BryteFlow for MySQL CDC
BryteFlow for MySQL Replication: Availability guaranteed and lightning fast replication across a wide range of platforms.
Need to get your MySQL data to Amazon S3, Redshift, Snowflake, Azure Synapse or SQL Server? BryteFlow’s MySQL Data Replication with Change Data Capture (CDC) will get your MySQL data to the destination in near real-time. BryteFlow is automated, self-service and really fast with a point and click interface that business users can use easily. With BryteFlow’s log-based CDC technology you can continuously load and merge changes in MySQL data to the destination with no impact on source systems. It is easy to use and set up – just a few clicks and you’re ready to go! Data Migration 101 (Process, Strategies and Tools)
BryteFlow supports on-premises and cloud MySQL sources (eg. Aurora) and variations like MariaDB.
Change Data Capture and CDC Automation
Solution Highlights:
- MySQL replication using CDC with zero impact on your MySQL source
- Analytics ready data assets ELT in Data Warehouse
- Get an AI and ML enabled Data Lake
- Availability and high throughput
Data pipeline and why automate it
Successful Data Ingestion (What You Need to Know)
Key Features

- Zero coding – for extraction, merging, masking or type 2 history for all destinations including S3
- Enterprise-level security – deployment in your network
- High Throughput and performance
- Time series your data
- Supports all editions of MySQL and all cloud based like Aurora MySQL
- Self-recovery from connection dropouts
- Smart catch-up features in case of down-time
- Multiple mechanisms for Change data capture
- Transaction Log Replication
- Change Data Capture
Unlock your MySQL Data with a BryteFlow enabled automated Data Lake.
With BryteFlow, you can extract data from a full range of MySQL versions with just a few clicks. Further, BryteFlow enables configuration of custom business logic to consolidate MySQL data from multiple applications or modules into AI and Machine Learning ready inputs.

Zero impact on MySQL source
BryteFlow eliminates the need for complex application procedures or queries to extract MySQL data. It extracts data from the MySQL application’s database level logs and does not require any additional agents or software to be installed in your MySQL environment.
Successful Data Ingestion (What You Need to Know)

Quicker Insights
BryteFlow for MySQL can replicate data with high performance and load it to the destination so that it is ready to use for real-time insights.
ELT in Data Warehouse

Near real-time replication of data
With frequent incremental extractions, compression and parallel streams, BryteFlow ensures your data is constantly kept up-to-date and available to enable real-time analytics.

MySQL workbench to blend data sources
An easy to use drag-and-drop MySQL workbench delivers a codeless development environment to build complex MySQL jobs and dependencies across MySQL and non-MySQL data on S3.

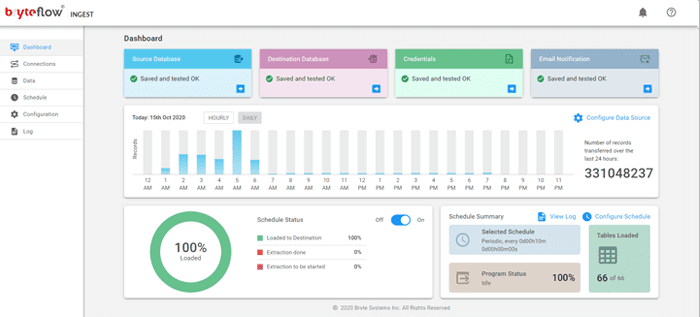
Dashboard for monitoring
BryteFlow for MySQL displays various dashboards and statistics so you can stay informed on the extraction process as well as reconciling differences between source and target data.

Automatic catch-up from network dropout
Pick up where you left off – automatically. In the event of a system outage or lost connectivity, BryteFlow for MySQL features an automated catch-up mode so you don’t have to check or start afresh.

Masking & Tokenization
BryteFlow for MySQL provides enterprise grade security to mask, tokenize or exclude sensitive data from the data extraction processes.

Time-scale history
BryteFlow for MySQL provides out-of-the-box options to maintain the full history of every transaction from MySQL with options for automated data archiving. You can go back and retrieve data from any point on the timeline.
Data Migration 101 (Process, Strategies and Tools)

Rob Pickering,
Head of IT,
Open Universities
They were professional, knowledgeable and willing to go above and beyond to help us.
“The team at Bryte recently helped us with some complex work in order to build a near-real time Data Hub on AWS featuring Amazon S3, EMR and Redshift. At all times in dealing with them they were professional, knowledgeable and willing to go above and beyond to help us, not only with the complicated design effort, but also with the implementation of that design.”


OPEN UNIVERSITIES
Helping Open Universities centralise and access data fast
Open Universities Australia is an online higher education organisation. Accessing data was slow and complicated since every department was accessing the data individually, leading to waste of analysts’ time and lengthy access processes. The lack of a single source of truth was another impediment to getting effective data insights.
BryteFlow helped build a near real-time Data-as-a-Service platform on AWS.
BryteFlow software was used to build a near real-time Data-as-a Service platform on AWS featuring Amazon S3, EMR and Redshift. BryteFlow delivered a centralised data repository for analytics and data science purposes and saved weeks of lost analyst time by providing easy access to the data. The solution provided Open Universities the capability to map the student journey from sign-up to course completion and being able to spot signs of student disengagement immediately.