Oracle Connections
Build a Teradata Data Warehouse
Why have a Teradata Data Warehouse?
A Teradata Data Warehouse is the perfect solution for integrating large volumes of data from multiple sources and subjecting it to analytics with your preferred BI tools. Teradata Database is a massively parallel relational database management system (RDBMS) and has been created for enterprise scale data warehousing and analytical processing applications. Teradata automates data distribution across multiple nodes in a cluster and allows queries to be executed in parallel. Teradata Database also enables a ‘Single Version of Business’ with a single data store accessible on a range of client architectures. You could have multiple data deployments with just a single data store and a single version of the company’s data, whether these deployments are on-premise, on Cloud or a hybrid implementation.
Oracle to Teradata Migration with BryteFlow
Teradata Data Migration Tool: BryteFlow
Migrating to Teradata is easy and automated with BryteFlow. It is a replication tool that extracts, loads and transforms data in real-time on the Teradata Data Warehouse. BryteFlow delivers ready-to-use data to Teradata EDW without coding and in real-time using Change Data Capture. It replicates data from legacy databases like SAP, Oracle, SQL Server, applications, and other sources to Teradata in real-time using log-based CDC (Change Data Capture). It automates every process including data extraction, partitioning, masking, schema creation, DDL, table creation, SCD Type2 history and more. Oracle vs Teradata (How to Migrate in 5 Easy Steps)
Migration to Teradata Highlights
- BryteFlow Ingest’s log-based CDC to Teradata does not impact source systems.
- Ingests large volumes of data for initial full refresh with multi-threaded parallel loading and partitioning.
- Replicates incremental data to Teradata using automated CDC, with best practices and optimization baked in.
- Migrates data to Teradata with zero coding for processes including extraction, merging, masking or type 2 history.
- BryteFlow provides automated data reconciliation on Teradata with row counts and columns checksum.
- Loads data to Teradata in minutes with high throughput – approx. 1,000,000 rows in 30 seconds.
- BryteFlow supports both -cloud and on-premise Teradata installations.
- Provides Automated Catchup for high availability and resilience with in case of network failure.
Data Pipelines, ETL Pipelines and 6 reasons to automate them
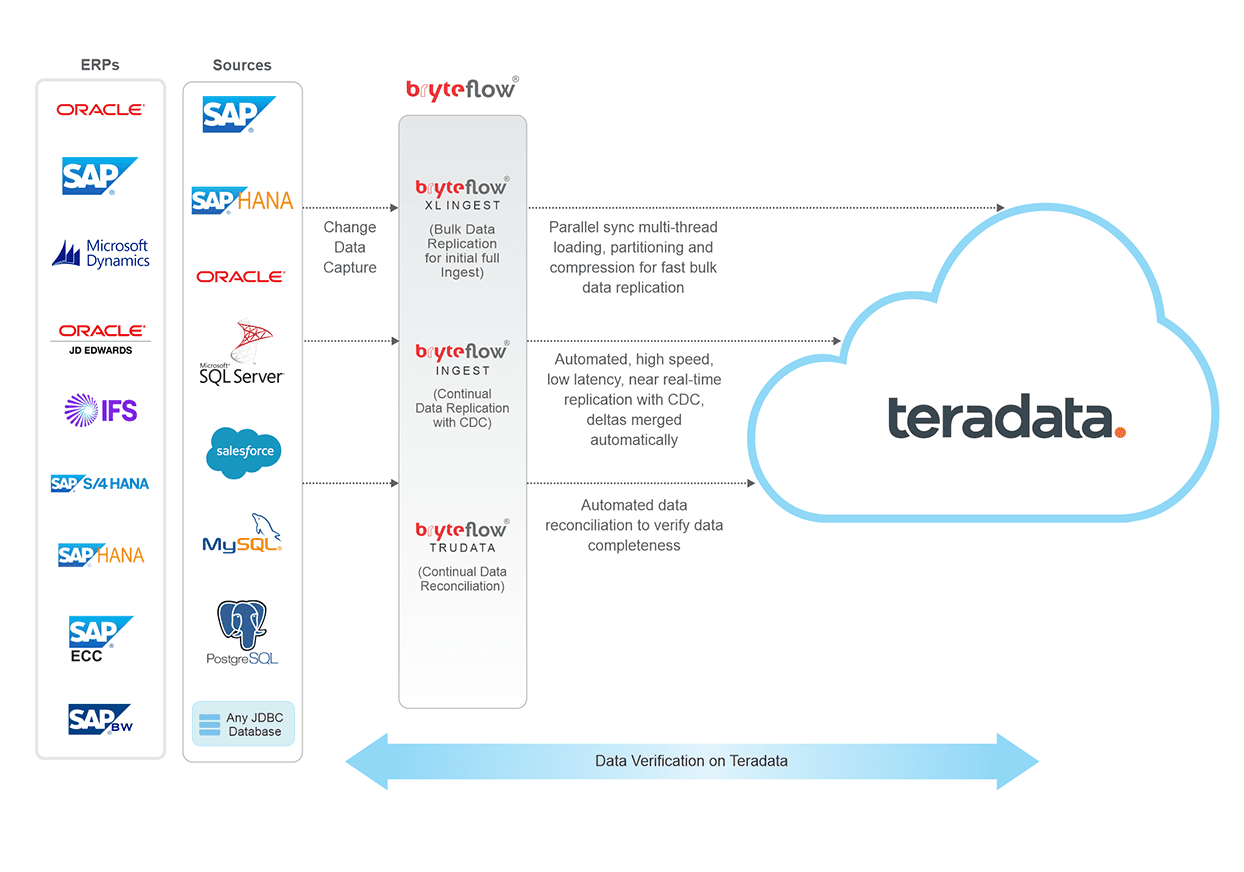
Teradata Migration with
Real-time CDC
BryteFlow provides fast, automated CDC to Teradata in
real-time. Here’s what you can do with BryteFlow in your Teradata Data Warehouse. Get a Free Trial of BryteFlow





Change Data Capture data to Teradata with history intact
BryteFlow uses log-based CDC to replicate data to Teradata in real-time, with a history of every transaction (optional). BryteFlow Ingest syncs data on Teradata in real-time with source capturing and merging deltas automatically with existing data (automates inserts, updates and deletes). Change Data Capture and why automate it
Data on Teradata is ready to use for Analytics or Machine Learning
BryteFlow delivers data to Teradata that can be immediately used for analytics or machine learning, through a range of built-in automated data conversions.
Loads data to Teradata with very high throughput
BryteFlow Ingest moves data to the Teradata data warehouse with a very high throughput of approx. 1,000,000 rows in 30 seconds. Oracle to Teradata Migration with BryteFlow
Automated DDL and high performance with best practices baked in
BryteFlow automates every process including DDL (Data Definition Language), schema creation, masking, partitioning and data extraction etc. to provide a fully automated data pipeline
Automated Database Schema Management
BryteFlow manages schema changes automatically. It can add columns to tables, add new tables if needed, and even change datatypes of columns.
Supports Teradata installations On-premise and in the Cloud
BryteFlow can replicate your data to the Teradata database in real-time, using built-in best practices and optimization, whether it is a Teradata on-premise database or a Cloud implementation.
Migrate data to Teradata with automated data reconciliation
BryteFlow provides automated data reconciliation with BryteFlow TruData. It verifies data using row counts and columns checksum, and provides alerts and notifications in case of incomplete or missing data.
Initial full refreshes to Teradata are fast with BryteFlow XL Ingest
in case of huge data volumes, BryteFlow XL Ingest performs the initial full ingest using multi-threaded parallel loading, smart partitioning and compression to transfer petabytes of data rapidly. This is followed by BryteFlow Ingest’s loading of incremental data and deltas using CDC to sync data with changes at source.
Replicate to Teradata with a user-friendly, point and click UI
BryteFlow is easy to deploy and use with a user-friendly point-and-click UI. You can deploy BryteFlow in a couple of hours and get delivery of data in just 2 weeks. Oracle to Teradata Migration with BryteFlow
Dashboard to monitor data ingestion instances
You can monitor your data ingestion statuses with the BryteFlow ControlRoom. View the BryteFlow replication instances, displaying latency, operation start time, operation end time, volume of data ingested etc.
Get built-in resiliency for your Teradata migration
BryteFlow has an automated network catch-up feature to deal with network failures, power outages, and other hindrances. It resumes operations from the point it stopped, when normal conditions are restored, so the Teradata migration can continue smoothly.
Oracle vs Teradata (How to Migrate in 5 Easy Steps)
Teradata Advantages




What is Teradata?
Teradata Database is a RDBMS (Relational Database Management System) designed for massively parallel processing. It is ideal for running analytics and data warehousing operations for high volume data. It can process queries in parallel owing to its unique architecture that supports unconditional parallelism. Teradata database has a shared-nothing architecture, which means that each node in the system has its own processor, memory, and disk storage. It supports structured as well as unstructured data and offers features for fast access, advanced analytics, and better governance. It can support multiple users concurrently, and can run on Unix, Linux, and Windows platforms. Here are some outstanding features of Teradata Database that make it the ideal data warehouse for analytics.
Teradata provides a Single Version of Business
Teradata allows multiple deployments with a single data store which can be accessed on a range of client architectures, whether on-premise, on Cloud or a combination of both. The single version of business enables a consistent and unified view of a company’s operations, processes, and data across all departments and business units.
Teradata Database has Linear Scalability
When data volumes grow, users can simply add more nodes to the system, thereby avoiding bottlenecks in processing or compromise in performance. Teradata systems are capable of scaling up to 2048 nodes. Adding on nodes increases the capacity to process data manifold and enables speedy performance.
Teradata has Shared-Nothing Architecture
Teradata’s shared-nothing architecture means that every node is independent and has its own resources that are not shared with other systems, including CPU, memory, and disk storage . This is a distributed computing model where each node has a portion of the data, and works on the data in parallel, making for fast query performance.
Teradata Database supports usage of SQL
Teradata Database supports ANSI SQL standards so you can interact with stored data using SQL commands like CREATE TABLE, INSERT, UPDATE, DELETE. You can use the SELECT statement to retrieve data from the tables and various clauses like WHERE, ORDER BY, GROUP BY, and HAVING to filter, sort and aggregate data. Teradata Database also has its own unique extensions that help users to benefit from Teradata parallelism efficiency. This is called Teradata SQL.
Teradata has Load & Unload utilities for data transfer
Teradata has unique utilities to make it easy to transfer data to and from Teradata systems, such as FastExport, FastLoad, MultiLoad, and TPT. These utilities provide reliable import and export of data, helping to make data movement more efficient.
You can use the same Teradata software across different depolyment models
A convenient aspect of the Teradata Database is that you can use the same database software across different modes of deployment. It has a hybrid and multi-cloud capability and whether you are running Teradata on-premise, in a virtual environment, in a private cloud or public cloud (AWS, Microsoft Azure), or a combination of these environments, you can use the same database software without any changes.
Teradata provides seamless connectivity
Teradata’s Massively Parallel Processing enables seamless connectivity with both – channel-attached systems, such as mainframes, and network-attached systems, thus users can manage and process data across various platforms with flexibility and efficiency.
Teradata automates Data Distribution
Teradata Database distibutes data to disks evenly and automatically, without need of manual intervention. It distibutes data across multiple nodes in a cluster. Each node contains a portion of the data and can process queries independently.