure synchronicity. Replicas enhance disaster resilience by storing a complete copy in separate locations, allowing for failover during outages, albeit PostgreSQL requires manual failover setup. Replicas also distribute workload, mitigating performance issues during heavy traffic. They offer global performance improvements for users regardless of location and are useful for testing environments, facilitating benchmarking and query tuning before implementing changes in production. SingleStore DB – Real-Time Analytics Made Easy
Advantages of PostgreSQL Replication
Here are several key advantages of employing PostgreSQL Replication:
- PostgreSQL Replication for Scalability
Horizontal scalability is achieved by expanding the number of replicas, thus accommodating higher data volumes and user demand. - PostgreSQL Replication enhances Fault Tolerance
In the event of primary server failure, the standby server, which mirrors the primary server’s data, can seamlessly take over, ensuring continuous operation. This setup, where the replica server acts as a standby server, can also support regular maintenance tasks on the primary server. Database Replication Made Easy – 6 Powerful Tools - PostgreSQL Replication for Analytics Offloading
Analytical queries are redirected to replicas, relieving the primary database of resource strain, and prioritizing transactional workloads. - PostgreSQL Replication allows for Parallel System Testing
PostgreSQL replication enables parallel testing of new systems by providing a copy of the production database for evaluation before deployment. This ensures smooth transitions and validates the functionality of the new system. - PostgreSQL Replication for High Availability
Through streaming replication, PostgreSQL ensures continuous database accessibility, minimizing downtime, and ensuring business continuity. Replicating data to standby servers guarantees prompt failover in case of primary server issues, thus enhancing system reliability. - PostgreSQL Replication to Migrate Data
PostgreSQL replication enables seamless data migration, whether it involves upgrading database server hardware or deploying the system for a new customer. Postgres CDC (6 Easy Methods) - PostgreSQL Replication for Disaster Recovery
PostgreSQL replication serves as a crucial component of disaster recovery plans, ensuring swift data recovery and minimal operational downtime in the face of catastrophes, data breaches, and hardware failures, thus guarding against permanent data loss. It facilitates the distribution of data across various geographical locations, enhancing both – data latency and disaster recovery capabilities. - PostgreSQL Replication for improved online transactional processing (OLTP) performance
By offloading reporting query load from the OLTP system to replica servers, PostgreSQL replication enhances both transaction processing time and query performance, optimizing system efficiency. - PostgreSQL Replication for Real-time Data Warehousing
Posgres replication facilitates real-time data integration into data warehouses, enabling timely insights and decision-making without impacting the performance of the primary database, thus seamlessly serving both operational and analytical needs. SingleStore DB – Real-Time Analytics Made Easy - PostgreSQL Replication for Load Balancing
Streaming replication allows for the distribution of read queries across multiple servers, allowing for maximum hardware utilization and improving application response times, thereby creating a more efficient and scalable system architecture.
PostgreSQL Database Replication Models
Scalability refers to enhancing a database’s capacity to store and process more data by adding additional hardware or resources to existing nodes. This can be achieved through horizontal and vertical scalability. PostgreSQL replication exemplifies horizontal scalability, which is typically more challenging to implement than vertical scalability. Horizontal scalability is primarily achieved through single-master replication (SMR) and multi-master replication (MMR).
- Single-Master Replication (SMR): SMR involves replicating changes to table rows from a designated master database server to one or more replica servers. Replica databases are restricted from accepting any changes except those originating from the master server. Even if changes are made on the replica, they are not replicated back to the master server. SMR ensures that data modifications occur only on a single node and are then propagated to one or more nodes. This unidirectional replication flow, from the primary to the replica database simplifies configuration and management and reduces the likelihood of conflicts. How to Select the Right Data Replication Software
- Multi-Master Replication (MMR): MMR is about replicating changes to table rows from multiple designated master databases to their corresponding tables in every other master database. MMR allows for more than one node to function as a primary node, allowing for modification in distributed data. Conflict resolution mechanisms are often employed to address issues such as duplicate primary keys or concurrent modifications done across multiple primary databases.
PostgreSQL Replication Modes
PostgreSQL replication primarily operates in two modes: Synchronous and Asynchronous. Synchronous replication involves writing data simultaneously to both the primary and secondary servers, while Asynchronous replication first writes data to the host, before copying it to the secondary server. When configuring replication settings, users should weigh the trade-offs between safety and performance associated with each mode.
- Synchronous Mode of Replication: Transactions on the master database are only considered complete when changes have been replicated to all replicas. This method minimizes the risk of data loss but increases response time for write transactions due to the need to wait for confirmations. Read-only transactions are unaffected. Synchronous replication is typically employed in high-demand, failover-sensitive environments.
- Asynchronous Mode of Replication: In this mode, transactions on the master server are marked as complete before being replicated to replicas, resulting in a replication lag. While there is a risk of potential data loss, the delay in committing changes is generally small if the standby server can handle the load. Asynchronous replication is the default mode and offers lower overhead, making it suitable for most scenarios, although failover from primary to secondary may take longer compared to synchronous replication.
Different Types of Postgres Data Replication
In PostgreSQL, there are two basic types of replications: Streaming Replication (Physical Replication) that replicates a database cluster collectively, and Logical Replication that replicates in units of tables and databases. Each PostgreSQL database replication type has its own advantages and drawbacks. Here we will discuss three types of PostgreSQL replication namely:
- Postgres Logical Replication: Logical replication involves transmitting both data and changes from a master database to replicas, followed by storing this data in Amazon S3 or Azure Blob for backup purposes. Aurora Postgres and How to Set Up Logical Replication
- Postgres Streaming Replication or Physical Replication: Postgres Streaming replication duplicates data between physical machines – from the primary node to secondary nodes before storing it in Amazon S3 or Azure Blob for backup storage.
- Postgres Replication with BryteFlow: In the case of BryteFlow, a third-party tool, data is replicated from the primary node to the secondary node in real-time, and subsequently, this data is copied to Amazon S3 or Azure Blob storage for backup needs, using separate BryteFlow Ingest pipelines as required. How to Select the Right Data Replication Software
Postgres Logical Replication
Logical replication was introduced in PostgreSQL v10.0. It is a replication process in Postgres where data objects and their changes are replicated based on their replication identity, typically a Primary Key. Logical replication operates at the database cluster level, enabling fine-grained control over replicated data and information security. It employs a Publish and Subscribe pattern, where subscribers pull data from their subscribed publications and afterwards may re-publish the data to allow for Cascading replication and other complex configurations. Please note, in a Postgres publisher node, a Publication is essentially a set of changes from a table or a group of tables. Meanwhile a Subscription is created in a subscriber node, which can subscribe to one or more publications. How To Make PostgreSQL CDC to Kafka Easy (2 Methods)
The Postgres Logical Replication Process
The process of a table’s logical replication begins with copying a snapshot of the data existing on the Publisher database to a subscriber. This is called the table synchronization phase. After that, all changes that happen on the Publisher are delivered to the subscriber in real-time. The subscriber applies the changes in the same commit sequence, so transactional integrity is maintained for publications delivered to a single subscription. The PostgreSQL Logical Replication process involves ‘walsender’ and ‘apply’ processes, where Walsender decodes WAL changes and applies filters based on publication specifications, to transfer data to apply workers who apply the changes on the subscriber. Logical replication is also called Transactional Replication since it guarantees transactional integrity. Aurora Postgres and How to Set Up Logical Replication
Advantages of Postgres Logical Replication
- PostgreSQL Logical replication enables real-time delivery of data
With Postgres logical replication, you can send incremental data changes as they occur in a database or subset of the database to various subscribers in real-time. Database Replication Made Easy – 6 Powerful Tools - PostgreSQL Logical Replication reduces server load
In comparison to trigger-based solutions, logical replication imposes a minimal server load while offering storage flexibility by replicating only filtered changes. Furthermore, it can replicate data from basic partitioned tables. Notably, Postgres logical replication supports data transformation during setup and enables parallel streaming across publishers.
- PostgreSQL Logical Replication reduces downtime for upgrades and migrations
Postgres logical replication offers cross-version support, facilitating replication between different versions of PostgreSQL reducing downtime for migrations and upgrades. - PostgreSQL Logical Replication makes data sharing easy
Postgres logical replication includes event-based filtering, and publications can accommodate multiple subscriptions, simplifying data sharing across diverse networks. - PostgreSQL Logical Replication can replicate specific data
Logical replication has the capability to replicate selected data. We can filter tables, columns, and rows that are to be replicated and deliver them to different databases. - PostgreSQL Logical Replication allows destination server to be used for writes
It allows users to designate a destination server for write operations, enabling developers to implement different indexes and security definitions. - PostgreSQL Logical Replication saves on network bandwidth
With PostgreSQL Logical Replication there is no need to send vacuum data and index changes, which makes it bandwidth-efficient.
Limitations of Logical Replication in PostgreSQL
- A Publication can contain only tables. The following cannot be replicated: Views, Materialized Views, Partition Root Tables, or Foreign Tables, Large Objects and Sequences.
- Postgres logical replication is restricted to DML operations only, with no support for DDL or truncate. Additionally, the schema must be predefined, and mutual bidirectional replication is not supported.
- Failure to promptly address conflicts can result in a frozen replication slot and accumulation of Write-Ahead Logs (WALs) on the publisher node leading to valuable disk space being used up.
Where is Postgres Logical Replication used?
PostgreSQL Logical Replication use cases include:
- Delivering incremental data changes as they occur in a database or subset of the database to various subscribers.
- Providing access to multiple user groups for replicated data and even specific datasets.
- Aggregating multiple databases into a centralized one, often for analytical purposes.
- Replicating between PostgreSQL instances on diverse platforms, such as Linux to Windows.
- Triggering changes as they are received on the subscriber.
- Enabling replication across different versions of PostgreSQL.
- Sharing a data subset among multiple databases.
PostgeSQL Streaming Replication or Physical Replication
PostgreSQL DB has a Streaming replication feature, which allows for movement of updated data from the primary server to the replica server in real-time, keeping the databases on both servers in sync. This type of replication is useful for Failover, enabling the replica to function as a standby server in case the primary server fails. It also helps in load balancing for read-only SQL processing since the data can be spread over multiple servers.
PostgreSQL streaming replication involves sending complete Write-Ahead Logging (WAL) files or streaming changes from the Primary server directly to the replica, making it suitable for creating a hot standby or read replica for failover purposes. Postgres Streaming replication involves copying the entire database from the primary server to another physical machine and is typically achieved through methods like file-based log shipping or streaming replication.
A word about the Write-Ahead Log or WAL
PostgreSQL saves the data updates of the primary server in the form of a transaction log known as write-ahead log, or WAL, to prepare for a crash or to ensure data rollback. Streaming replication functions by shipping the WAL to the standby server in real time and applying it.
WAL’s basic premise is that changes to data files (containing tables and indexes) must be written only after the logging of changes, i.e. when WAL records describing the changes have been flushed to permanent storage. A big advantage here is that with every transaction commit, there is no need to flush data pages to disk, should a crash happen, the files can be re-applied using the log. Changes that are yet to be applied to the data can be executed using WAL records. This roll-forward recovery is also called REDO.
Two methods of Postgres Streaming Replication
There are two methods of PostgreSQL streaming replication:
File-based log shipping
File-based log shipping, which transfers WAL records one file at a time. File-based log shipping waits for the Write-Ahead-Log (WAL) file to reach maximum capacity before shipping, which could lead to potential data loss due to the lag.
Record-based log shipping
Record-based log shipping transfers individual WAL records to the replica as they occur, reducing the time window for data loss, but requiring a more complex setup and addressing potential replication issues if the streaming connection breaks. These replicas are useful for offsite backups and read replicas, ensuring changes are replicated at the disk level to maintain consistency. A WAL receiver on the standby server connects to a primary server via TCP/IP, while a WAL sender on the primary server sends WAL records in real-time. Enabling WAL archiving is optional but crucial for a robust setup, preventing the main server from recycling old WAL files before they’re applied to the standby server. Failure to do so may require recreating the replica from scratch.
Advantages of Streaming Replication in PostgreSQL
- In the event of a shutdown on the primary server, it will wait until updated records are transmitted to the replica before powering down, ensuring synchronization.
- One of the foremost benefits of employing streaming replication is its resilience against data loss, as data is only at risk if both the primary and receiving servers fail simultaneously. This ensures a high level of data integrity.
- Setting up log-shipping via streaming replication does not disrupt ongoing operations on the primary database.
- Users can link multiple standby servers to the primary, with logs streamed concurrently to each connected standby. Even if one replica experiences delays or disconnection, streaming continues unaffected to other replicas.
Limitations of Streaming Replication in PostgreSQL
- Sensitive data may face the risk of unauthorized extraction if user authentication credentials have not been configured for replica servers. To enable real-time updates between the master and the replica, users must switch from the default asynchronous replication process to synchronous replication.
- In asynchronous streaming replication, older WAL files that haven’t been copied to the replica may be deleted if changes are made to the master. To prevent loss of critical files, users can increase the value of wal_keep_segments.
- Streaming replication does not transfer data across different versions or architectures, alter information on standby servers, or provide fine-grained replication control.
Where is Postgres Streaming Replication used?
Streaming replication is commonly employed by engineers for various purposes, including:
- Offloading resource-intensive queries to reduce the load on the primary system.
- Distributing database workloads across multiple machines, particularly for read-only operations.
- Implementing a high-availability solution with minimal replication delay.
- Establishing a backup for the primary database to safeguard against server failures or data loss.
Postgres Logical Replication vs Streaming Replication: A Comparison
| Feature | Logical Replication | Streaming Replication |
| Data Pattern | Data sent from Publisher to Subscriber | Data sent from Master Server to Replica Server |
| Transactional Replication Possible | Yes | No |
| Replication Interruption | A conflict will halt replication | Asynchronous replication – there may be a delay between moving data between the master and replica; Synchronous – Data loss only happens if all connected servers crash at the same time |
| Replication between different platforms or PostgreSQL versions | Yes | No |
| Security | Secure, since access to data is limited to subscribers only | Access credentials need to be set up to keep data secure |
| Replication Volume | Suitable for granular replication | Suitable for high volume replication |
| Main Objective | Aggregating data from multiple systems into one database for Analytics, ML models etc. | Creating a backup database for situations like Disaster Recovery, data breaches etc. |
PostgreSQL Replication with BryteFlow, a Third-Party Tool
BryteFlow Ingest is our flagship CDC replication tool that replicates data from a Postgres primary server to its replica, and subsequently to backup storage such as Amazon S3 or Azure Blob storage. This data migration is executed by implementing two separate BryteFlow Ingest pipelines: one dedicated to loading data from the primary to the replica, and another to transfer data from the replica directly to S3 or Blob storage. Postgres Replication with BryteFlow
BryteFlow for CDC Replication
BryteFlow is a no-code, real-time data replication tool that enables automated data pipelines to On-premise and Cloud destinations. BryteFlow uses automated log-based Change Data Capture (CDC) to replicate data from transactional databases (On-Prem and Cloud) like SAP, Oracle, PostgreSQL, MySQL and SQL Server to Cloud platforms like Amazon S3, Amazon Redshift, Snowflake, Azure Synapse, Azure Data Lake 2, PostgreSQL, Google BigQuery, SQL Server, Teradata, Kafka, SingleStore and Databricks in real-time.
BryteFlow has a user-friendly graphical interface and is self-service. It’s robust enterprise-grade replication supports high volumes of enterprise data, moving petabytes of data in minutes – approx. 1,000,000 rows in 30 seconds. It does this with powerful multi-thread, parallel loading, smart configurable partitioning and compression. BryteFlow Ingest provides a range of data type conversions (Paquet-snappy, ORC) out-of-the-box, so data is immediately ready to use on destination.
BryteFlow automates every process, including data extraction, CDC, data merges, schema, and table creation, DDL, data mapping, masking, and SCD Type-2 history. Deltas including updates, inserts and deletes are merged automatically with existing data to sync with source. BryteFlow provides an option for data versioning and has a rapid deployment process, allowing you to receive your data within two weeks, in contrast to the months required by competitors. How BryteFlow Works
BryteFlow for PostgreSQL Database Replication: Highlights
- BryteFlow’s Change Data Capture (CDC) for PostgreSQL replication operates without impacting source systems and incorporates best practices.
- High-performance data extraction and loading to PostgreSQL are achieved through parallel multi-thread loading and configurable partitioning. About BryteFlow Ingest
- Postgres replication without any coding – BryteFlow automates ETL including data extraction, CDC, merges, mapping, schema, table creation, masking, and SCD type 2 history. How to Select the Right Data Replication Software
- Provides out-of-the-box data type conversions, data is ready to use on destination for Analytics or ML. Postgres to Snowflake: 2 Easy Methods to Move Data
- Loads data rapidly with impressive throughput, handling approximately 1,000,000 rows in just 30 seconds. Supports both full refresh and incremental sync. SingleStore DB – Real-Time Analytics Made Easy
- BryteFlow offers automated data reconciliation using row counts and column checksums.
- BryteFlow supports PostgreSQL installations in both – Cloud and On-premise environments.
- Supports AWS Aurora Postgres, a PostgreSQL-compatible service.
- Ensures high availability and resilience with Automated Catchup functionality for network failure scenarios.
PostgreSQL Replication with BryteFlow Step-by-Step
The process remains the same for both – Ingest Pipeline 1, to transfer data from a Postgres Primary DB to a Postgres Replica DB, and Ingest Pipeline 2, to move data from a Postgres DB (either Primary or Replica) to Amazon S3 as a backup. The only difference is that the configuration of the destination database will be different.
*Please note that the following screenshots depict data loading from PostgreSQL into S3.
Step 1: Download and Install BryteFlow Ingest, followed by Login and Configure source database.
To use BryteFlow Ingest, you will to contact the BryteFlow team or download it from the AWS Marketplace and install it, take care that all pre-requisites have been met. Upon installation, login and navigate to the “Connections” tab in the left-hand panel. Choose the “Source Database” option and then follow these steps to configure your source database:
- From the available choices, select “Postgres” as the Database Type.
- Provide the Postgres Host Details in the Database Host field.
- Specify the Port Details in the Database Port field.
- Enter the Database Details into the Database Name field.
- Input the User Id used for Database connection in the User Id field.
- Provide the corresponding User password for Database connection in the Password field.
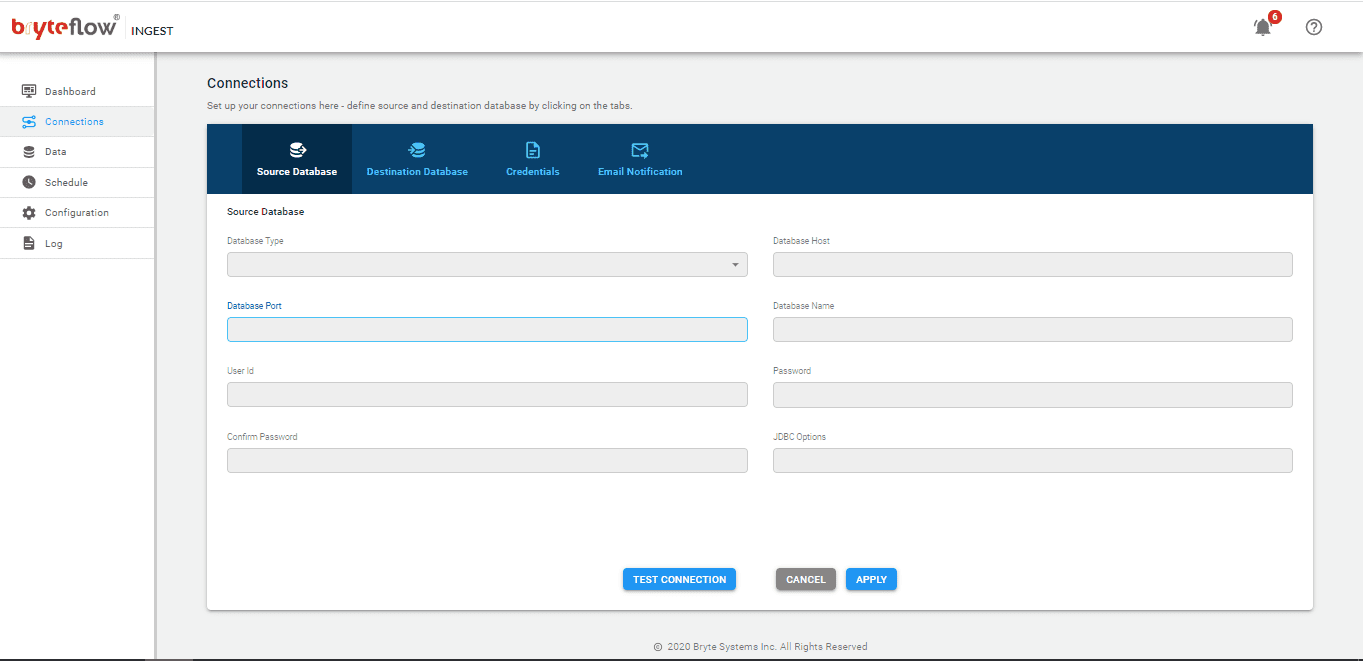 Connections Screen
Connections Screen
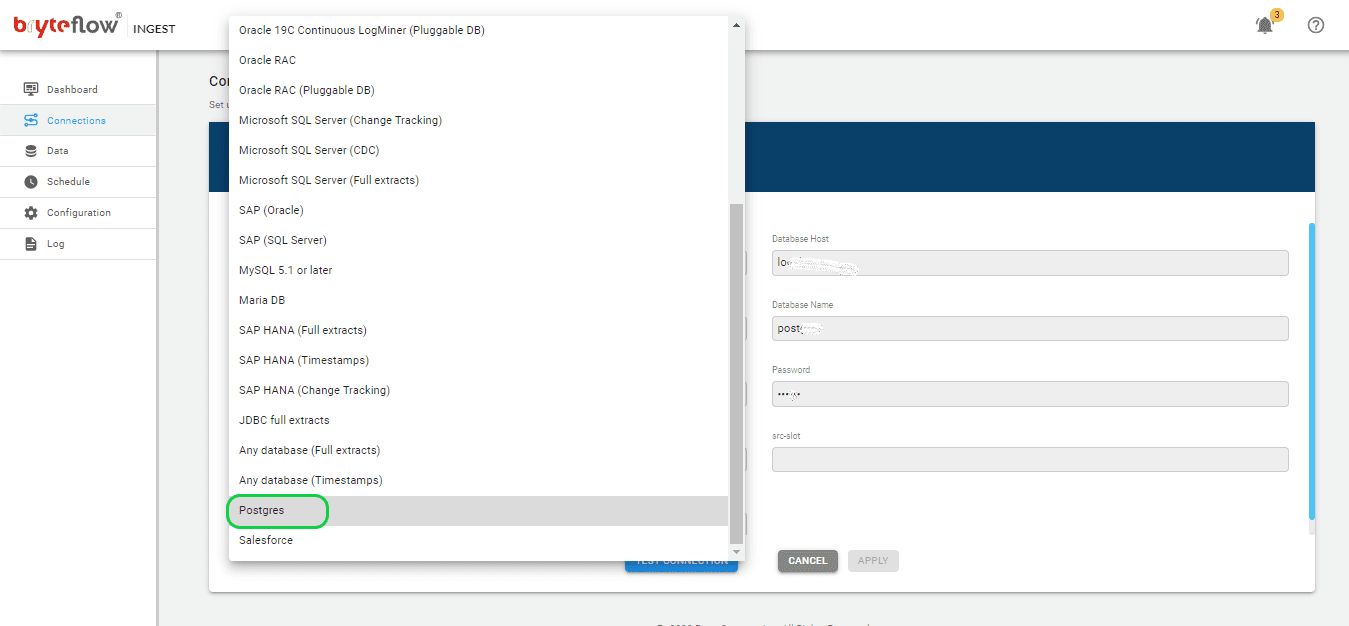
Step 2: Configure destination database.
Select “Connections” tab in the left panel and choose the “Destination Database” option. Follow the steps below to establish a connection with your destination database:
For Pipeline 1
Please refer to the provided screenshot for guidance on connecting to the Postgres replica for BryteFlow Ingest Pipeline 1.
- Select “Postgres” as the Database Type.
- Enter the Postgres Host Details in the Database Host field.
- Specify the Port Details in the Database Port field.
- Input the Database Details into the Database Name field.
- Provide the User Id used for Database connection in the User Id field.
- Enter the corresponding User password for Database connection into the Password field.
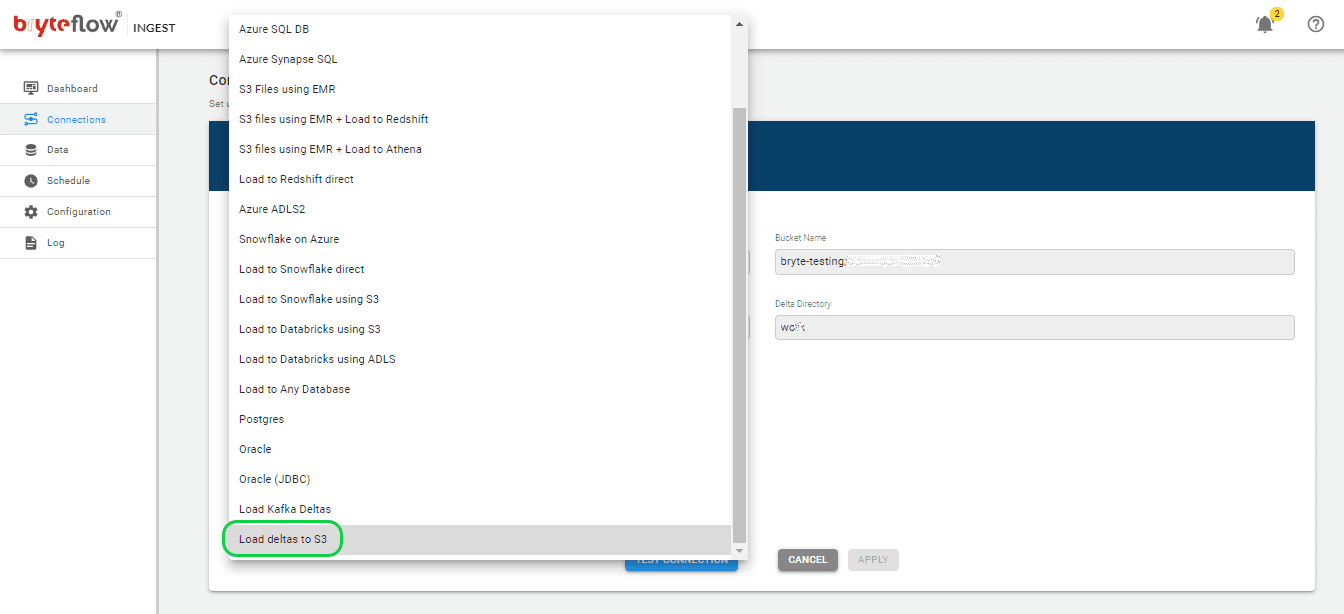
Select “Connections” tab in the left panel and choose the “Destination Database” option. Follow the steps below to establish a connection with your destination database:
The following screenshot illustrates connecting to AWS S3 for Ingest Pipeline 2:
- Choose “Load deltas to S3” as the Database Type.
- Enter the Bucket Name in the designated field.
- Specify the Data Directory in its respective field.
- Update the Delta Directory information in the corresponding field.
Connections Screen
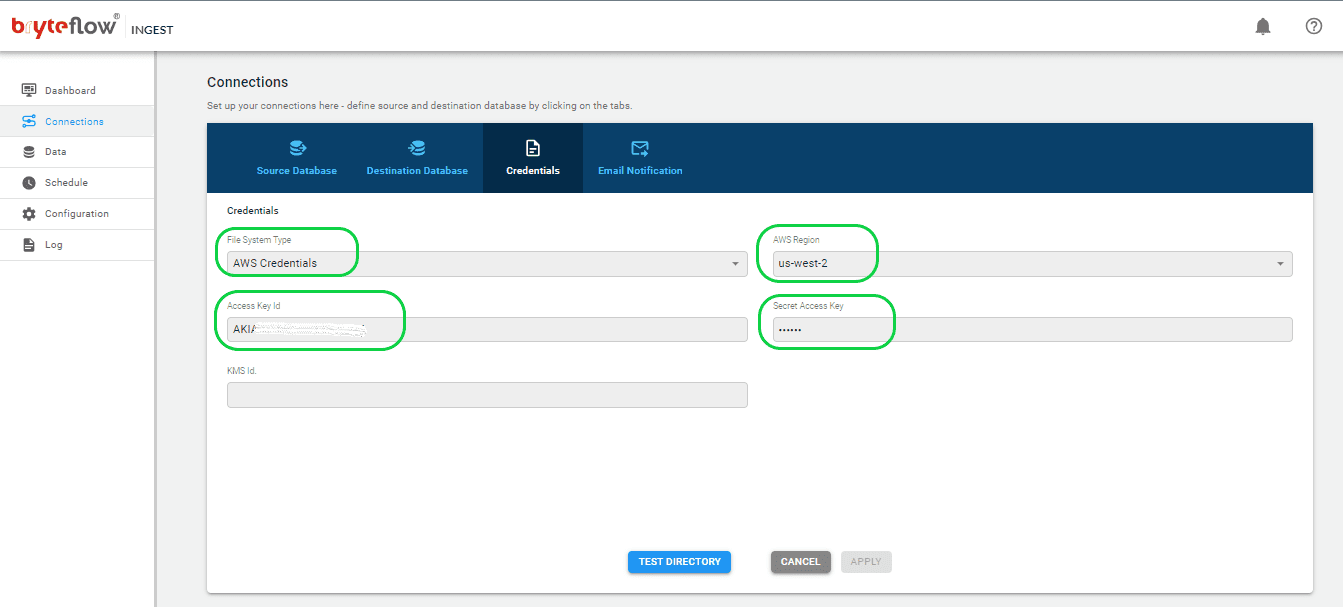
Step 3: Configure AWS Credentials.
Navigate to the “Connections” section and select “Credentials” to initiate a connection setup with your target database. Follow these steps:
- From the provided options, select “AWS Credentials” as the File System Type.
- Pick your desired AWS region from the “AWS Region” dropdown menu.
- Enter your Access Key ID in the designated field.
- Input your Secret Access Key in the appropriate field.
- Optionally, update the KMS ID field with your relevant details if you select “AWS IAM access” in the File System Type.
Step 4: Select the tables you want to replicate.
Select the “Data” tab to set up the source table(s) for replication. Here, you’ll define the primary key and transfer method for each table. Opting for ‘By Primary key with History’ ensures preservation of SCD Type2 history. If you choose ‘By Primary Key,’ it creates a replica of the source table without historical data. Additionally, you can use the “Where” feature to filter out unwanted data, and Byteflow Ingest allows you to mask sensitive data within columns (Primary Key and Masking Panel).
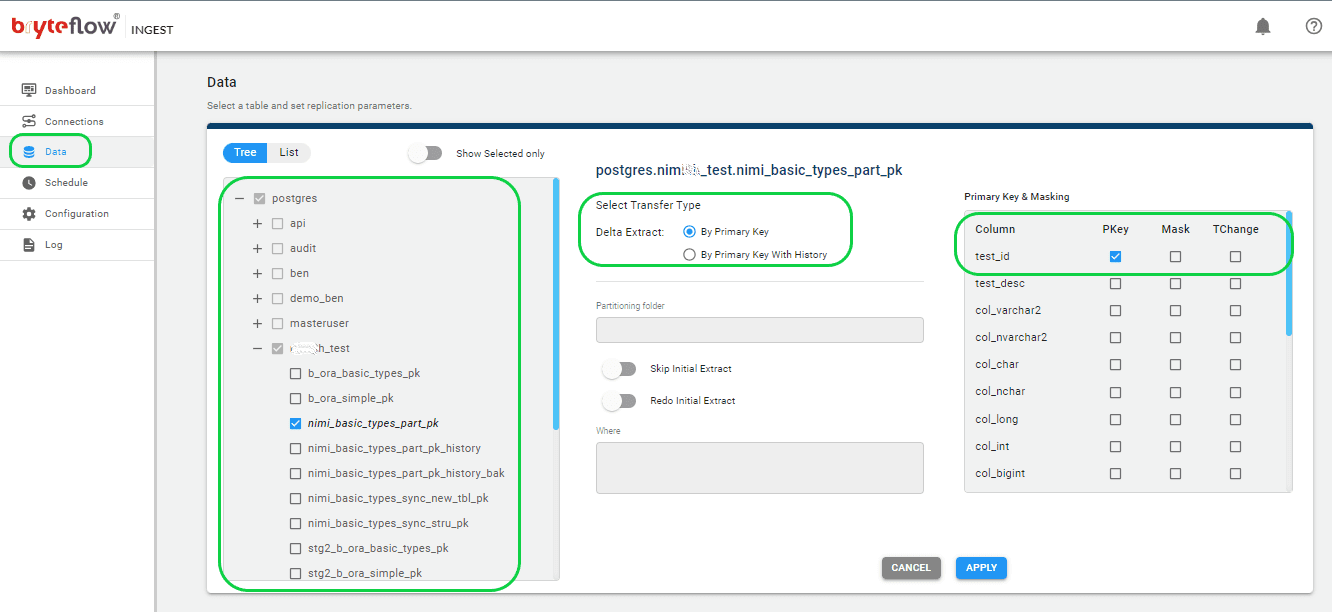
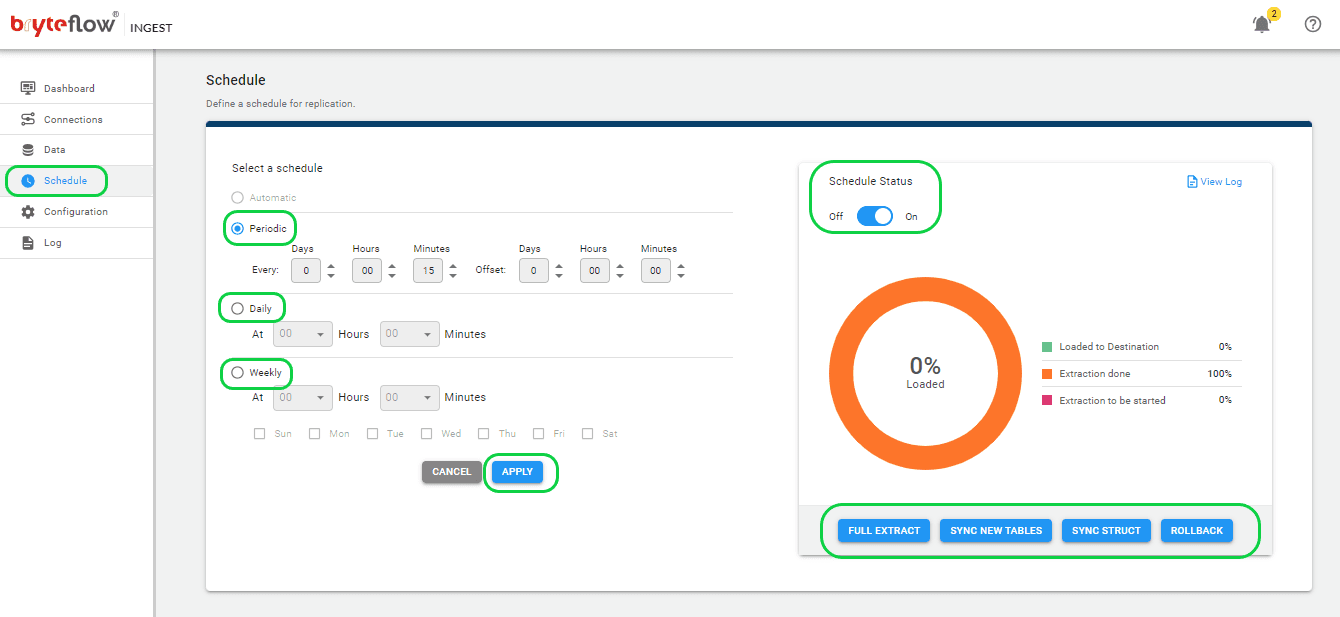
Step 5: Schedule the replication.
Select the Schedule tab in the left panel to go to the Schedule page to schedule the frequency of the replication. Select the ‘Automatic’ radio button for delivering changes as they happen or select from ‘Periodic’, ‘Daily’ or ‘Weekly’ if you need to schedule a frequency.
You can also prescribe the kind of replication you need. Opt for “Full Extract” for the initial load, “Sync New Tables” to incorporate new tables post-replication activation, “Sync Struct” to reflect structural changes in current tables, and “Rollback” to revert to a previously successful run, particularly useful in case of replication disruptions due to outages.
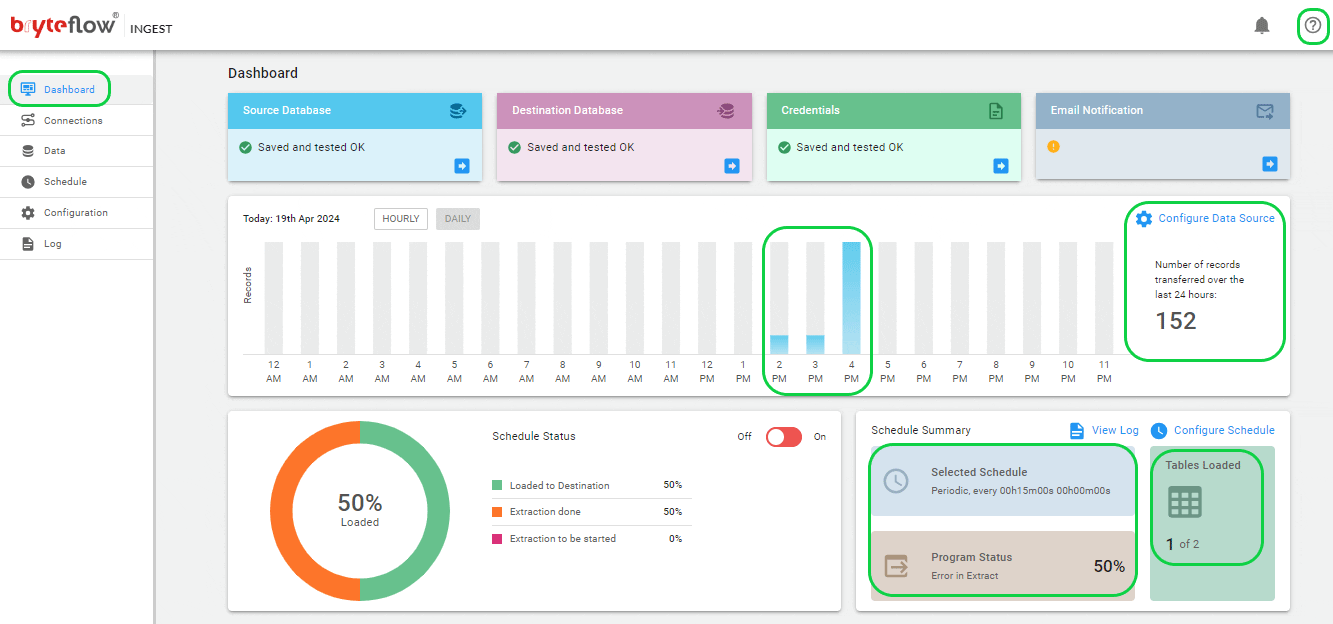
- Effortlessly monitor these tasks with the BryteFlow Ingest dashboard. This dashboard provides total visibility into BryteFlow Ingest operations, including the total number of records and tables loaded, real-time updates on active loading processes, replication frequency, and the current status of connections.
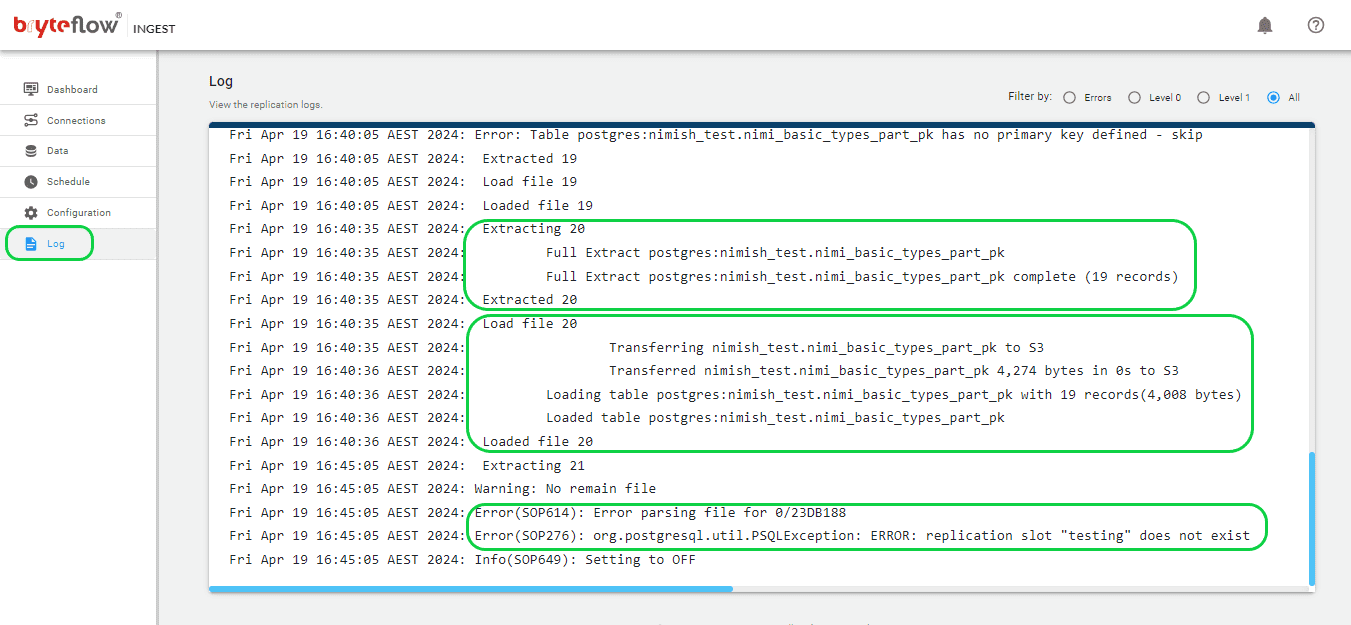
- Additionally, you can track progress through the log, receiving instant updates regarding the replication process. This includes extraction or loading statuses, the quantity of loaded records, and any encountered errors.
Conclusion
This blog provided insights into PostgreSQL database replication, discussing various types of replication methods and their pros and cons. It also introduced BryteFlow as a highly efficient no-code tool for PostgreSQL replication and provided a step-by-step demo to move data using BryteFlow. If you are interested in easy, real-time PostgreSQL replication with BryteFlow, do contact us for a demo.




