
This blog discusses the trail-blazing SingleStore DB, its innovative features, benefits, and use cases for different industries. SingleStore has now acquired BryteFlow and we explain the synergy between the solutions – how the features of BryteFlow make it an asset to SingleStore DB. BryteFlow for SingleStore
Quick Links
- The World of Databases
- Introducing SingleStore DB
- SingleStore Features and Benefits
- Innovative SingleStore DB Architecture
- Real World Use Cases by Industry for SingleStore DB
- BryteFlow as a Data Replication and Migration Tool
The World of Databases
There are databases, there are databases and then there are databases. The one you need has a lot to do with why you need it. Transactional processing? You need an OLTP database. Real-time analytics? Hello OLAP database! The transactional DB is great at reading and writing limited number of rows but not so much at scanning tables. This contrasts with the analytical DB which is a specialist at combining and filtering data from large tables, but slow when doing reads and writes for applications. Not just these, you also have other types of databases meant for specific purposes – timeseries databases, streaming databases, graph databases, search-optimized databases, key/value stores and more.
Data volumes are exploding and so are the types of data
The world is expanding and so is data, not only the volumes, but also the types of data and the ways in which it is used. Data from operational transactions, data from social media, IoT data from devices, sensor data, geo-spatial data, data from ERP and CRM applications, the list goes on. Also, in many scenarios, users need real-time data. A lot of applications and services have streaming data where they need to ingest thousands of transactions / events per second. Most large organizations need to monitor and analyze their ingested data for real-time analytics and reporting, not to mention ML and AI use cases. If you have multiple databases for different use cases you are simply adding to the complexity of the backend architecture, not to mention the costs. The ideal solution would be a database with simplified architecture that could take on multiple workloads easily and cost-efficiently. Enter SingleStore DB. Data integration on SingleStore
Introducing SingleStore DB
What is SingleStore DB? SingleStore DB was earlier known as MemSQL. SingleStore is an extremely fast, in-memory HTAP database (Hybrid Transactional and Analytical Processing Database). An HTAP DB enables you to run both transactional and analytical queries within the same database. Sounds good? But remember your database needs to be equally adept at managing both kinds of queries efficiently – which is easier said than done. SingleStore DB is a distributed, relational database that handles both transactions and real-time analytics at scale. In fact, SingleStore describes its database software as the No-Limits Database™ because it’s able to scale so massively.Oracle Migration to SingleStore
SingleStore can be accessed through standard SQL drivers and supports ANSI SQL syntax including joins, filters, and analytical capabilities. It provides very high throughput and scales horizontally by adding more clusters across a large range of platforms, both in the Cloud or On-Premise. It is easily compatible with popular data processing technologies like developer IDEs, BI tools and implementation platforms and makes for easy integration within existing environments. SAP CDC to SingleStore
SingleStore Features and Benefits
SingleStore simplifies data architecture
Since the SingleStore database can handle both OLAP and OLTP workloads, you do not need two separate databases to handle these operations. Whether it is smaller single record transactional operations or analytical queries crunching massive volumes of data, SingleStore performs these easily, without you needing to move your data to another system. Earlier you would have needed to transfer the data from your transactional OLTP DB to an OLAP system for analytics, and build out complex, time-consuming ETL pipelines. MySQL migration to SingleStore
SingleStore DB powers Real-Time Analytics
SingleStore is great for real-time analytics use cases ranging from IoT, supply chain analytics, cybersecurity, retail and more. The data could be from video feeds, market feeds, IoT sensor feeds, or real-time events. For some customer-facing applications, real-time streaming data needs to be analyzed as it comes in. And it needs to be consumed at high speed within an application or in a BI dashboard. SingleStore combines streaming ingestion together with lightning-fast writes, analytics and AI/vector capabilities in a single data platform. All this, without needing ETL or needing to move your data. Here are a few highlights of SingleStore features for real-time analytics. How to Select the Right Data Replication Software
- SingleStore provides high throughput and parallel streaming, ingesting millions of events per second from data sources like Apache Kafka, Blob storage (S3, Azure Blob, GCS) or HDFS. Oracle Migration to SingleStore
- With SingleStore DB you can analyze more than just relational data. It combines JSON, time-series, full-text search, geospatial, vector data and more.
- SingleStore possesses the patented three-tier Universal Storage format that combines the high-speed table scan performance of a columnstore with the selective seek performance of a rowstore index, along with Cloud Object storage.
- SingleStore provides millisecond query performance for complex queries, that matches that of premier data warehouses as far as analytics benchmarks are concerned. SAP CDC to SingleStore
- SingleStore separates storage and compute so you can get high availability, and unlimited storage and compute resources that can be scaled separately as per requirement, to align with your workload. Learn about Oracle Autonomous Data Warehouse
- With SingleStore it is simple to extract, load and transform your data since data pipelines are built into the product, which is not the case for other databases. You can continuously extract, transform (if required) and load data in parallel threads at lightning-fast speed. It supports data formats such as CSV, JSON, Avro and Parquet. A convenient feature is SingleStore performs real-time de-duplication of data. MySQL migration to SingleStore
SingleStore DB supports Generative AI Applications
- SingleStore offers great support for generative AI applications with its vector search capabilities. Though it is a high-performance relational database, it offers accurate, high-speed vector and full-text search that is required for AI applications.
- SingleStore functions as a vector database, enabling fast vector + full-text search. It offers Indexed ANN search, fast K-NN search, dot_product and euclidean distance measures, metadata filtering and re-ranking of semantic search results.
- SingleStore is compatible with the Generative AI ecosystem and provides users the capability to use platforms, plugins and libraries like OpenAI, AWS Bedrock, Llama 2, LangChain, Hugging Face, Vertex AI, Vercel and more, to build generative AI applications.
- With SingleStore you get all the benefits of a vector database without the complexity, licensing costs and additional training requirements of a pure vector database.
- SingleStore allows you to be up and running with SQL and Python Notebooks, enabling quick prototyping and deployment. Learn about Oracle Autonomous Data Warehouse
- With SingleStore you can use a huge range of relevant data. You can combine your enterprise data with vector embeddings from text, images, audio, video, etc. It supports all kinds of structured and unstructured data, including vectors, JSON, time-series, text, SQL and geospatial data.
- SingleStore provides metadata filtering, joins, aggregates, subqueries, window functions and other language features through its powerful SQL capabilities.
- SingleStore helps you augment for speed. Since transactional databases like MySQL or MongoDB® are limited in their capacity for analytics owing to row-based storage, and analytics-focused data warehouses cannot perform fast transactional operations (they have to read and write data from the Cloud object store), SingleStore provides a great fix by allowing companies to benefit from real-time analytics in their existing data stack with minimal code changes. SingleStore can simply be plugged in between the transactional and analytical databases providing millisecond response times for queries.
Innovative SingleStore DB Architecture
SingleStore combines the scalability of NoSQL databases with the structure, transactional strengths and SQL-driven functionality of conventional databases. With its support for SQL, SingleStore can be easily integrated with your current database environment, and you can even use your SQL-based tools with it. About SQL Server Change Data Capture
SingleStore architecture has been purposely created to manage truckloads of enterprise data and enable analytics in real-time. It has a shared-nothing, distributed architecture where data is partitioned and replicated over multiple nodes in a cluster. At the highest level SingleStore DB is made up of 3 basic components – Aggregator, Leaf Nodes and Disk Storage. BryteFlow integration on SingleStore
Aggregator
The aggregator is the gatekeeper to SingleStore cluster, it co-ordinates queries and manages data. It receives client SQL queries and prepares a query execution plan that is distributed across the leaf nodes. The aggregator controls data distribution and manages the results of the queries before sending them back to clients.
Leaf Nodes
In a SingleStore cluster, the leaf nodes are engines that each hold a part of the data, and execute a portion of the query execution plan. This is the reason behind SingleStore’s fast, scalable, concurrent query processing. The leaf nodes have a messaging system by which they communicate with each other to deliver data consistency and availability.
Disk Storage
SingleStore DB also has an optional disk storage feature for persisting data to disk. This can be used as a backup and for data recovery purposes. In case disk storage is used, data is stored in memory and on disk, in which the data distribution in both is managed by the aggregator.
Overall SingleStore DB architecture is immensely scalable and fault-tolerant. The database has horizontal scalability where it scales up by adding additional nodes to the cluster. The distributed architecture replicates data across multiple nodes. This feature makes the data available to users even if a node fails.
In-Memory Processing
Apart from the distributed architecture, SingleStore DB delivers super-fast query performance owing to its in-memory processing. Also, the SingleStore DB supports column-store indexing, which in turn improves query performance, since the quantum of data that needs to be read from the disk can be reduced.
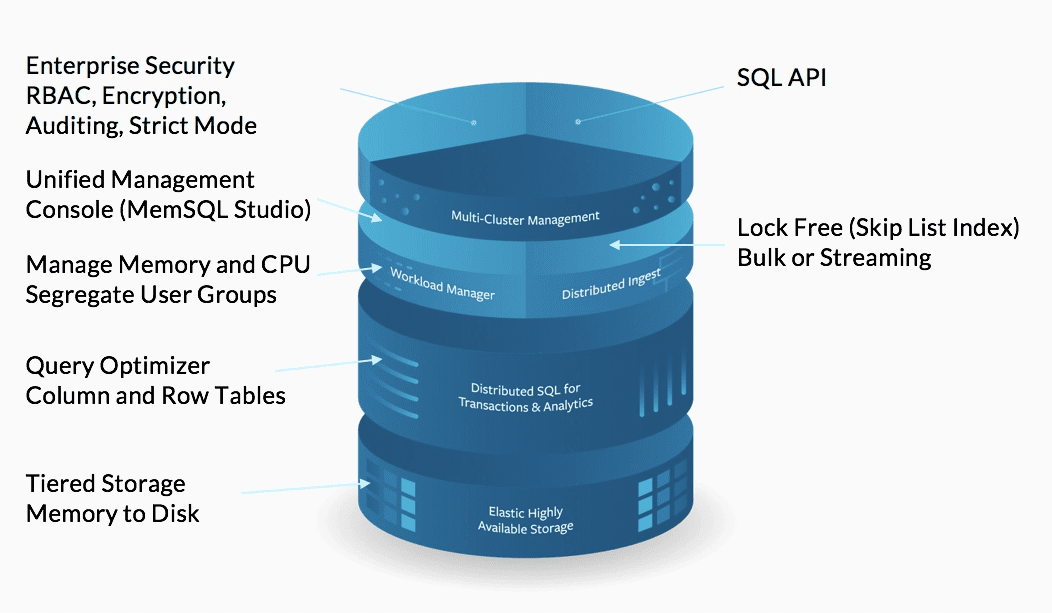
Here’s how SingleStore’s unique architecture is structured:
- SingleStore has tiered storage for memory and disk
SingleStore has tiered storage for memory and disk with each using a separate table type. This means you get the benefit of SingleStore’s memory-optimized row-store tables for super-fast query processing or ingestion. SingleStore also runs queries on disk, using column-store tables. In both cases everything is distributed, resulting in a highly elastic SingleStore DB that allows for scale-out processing of data. - Query Optimizer that handles Row-store and Column-store Tables
SingleStore has an optimizer for queries that manages both table types- row-based and column-based, due to which transactional processing, analytic processing, or both can be done at the same time. - SingleStore’s memory and CPU manager has the ability to segregate user groups SingleStore has a memory and CPU management governor that sits atop the query optimizer. It is also partly a workload manager that enables you to identify and segment processes or users to prevent outages through query processing.
- It has a lock-free distributed ingest across reads and writes, for bulk and streaming data ingestion
SingleStore provides a lock-free architecture based on the skiplist index, which carries out transactions and updates without needing to lock or block other reads and/or writes. This feature enables efficient delivery of bulk and/or streaming ingestion. How to Select the Right Data Replication Software - Transactional support like NoSQL but with ACID compliance
Transactional support on SingleStore is quite alike to that of a NoSQL system, since both can do continuous loading. However, SingleStore is ACID compliant. Every transaction is written to disk with SingleStore’s logging mechanism, so there’s no risk of data loss. This ensures HA configurations and transaction replication to other nodes or clusters can be done to ensure availability. - Multi-cluster management with SingleStore Studio and command-line tools
SingleStore DB has a management console called SingleStore Studio with an intuitive, user-friendly interface. There are also built-in command-line utilities for functions that enable you to deploy, manage, repartition, and rebalance nodes. SingleStore Studio and the command-line tools make it easy to identify bottlenecks and perform query planning analysis through the built-in web-based monitoring system. - SingleStore has a high level of enterprise security
SingleStore has a lot of financial services and public sector customers for whom security is crucial. Thus, SingleStore security includes role-based access control (RBAC), encryption, and support for auditing. There is also a ‘strict mode’ that prevents administrators from viewing data but does not get in the way of their administrative tasks. - SingleStore has a SQL API
Unlike distributed databases (NoSQL databases), SingleStore has a SQL API. It is a completely relational SQL database with table structures in relational format, making it easy for developers, engineers and data analysts to work with.
Get a Free Trial of SingleStore
SingleStore Architecture – How it Works (Source)
Real World Use Cases by Industry for SingleStore DB
SingleStore DB is extremely powerful and with its fast performance and immense scalability, it works well with modern applications. Here are some use cases in which SingleStore DB shines.
SingleStore for Financial Services
SingleStore enables real-time transactions with sub-second refreshes
SingleStore DB with its in-memory database and distributed architecture works well for fast transactional workloads, think of huge investment portfolios with thousands of positions that require real-time data with sub-second refresh. Portfolio managers of Hedge funds, high net worth individuals, investment banks, sovereign wealth funds, endowments, and bond management institutions appreciate the super-fast processing on SingleStore.Developers find it easy to build high-performance transactional applications using SingleStore owing to its support for standard SQL queries and mainstream programming languages.
Millisecond queries, on-demand risk analysis and pattern recognition
SingleStore enables financial institutions to perform low latency, complex analytical queries to continuously check for compliance exposure. They can perform on-demand risk analysis without impacting operational systems. SingleStore also enables organizations to run pattern recognition queries on fast-changing data for accurate insights, to minimize compliance risk, and for fraud detection. For e.g. a Fortune 25 Financial Services Company with global offices selected SingleStore as a data platform to power multiple use cases, including a Private Wealth Management Portal for high net worth individuals.The customers needed to view portfolios and execute trades without delay, which their earlier platform was hard-pressed to do. Role of Data in Financial Services
SingleStore for Retail and E-commerce
SingleStore enables real-time insights into Sales and Customer behavior
SingleStore DB can help provide real-time insights into customer behavior, inventory, and sales etc. With data being analyzed on the fly for insights, companies can optimize retail operations, improve customer experiences, and increase revenue growth. Besides offline retail stores, e-commerce websites also need to manage real-time data to reflect payments and other transactions, something SingleStore excels at.
Multiple use cases for Retail
SingleStore solutions can also be used for recommendation engines, forecasting trends and fraud prevention. With its real-time analytics capabilities, SingleStore helps retailers become more responsive to market trends and customer preferences. Learn how SingleStore helped one of the world’s top ten retailers sort out its inventory forecasting issue. Role of Data in Retail
SingleStore for Media and Communications
SingeStore can monitor advertising performance and enhance customer engagement
Advertisers need to keep tabs on advertising performance and customer engagement, and to observe how customer behavior is being impacted by their ads. Customers rely on SingleStore solutions to drive fast scalable analytics of live streaming content and respond to glitches in real-time. This is especially true of video streaming. Video delivery requires continuous monitoring and maintenance and real-time diagnostics on the quality of streaming to handle issues before customers notice them.
Customers can receive personalized content
SingleStore also enables content personalization at scale, which can enhance customer interaction and revenue if the content is on point, and available when customer engagement happens. This can be difficult to achieve for legacy data architectures. Pandora, the jewellery company needed a dashboard that allowed the Ad sales team to view data about current and former ad campaigns without significant delay (which was happening earlier). SingleStore enabled Pandora to write performant, sub-second queries against hundreds of billions of rows of data to drive the new dashboard.
SingleStore for Healthcare & Life Sciences
SingleStore is a reliable partner in managing petabytes of healthcare data
Data in healthcare is getting increasingly complex and massive, spurred by digitization of health records, wearable device data, data from clinical trials, and real-time health monitoring. Real-time processing and analytics of huge datasets becomes imperative, and traditional databases cannot easily manage this. That’s where SingleStore come in. It handles vast amounts of data and analyzes data as it is coming in, which enables health services providers get real-time insights to drive patient care, run efficient clinical trials and speed up the discovery of new drugs. Role of Data in Healthcare
SingleStore for High Technology Companies
SingleStore is a powerful real-time data warehouse
High technology driven companies need SingleStore as a real-time data warehouse to manage their customers’ operational data, create personalized customer engagement, and live operational analytics. SingleStore allows tech companies to collect and store multiple data streams in a relational format for real-time or historical analysis. For e.g. SingleStore helped Uber analytics get real-time data on riders, drivers, trips, financials, etc.to derive actionable metrics, for e.g., responding immediately to a surge of demand in a particular area.
Easily scalable, shared-nothing architecture
SingleStore’s shared-nothing architecture enables scaling up or out using typical commodity hardware. It is also SQL-compliant and data-persistent which is an advantage when it comes to using BI and middleware tools. SingleStore can be deployed on-premise, as-a-service, or a combination of both. It can be queried very fast, enabling discovery of new customer segments, and highlighting ‘likely to buy’ events as they happen, using standard SQL with historical and real-time data sources. Get a Free Trial of SingleStore
SingleStore and BryteFlow – A Great Synergy
You may have heard that BryteFlow has been acquired by SingleStore. This was not a random decision – a lot of thought went into it. SingleStore DB and BryteFlow have a rare synergy. Both solutions, though one is a modern database and the other a real-time data replication tool, enable the use of real-time data, allowing for query responses in milliseconds. They deliver and process data in real-time for large enterprise use cases, involving multiple data sources and data types. Customers of both companies are typically looking at migration from traditional legacy platforms, and need data implementations that are future-proof, scalable, resilient and capable of handling massive volumes of data in real-time.
Highlights of BryteFlow as a data replication and migration tool
- BryteFlow Ingest is a completely no-code, enterprise-scale data replication tool with extremely high throughput – approx. 1,000,000 rows in 30 seconds, which is 6x faster than GoldenGate.
- BryteFlow specializes in data migration from transactional sources and applications likeSAP,Oracle,SQL Server,MySQLandPostgreSQLto popular platforms likeAWS,Azure,SQL Server,BigQuery,PostgreSQL,Snowflake,SingleStore,Teradata,DatabricksandKafka
- It moves petabytes of data in real-time with parallel muti-thread loading, smart configurable partitioning and compression for handling huge initial data refreshes, and replicates changes and incremental data using log-based Change Data Capture, eliminating tedious batch processing. What to look for in a Real-Time Data Replication Tool
- With BryteFlow every process is automated, including data extraction, data merges, Change Data Capture, masking, mapping, schema and table creation, SCD Type-2 history and DDL (no coding ever).
- BryteFlow is Cloud-native and can be deployed on-premise or on Cloud. It has a point-and-click, intuitive interface that business users can use easily. How BryteFlow Works
- It delivers ready-to-use data on destination with out-of-the box data type conversions (e.g. Parquet-snappy, ORC) and provides time-series data for data versioning.
- BryteFlow enables configuration of custom business logic to collect data from multiple applications or modules into AI and Machine Learning ready inputs. How to Select the Right Data Replication Software
- It merges deltas (inserts, updates and deletes) with existing data continually, or as per the schedule defined, so your data stays current and synced with source.
- BryteFlow automates ETL of SAP data with the BryteFlow SAP Data Lake Builder, extracting data from SAP applications and databases likeSAP ECC,S4HANA,SAP BW,SAP HANA with business logic intact to the target. You get a completely automated setup of data extraction and automated analysis of the SAP source application.CDS Views in SAP HANA and how to create one
- BryteFlow provides replication support for all Oracle versions, including Oracle 12c, 19c, 21c and future releases for the long term.Oracle CDC (Change Data Capture): 13 Things to Know
It provides multiple SQL Server CDC options to cover any SQL Server version and edition, including SQL Server CDC, SQL Server Change Tracking and CDC with Timestamps. For ISVs it provides CDC from multi-tenant SQL Server databases easily, delivering ready-for-analytics data in near real-time. BryteFlow for SQL Server CDC
- BryteFlow has an Automated Network Catch-up feature in case of power or network outage, and simply resumes from where it stopped, when normal conditions are restored.
Conclusion
In this blog we have learned about the awesome features of the SingleStore DB, its benefits, architecture and use cases. We have also seen how SingleStore’s acquisition of BryteFlow with the latter’s powerful replication features, can help companies achieve their real-time data processing objectives on SingleStore even faster. If you would like a demo of BryteFlow, contact us
