SingleStore Connections
Connect to SingleStore Database with BryteFlow
What is SingleStore DB?
SingleStore DB is having a moment in the data world. And deservedly so, considering SingleStore DB is an extremely powerful DBMS that can process large volumes of transactions and analytics easily and concurrently. SingleStore is versatlie and can handle structured, semi-structured or unstructured data. SingleStore DB’s in-memory capabilities and distributed architecture make it a must-have for enterprises who need to focus on fast data processing and derive valuable insights. SingleStore can be run on public clouds, on-premises environments and hybrid deployments. SingleStore DB – Real-Time Analytics Made Easy
BryteFlow moves data to SingleStore on AWS, Azure and GCP using Change Data Capture
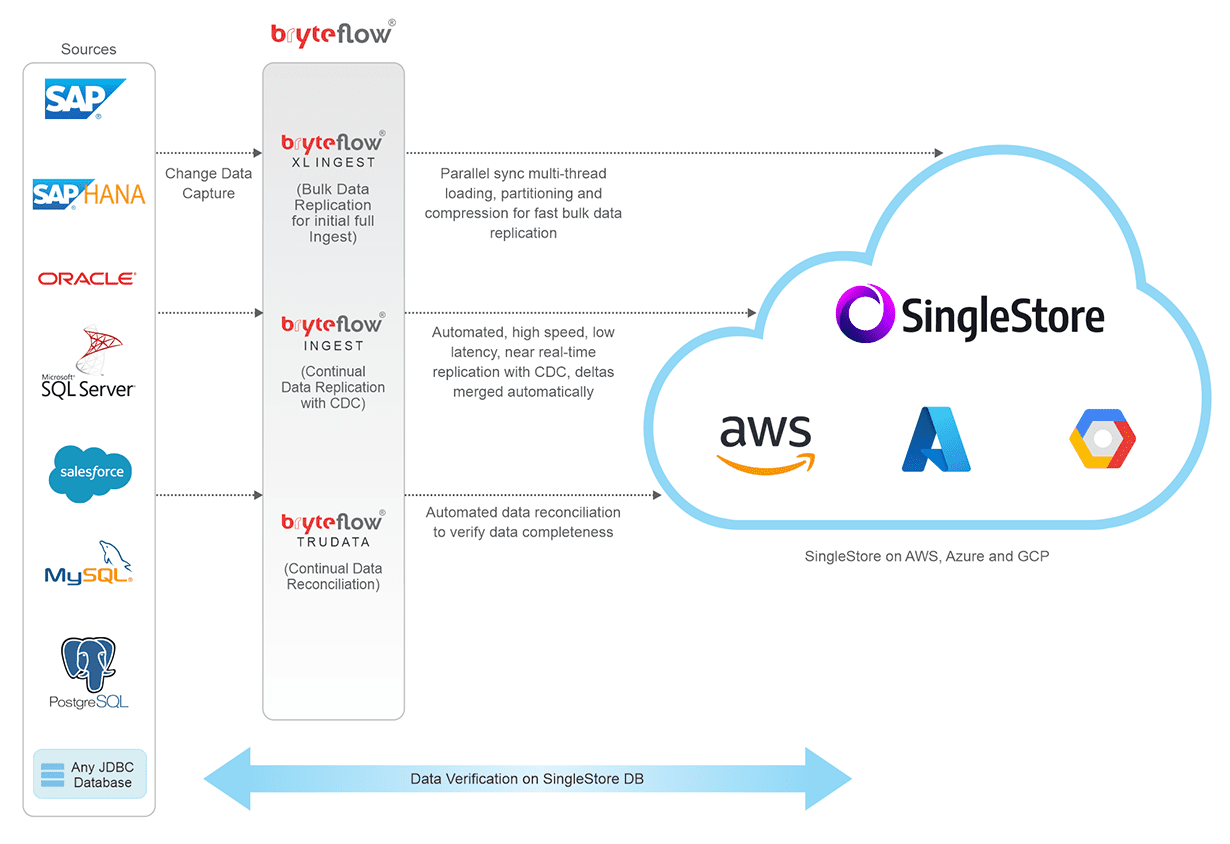
BryteFlow Ingest delivers data from sources like SAP, Oracle, SQL Server, Postgres and MySQL to the SingleStore platform on Azure, AWS and GCP in real-time using log-based CDC. BryteFlow replicates huge datasets (initial data) to SingleStore in minutes using parallel, multi-thread loading and smart, configurable partitioning. It replicates deltas in real-time using log-based CDC. BryteFlow automates every process, including data extraction, CDC, DDL, schema and table creation, masking and SCD Type2. Your data is immediately ready to use on SingleStore for Analytics, BI and Machine Learning.
BryteFlow as a SingleStore Connector: Highlights
- BryteFlow works as a SingleStore Connector to deliver real-time data from transactional databases like SAP, Oracle, SQL Server, Postgres, and MySQL to SingleStore on AWS, Azure and GCP. CDC with BryteFlow
- The initial full load of heavy enterprise data (>50 GB) to the SingleStore DB is performed with parallel, multi-thread loading and smart configurable partitioning by BryteFlow XL Ingest.
- BryteFlow Ingest replicates incremental data to the SingleStore database using low impact, log-based Change Data Capture to deliver deltas in real-time, keeping data continually synced with source (or as per specified schedule.)
- BryteFlow delivers ready-to-use data to the SingleStore DB with out-of-the box data type conversions and compression ( e.g. Parquet-snappy, ORC). SingleStore DB – Real-Time Analytics Made Easy
- BryteFlow provides data with low latency and very high throughput to SingleStore – approx. 1,000,000 rows in 30 seconds. How BryteFlow Works
- Our SingleStore ETL process is completely automated and has best practices built in.
- In case of data from SAP, the BryteFlow SAP Data Lake Builder can ETL data directly from SAP applications (with business logic) intact to the SingleStore database -no coding needed.
Suggested Reading:
SQL Server CDC for real-time SQL Server Replication
Oracle CDC (Change Data Capture): 13 Things to Know
Postgres CDC (6 Easy Methods to Capture Data Changes)
Replication with CDC to SingleStore DB
This technical diagram explains how BryteFlow works to integrate data on SingleStore. Try BryteFlow Free
ELT Data in Real-time to the SingleStore Database
Access ready-to-use data for Analytics, Reporting, ML, and AI on SingleStore DB using BryteFlow.

Fastest Replication
1,000,000 rows in 30 secs

Data Sync with
Change Data Capture

Time to Data Delivery
is just 2 Weeks

Every Process
Automated
BryteFlow uses log-based CDC (Change Data Capture) to sync data in the SingleStore DB with source
BryteFlow replicates data from transactional databases and applications with log-based CDC (Change Data Capture) to deliver deltas continually or as per schedule to your SingleStore target with zero impact on source systems. Learn about Oracle CDC, SQL Server CDC and Postgres CDC
Replicate data to the SingleStore DB with very high throughput
BryteFlow loads data to your SingleStore DB on AWS, Azure and GCP at an approx. speed of 1,000,000 rows in 30 seconds.
2 Weeks to Delivery of Data to SingleStore
BryteFlow can be deployed at least 25x faster than other products. You can set up in a day and start getting delivery of data in just 2 weeks, compared to an average of over 3 months for competitors. How BryteFlow Works
BryteFlow automates DDL in the SingleStore DB
BryteFlow automates DDL (Data Definition Language) in the SingleStore DB and creates tables automatically with best practices for performance. Save time and effort spent on data prep. About BryteFlow Replication
No-Code Data Integration on SingleStore
BryteFlow is a no-code CDC tool so there is no coding to be done for any process including data extraction, merges, schema and table creation, masking, and SCD Type2 etc. SingleStore DB – Real-Time Analytics Made Easy
Access ready to use data in your SingleStore DB with out-of-the box data conversions
Get a range of data type conversions out of the box with BryteFlow Ingest, It delivers data ready for analytical consumption in your SingleStore DB. BryteFlow enables configuration of custom business logic to aggregate data from multiple applications or modules into ready inputs for AI and ML.
Load heavy volumes of enterprise data to the SingleStore DB easily
Multi-thread parallel loading, smart partitioning, and compression is used for the rapid initial full refresh of data to your SingleStore DB. This is followed by capture of incremental data by BryteFlow Ingest that captures deltas continually with log-based Change Data Capture to sync data with source.
Built-in resiliency and Automated Network Catchup in SingleStore DB
BryteFlow has an automatic network catch-up feature. It just resumes where it left off in case of power outages or system shutdowns, when normal conditions are restored.
BryteFlow ETLs data to SingleStore on Cloud
BryteFlow delivers data in real-time to SingleStore AWS, SingleStore Azure and SingleStore GCP. Being a Cloud-native tool, BryteFlow has best practices built in for automated ETL to the Cloud.
About SingleStore DB
Why having a SingleStore implementation is worth your while
-
SingleStore, the high performance distributed SQL Database
SingleStore DB is a cloud-native, distributed SQL database which is high performance, highly scalable and very fast. It is designed as a real-time data platform and is meant for all applications -Analytics, BI and AI. It is reputed for low-latency queries and fast processing. It combines the scalability and speed of NoSQL databases with the stability and versatlity of relational databases.
-
The SingleStore DB is extremely versatile
With SingleStore you don’t need different databases for OLTP, OLAP, vector search, full-text search, documents, etc. Also built-in are SQL/Python Notebooks, are also built-in which is a data integration and compute service for AI workloads. This enables various data professionals (developers, ML engineers, data engineers) to collaborate on innovative projects.
-
The SingleStore DB can handle high volumes of streaming data
The Single Store DB can process millions of events per econd with high throughput and parallel streaming ingestion from sources like Kafka, Azure Blob stores, Amazon S3, GCS and HDFS.
Advantages of the SingleStore Database
-
SingleStore Database unifies transactions and analytics
SingleStore database can run transactions and analytics in the same db to provide high-performance real-time analytics on data from operations. You are spared the complexity of managing multiple databases.
-
SingleStore DB supports Standard SQL queries
SingleStore supports standard SQL queries and popular programming languages. It is easy to deploy and manage.
-
SingleStore allows for querying of multi-model hybrid data
SingleStore can combine data from sources like JSON, time-series, vector, full-text search, geospatial and more to enable super-fast analytics.
-
SingleStore separates storage and compute
With SingleStore you can get unlimited storage with high availability. You can seamlessly scale storage and compute resources independent of each other to manage the demands of any workload.