
Data can be transformative for an organization. How and where you store your data for analysis and business intelligence is therefore an especially important decision that each organization needs to make. Should you choose an on-premises data warehouse/data lake solution or should you embrace the cloud? Do you need a Data Lake or Data Warehouse?
On-premises or Cloud Data Warehouse/Data Lake– that is the question
On-premises data warehouses and data lakes require servers to be in your data centre, a team to manage them and require a large initial investment that tries to accommodate current and future data needs. Cloud data warehouses and data lakes on the other hand are fully managed and can start with a small investment and grow as per the business demands. You do not need to provision for the future, but for present needs. This knowledge brings peace of mind that extra capacity can be added overnight if need be. Build a Data Lakehouse on Amazon S3 without Hudi or Delta Lake
Amazon Redshift
Amazon Redshift is a cloud data warehouse . It is a fully-managed petabyte-scale cloud based data warehouse product designed for large scale data set storage and analysis. It provides organizations agility, flexibility and cost-effectiveness. Data Integration on Amazon Redshift
Amazon S3
Amazon Simple Storage Service (S3) is a performant object storage service for structured and unstructured data and the storage service of choice to build a data lake. You have the flexibility to choose various AWS services to process the data or analyze it whilst keeping costs very low.
Create an S3 Data Lake in Minutes
To use Amazon Redshift and Amazon S3 effectively, getting your data efficiently from various data silos to the data warehouse/data lake is critical, as this will determine how quickly the users can access the data. Do they have to wait for 2 whole days till the data is loaded and make do with stale data or can they access their data across the organisation in near real-time to derive fresh and rich data insights?
In this post, we will explain how you can create your data lake 10x faster to Amazon Redshift and S3 using the BryteFlow software
Some of the best practices for building your AWS Data Lake 10x faster:
- Log based Change Data Capture mechanism to get data to Redshift/S3
Instead of time-consuming bulk load updates or heavy batch processing, CDC captures only the changes in data from source transaction logs to destination, so you get data in almost real-time. It is a continual, extremely reliable process and has no impact on source systems.
Change Data Capture Types and CDC Automation
- Parallel multi-threaded initial sync
When doing an initial ingest of data, especially of exceptionally large datasets to Redshift/S3, parallel, multi-thread syncing to replicate data is extremely helpful in cutting down total data ingest time, since data replication proceeds in parallel on multiple threads with optimised extraction and loading. Build a Data Lakehouse on Amazon S3 without Hudi or Delta Lake
- Parallel multi-threaded log based capture and merge for Oracle
The logs can be mined on a completely different server therefore there is zero load on the source and data replication is much faster with parallelism. This can be configured as per your requirements. Your operational systems and sources are never impacted even though you may be mining huge volumes of data, and the throughput is extremely high, helping to build your AWS data lake that much faster.
Learn about AWS DMS Limitations for Oracle Replication
- Some of the best practices for loading data to Redshift
Split large files into multiple files for high performance loads
Amazon Redshift is an MPP (massively parallel processing) data warehouse, where several compute nodes work in parallel to ingest the data. Each node is further subdivided into slices, with each slice having one or more dedicated cores, equally dividing the processing capacity. The number of slices per node depends on the node type of the cluster. The table below shows the different node types and the number of slices.
| Node type | Default Slices per node |
| Dense Compute DC2 | |
| dc2.large | 2 |
| dc2.8xlarge | 16 |
| Dense Storage DS2 | |
| ds2.xlarge | 2 |
| ds2.8xlarge | 16 |
| RA3 Nodes | |
| ra3.4xlarge | 4 |
| ra3.16xlarge | 16 |
Once you extract data into files, compresses them and splits a single file, into multiple files according to the number of slices, so that files are loaded with the compute being distributed evenly across the slices on Redshift. The number of multiple files is a configurable parameter that can be set depending on the Redshift node types. The COPY command that ingests data into Redshift is configured optimally for fast data loads to Redshift.
Automatic creation of tables, default dist keys and distribution style
Data is distributed among the nodes on the basis of Distribution Style and Distribution Key of a particular table in Redshift. An even distribution of data enables Redshift to assign the workload evenly to slices and maximizes the benefit of parallel processing. This also helps during ingestion of the data. When ingesting data, BryteFlow automatically creates tables with the right DDL on Redshift. It also creates default dist keys and distribution style, so that table ingestion is highly performant.
Optimum sort keys used for optimum loads support efficient columnar storage
Data in the Amazon Redshift data warehouse is stored in a columnar fashion which drastically reduces the I/O on disks. Columnar storage reduces the number of disk I/O requests and minimizes the amount of data loaded into the memory to execute a query. Reduction in I/O speeds up query execution and loading less data means Redshift can perform more in-memory processing. Using the optimum table sort keys is the best practice for optimum loads.
- Some of the best practices for loading data to S3
Partition your data
To make data ingestion and data access performant, partitioning your data on S3 is vital. Partitions work like an index on a conventional database for speedy access.
Use the right file compression and file formats
Data can be accessed faster if they are stored in a Parquet and ORC file formats with the right compression. To decide which format and compression to use please refer to our blog which provides the details and the pros and cons of each approach.
- Automatic sync on Redshift and S3
BryteFlow automatically merges changes on Redshift and S3, with type2 history (if configured) with high performance. This means that data is ready to use as soon as it is ingested, without running lengthy ETL processes on it. The type 2 history feature is explained as below:
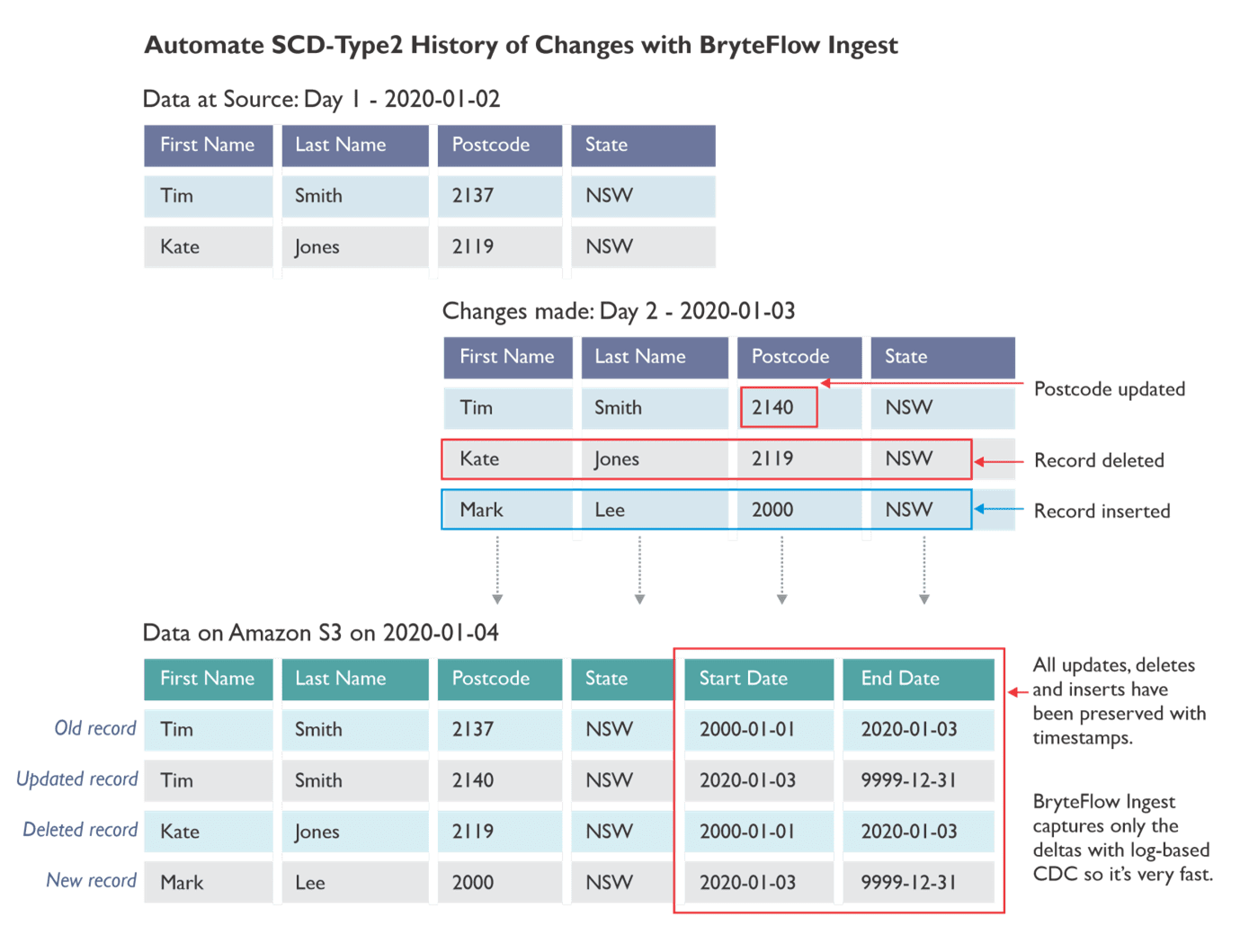
- Metadata for every extract and load can be captured on Aurora
Details on each extract and load process, for example tables names, the number of records affected, the start and end times and various other details is critical operational metadata that is very useful in determining performance, tuning and also for triggering other ETL processes. If this operational metadata is maintained on Redshift with every extract and load, constant single row inserts and updates can hamper performance drastically as Redshift is a columnar database and not an OLTP system.
The best practice is to keep the operational metadata in an Aurora database, which is OLTP in nature and can store this metadata with constant updates and inserts and low latency.
- Build your data lake on S3 and automatically query on Redshift using Spectrum
Build a continually refreshing data lake at scale on S3 with continual replication and transformation of data. you can query data automatically on S3 using Redshift Spectrum.
9. Offload data ingestion and data preparation on S3 and load to Redshift
Replicate and prepare data on S3 that can be pushed to Redshift for querying. This helps reserve the computational resources of Redshift for the actual querying (queries run much faster) while the S3 data lake handles data integration. Distributed Data Preparation on AWS
BryteFlow software supports all of the above ingestion best practices with a point and click interface and configurations, and helps building your AWS Data Lakes with zero coding and speed, so that you can focus your efforts on using the data lake, rather than creating it.
Conclusion
Amazon Redshift and Amazon S3 deliver fast performance and support efficient querying of data with high query performance. Your data can be stored cheaply and be used for various use cases throughout the organization with speed and agility whilst being extremely cost effective. The BryteFlow software makes this an extremely attractive value proposition, as you can liberate your data across data silos, and unlock the value super-fast on your AWS Data Lake. Compare AWS DMS with BryteFlow for data replication
To see how this works for your project, please Get a Free Trial from our website. We offer complete support on your free trial including screen sharing, online support and consultation.



