Microsoft Azure / SQL Server Connections
Replication to ADLS Gen2
Azure Data Lake on ADLS Gen2
Why Build an Azure Data Lake on ADLS Gen2?
An Azure Data Lake on Azure Data Lake Storage Gen2 or ADLS Gen2 as it is popularly known, has been described by Microsoft as a ‘no-compromise data lake’ with good reason. It combines the best features of both – ADLS Gen1 and Azure Blob Storage. ADLS Gen2 minimizes usage of compute resources needed to extract data for analytics and provides cost-effective Azure Cloud storage. ADLS Gen2 is highly elastic and scalable which works great for big data analytics – it can seamlessly scale up resources to handle increasing analytics workloads. ADLS Gen2 also provides a highly secure environment for your Azure Data Lake with multiple cloud security features. ADLS Gen2 delivers high performance since you do not need to move or transform data for analytics. The addition of hierarchical namespace optimizes directory management processes, improving overall performance. Data Migration 101
Azure Data Lake on ADLS Gen2 with BryteFlow – The Highlights
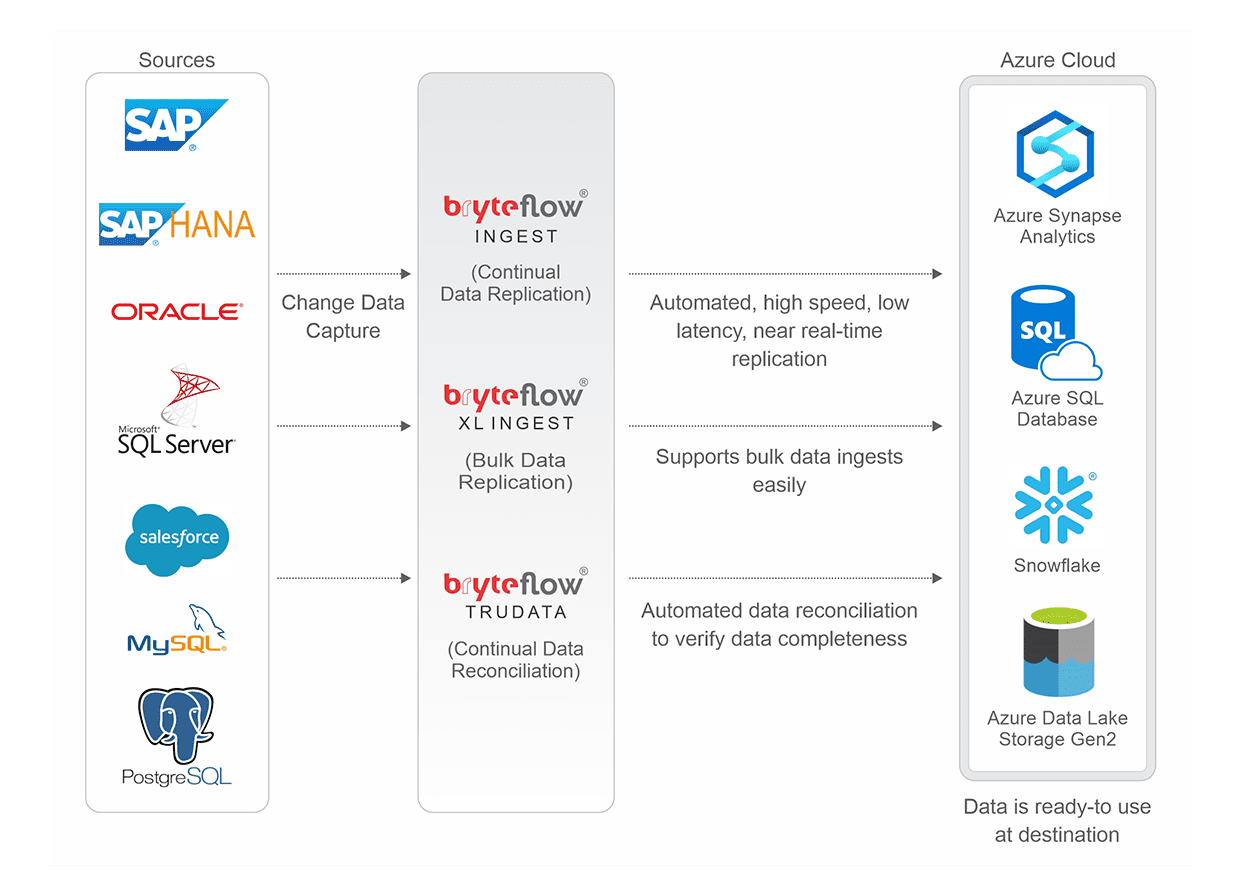
- BryteFlow delivers real-time data from transactional databases like SAP, Oracle, SQL Server, Postgres, and MySQL to the Azure Data Lake without coding for any process. Change Data Capture Types and CDC Automation
- BryteFlow Ingest replicates data to ADLS Gen2 using low impact, log-based Change Data Capture to deliver deltas in real-time, keeping data at destination synced with source. Also learn about Data Integration on Azure Synapse
- Our Azure Data Lake solution is completely automated and includes best practices for building an Azure Data lake, including security, Azure Data Lake partitioning and compression with data from multiple sources including SAP and Oracle.
- Bulk loading of data to the Azure Data Lake is easy and fast with parallel, multi-thread loading and partitioning by BryteFlow XL Ingest. How BryteFlow Data Replication Software Works
- BryteFlow delivers ready-to-use data to the Azure Data Lake with automated data conversion and compression (Parquet-snappy). 6 reasons to automate your data pipeline
- BryteFlow provides very fast replication to ADLS Gen2 – approx. 1,000,000 rows in 30 seconds, at least 6x faster than GoldenGate, so you can build your Azure Data Lake fast. Replication to Microsoft SQL Server
Build a Snowflake Data Lake or a Data Warehouse
Extract SAP Data easily with BryteFlow SAP Data Lake Builder
Successful Data Ingestion (What You Need to Know)
Azure Data Lake Architecture
This technical diagram explains our Azure Data Lake Architecture. Try BryteFlow Free
An Azure Data Lake in Real-time with BryteFlow
BryteFlow provides no code, real-time replication to your Azure Data Lake, delivering data that is ready to use for Analytics, ML and AI. Get a Free Trial of BryteFlow

Fastest Replication
1,000,000 rows in 30 secs

Data Sync with
Change Data Capture

Time to Data Delivery
is just 2 Weeks
Automated Data
Reconciliation
Update the Azure Data Lake with log-based CDC (Change Data Capture) to deliver incremental loads
Replicate data with log-based CDC (Change Data Capture) to deliver deltas continually to your Azure Data Lake from transactional databases and files, with zero impact on source systems. Learn about Oracle CDC and SQL Server CDC
Highest throughput, 6x faster than GoldenGate
BryteFlow replicates data to your Azure Data Lake at an approx. speed of 1,000,000 rows in 30 seconds. It is at least 6x faster than GoldenGate.
2 Weeks to Delivery of Data to your Azure Data Lake
The BryteFlow solution can be deployed at least 25x faster than other products. You can deploy BryteFlow in one day and get data delivery in just 2 weeks, as compared to our competitors’ average of over 3 months. How BryteFlow Works
No-code Azure Data Lake Implementation on ADLS Gen2
While doing the Azure Data Lake implementation, there is no coding to be done for any process including data extraction, partitioning, and masking. Change Data Capture Types and Automated CDC
Ready to use data in your Azure Data Lake with out-of-the box data conversions
Get a range of data conversions out of the box with BryteFlow Ingest, and access data ready for analytical consumption. BryteFlow enables configuration of custom business logic to aggregate data from multiple applications or modules into ready inputs for AI and ML. ELT in Data Warehouse
Bulk Loading to the Azure Data Lake is super-fast with XL Ingest
Bulk loading to ADLS Gen2 is easy. BryteFlow XL Ingest ingests the initial full load on the Azure Data Lake extremely fast, with multi-threaded parallel loading, smart partitioning, and compression. BryteFlow Ingest captures incremental loads continually with log-based Change Data Capture.
Built-in resiliency and Automated Network Catchup in your Azure Data Lake
BryteFlow has an automatic network catch-up mode. It just resumes where it left off in case of power outages or system shutdowns when normal conditions are restored. Data Migration 101 (Process, Strategies and Tools)
ADLS Gen2 as an Azure Data Lake
Building an Azure Data Lake on ADLS Gen2 has many benefits as seen below
-
ADLS Gen2 combines the best of ADLS Gen1 and Azure Blob Storage
Earlier users needed to select between an object store (Azure Blob Storage) or file-based system (ADLS Gen1). ADLS Gen2 provides both – Azure ADLS file level security, file system semantics and unlimited scalability, and since Azure Blob Storage serves as a foundation, users get low cost, tiered, limitless storage with high availability and disaster recovery capabilities.
-
ADLS Gen2 is optimized for large scale big data analytics
Azure Data Lake Storage Gen2 features the addition of a hierarchical namespace to Blob storage. This means objects/files are categorized into a hierarchy of directories for accessing data efficiently and fast, leading to faster query performance. ADLS Gen2 has been designed to handle very high throughput and gigabytes of data and is ideal for building enterprise data lakes on Azure and supporting large scale analytics workloads. Data Integration on Azure Synapse Analytics
-
ADLS Gen2 Data Lakes are highly scalable
ADLS Gen2 can store and serve data at exabyte level since it is highly scalable in design. Throughput can be measured in gigabits per second (Gbps)with a high number of input/output operations per second. ADLS Gen2 processes data at almost constant per-request latencies.
-
Azure Data Lake on ADLS Gen2 has low storage and compute costs
On ADLS Gen2 storage and compute costs are low. Users do not need to move their data or transform it for analytics, which saves time and warehousing costs. Since ADLS Gen2 is built on Azure Blob Storage, data storage costs are very low (roughly 50% of ADLS Gen1). The hierarchical namespace feature further improves analytics performance, requiring fewer compute resources and reducing time to process and access data, leading to a lower total cost of ownership. Need a Data Lake or a Data Warehouse?
-
ADLS Gen2 integrates with several other Azure services
ADLS Gen2 integrates easily with and supports several Azure services that can help in data ingestion, data analytics and to create visual representations. This can help users do more with their Azure Data Lake with less time and effort.
-
ADLS Gen2 Security
ADLS Gen2 has several features that provide your Azure Data Lake a high level of security.
- Integration with Azure Active Directory (AAD) for seamless, secure access to apps within Azure Cloud. Security policies can be deployed and managed across the environment.
- Azure Role-based Access Control and POSIX ACLs (Access Control Lists) deliver granular data access control
- TLS (Transit Layer Security) encrypts data at rest and in transit providing confidentiality to the data in the Azure Data Lake
- ADLS Gen2 guarantees 99.99% of availability of data with read-access geo-redundant storage. ADLS Gen2 has data replicated in different geographical regions so it will always be available even if the original location is affected by a natural disaster or catastrophe.
-
Azure Data Lake has Convenience Built In
The Hierarchical File System (HFS) allows objects/files within an account to be organized into directories and sub-directories in a similar manner as the file system on users’ computers. Renaming or deleting a directory is a single metadata operation on the directory. There’s no need to apply the changes individually to objects that share the name prefix of the directory. Successful Data Ingestion (What You Need to Know)