What is SQL Server Change Tracking?
SQL Server Change Tracking is a way to capture all changes made to a Microsoft SQL Server database. Any inserts, updates or deletes made to any of the tables made in a specified time window are captured. This information is made available for SQL Server replication purposes. SQL Change Tracking reads the transaction logs to find data changes and records the changes for ease of use. It is an extreme lightweight mechanism to capture the incremental changes in a specified window. Also learn about SQL Server CDC and Oracle CDC
SQL Change Tracking is an integral part of SQL Server replication
When data needs to be transferred or replicated to data lakes or data warehouses from a SQL Server database, the SQL Change Tracking functionality is especially useful as it helps in replicating incremental data efficiently, so that the data lake/ warehouse is always up to date and is a centralized place for data access from different SQL Server repositories. SQL Server to Snowflake in 4 Easy Steps
SQL Server is a relational database management system developed by Microsoft. Its primary function is to store and retrieve data efficiently and is generally used by applications for data storage and retrieval. SQL Server versions 2008 onwards support Change Tracking functionality.
Learn about migration from Oracle to SQL Server
SQL Server Change Tracking – points to note:
- All editions of SQL Server support this functionality. The Easy Way to CDC from Multi-Tenant Databases
- You need to enable Change Tracking at database level AND at the table level for all tables that need to be tracked.
- The tables need to have a primary key defined in the database. Database Replication Made Easy – 6 Powerful Tools
These steps are explained in depth below:
To enable Change Tracking
1. At DB level:
ALTER DATABASE databasename
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 7 DAYS, AUTO_CLEANUP = ON)
For Example:
ALTER DATABASE Adventureworks2019
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 7 DAYS, AUTO_CLEANUP = ON)
2. At table level:
USE <databasename>
GO
ALTER TABLE tablename
ENABLE CHANGE_TRACKING
WITH (TRACK_COLUMNS_UPDATED = ON);
For Example:
USE Adventureworks2019
GO
ALTER TABLE DimCustomer
ENABLE CHANGE_TRACKING
WITH (TRACK_COLUMNS_UPDATED = ON);
Checks to see if Change Tracking has been enabled:
1. Check if Change Tracking has been enabled at database level
SELECT *
FROM sys.change_tracking_databases
WHERE database_id = DB_ID(‘databasename’);
For example:
SELECT *
FROM sys.change_tracking_databases
WHERE database_id = DB_ID(‘Adventureworks2019’);
Results: ![]()
2. Check if Change Tracking is enabled at the table level
USE databasename;
SELECT sys.schemas.name as schema_name, sys.tables.name as table_name
FROM sys.change_tracking_tables
JOIN sys.tables ON sys.tables.object_id = sys.change_tracking_tables.object_id
JOIN sys.schemas ON sys.schemas.schema_id = sys.tables.schema_id;
For example:
USE Adventureworks2019;
SELECT sys.schemas.name as schema_name, sys.tables.name as table_name
FROM sys.change_tracking_tables
JOIN sys.tables ON sys.tables.object_id = sys.change_tracking_tables.object_id
JOIN sys.schemas ON sys.schemas.schema_id = sys.tables.schema_id;
Results: 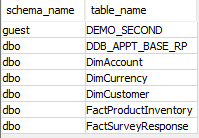
SQL Server Change Tracking: Pros and Cons
Challenges
- The table needs to have a primary key defined. Change Tracking cannot be applied for tables without a primary key.
Benefits
- An extremely light weight solution, Change tracking is very useful in most scenarios. SQL Server to Databricks (Easy Migration Method)
- It is supported by all editions of SQL Server, making this a very versatile solution. How BryteFlow enabled SQL Server Change Tracking and CDC from Multi-tenant databases for Optimove
SQL Server Change Tracking limitations or challenges with custom coding
- Though the native SQL Server Change Tracking functionality helps to capture changes, there is significant coding to be done, to capture these changes and use them for SQL replication to a Data Warehouse or Data Lake. SQL Server to Snowflake in 4 Easy Steps
- Not only does reliability and robustness need to be catered for but on-going maintenance, data issues and handling new tables and data types becomes an on-going issue for enterprises. SQL Server CDC To Kafka (Unbelievably Easy New Connector)
- The alerting and monitoring solution needs to be hand coded as well, and when you look at the different components required to get this working, a hand coded solution does not offer quick time to value and can be expensive to develop and maintain.
The No Code, automated way to capture changes from SQL Server is by using BryteFlow
- BryteFlow is a GUI based tool that helps to capture the changes from SQL Server with Change Tracking and several other mechanisms. Read more about the solution
- It is a no-code way of transferring your data to various data warehouses and data lakes SQL Server to Databricks (Easy Migration Method)
- It creates the schemas automatically on the target with the optimum data types and implements best practices for the target
- Data replicated to the target can be held automatically with SCD type 2 history if configured SQL Server vs PostgreSQL
- Automated, sophisticated data reconciliation – this is another enterprise grade feature not ordinarily offered in the market Database Replication Made Easy – 6 Powerful Tools
- BryteFlow offers enterprise grade SQL server replication and watertight security for installations on-premises, on the cloud or using a hybrid approach. SQL Server CDC To Kafka (Unbelievably Easy New Connector)
SQL Server Change Tracking for Multi-Tenant Databases to the Cloud Data Warehouse
Loading and merging large volumes of data from multi-tenant SQL Server databases can be challenging, especially when near real-time replication for Analytics is required. There is significant coding to be done to handle the number of databases, number of tables in each database and to deal with the schema evolution not being in sync across all the various tenants. BryteFlow as an alternative to Matillion and Fivetran
Further high volumes of data can cause bottlenecks and slowdowns (especially when a large amount of data gets loaded) or even deadlocked transactions. Cost of computing resources, memory and disk also become a challenge and add to the overall cost and complexity of the solution significantly. SQL Server to Snowflake in 4 Easy Steps
However, you don’t need to spend time on making your code more efficient to resolve these issues. BryteFlow can automate CDC from multi-tenant SQL databases easily. BryteFlow provides a massively scalable, secure, no-code solution that loads terabytes of data in near real-time, from multi-tenant SQL Server implementations using Change Data Capture (CDC) or Change Tracking. It merges and delivers complete, ready-for-analytics data that can be queried immediately with BI tools of choice. It enables data from multi-tenant SQL databases to be defined and tagged with the Tenant Identifier or Database ID from where the record originated, so using this data becomes simple. BryteFlow for SQL Server Replication
Conclusion
In contrast to the coding-intensive approach, we offer easy, real-time SQL Server replication with Change Tracking using BryteFlow. Just point and click to set up. Replicate large volumes of data easily with parallel threaded initial sync and partitioning followed by delta sync. Tables are created automatically with data upserted or with SCD Type 2 history. You get multiple change data capture options appropriate for the SQL Server version or edition you are using (all versions/editions supported). Get ready to use data at the destination whether S3, Redshift, Snowflake, Azure Synapse, Databricks, PostgresSQL, BigQuery, Kafka or SQL Server.



